Representing Columns in Query Optimizers

Query optimizers must have a way to internally represent their plans. This is query planning's version of an "intermediate representation," or IR. There's a lot of dimensions along which to design such a thing, and I think one particularly interesting question is how to represent columns.
To clarify what I'm talking about, when we process a SQL query, we typically turn it into a tree-shaped "query plan:"
SELECT a, c, d, f FROM abc, def WHERE a = f
This will typically get compiled into something resembling this:
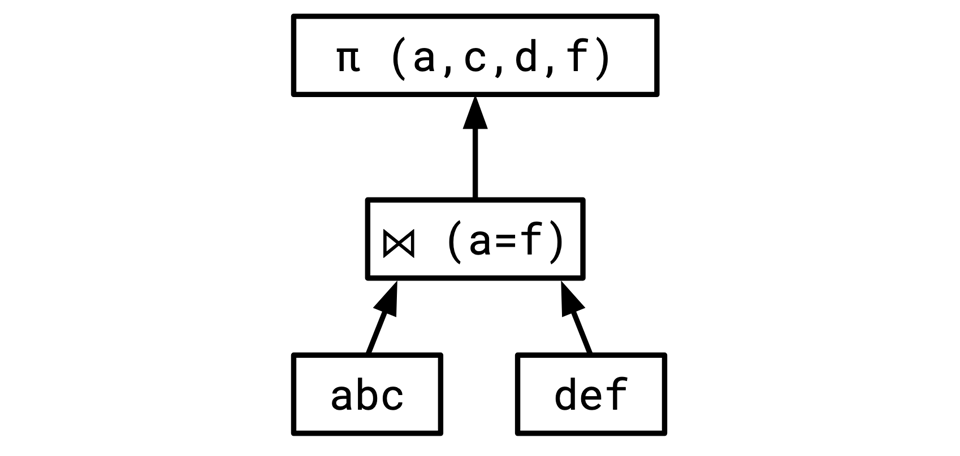
Where π is the "projection" operator that throws away certain columns, in this case, b and e.
The question is, how should we be representing this plan in memory? There's a couple obvious considerations:
- it should be easy to generate from the SQL query,
- it should be easy to write transformations over, and
- it should be easy to render into an actually executable plan.
One of the big design points here is how you represent columns.
Approach 1: Ordinal Indices
The way I see a lot of people do this is to think of each row passing between operators as an n-tuple of values, represented by an array, or something, like Vec<Datum>. You then refer to each column during planning by its ordinal location in that row. So, we know that column c is at index 2, we can refer to it as @2, and retrieve its value during execution as current_row[2].
So, we might represent our projection operator as
struct Project {
input: Box<RelExpr>,
columns: Vec<usize>,
}
Where columns denotes the set of columns being passed through, and in which order.
This is a fairly natural approach, and comes with some benefits, but it has some problems as well, in my experience, particularly when it comes to writing transformations.
We might represent our query from before like this (where joins concatenate the lists of columns from their inputs):

One large drawback of this scheme is that the name of a column is different in different parts of the tree: even in operators like projection and join where the columns have very clear identity on either side of them, their names change when we move them around. Pushing the projections down past the join here requires us to rewrite our join predicate:

This may seem like a small thing, but in my experience, having to constantly rewrite column references like this is very error prone.
Approach 2: Fixed Naming
The alternative is to give every column a globally unique name that it keeps as it moves up the tree. You might think of this as query planning's version of SSA.
The way this is commonly done is to have a system that allocates some kind of unique integer for every column as they get introduced. Here I'm representing them as %name to distinguish them the SQL-level names for the columns, but in practice, they would just be unique integers:

In code, our operator might look more like this now:
struct Project {
input: Box<RelExpr>,
columns: HashSet<ColumnId>,
}
Also of note is that if you reference the same table multiple times in the same query, the columns coming from those different instances of the table will need to get their own unique names so they can be distinguished.
This has the nice property that now, if we push the projection beneath the join, all the names stay the same:

Plus, transformation rules tend to be much simpler to express in this way, since we don't need to include logic for renaming columns. The following fully expresses this transformation to push a projection into the left side of such a join (syntax roughly lifted from CockroachDB, with some liberties taken):
(Project
(Join
$p
$left
$right
)
$cols
) & (Not (SubsetOf (OutputCols $left) $cols))
=>
(Project
(Join
$p
(Project $left (Intersect (OutputCols $left $cols)))
$right
)
$cols
)
Some additional rules would be needed to push the projection into the right side as well, and eliminate it once it's a no-op, but I think this kind of decomposition of a transformation into multiple smaller ones is a very good way to design this kind of rule-based rewriting system.
This isn't perfect, though. There are some downsides.
- First of all, it's not clear (to me, at least) how to represent DAG query plans very well with this setup. You basically have to represent them with some kind of let/get setup, where the
gets reassign column names, and that gets a bit ugly. Otherwise, you might have to columns with the same name meet in the tree, which doesn't really work. - It's more difficult to recognize common subtrees in plans like this, since you have to compare subtrees for equality up to their column names. If you use ordinal indexes, a repeated tree will be represented by the same structure in memory, but if you're giving every column a unique name, that isn't true.
- For that same reason, some of the benefits of Hash Consing are lost here: you won't necessarily recognize when you have the same tree twice if you gave the same column different names in different contexts.
- You need some kind of global context to assign names. This isn't too onerous, but it means you can't just construct a tree as easily in tests.
- Some of the rules around maintaining identity can be confusing. What constitutes the "same" column? If a column passes through the outer side of an outer join, it can take on values (
NULL) it never took on below the outer join. Should that be the same column, or a different one? - You still, generally, require some kind of transformation step at the end to turn these into something your execution engine can make use of.
All that said, this is definitely my preferred way to design a query IR, having worked on systems that use both ways, and I would unequivocally recommend it as The Right Way. It's just so powerful to have expressions that mean the same thing in multiple contexts, and being able to shuffle things around without worrying about their semantics changing is extremely nice.
Add a comment: