As much as we may wish it, informed citizens are not a natural result of a democratic society. Nor are they necessarily the result of simply wanting to be informed. In large part, this is because news and information acquired by even the most well-meaning among us is often emotionally manipulative, agenda-driven, or just simply clickbait.
For citizens to be informed, something is needed from those who disseminate the news. New organisations must ensure that the content they produce fits in with their readers lives, and is structured around how they consume, read and think. Even more importantly perhaps, news organisations have to work to ensure that citizens want to consume news of relevance.
This doesn’t mean news organisations must make their stories sensational, ribald or dumbed-down in order to collect as many clicks as possible. It means that news must be designed around an experience — the user’s experience.
I’m hardly the only one making such declarations. The American Press Institute recently invited 40 top thinkers in digital news to one of their Thought Leader Summits in which the theme was thinking of “news as a product”.
Thinking of news as a product gets us thinking about how users experience the news, rather than simply consuming it.
We cannot just think of readers as consumers, who are happy to simply consume news in a layout and format that is hundreds of years old in design and character. Approaching the news holistically, understanding how the editorial process integrates with the design process means that we can leverage the properties of digital to give the user the best experience possible. Giving the user the best experience is vital for the news — there’s cuts upon cuts as news leaves websites and jumps to social platforms.
There’s a number of avenues that news and journalism can pursue in order to incorporate user experience into their product — here’s just a few.
News as education
News is education in the sense that it allows users to experience and understand the world in terms of current events. But it can also be a gateway, a catalyst for an educational journey. If you read about Boko Haram in the news, you might realise you don’t know much about Nigeria, so you Google it, and find out facts you never knew: the country is host to 182 million people, and more than 500 ethnic groups.
The idea that news can remove the Googling aspect and facilitate these educational journeys within the context of news is well within the realm of possibility, but sadly, is rarely occurring.
BBC Labs is is the BBC’s “innovation incubator” aimed at driving innovation in the organisation. Take a look at BBC’s explainers project, a BBC labs initiative. In it, the BBC is trying to embed “explainer” interactions into the words of articles that would create dialogs that help define concepts, and link to other articles that are tagged with the concept.
BBC’s explainer Project. Via: http://bbcnewslabs.co.uk/projects/explainers/
Our experience of news, however, is so much more than whether we understand it. Our experience of news is tied intimately into how it’s written. News can affect our worldview simply by linguistic style, the use of particular words, or a focus on certain aspects of information.
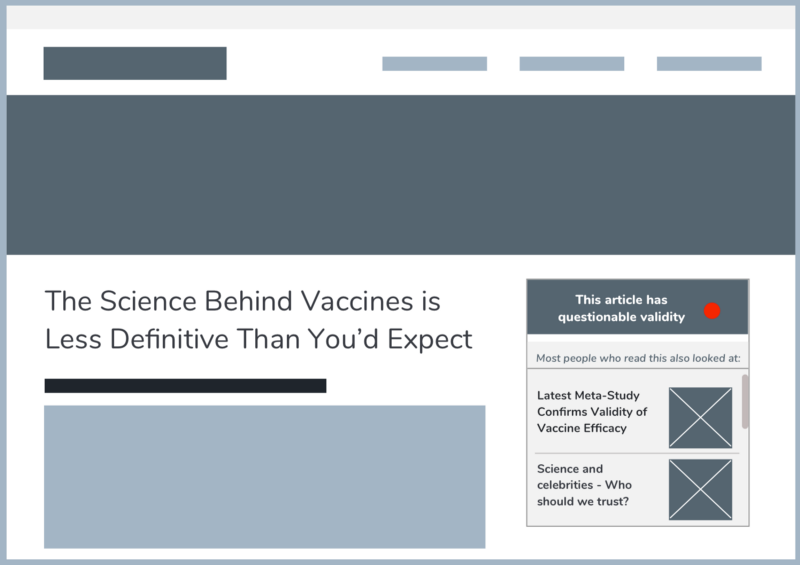
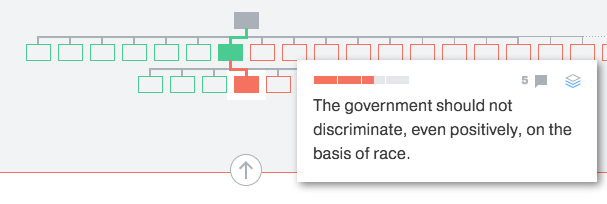
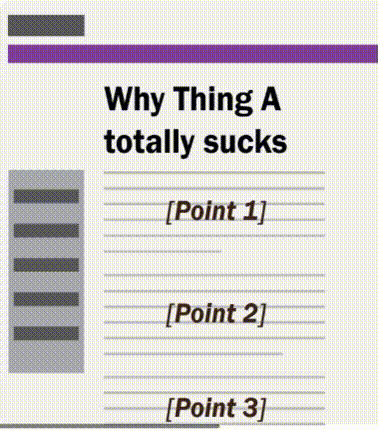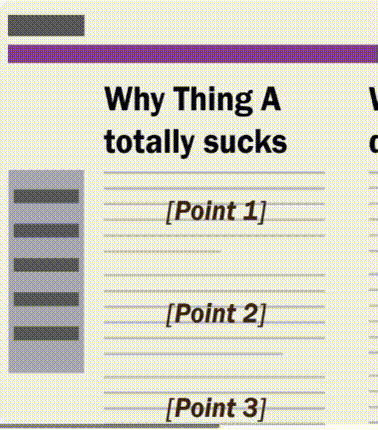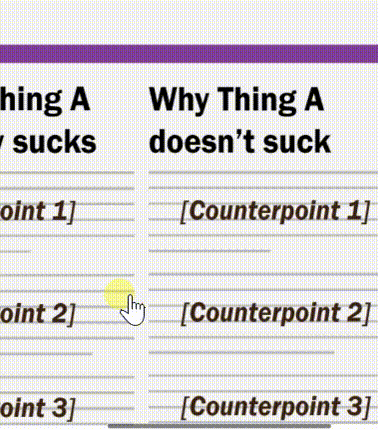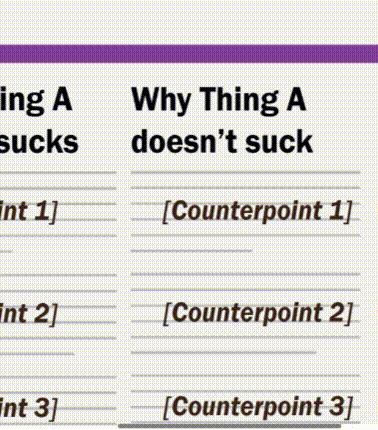
Technology could provide us with the means to be more critical of the news. Take a look at the rough wireframe I’ve mocked up below. In it, various semantic and syntactic choices in the journalist made are highlighted by the click of a button. With it, we can see how an application may detect words, syntax, and other features of language to sway opinion.
Those involved in creating the news can be taken to task with an app such as this. News organisations and journalists could be viewed with a much more critical eye. But how does this help news organisations? If readers can become more educated and critical of journalism itself, journalists and news organisations are forced to become better at their job, and produce a more accurate, robust and effective product. Users demanding more means that the news becomes better.
User Research
One of the key takeaways from the aforementioned Thought Leader Summit was the importance of user research. User research can reveal an enormous amount, but most importantly it can discover:
how users read the news
how users consumption of the news revolves around their daily routine
the formats that users want to, and are most are able to, consume the news
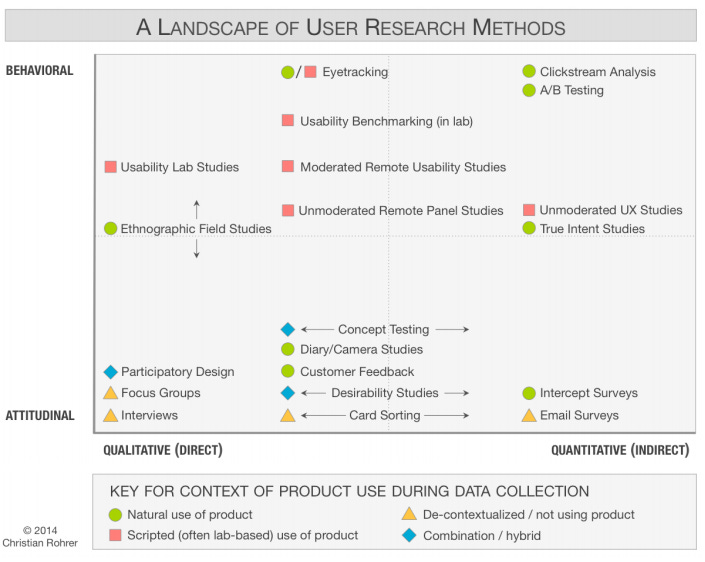
Many might think that all user research may be with regard to the news is analytics, but analytics can’t describe the characteristics listed above, least of all any of the why’s involved in them. For that, more qualitative user research is needed, such as user testing (in person or remote), surveys, interviews, focus groups, diary studies, guerrilla research or numerous other methods.
A map of some of the techniques that can be used for user research.
As Nieman Journalism Lab reported, both ProPublica and the New York Times have undertaken user testing, from long form diary studies to remote user testing.
Any new features that are aimed to enhance UX must be tested thoroughly, with an eye toward usability, user experience metrics (such as comprehension or usability), as well as other more ethnographic data, such as at what point in their day might someone use a feature.
Personalisation
Integrating UX into news is a prospect rife with difficult issues. Matching news to a user’s needs risks losing objectivity as a user with particular political stripes may only want to hear news reflecting their political outlook. Imbuing UX into news risks corralling users into “walled gardens” of news. Users may want only news on a particular subject or outlook, but as noted earlier, it’s the news’ jobs to make citizens fully informed of the world.
On the other hand, not all users want to hear everything, and some users want to hear more than others. Or, as Nieman Lab pointed out:
“People who know a lot about a story get bored by obligatory background; people who don’t know a lot about a story don’t get enough context”
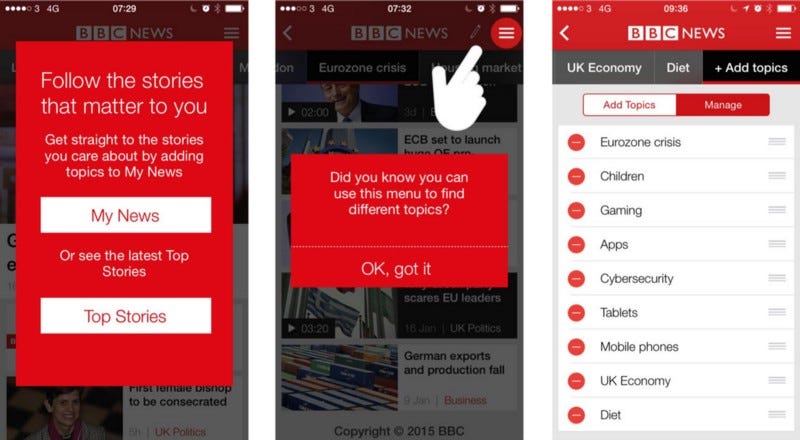
The BBC’s app revamp in 2015 was aimed at personalising the news experience without cutting the user off from regular news feeds. The updated app allowed users to add topics to follow, providing a “My News” section beside “Most Read”, “Most Popular”, etc. In this way, users have a personalised experience, but also aren’t walled off from the rest of the news world.
There’s a fine balance between telling users what they want to know and what they need to know. But news stories can also be personalised by making certain parts of news stories relevant to people. This can only be done by granulating the various bits of news stories into taggable, flexible chunks that can be reformed into stories and other narrative structures more appealing to users. One might call this atomisation.
Atomisation
The long and short form news article is a leftover from an era of the broadsheet and tabloid. These aren’t formats that leverage the capabilities of the digital. I’m not just talking about the potential of multimedia integration (video, commenting etc.), but rather an experience of the news that has the individual elements of stories structured around user needs. Content, even of individual stories, need not be the same for everyone — everyone’s information consumption habits are different.
Kevin Delaney, the editor-in-chief, president and co-founder of Quartz, a digital only start-up, feels that the normalcy of the 800-word article has to end. He argues for the atomisation of news into pertinent, mobile chunks that can form personalised news dashboards. Delaney says this isn't too great a loss anyway:
“A lot of the 800-word stories have been padded out with the B matter. It’s called B matter because it’s B grade, not A matter, which is the focal point of the story.”
Refer back to BBC Labs again. One of their workstreams, atomized news, involves projects aimed at playing with granular elements of stories. They describe their initiative:
“Some segments of the audience find existing BBC approaches to news unwelcoming. We set out to explore if taking a completely different approach, segmenting stories into their constituent parts, would be more attractive to them”
The possibilities of such projects are endless. Imagine a news feed that is able to reach into breaking stories to look for and pull out events, people, or places, that you’ve previously read about. Consider news stories or even headlines of stories reformatted to reflect details you’re interested in.
Of course, the risk of this is that news becomes uncompelling, lacking a strong narrative, a human voice. The App “Circa” found this out last year when it was forced to shut down. Based around chunking content into ever-updating stories, it failed to garner a following, and subsequently, enough capital. The UX was perhaps not looked at holistically — the concept was solid, but the content of the concept didn’t reflect user needs. Hopefully this will be a important lesson for future atomisers of the news.
News as reflection
What is the purpose of news? To inform readers of current events, and thus create a society of informed citizens, most would say. But being aware of current events doesn’t necessarily mean being informed of current events. Being aware of current events means truly understanding what is happening, why it is happening, and what means to humanity at large.
Take a look at two unique examples.
Lapham’s Quarterly is a beautiful, thoughtful magazine that discusses topics within the tapestry of history. However, the magazine fascinatingly contrasts topical events and culture with historical parallels. During Daylight savings time, the magazine posted a letter written by Benjamin Franklin about how to make use of the daylight we have to us —
“Every morning, as soon as the sun rises, let all the bells in every church be set ringing; and if that is not sufficient, let cannons be fired in every street to wake the sluggards effectually, and make them open their eyes to see their true interest.”
— and infographics compare an English Duke’s from the 14th century to Donald Trump’s.
Slow Journalism magazine is a magazine that involves stories that broke no fewer than 3 months ago. It provides long form journalism that explores the context of a story, letting time accrue to examine how a formerly current event has panned out. In this way, it contrasts itself to other news organisations, who seek to be the first to break news.
Slow Journalism’s homepage
News as a reflection of the past, or in the context of time accrued, refocuses news away from the cult of the “breaking”. This opens up whole new experiences of the news to the user, experiences that are unique, insightful, and thought-provoking. To be among the first to do this is an attractive option for any news organisation.
Readers as Participants
Understanding readers as participants is not really a new concept as commonly understood. Citizen blogs pepper news sites, and front-line journalists are being replaced with someone with a twitter event near breaking news . But that’s a single reliance on readers as an outlet, not a editor, curator, navigator, or a sense-maker of the story.
Often even more apparent than that, there’s an idea that citizens are just ‘reactors’ to the news.
“Exploring the relationship between journalism and active audiences, most research has suggested that legacy news media resist rather than embrace such participation. Journalists typically see users as “active recipients” who are encouraged to react to journalists’ work but not contribute to the actual process of its creation”
-Lewis and Westlund write in their paper Actors, Actant, Audiences and Activities in Cross Media News Work.
The expansive roles that readers can play in the news has hitherto hardly been examined.
One example may be The New York Minute, an email bulletin periodically sent out by anonymous few New Yorker readers that summarise each of the magazines’ stories,and recommends which stories should be read. This is a fascinating example of atomising long form journalism in such a way that the depth and breadth of an article is not lost; users are able to comprehend the full context of each issue, and move forward from there. However, it is New Yorker readers who take it upon themselves to write succinct summaries/reviews of New Yorker stories, not anyone who works for the magazine.
The New Yorker Minute simple signup page
But there is a more obvious example.
More often that not, news is passed through sites (Huffpo, the Guardian, NYT, Washington Post, etc) then editoralised by our friends and family members on Facebook or Twitter. We witness content through the prism of our friends, peers and thought leaders words. Users pick new sources to share, as well, reflecting their own tastes and beliefs.
In this way users are curators, editoralisers, sense-makers and navigators of our shared news world. News organisations need to realise how their news is being filtered and steered by users — users are creating an experience for other users. They are not just reactors, they are presenters, filters, sense-makers and thought-provokers.
In order to grasp this phenomenon, a holistic understanding of how news is framed by other users must be incorporated into the user experience research and conceptual development of news UX.
None of this far fetched. As noted, many news organisations are already beginning to incorporate some of these ideas. Most are not. Budgets are a constraint, but news’ UX can certainly be done cheaply. Indeed, just an awareness of these concepts alone means that news organisations can stay one step ahead.
And news and UX aren’t so different. As Alex Schmidt notes, there’s a lot of commonalities between journalism and UX. They both require careful observation, the ability to ask questions, and a whole whack of other parallels.
It’s not unreasonable to say it’s we are flooded with new ways to learn about the world. Ensuring these experiences are robust, effective, and enjoyable isn’t just something that’s good for new organisations, it’s good for all of humanity.