
Here at Buttondown, we rely on Postgres extensively for all of our data needs. Of course, we use it for our application database, which is where all newsletters, emails, users, and subscribers live. But we also use it beyond that: we sync Stripe subscriptions, support tickets and Git commits to track on our admin dashboard, we store events for every single email sent and page viewed, and even all the email providers that are often used maliciously. We've even started moving all of our email queueing system from the wonderful rq to Postgres (more about this in another post.)
Since the very start, this core Postgres database has been hosted in Amazon's Relational Database Service (RDS). This has a lot of advantages: we can scale it up with a few clicks, storage auto-expands to whatever we need, and best of all: we don't have to manage the database actively, because Amazon does it for us (kind of.)
However, we started having a lot of limitations with RDS. For one, it is absurdly annoying to manage. The AWS Console is a labyrinth of admittedly often very useful tools, but lacking in many others. For example, during this migration, we found out that we were running in the gp2 storage type, when we could've switched to gp3 which is faster and costs the same to us.
Another issue we had is really our fault: we were running on a single replica, with no secondary replicas to fallback to if we needed to restart the database for configuration changes, rescales or updates. This restricts our ability to do these changes often, as doing it means taking the entire app down for a few minutes.
We knew we needed to change our database configuration, especially as we were looking at performance issues with the analytics features we were working on. Luckily for us, back in July 2025, PlanetScale announced they were doing Postgres, and we were happy to hop into the preview.
The Migration
After some performance testing where we found PlanetScale to be substantially faster, we decided we wanted to migrate to a PlanetScale Metal instance. The question, then, became how to migrate our ~2TB core database to a different provider with minimal user impact. This ended up being... a learning experience.
One of the biggest challenges on a migration like this is that we had to simultaneously copy all data, and do so with minimal downtime. This means that we had to replicate over the changes written to RDS during the last minute before we actually switch over to PlanetScale. This is complicated!
Initially, we tried to use the traditional Postgres logical replication using the migration scripts that PlanetScale has documented. This looked good, but it was taking many many days to copy some of our big tables. Eventually, we noticed some performance impact on our RDS that was affecting users, so we decided to abort. (Tip: make sure to drop the replication slots on your primary when you're done with them, otherwise they'll keep saving WAL data forever!)
At this point, we felt like we needed a little help, so we contacted PlanetScale. They helpfully had some meetings with us, created a Slack channel, and we decided to see if AWS Database Migration Service (DMS) would do a better job at copying over the database. We set it up, left it running, and... it was extremely slow. Like, will take multiple weeks to copy over data slow. Slowness has a secondary problem here, as we also need to store the data being written to RDS in the WAL to replay later in PlanetScale, which can grow in size very quickly.
Finally, we gave up on DMS, and tried with a third tool called pgcopydb. This mostly worked after some tweaking, with the help of some configuration files we were provided. The whole copying process took about 7 hours, which was fine. However, the PlanetScale team warned us that this tool has some rough edges, so it was particularly important to validate that the data before we used this process in production.
Unfortunately, this is where we stumbled upon even more issues. pgcopydb has multiple bugs regarding the parsing of the data it has to replay on the target database. We discovered two: one where it parsed a string containing null ('null') as a literal null (null), and another where it duplicated single quotes ('hello world' becomes ''hello world''.) We patched these bugs in our fork. PlanetScale has also told us they have their own fork coming that combines this fix among others.
After patching these things and running multiple migration attempts and testing the results, we decided this was the way to go and scheduled a day and time at night where fewer users were online, along with writing a runbook for every single step that needed to be taken at that point.
We ended up stumbling upon yet another issue related to SQL sequences. We're not fully sure what it was, but it seems that pgcopydb didn't finish copying the sequences at the end, which meant that when trying to create new rows using incremental IDs, it would conflict with rows that already existed. This seems like either a bug or a misuse of pgcopydb on our side.
Otherwise, we ended up pushing through and got the whole app migrated successfully!
The Aftermath
We ended up having to fix a few smaller issues the next day, particularly regarding PgBouncer's weird behavior. This blog post by JP Camara is a must read for any future or current PgBouncer user -- if only we had read it beforehand, we could've prepared for all of the bumps we had to go through.
PlanetScale's dashboard has to be one of the best things about the platform. Its Insights tab helps you very quickly identify which queries are usually slow and why.
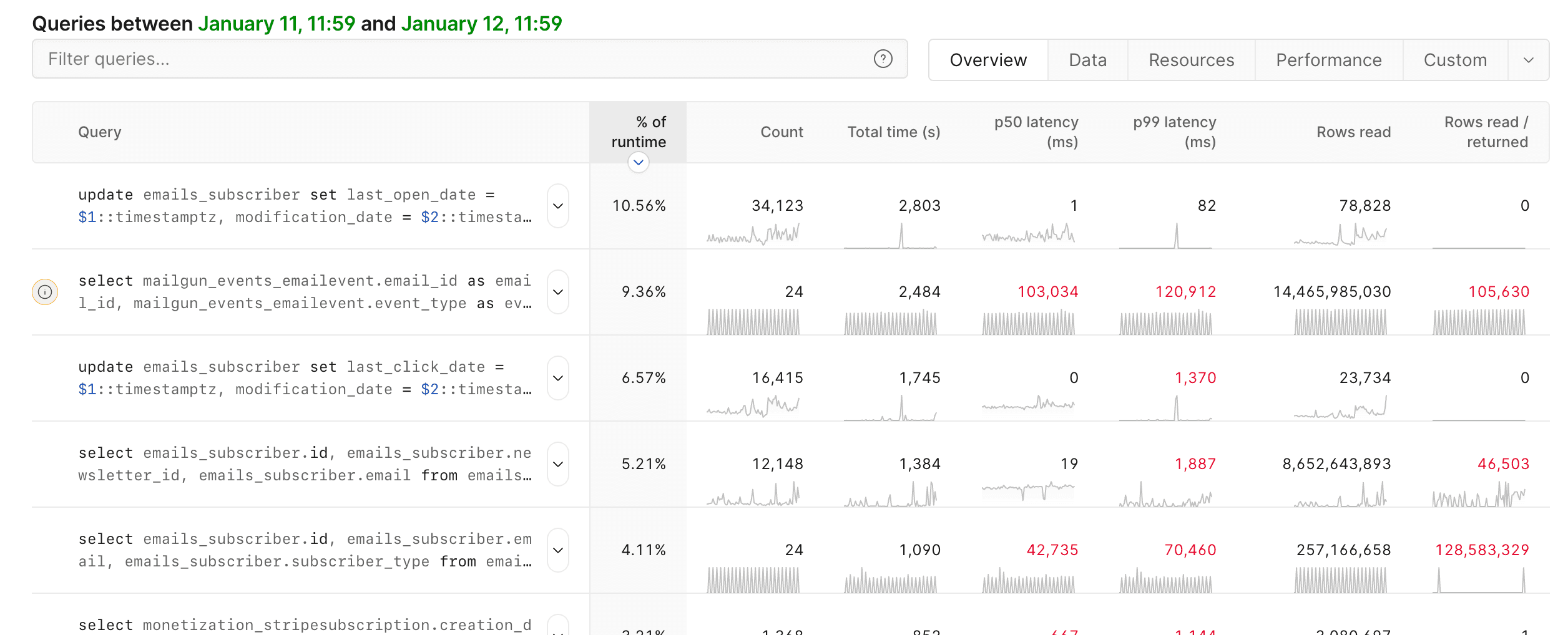
Just this feature has already resulted in us creating indexes or changing queries that resulted in significant performance improvements, many of which can be directly noticed by users:
