Channel Sharding in Go

It’s a common pattern in Go to fan out I/O-bound tasks to a bunch of worker Goroutines. We have some big batch of work that has to get done, and we dole it out to workers that each do blocking I/O. There are a couple of natural ways to do this, but let's talk about a way not to do it first.
I recently was shown a piece of code that implemented this pattern like this:
chans := make([]chan job, workerCount)
for i := range chans {
chans[i] = make(chan job)
}
... more setup code ...
for i, job := range jobs {
chans[i % len(chans)]<-job
}
This code looks innocent, but there’s two major problems with this. The first is that this kind of workload benefits from load-balancing, especially if the I/O we're doing is network-bound and there's a lot of variability in job size. By forcing the i-th job into the (i%n)-th bucket all the time, we don’t get any benefit from one worker getting a small job and being able to work on another one right away.
There is a second, much worse problem that might only be clear if you’re familiar with Go: these channels are unbuffered, which means that sends on them are blocking: if nobody is waiting around on the other end of the channel to receive the job, the sender will wait for them to show up, and won't proceed on to the other channels.
Thus, one slow job can block every other worker from proceeding with its tasks! We’ll make one successful trip around the workers where every send will succeed, then on the second trip we’ll have to wait on whichever one was slowest.
It’s easy enough to run some simulations to see what the actual effect of this is. We can make a couple implementations of this behaviour. I've been trying to get better at writing these kind of quick one-off simulations and have been slowly converging on a workflow I like, so I'll outline how I go about this sort of thing.
First, we'll re-implement the problematic implementation (don't be scared by the closure inside of the for loop, they fixed that):
func runFanoutIncorrect(config config) {
var wg sync.WaitGroup
jobChans := make([]chan job, config.workers)
for i := range jobChans {
jobChans[i] = make(chan job)
}
for i := range config.workers {
wg.Add(1)
go func() {
defer wg.Done()
for job := range jobChans[i] {
// Simulate an I/O-bound task by sleeping.
time.Sleep(job.size)
}
}()
}
r := rand.New(rand.NewSource(time.Now().UnixNano()))
i := 0
for i < config.jobs {
jobChans[i%len(jobChans)] <- job{size: config.timePerJob.Sample(*r)}
i++
}
for i := range jobChans {
close(jobChans[i])
}
wg.Wait()
}
Now we have two directions to go. One reason you might reasonably do this kind of sharding is to avoid contention on the channel. So, we can re-implement this, but fixing the problem: do a non-blocking send, and if a channel isn't accepting, move on to the next one:
func runFanoutCorrect(config config) {
var wg sync.WaitGroup
jobChans := make([]chan job, config.workers)
for i := range jobChans {
jobChans[i] = make(chan job)
}
for i := range config.workers {
wg.Add(1)
go func() {
defer wg.Done()
for job := range jobChans[i] {
time.Sleep(job.size)
}
}()
}
r := rand.New(rand.NewSource(time.Now().UnixNano()))
i := 0
j := 0
for i < config.jobs {
select {
case jobChans[j%len(jobChans)] <- job{size: config.timePerJob.Sample(*r)}:
i++
default:
}
j++
}
for i := range jobChans {
close(jobChans[i])
}
wg.Wait()
}
But it's also worth questioning this in the first place. If our jobs are big enough, do we need to care about this channel sharding? So here's a third, simpler implementation:
func runOneChannel(config config) {
var wg sync.WaitGroup
jobs := make(chan job)
for range config.workers {
wg.Add(1)
go func() {
defer wg.Done()
for job := range jobs {
time.Sleep(job.size)
}
}()
}
r := rand.New(rand.NewSource(time.Now().UnixNano()))
for i := 0; i < config.jobs; i++ {
jobs <- job{size: config.timePerJob.Sample(*r)}
}
close(jobs)
wg.Wait()
}
My current preferred way to collect data for this kind of thing is to just println out comma-separated lines from all my various experiments. I think of this like a lab notebook where a scientist writes down all the parameters and results of every experiment as they do them.
