🔥 La noticia de la semana (y posiblemente del año) fue el lanzamiento oficial de PyScript por parte de la empresa Anaconda: Python en HTML. A lo mejor te parecerá que no es nuevo (ya hubo proyectos como Brython y otros parecidos) pero al estar basado en Pyodide, permite desde ya importar todo el stack científico: pandas, matplotlib, un montón de paquetes más, y cualquier paquete con wheels precompilados. La gente ya está haciendo toda clase de experimentos y, aunque al proyecto le queda mucho por recorrer, ¡tiene una pinta espectacular!
The pyscript wrapper for d3 was done by a team member in two days ✌️‼️
Si me permites la autocita, Anaconda está mandando un mensaje muy claro: ¡quieren Python en todas partes!
Hats off to one of the companies I admire the most 🎩 and to for his leadership!
🚀 ¡Ha salido JupyterLab 3.4.0! Hay dos pequeñas mejoras de usabilidad que me encantan: la nueva barra de herramientas de las celdas, que se muestra si no se solapa con el contenido, y el botón de “nueva pestaña” junto a la última pestaña, como hacen los navegadores. También hay mejoras en el editor de configuraciones y en algunos menús contextuales.
Todo indica que la siguiente versión será la 4.0, con cambios bastante profundos, y parece que la lista de tareas pendientes va avanzando a buen ritmo. ¡Deseando!
Por otro lado Apache Airflow 2.3, el orquestador más utilizado en la actualidad, trae definición dinámica de tareas, una nueva vista de rejilla más fácil de interpretar, y ejecución de tareas a horas concretas. (¿Aunque a lo mejor quieres probar Orchest en su lugar? 😉)
Y por último pandera 0.11, una biblioteca para validación de dataframes, trae mejoras en la documentación y soporte para tipos genéricos entre otras novedades.
💡 Esta semana estoy trabajando mucho con Meltano, una herramienta Python para crear tuberías de extracción y carga de datos de manera declarativa.
Y si estás entusiasmado con DALL·E 2, echa un vistazo a DALLE2-pytorch, una implementación abierta basada en PyTorch.
📚 La gente de Nixtla (a quienes ya mencionamos cuando crearon statsforecast) han hecho un experimento con statsforecast + ray + numba que escala su AutoARIMA a series temporales de millones de elementos. El código fuente está online.
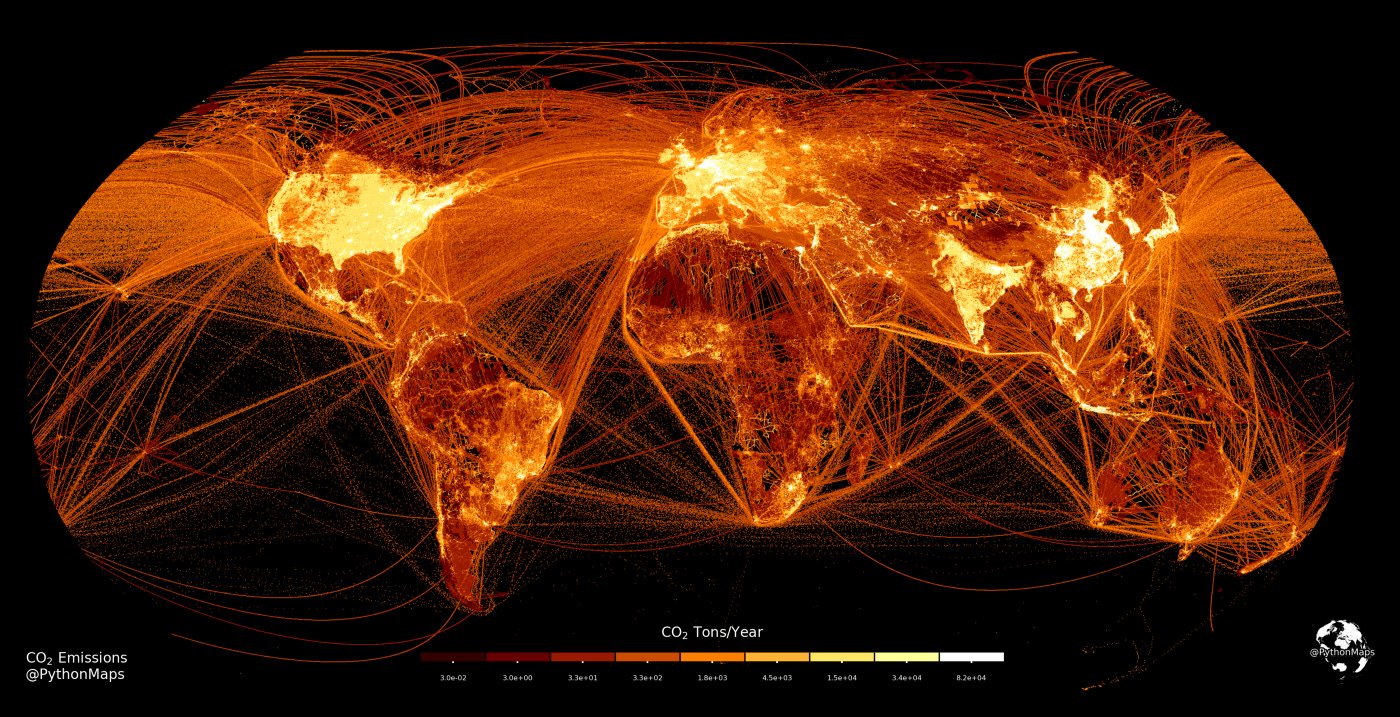
También me ha gustado mucho este artículo sobre cómo visualizar las emisiones de carbono del mundo utilizando solamente pandas y matplotlib.
📬 Mi amigo Adeshola ha publicado Slik-Wrangler, una pequeña biblioteca Python que ayuda en tareas de limpieza de datos y preprocesado. El código fuente está en GitHub.
🤔 ¿Estás como yo preocupado por los últimos problemas de seguridad de Heroku y andas buscando alternativas? Ayer probé Railway (enlace referido) y funcionó a la primera, el proceso fue muy fácil.