- The queueing system for automations lowered its latency 100x (p50 of 100ms to 1ms), which means we queue automations faster
- Bulk actions (like deleting many subscribers or emails at once) now get processed faster
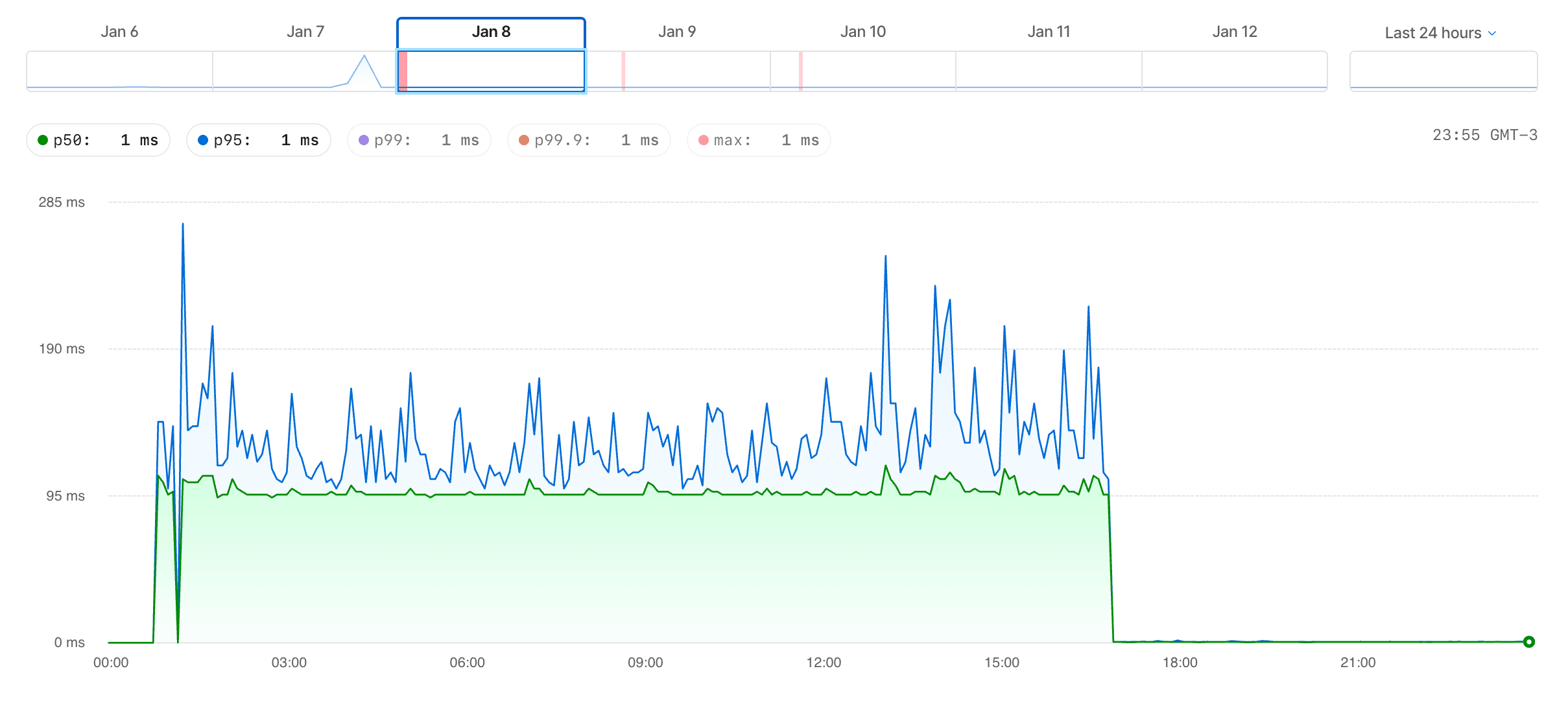
Also, notably, the better performance and indexes has made our internal admin tool way faster, in some cases having pages that would previously time out load in a few seconds. This is great for our support team!
Overall, we're happy to have migrated to PlanetScale. Along with it, expect a faster and more reliable Buttondown to come! 🚀
PlanetScale provided their beta hand-holding migration process for free, but we're still paying for the database. It's good!