This structure is nice because you don't need them to be ordered, you can just redirect the result to a csv in your lab directory, and it's easy to turn them into plots with Jupyter:
func main() {
fmt.Printf("strategy,dist,size,workers,jobs,time\n")
for size := range 10 {
config := config{
timePerJob: exp{mean: time.Millisecond * time.Duration(size)},
workers: 128,
jobs: 10000,
}
runAll(config)
}
}
func runAll(config config) {
start := time.Now()
runOneChannel(config)
elapsed := time.Since(start)
fmt.Printf("one,%s,%f,%d,%d,%f\n", config.timePerJob.Name(), config.timePerJob.Mean().Seconds(), config.workers, config.jobs, elapsed.Seconds())
start = time.Now()
runFanoutCorrect(config)
elapsed = time.Since(start)
fmt.Printf("fanout-correct,%s,%f,%d,%d,%f\n", config.timePerJob.Name(), config.timePerJob.Mean().Seconds(), config.workers, config.jobs, elapsed.Seconds())
start = time.Now()
runFanoutIncorrect(config)
elapsed = time.Since(start)
fmt.Printf("fanout-incorrect,%s,%f,%d,%d,%f\n", config.timePerJob.Name(), config.timePerJob.Mean().Seconds(), config.workers, config.jobs, elapsed.Seconds())
}
So 128 workers, exponentially distributed job sizes (with means 1-10ms), and 10000 jobs. The result we see plotting the job size mean against the time to complete them all is pretty clear.
Once I have the csv file I plot them in Jupyter with (embarrassing confession) Python written by ChatGPT:
import pandas as pd
import matplotlib.pyplot as plt
file_path = "files/fanout.csv"
data = pd.read_csv(file_path)
data['dist'] = data['dist'].astype('category')
plt.figure(figsize=(10, 6))
for strategy in data['strategy'].unique():
subset = data[data['strategy'] == strategy]
plt.plot(
subset['size'], subset['time'], label=strategy, marker='o', linestyle='-'
)
plt.xlabel("Size")
plt.ylabel("Time")
plt.title("Performance Comparison by Strategy")
plt.legend(title="Strategy")
plt.grid(True)
plt.tight_layout()
plt.show()
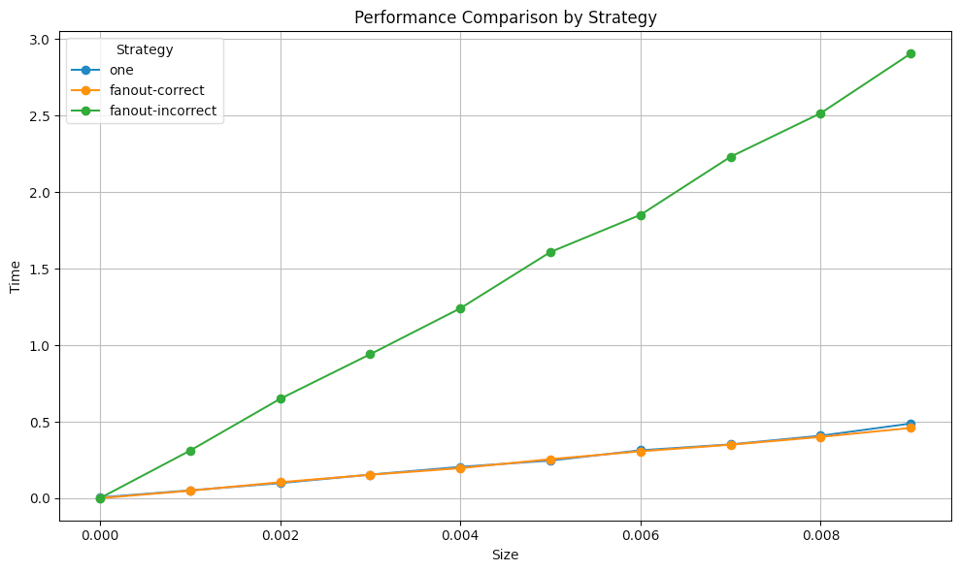
The more workers you add, the more prominent the effect gets.
if we make the job size smaller, we can start to see the impact of channel contention. These jobs are a hundredth of the jobs before, and there are a hundred times as many of them:
func main() {
fmt.Printf("strategy,dist,size,workers,jobs,time\n")
for size := range 10 {
config := config{
timePerJob: exp{mean: time.Millisecond * time.Duration(size) / 100},
workers: 128,
jobs: 1000000,
}
runAll(config)
}
}
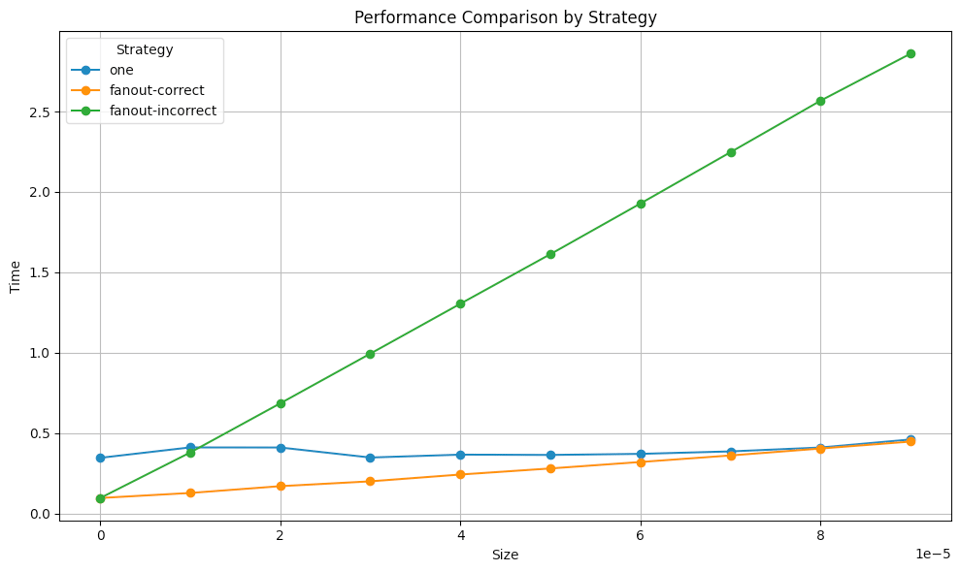
But the difference is small and vanishes pretty quickly as the sizes of the jobs get bigger. A corollary of this observation is that if your jobs are too small, batching is a way to turn them into larger jobs to reduce the impact of channel contention.
This seems to me to be fairly consistent across job size distribution. All of these examples so far have used exponentially-distributed job sizes.
If we change the job distribution size to be uniform:
func main() {
fmt.Printf("strategy,dist,size,workers,jobs,time\n")
for size := range 10 {
config := config{
timePerJob: uniform{
min: time.Millisecond,
max: time.Millisecond * time.Duration((size + 1)),
},
workers: 128,
jobs: 10000,
}
runAll(config)
}
}
We get a pretty similar-looking graph:
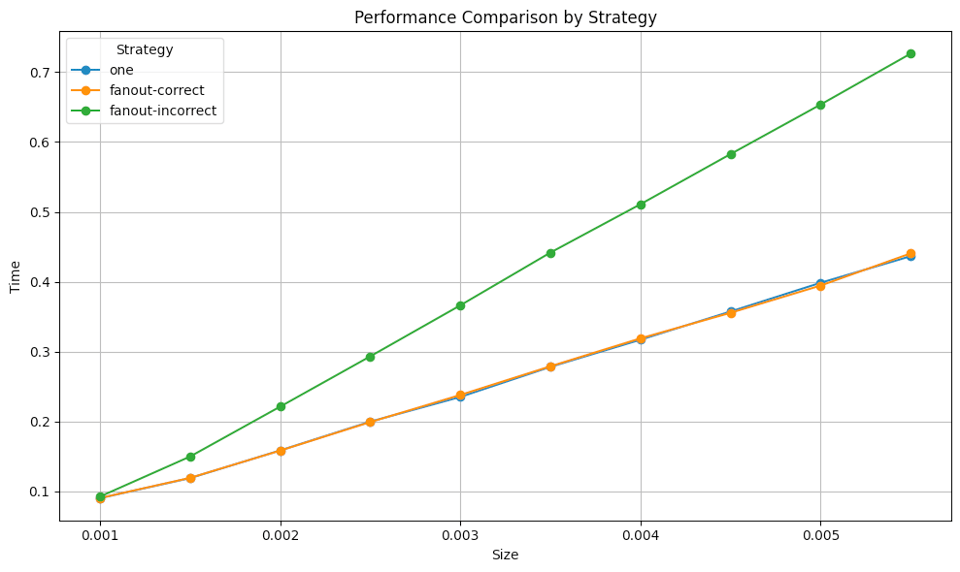
But the impact seems a bit less stark.
If you have workloads where you've observed things behaving differently than this I'd be curious to hear about them. All the code I used to generate these is here.
Do you have a better workflow for this kind of test? Do you object to any of my methodology? Let me know!
Add a comment: