Versiones nuevas de Altair, plotnine, y pandera, codificando variables categóricas de manera sencilla en scikit-learn, trabajando con datasets particionados en Kedro, nos vemos en la PyCon Lituania, y fotitos de la JupyterCon de París.
🚀 ¡Muchas versiones nuevas esta semana!
Se ha publicado Vega-Altair 5.0 (Altair para los amigos), una biblioteca Python para visualización estadística basada en la gramática Vega-Lite, con muchas novedades: soporte para parámetros dinámicos, soporte experimental para el protocolo de intercambio de dataframes `dataframe, y mucho más.
De hecho, en el blog de Liam Brannigan, uno de los divulgadores de Polars más activos, puedes leer cómo utilizar dataframes de Polars con Altair 5.
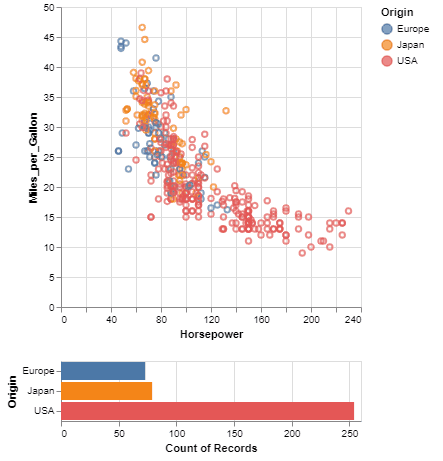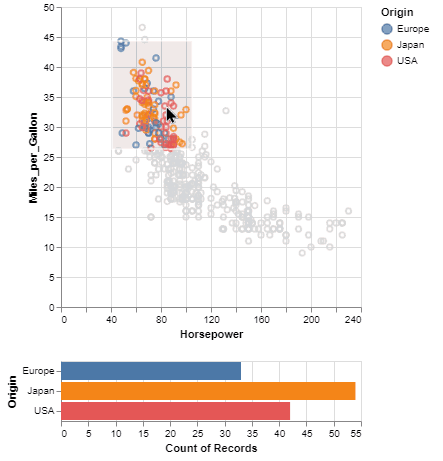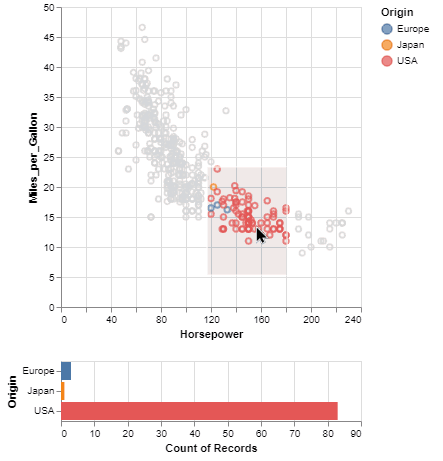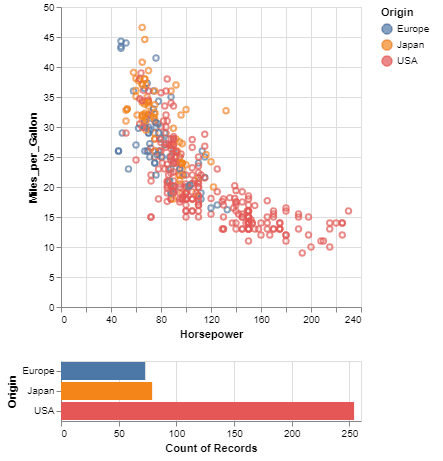 También tenemos plotnine 0.12.1, una implementación del "Grammar of Graphics" en Python (en otras palabras: "ggplot2 en Python"). Esta versión trae un nuevo gestor de composición (es más fácil evitar que se solapen los objetos), un nuevo método
También tenemos plotnine 0.12.1, una implementación del "Grammar of Graphics" en Python (en otras palabras: "ggplot2 en Python"). Esta versión trae un nuevo gestor de composición (es más fácil evitar que se solapen los objetos), un nuevo método save_helper() que devuelve la figura de matplotlib subyacente, y mucho más.
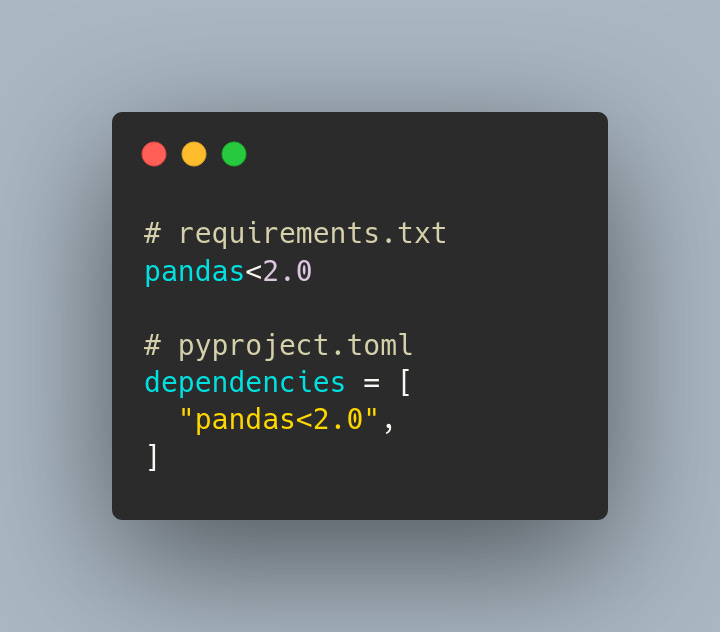
 Y por último, pandera 0.15, que permite definir esquemas de datos para dataframes, trae soporte para pandas 2.0, sintaxis más breve para el tipado de los esquemas, valores por defecto, y mucho más.
Y por último, pandera 0.15, que permite definir esquemas de datos para dataframes, trae soporte para pandas 2.0, sintaxis más breve para el tipado de los esquemas, valores por defecto, y mucho más.
 💡 Esta semana he descubierto category_encoders, una extensión de scikit-learn para codificar variables categóricas. Creo que era el problema más frecuente entre mis alumnos, ¡y de mucha gente! Los hay supervisados y no supervisados.
💡 Esta semana he descubierto category_encoders, una extensión de scikit-learn para codificar variables categóricas. Creo que era el problema más frecuente entre mis alumnos, ¡y de mucha gente! Los hay supervisados y no supervisados.
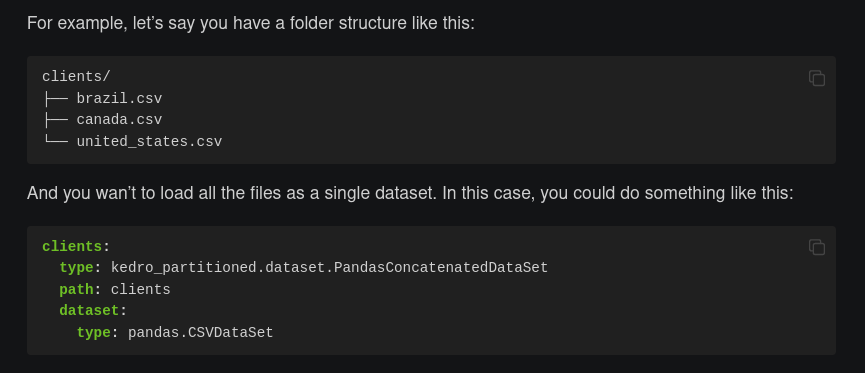
También he descubierto kedro-partitioned, una extensión de Kedro para trabajar con datasets compuestos de muchos archivos.
📚 Esta semana no he leído ningún artículo notable, ¡mucha faena!
🛫 La semana que viene estaré en la PyCon Lituania hablando de cómo convertir tus notebooks de Jupyter en código mantenible usando Kedro. ¿Alguien más por allí?

🗼 Esta semana me perdí la JupyterCon en París, ¡por las fotos parece que estuvo espectacular! Mi sueño sería poder tener a Fernando Pérez dando una charla en la PyConES, ojalá se cumpla algún día.
Algunas de estas actualizaciones las he ido publicando en inglés en mi cuenta de Mastodon. ¡Sígueme en el Fediverso!
 También ha salido
También ha salido 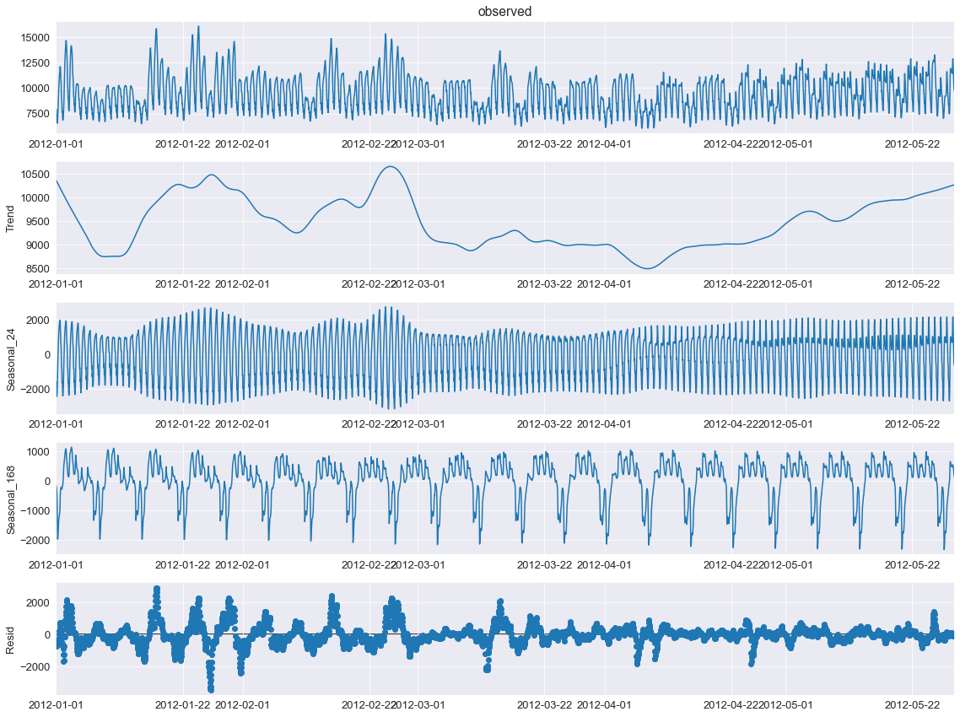 Y por último,
Y por último, 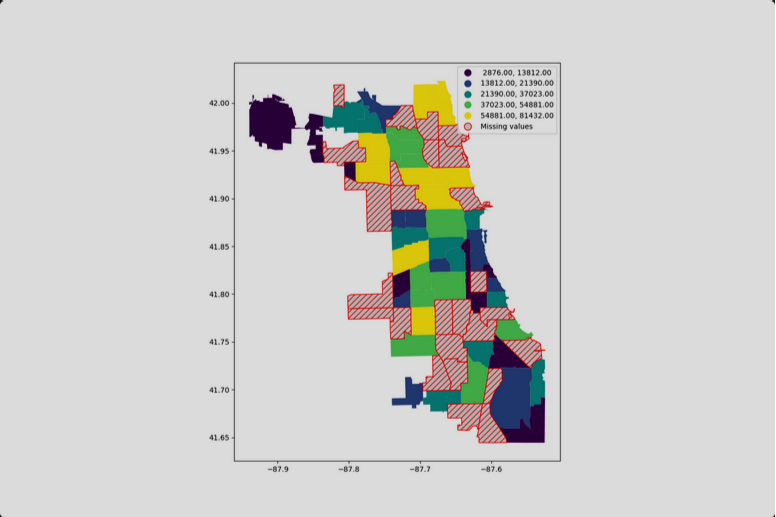 Y como cada primer noticiero de mes, novedades sobre
Y como cada primer noticiero de mes, novedades sobre  📚 Me ha gustado mucho este artículo de Cameron Riddell sobre
📚 Me ha gustado mucho este artículo de Cameron Riddell sobre 
 Como ya señaló André Staltz,
Como ya señaló André Staltz, 
 Y finalmente, tenemos versiones nuevas de:
Y finalmente, tenemos versiones nuevas de: