Estamos en el segundo noticiero del año y ya tengo exceso de enlaces, he tenido que comprimir y sintetizar bastante. ¡Vamos allá!
🚀 Ha salido Ibis 4.0, con varios nuevos backends incluyendo Polars y Snowflake, nuevos métodos read_csv y read_parquet para lectura de datos más sencilla, mayor granularidad para extraer elementos de campos JSON, y mucho más. Si estás buscando una capa de abstracción en Python sobre SQL, no te pierdas este proyecto.

También tenemos Fugue 0.8, y me gusta mucho cómo Kevin ha contado en LinkedIn la forma en la que han escuchado a los usuarios para hacer el proyecto más fácil de usar. Incluye varias funciones nuevas para lectura y escritura de datos y varias pequeñas mejoras de usabilidad.

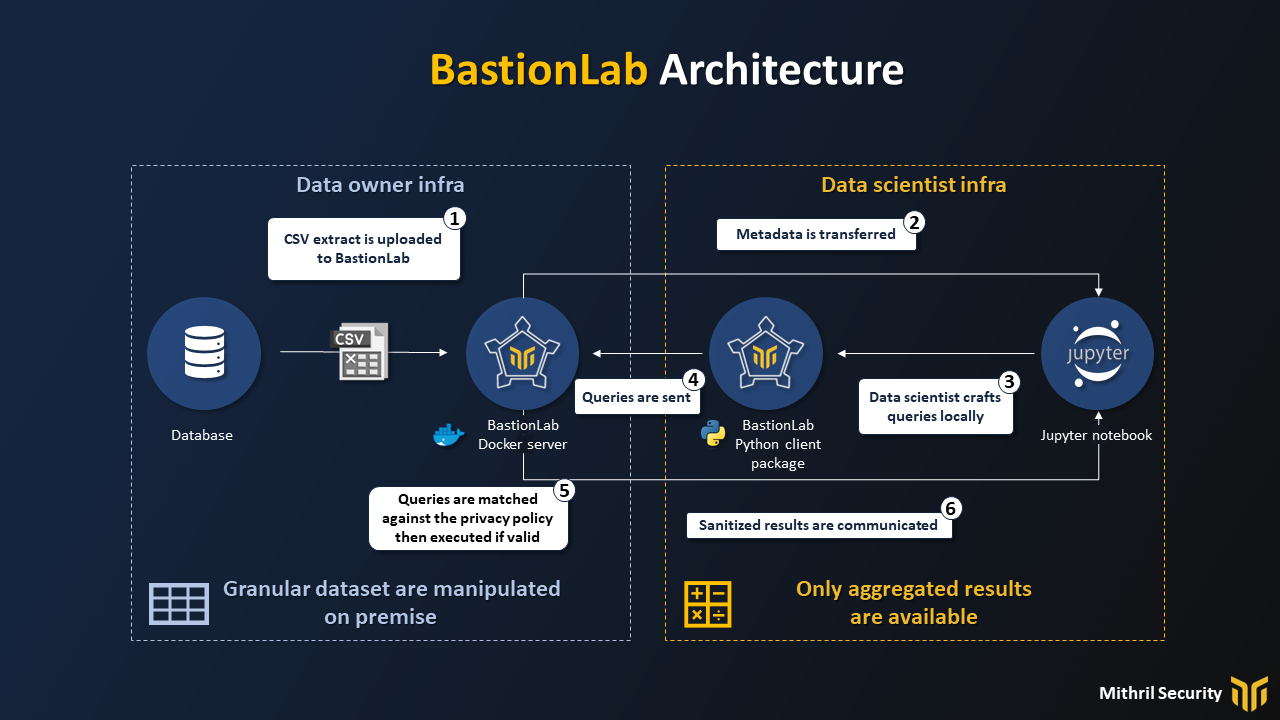
💡 Esta semana he descubierto bastionlab, un framework para mantener la privacidad de los datos al hacer análisis exploratorios.
Y Toni Almagro me comenta por LinkedIn (¡gracias!) sobre snorkel, un proyecto (tristemente abandonado en octubre del año pasado) para generar datos de entrenamiento con supervisión débil.
📚 Martxelo nos comparte en el grupo de Telegram de Python Científico cómo ha utilizado la nueva funcionalidad de scikit-learn 1.2 de mantener los nombres de las columnas.

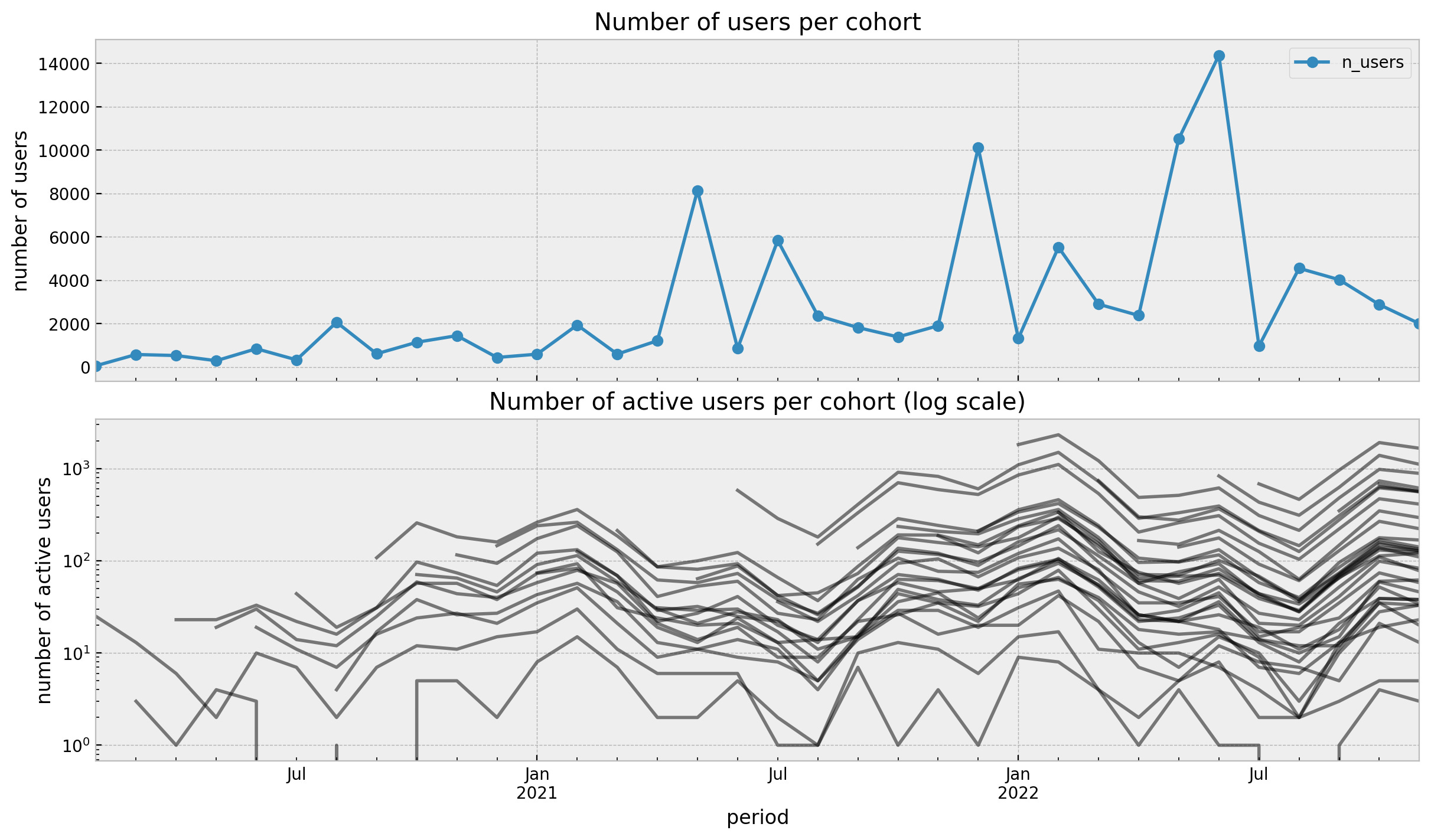
Me ha explotado la cabeza con este análisis de retención de cohortes de Juan Orduz utilizando PyMC. Si trabajas en una startup de producto, esto es lectura obligada: te ayudará a entender si estás encontrando product market fit o no de una forma rigurosa.
Como a lo mejor ya sabrás, me encanta todo lo que tiene que ver con la paquetería en Python, y he dado algunas charlas sobre ello. Una de las personas que más ha empujado para mejorar la experiencia de desarrollo en este área es Ralf Gommers, histórico mantenedor de NumPy y SciPy. En este artículo desgrana con mucho acierto cuál es el futuro de la paquetería en Python, enlaza algunas conversaciones muy relevantes que están teniendo lugar ahora mismo, y expone con precisión los problemas a los que se ha enfrentado la comunidad científica en este aspecto. Por cierto, si quieres empaquetar una biblioteca Python que también incluya código compilado con C++, Rust o similares, no te pierdas esta guía del mismo autor.
, and the third one
shows alternative tools that can perform the same job as the default tool
(e.g., mamba or spack instead of pip).")
Y por último, me ha encantado este resumen del crecimiento de Python en el ámbito geoespacial.

📣 ¡El jueves que viene tenemos reunión de PyData Madrid con la gente maja de KSchool! Hablaremos de drones conectados y de interpretabilidad. ¿Te veo allí?

Y por si fuera poco, ¡se acaba de anunciar la primera reunión de PyData Granada! Si vives por la zona, tienes una cita el 1 de febrero.


🤡 Parece que algunos equipos académicos excesivamente sinceros están añadiendo ChatGPT a la lista de autores de sus artículos… Más allá de lo divertido del asunto, pregunta provocadora: ¿no es ChatGPT una herramienta al mismo nivel que matplotlib o ggplot2 para las gráficas por ejemplo? ¿Qué opinas?

PS: Dear researchers, you forgot the version number!
(thx @3scorciav for sharing this!)


If a person creates or contributes results for a paper, this person is a coauthor. But this naturally doesn’t extend to models or algorithms.
Imagine AlphaFold were an author on the AlphaFold paper.
So, why would/should it be different for ChatGPT?!
¿Buscas proveedor de dominios y hosting bueno, bonito y barato para tu próximo proyecto? Llevo años con Dinahosting (enlace afiliado) y no me cambio por nada, el soporte 24 horas es 🔝, y son de Galicia 🇪🇸
Acabas de leer la edición #52 de El noticiero de Juanlu. También puedes explorar archivo completo de este boletín.