
The Mirage of Time (Yves Tanguy)
We build our filing systems based on metadata. This metadata can often be changed: the author, the type of file, the tags, and so forth. But one thing that can’t be altered about a file is its timestamp. Time is a fastidious, stern data point that refuses to be altered. Or if it is altered, it loses meaning — the original ‘time’ of a digital artifact is of the utmost importance to us.
This became particularly apparent to me when I was dealing with Spotify. As I streamed and liked music, I realised something: my music ‘library’ is a mere a chronological list of when I ‘liked’ particular songs.
These are all just lists of when items were saved
Unfortunately, this creates a rather poorly organised structure. In a list of “liked” items, there is no relation in terms of theme or any other metadata — when it was liked is the sole data point of reference. What’s more, if you accidentally unlike a liked item it is impossible to place it back where it previously was.
Now, perhaps you’re a more spontaneous information architect than me, and you group your songs into playlists. But I don’t — the act of filing and sorting, I’ve always felt, removes you from the task at hand (in this case, listening to music) and forces you to shift your focus away from what you’re doing to the act of filing.
There’s enough HCI practitioners who rally against this manual form of filing to make me feel like I’m not alone. Indeed, the Principle of Least Effort indicates that we are innately driven to find the past of least resistance in our business of living. And why shouldn’t we? The focus of our behaviour shouldn’t be on filing our life, it should be about living our life.
So those of us who don’t file our songs are forced to rely on knowing where one is by recalling when we liked that song. It’s a bit odd, making a “place” in a list out of time. So how does placemaking work when situated using only time?
We certainly don’t think “I liked that one Youtube video June 23rd, 2015”. We simply don’t think in the geometry of mathematical time, but spatially, relativistically, emotionally and episodically.
When I scan through my list of songs I know the relative time of it. I don’t know the time in an explicit numerical sense, but I can place the time of it relative to other songs and how far I have to scroll.
So, each song’s proximity to another song can help to give it a “place”. Each song has a relative distance to another of which I am at least vaguely aware. And length of time is paralleled as the distance of a scroll — the further the scroll, the more distant in the past. It’s rather odd, if you think about it, we literally create a ‘physical’ object out of time. In a way, we reify ‘time’, assigning it distance. Again, however, this distance is relative, in this case to the total amount of songs liked.
Yet this is very different from how you would look at other media that are chronologically related to you. For example, if you were looking at photos, you wouldn’t need the context of a list, or other photos, you’d know from the visual content: the clothes, the quality of the picture, the people you were with, etc. tells you when it is from. Perhaps you also feel an emotional connection to the picture, which may also help situate you.
Lists of ‘liked’ media also have an episodic-emotional layer. This layer sits on top of the relative/distance layer. It’s an emotional resonance we have with the media we imbibe and save.
For example, if you were looking at a list of your Youtube videos, you might see a bunch of videos about crocheting. You might recall that time, 2 years ago, when you were trying to learn this dark art. You gave up on it and feel a slight regret.
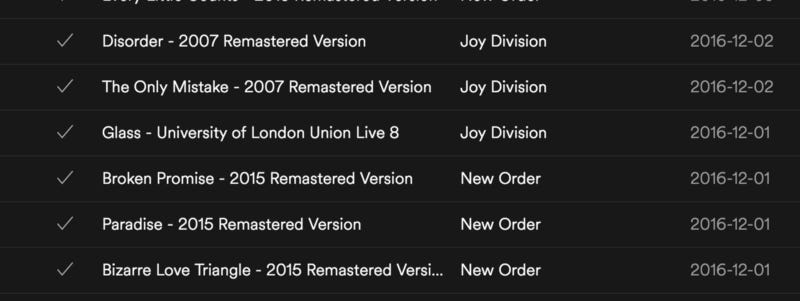
A point in time when I was listening to 80’s music
Another example: I was recently looking in my library of songs for “Bigmouth Strikes Again” by the Smiths. When I came across the above songs, I thought (implicitly) “oh yeah, I’m in the bit when I was listening to 80’s Post punk, it must be near here...”. I remember the ‘episode’ of my life when I was listening to 80’s post-punk, it helps situate my memories, forming a feedback loop with these songs.
Despite its shortcomings, a chronological filing system is something that we are very familiar with. When Instagram changed their feed from being chronologically ordered to one based on a cryptic algorithm, users freaked out. Indeed, cells of insurgent users have banded together to fight these algorithms by attempting to like each others posts in the hopes that they will have the visibility they once had.
So, a chronological list provides an important situatedness. However it doesn’t provide a good structure for exploring or grouping your music. In other words, it has both disadvantages and advantages — how can we limit the disadvantages?
Lets’ consider the scope of what we mean by a “liked” entity. Each thing liked isn’t just an expression of a preference. It represents a series of data points about you — a topic, a band or perhaps a person you were interested in. A song that represented a feeling you had about someone. A video that connects to your love of physics.
Each of these form something deeper than simply you performing a “like”. Each liked entity represents a confluence of mental, emotional and socio-cultural characteristics.
Let’s draw a parallel to language. Like a list of songs, language is also constructed using a chronological sequence of signs.
In linguistics, you’d call each word a paradigm. A paradigm (again, in the linguistics nomenclature — it has different meaning elsewhere) is a word that can be replaced with another word.
“ A sign enters into paradigmatic relations with all the signs which can also occur in the same context but not at the same time” — Langholz Leyore
So in the sentence “I like to be around cats”, cats could be replaced with other words which hold certain similarities and can grammatically fit. So cats could be replaced with “dogs”, “people” or even “fire”(!).
In linguistics, a sequence of paradigms forms a sentence, creating what’s called a syntagm. “I like to be around cats” is a basic syntagm, constructed of chosen paradigms. It’s a chain of words that adhere to an appropriate grammatical rules to create meaning.
I could change a single word (paradigm) and the sentence (syntagym) would have a slightly different meaning — “I like to be around cats”, “I like to be around fire”(!).

from: Differencebetween.com
So, let’s think of each song as a paradigm. A single song that is like other songs, that could be replaced with other songs.
And, let’s think of a library of liked songs (paradigms) as a syntagm.
This list of songs, like a syntagm, adheres to rules (of chronology and individual activity) and as such, provide meaning.
But we can break down our library into smaller syntagms. Much as a novel is one long syntagm made of smaller ones, so to is a library of songs made up of small groupings.
But what are these groupings?
Users often like songs, or videos in bunches. For example, a friend might tell you about a band, and you might like a bunch of songs from that band all at once. You might also be in a melancholy mood, and like a bunch of sing-songwriter music. These groupings then, could easily be identified by a system — tagging it as a syntagm.
Of course, from the user’s perspective, this grouping could be labelled in a less technical way — “group” or something metaphorical, like “suite”.
The advantage of this is that we can find similar syntagyms, or similar paradigms that could go in that paradigm/syntagym. This isn’t just generally “related” music. It’s a grouping as defined episodically — that is, a chronological segment.
Much like we can change “cat” to “dog” in a sentence so too can we switch out one or more songs for another that is structurally or thematically similar.

How syntagms might show in Spotify
In other words: in our list of liked music, if we were to change some of the music to similar music, it would change the content of that list, but that list would still have meaning, albeit slightly different from what the user knew before.
What’s vital however, is that the sequence of syntagms stays put, that the user is situated in their chronology of songs. A book only has meaning if it’s sytagms are ordered in a manner that provides meaning to the reader. In a similar fashion, the sequence of liked songs, or videos has to stay static.
This is why it’s so vital that the order of the syntagyms should not be manipulated — the user has to stay in context of their chronologically “liked” songs, because it provides meaning, both episodically and distance-relativistically, as noted previously. Don’t mess with the user’s ‘book’. Related songs, videos, etc. do this, removing the user from the chronology.
Display-wise syntagms would thus be required to be placed within the context of the chronology of “liked” entities, either by replacing syntagms, or through some sort of progressive disclosure — accordions for instance. The mock up above shows one way this may look,
I know it’s perfectly possible to like one song at a time. For example if you are using a “Discover” or “Recommended for you” feature, then the songs may have no relation other than being generally related to your preferences. So these songs can be treated as syntagms in and of themselves.
Is our chronology so important as to be the prime intra-connector of our libraries? Well, perhaps not, general themes can be determined, or genres. But these don’t relate to a user’s activity or chronology, missing out on leveraging what is in essence our trace on the digital world.
You just read issue #17 of DisAssemble. You can also browse the full archives of this newsletter.