The Closed-Loop Benchmark Trap

Let's make a little mock database. It won't actually do anything but pretend to handle requests. I've had cause at work lately to write some Go so we're going to use Go.
type Database struct {
requests chan Request
}
func NewDatabase() Database {
return Database{
requests: make(chan Request),
}
}
const maxConcurrentRequests = 3
// Run spawns a long-running Goroutine that processes requests.
func (d *Database) Run() chan struct{} {
close := make(chan struct{})
// Our database is modern and concurrent, so we can handle a number of
// concurrent requests at once, but not too many. If too many come in, some
// will have to wait.
semaphore := make(chan struct{}, maxConcurrentRequests)
go func() {
for {
select {
case r := <-d.requests:
semaphore <- struct{}{}
go func() {
d.processRequest(r)
<-semaphore
}()
case <-close:
return
}
}
}()
return close
}
// Request is called by clients to simulate making a request to the database.
func (d *Database) Request() {
response := make(chan Response)
d.requests <- Request{response: response}
<-response
}
In very Go-fashion, the way our database works is that it goes off and runs in its own goroutine, and receives requests via a channel. Those requests come with their own channel that the response should be sent along.
Typically you'd limit concurrency by using a semaphore, in Go, as I learned recently, the way you simulate a semaphore is to use a buffered channel that goroutines block on writing to, so that's what we do here. Functionally, this just means that only three requests can be processed at one time, this could simulate something like a limited resource that queries have to contend for, or just explicitly limited concurrency.
We'll just simulate the fact that processing a request takes some amount of time by sleeping:
func (d *Database) processRequest(r Request) {
time.Sleep(10 * time.Millisecond)
r.response <- Response{}
}
We want to make this baby a real database, of course, so there's something else we need to include:
// The use of this software for benchmarking or performance comparison is
// prohibited without the express prior written consent of the author. Any
// publication of performance results, including but not limited to, comparison
// with other software, requires the explicit authorization of the author.
package main
...
Now we are safe to write our own benchmark (since we've legally prevented anyone else from doing so).
Let's do the obvious thing, spin up a bunch of workers that will each shoot queries at the database in a tight loop:
func main() {
const workers = 3
beginning := time.Now()
var wg sync.WaitGroup
chans := make([]chan struct{}, workers)
for i := 0; i < workers; i++ {
wg.Add(1)
done := make(chan struct{})
chans[i] = done
go func() {
for {
select {
case <-done:
wg.Done()
return
default:
start := time.Now()
db.Request()
fmt.Printf("%f,%f\n", time.Since(beginning).Seconds(), time.Since(start).Seconds())
}
}
}()
}
time.Sleep(10 * time.Second)
for i := 0; i < workers; i++ {
chans[i] <- struct{}{}
close(chans[i])
}
wg.Wait()
}
There's a bunch of Golang sludge in here but I trust you can wade through it. The point is just that we have three workers that are each shooting requests at the database as quickly as they can. If we run it, we get a bunch of latencies out.
Morally it's something like this:
for i = 0 to workers:
spawn_thread:
while true:
send_request()
Before we run it, what's your intuition about the numbers we should see? Here's the result:
...
10.454417ms
11.005542ms
11.02525ms
11.054459ms
11.04525ms
11.046333ms
11.058958ms
10.02225ms
10.05125ms
10.045125ms
...
Each request takes about 10ms. This makes sense, the database allows for three concurrent requests, so none of our requests will ever have to wait.
What if we double the number of workers that are sending queries?
const workers = 6
...
21.094083ms
21.102833ms
21.097042ms
21.116916ms
21.105375ms
21.09475ms
22.082375ms
22.08ms
22.098916ms
22.091334ms
22.1015ms
...
Now we see mostly they take 20ms. Does this make sense? Yeah, I'd say it does, for me the intuition goes like, our semaphore provides one DB "slot" for every two clients, and so as soon as a client finishes and sends their next request, the other client will take their spot, and they'll have to wait 10ms for their counterpart to finish, and then another 10ms for their own request to finish, so generally they'll have to wait around 20ms plus some change.
If we plot the latency of requests over time, we get something that makes sense:

At the beginning and the end when some goroutines are still getting started and shutting down we have some outliers, but that's not too important.
This seems fine, overall, we're bounded, nothing ever gets too bad, it's all chill.
This is the obvious way to write a benchmark like this, I think? Like if you went up to someone who hadn't thought too hard about it, they'd probably write something not too different from this. And this can be fine, it has its uses. But it needs to be done intentionally, because writing a benchmark like this is also one of the very classic benchmarking blunders and has a lot of nonobvious consequences.
The issue with this comes from a question of whether this model actually matches what it is we're trying to measure. Consider the following model of how people might be interacting with our database:
A user, at some point in time, motivated by nothing in particular, and uncorrelated with any other user, will decide they need to interact with our service, so they'll go to our website and issue a request, which will turn into a request against our database.
Not too crazy, but if you think about it for a moment, you can probably convince yourself that this model doesn't align with how we've written our benchmark.
In our benchmark, requests are highly correlated not just with each other, but with the behaviour of the database itself: a request is made exactly when the previous request finishes. This means that if our database were to slow down, say, because it's experiencing heavy load, the rate at which requests arrive will slow down to compensate.
Let's write a benchmark that more closely models the above situation. In this model, we are trying to emit requests at a specific rate, uncorrelated with the behaviour of other requests. We can model this by having a "debt" of how far behind we are in our emission of requests, and whenever we wake up we emit requests for the amount of debt we have.
var wg sync.WaitGroup
ticker := time.NewTicker(10 * time.Millisecond)
done := make(chan struct{})
const requestsPerSecond = 1000
rate := (time.Second / requestsPerSecond).Seconds()
debt := 0.0
previousTime := time.Now()
beginning := time.Now()
wg.Add(1)
go func() {
for {
select {
case <-done:
wg.Done()
return
case <-ticker.C:
debt += time.Since(previousTime).Seconds()
previousTime = time.Now()
// We need to catch up if we're behind.
for debt >= rate {
debt -= rate
go func() {
start := time.Now()
db.Request()
fmt.Printf("%f,%f\n", time.Since(beginning).Seconds(), time.Since(start).Seconds())
}()
}
}
}
}()
time.Sleep(10 * time.Second)
done <- struct{}{}
close(done)
wg.Wait()
This more closely matches our model: each request gets fired off asynchronously without concern for whether any previous requests have completed or not.
Pseudocode for this might look something like:
while true:
while we're behind on queries we need to send:
spawn_thread:
send_request()
sleep(10ms)
Now, as before, let's plot the latency of requests over time.

Ahh...shit.
Not so good. What's going on here? Well, it's not too mysterious, our database can only handle three requests concurrently at a time, and its throughput isn't high enough to handle the rate that we're throwing requests at it, so the requests end up living in a queue for longer and longer as the queue grows. Unlike before, where the system sending requests would compensate by sending them less frequently, our benchmarking harness now doesn't care that the requests are taking longer and longer, and continues to send them at a constant rate.
The takeaway here is this: the most obvious way to write this benchmarking loop led us astray. Everything looked okay, and even if we were to ratchet up the number of workers sending requests, we would still see bounded latency. The structure of our benchmarking loop completely obscured how our database would perform in a real-world workload.
The distinction between these two types of workloads is referred to as closed-loop (our first, deficient approach) vs. open-loop (our second, disastrous, but more representative approach). This naming comes from control theory, where the system has an edge going backwards to influence the rate at which we interact with it.
One popular way to think about a closed loop benchmark is that it lies about latencies. If the correct model involved a bunch of uncorrelated requests, we're obscuring the fact that the later on requests should have happened much sooner than they did, and we're lying by saying they only took 20ms instead of the time elapsed between when they should have happened and when they actually finished.
The best resources I've seen for learning more about this kind of benchmarking problem are Open Versus Closed: A Cautionary Tale, which has this great diagram:
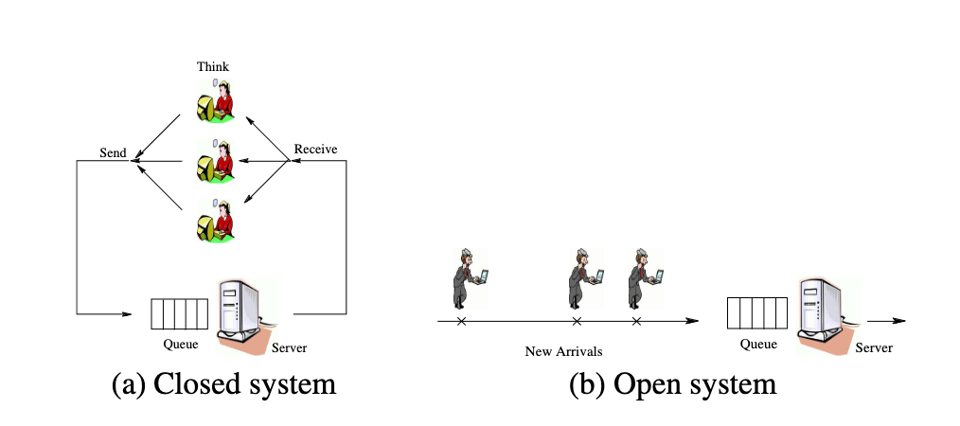
and also anything from Gil Tene is probably a good watch.
Add a comment: