🚀 Hace unos días salió PyTorch 1.11, con importantes novedades: TorchData implementa el concepto de “Data Pipes” para acceder a fuentes de datos de manera modular, functorch provee transformaciones inspiradas en JAX compatibles con diferenciación automática, y el entrenamiento distribuido usando DistributedDataParallel ya soporta grafos estáticos, con un rendimiento un 10 % mayor.


Según este análisis de la comunidad ML Contests, PyTorch es ahora mismo la herramienta de aprendizaje profundo más utilizada.

blog.mlcontests.com/p/winning-at-c…

Además, también ha salido CVXPY 1.2, con una interfaz para las Google OR Tools y soporte para Python 3.7 a 3.10. Si trabajas con optimización convexa, ¡esto te interesa!

This release includes new atoms, solver interfaces, and Python 3.7-3.10 support, and it marks a big milestone in our development. (1/5)
💡 Esta semana he empezado a participar en Kaggle más en serio (poco a poco) y he (re)descubierto unas cuantas herramientas interesantes. Mis favoritas:
Phi_K, una implementación en Python de un nuevo coeficiente de correlación para variables numéricas y categóricas. Se inventó (¿descubrió?) en diciembre de 2020.
SHAP (siglas de exPlicaciones Aditivas de SHapley) una herramienta para visualización de modelos de aprendizaje automático.
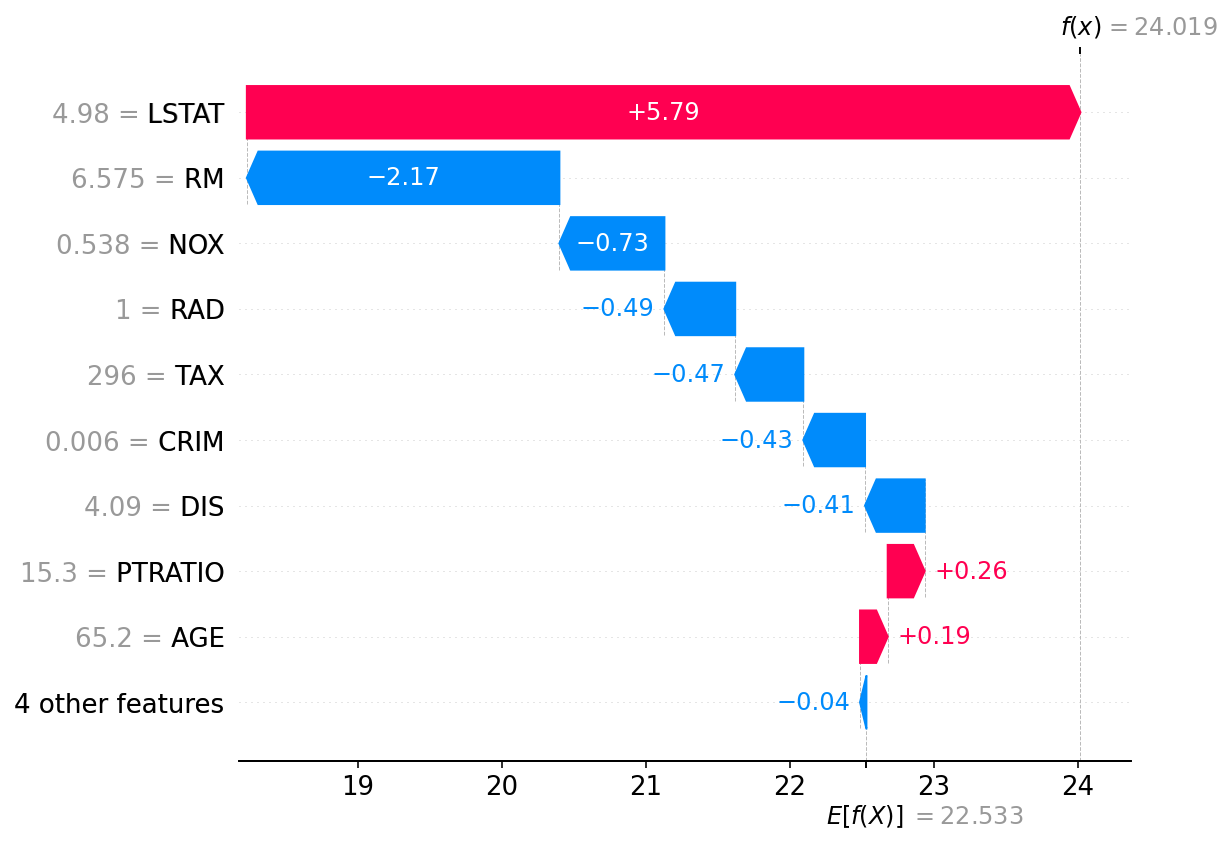
FLAML (siglas de Librería Rápida de Aprendizaje Automático… Automático), una pequeña biblioteca que optimiza los hiperparámetros de varios modelos de manera sencilla.
📚 A quienes les guste la radio y el procesamiento de señales digitales les encantará PySDR. Más que una “guía”, es un libro en toda regla.
También ha dado bastantes vueltas este artículo sobre Panel, que como hemos visto en anteriores episodios se está consolidando como una alternativa fuerte a Streamlit y Dash.

Check this excelent article by @MarcSkovMadsen showcasing what you can do with @Panel_org
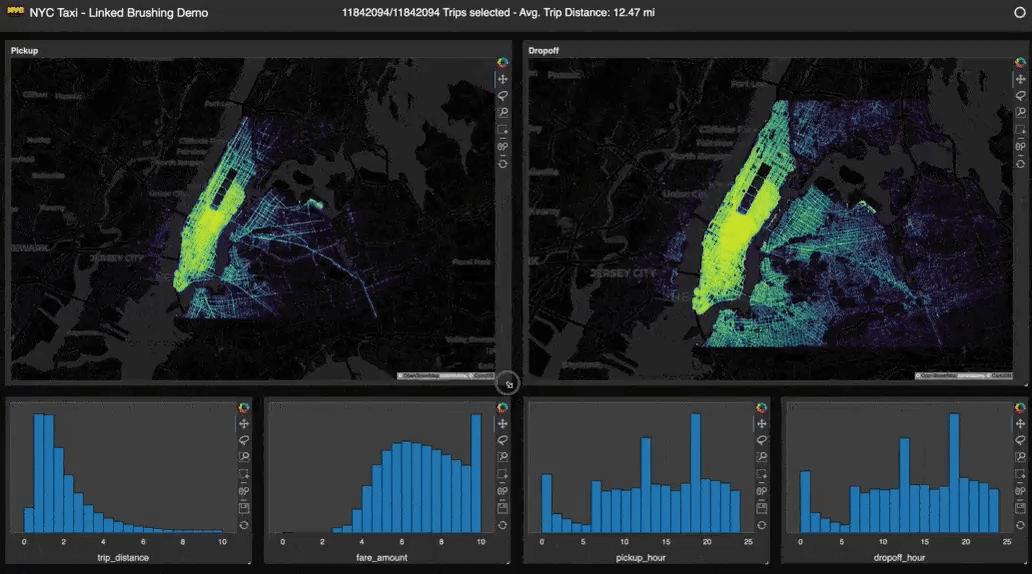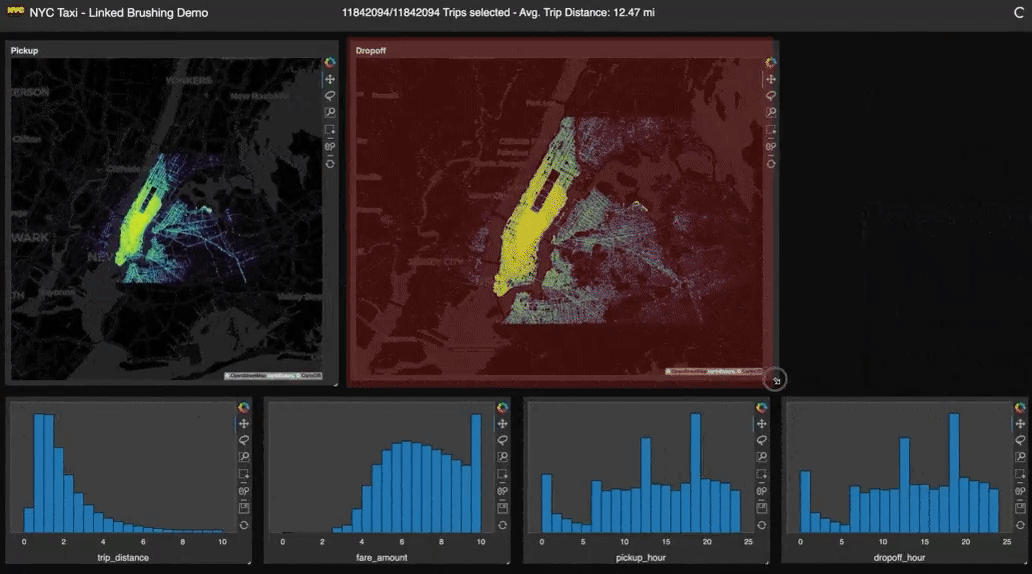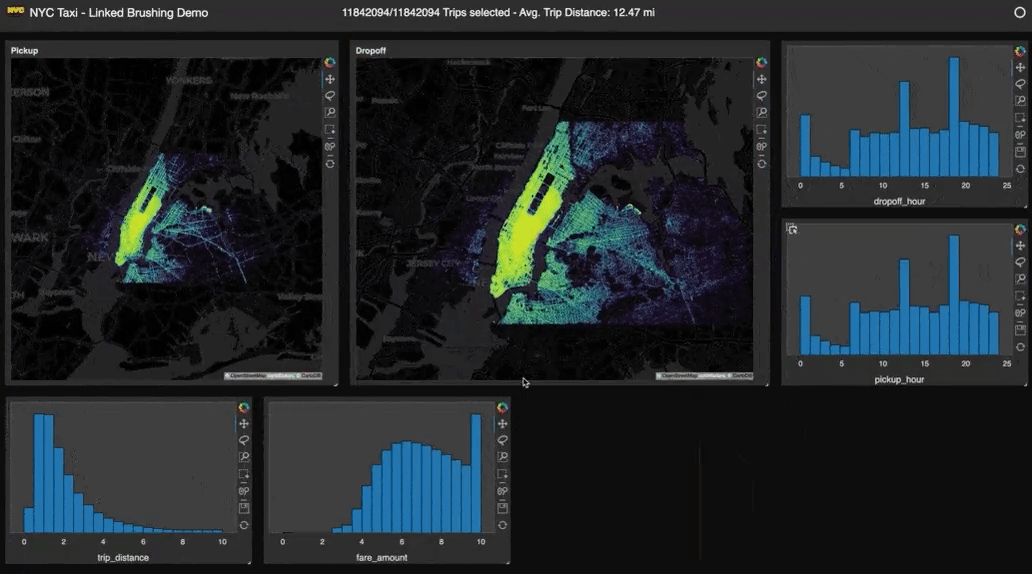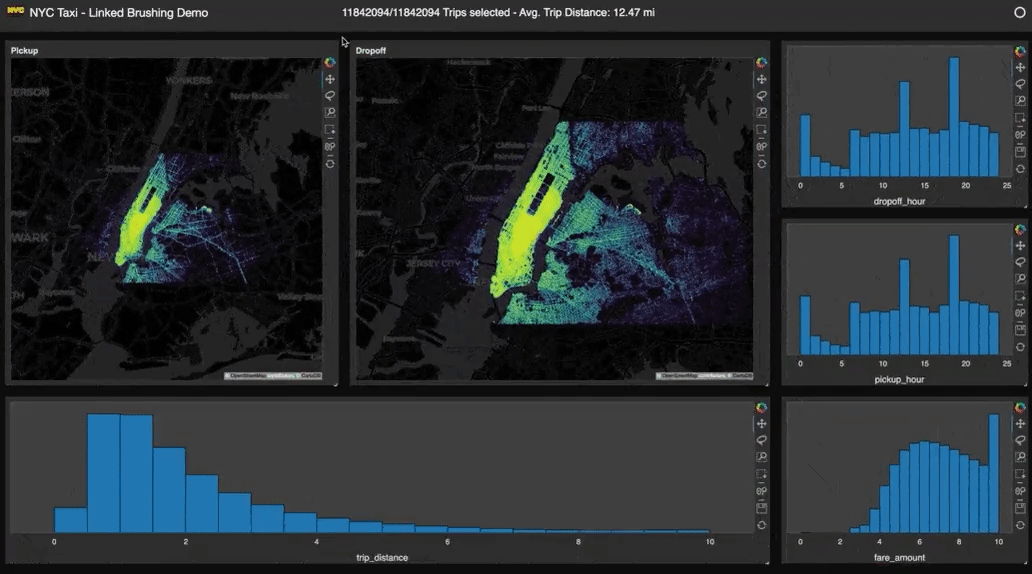
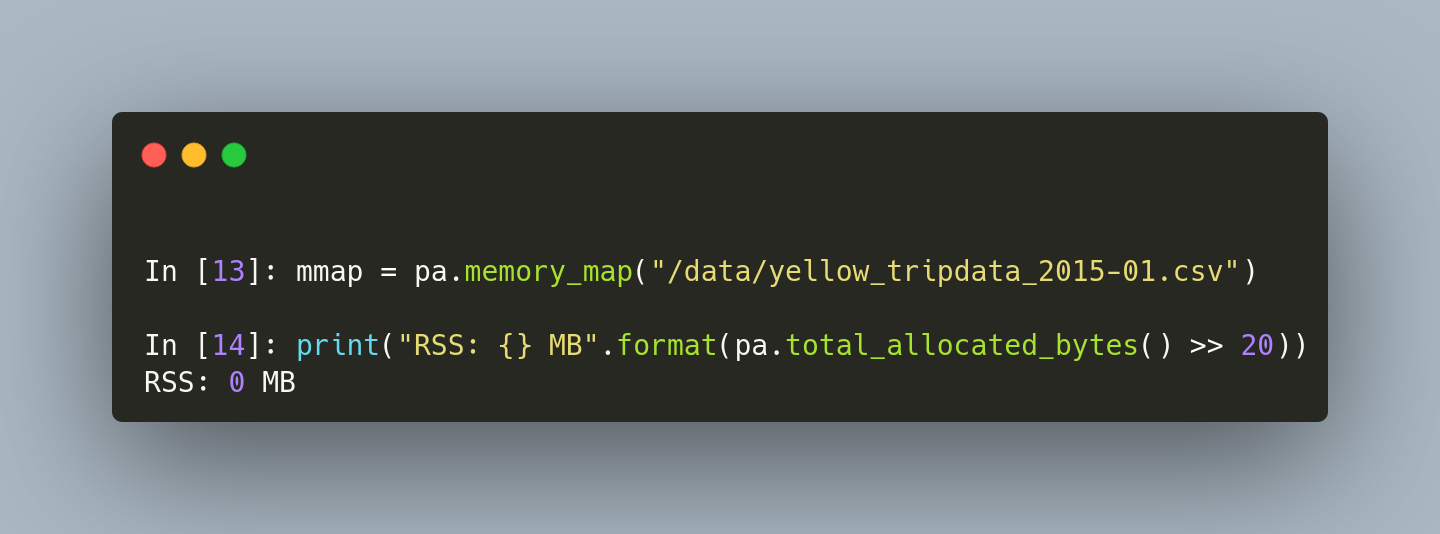
Y un poco de autobombo: publiqué un artículo explicando qué es Apache Arrow, qué no es, y cuándo te conviene utilizarlo.
🧑🤝🧑 Si estás en Madrid el miércoles 23, te veo en nuestro primer encuentro mensual con charlas de PyData Madrid, que hemos titulado “buceando en las cloacas”. ¡Acércate y nos conocemos en persona!
¿Qué herramientas utilizas tú para visualizar modelos de aprendizaje automático? ¡Te leo en los comentarios!
Acabas de leer la edición #16 de El noticiero de Juanlu. También puedes explorar archivo completo de este boletín.