
|
|
SECURITY
MAJOR
2026-05-25
Heretic Strips Safety Guardrails From Meta's Llama 3.3 and Google's Gemma 3 in Under 10 Minutes
A free, fully automatic GitHub tool removes the refusal mechanisms baked into open-weight models in minutes.
What is it?
Heretic is open-source software that "decensors" downloadable language models by stripping out their safety refusals. The FT and AI safety group Alice tested it on Meta's Llama 3.3 and Google's Gemma 3, reporting guardrails came off in under ten minutes with no specialist hardware.
How does it work?
The tool uses abliteration: it locates the internal directions a transformer uses to refuse a request and removes them, leaving the rest of the model intact. The process runs automatically end to end on any open-weight model that can be downloaded locally.
Why does it matter?
It shows that safety tuning on open-weight models is reversible by anyone, not just experts — stripped Gemma 3 returned instructions for dispersing chlorine gas in a crowd and code to steal credit-card data. Proprietary systems like Claude and ChatGPT are unaffected because their weights are not downloadable.
Who is it for?
AI safety researchers, policymakers, and model providers evaluating the risks of open-weight model releases.
|
|

|
|
SECURITY
MAJOR
2026-05-25
Microsoft Copilot Cowork Exfiltrates Files via Poisoned Skills — 100% Success Rate Against Claude Opus 4.7 and Sonnet 4.6
A poisoned skill turns Microsoft's M365 agent into a file thief with no user approval step.
What is it?
PromptArmor's disclosure of a data-exfiltration flaw in Microsoft Copilot Cowork — the M365 agent that acts with the user's full permissions and reads tenant data through Microsoft Graph. A booby-trapped skill file is enough to make it leak files silently.
How does it work?
An indirect prompt injection hidden in a skill instructs the agent to send a Teams message containing an external image tag. Sending messages to the active user runs without human approval, so when the target opens the message, the image request fires and carries pre-authenticated download links to an attacker domain.
Why does it matter?
It is a concrete example of the auto-approval gap in enterprise agentic assistants: the agent inherits the user's full Graph access, and one un-gated send action becomes the entire exfiltration channel. The same pattern threatens any agent that can message users without confirmation.
Who is it for?
Security teams and M365 admins who deploy Copilot Cowork — mitigation requires restricting file download policies via SharePoint admin controls.
|
|

|
|
ECOSYSTEM
MAJOR
2026-05-25
Pope Leo XIV's First Encyclical 'Magnifica Humanitas' Makes AI Ethics Church Teaching — Presented With Anthropic Co-Founder Chris Olah
The Catholic Church makes AI ethics a core teaching: Pope Leo XIV's first encyclical urges the world to 'disarm' artificial intelligence.
What is it?
Magnifica Humanitas is Pope Leo XIV's first encyclical — the highest form of papal teaching document — and the first ever devoted to artificial intelligence. Signed May 15 on the 135th anniversary of Rerum Novarum and released May 25, 2026, it extends Catholic social teaching into the age of AI.
How does it work?
The text argues AI cannot replicate the human capacity to suffer, grow, and love, warns against "increasingly autonomous weapons systems," and frames AI concentrated in a profit-driven few as a "new colonialism" that appropriates data and weakens democracy.
Why does it matter?
It elevates AI ethics to a moral imperative for over a billion Catholics and addresses the tech industry directly. Pope Leo broke tradition to present the document in person alongside Anthropic co-founder Chris Olah, who said engineers need "moral voices that incentives cannot bend."
Who is it for?
AI policy watchers, ethicists, and industry leaders tracking how institutions outside tech are shaping AI governance.
|
|

|
|
SECURITY
MAJOR
2026-05-22
Anthropic's Project Glasswing: 10,000+ Vulnerabilities Found — Claude Mythos Hits 90.6% True-Positive Rate, Claude Security Enters Public Beta
Anthropic's one-month report on its ~50-partner program to find software flaws before AI models can exploit them.
What is it?
Project Glasswing is Anthropic's coordinated effort with ~50 partners to use its Claude Mythos Preview model to find and fix security flaws in critical software ahead of attackers. This first public results report covers the program's opening month.
How does it work?
Partners run Claude Mythos against their codebases and open-source projects; an automated scan of 1,000+ projects flagged 6,202 high/critical issues. Independent assessment confirmed 1,587 as valid — a 90.6% true-positive rate — and findings route to maintainers through coordinated disclosure.
Why does it matter?
It is a concrete data point on whether frontier models can do useful defensive security at scale: 530 bugs reported to maintainers, 75 patched so far. Security teams can now try the workflow through the new Claude Security public beta and an open vulnerability dashboard.
Who is it for?
Security researchers and open-source maintainers who want AI-assisted vulnerability discovery in their own codebases.
|
|

|
|
MODEL
MAJOR
2026-05-22
DeepSeek Makes Its 75% V4-Pro API Discount Permanent — Input at $0.435/M, Output at $0.87/M, a Quarter of Original Sticker
DeepSeek makes its 75%-off V4-Pro API pricing permanent instead of letting the promo expire May 31.
What is it?
DeepSeek-V4-Pro is the company's flagship API model. A 75% promotional discount set to expire May 31 has now been confirmed permanent: once the promo window closes, the standing price stays at one-quarter of the original sticker rate.
How does it work?
Cache-miss input drops to $0.435 per million tokens and output to $0.87 — a quarter of the original $1.74 and $3.48 list prices. Cache-hit input falls to $0.003625 per million, roughly a 90% reduction on cached reads.
Why does it matter?
For agentic and long-context workloads that re-read large prompts repeatedly, the near-zero cache-hit price reshapes the cost math entirely. Teams get a capable, OpenAI-compatible API on open harnesses without contract lock-in.
Who is it for?
API developers, agent builders, and cost-sensitive teams currently paying for GPT-4-class models — model ID is deepseek-v4-pro.
|
|

|
|
MODEL
NOTABLE
2026-05-25
OpenBMB MiniCPM5-1B — 1.08B On-Device Model Reaches Open-Source SOTA in Its Size Class, Ships GGUF and 4-Bit MLX Builds
A 1.08B on-device language model that reaches open-source SOTA in its size class.
What is it?
MiniCPM5-1B is a dense 1-billion-parameter language model from OpenBMB, built to run locally on phones, laptops, and browsers — not in the cloud. Released under Apache-2.0, a single checkpoint answers directly or reasons step by step.
How does it work?
A 24-layer transformer with grouped-query attention over a 131,072-token context, supporting both think and no-think modes via the chat template, plus XML-style tool calling. Ships as GGUF builds for llama.cpp/Ollama/LM Studio and a 4-bit MLX build for Apple Silicon.
Why does it matter?
It fits on consumer hardware with no GPU cluster, yet the model card reports 1B-class open-source SOTA against same-size baselines like Qwen3.5-0.8B, with the strongest lead on tool use, code generation, and reasoning — making capable offline assistants practical on a single device.
Who is it for?
On-device and edge developers building private, offline AI features for phones, laptops, or embedded systems.
|
|
|
|
REPO
NOTABLE
2026-05-24
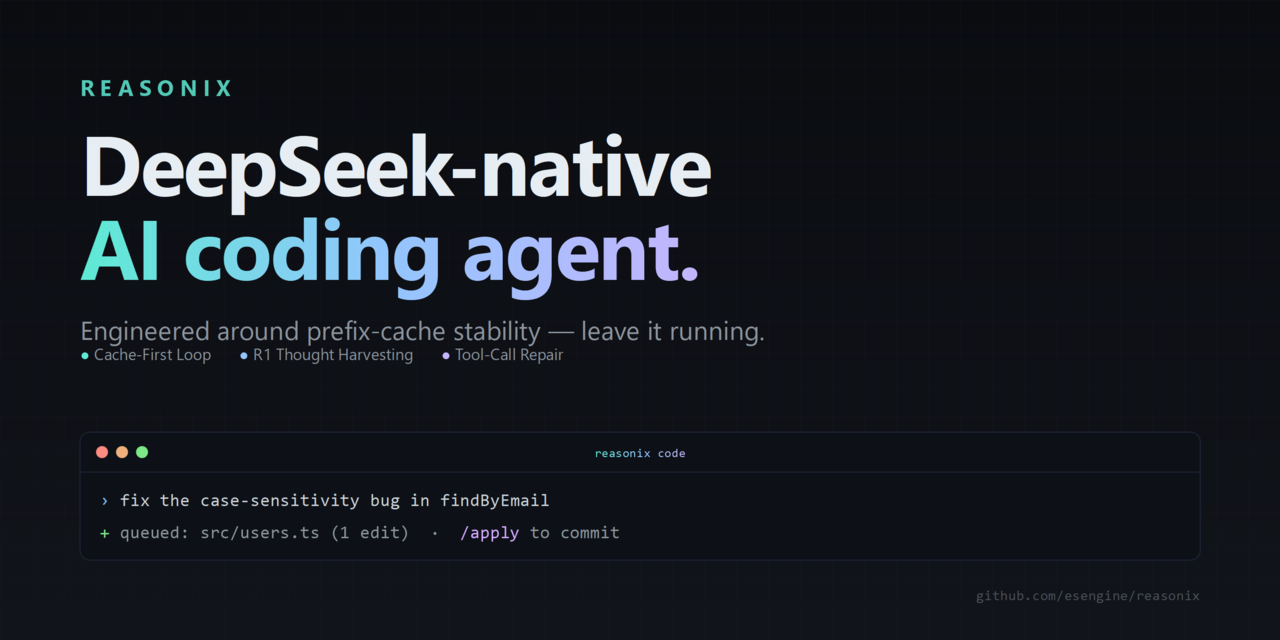
DeepSeek-Reasonix — Terminal Coding Agent Reports 99.82% Cache Hit Rate, Cutting a 435M-Token Day From ~$61 to ~$12
A terminal coding agent that bets on DeepSeek's prefix cache to keep long sessions cheap.
What is it?
Reasonix is an open-source command-line coding agent that talks directly to DeepSeek's API with no provider-abstraction layer. It runs in your terminal, reads and edits files, and defaults to DeepSeek-V4-Flash with a per-session switch to V4-Pro.
How does it work?
It is engineered around DeepSeek's byte-stable prefix cache: the agent keeps the prompt prefix identical across turns so cached tokens stay valid, using four mechanisms to avoid cache-invalidating edits. A tool-call repair layer fixes malformed tool calls without restarting a turn.
Why does it matter?
Prefix-cache misses are the main hidden cost of long agent sessions. Maintainers report 99.82% cache hit rate across 435M input tokens in one day — dropping the bill from ~$61 to ~$12, making always-on agents affordable for solo developers.
Who is it for?
Developers using DeepSeek's API who want a lightweight coding agent that actively minimizes inference costs — try it with npx reasonix code.
|
|
|
All releases at ai-tldr.dev
Simple explanations • No jargon • Updated daily
|
|