|
|
REPO
NOTABLE
2026-05-24
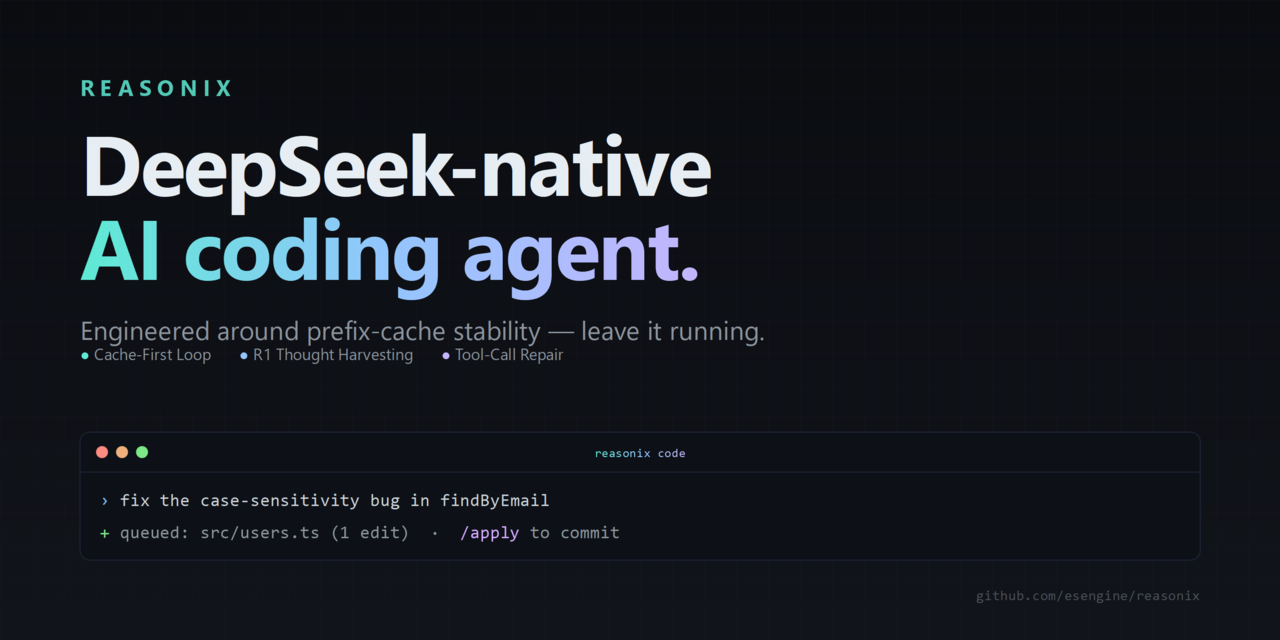
DeepSeek-Reasonix — Terminal Coding Agent With 99.82% Cache Hit Rate, Cutting a 435M-Token Day From ~$61 to ~$12
A terminal coding agent that bets on DeepSeek's prefix cache to keep long sessions cheap.
What is it?
Reasonix is an open-source command-line coding agent that talks directly to DeepSeek's API with no provider-abstraction layer. It runs in your terminal, reads and edits files, and runs tasks — defaulting to DeepSeek-V4-Flash with a per-turn switch to V4-Pro.
How does it work?
It keeps the prompt prefix byte-stable across turns so cached tokens stay valid, using four mechanisms to avoid cache-invalidating edits. The maintainers report a 99.82% cache hit rate across 435M input tokens in a single day.
Why does it matter?
The same 435M-token day that would cost ~$61 uncached on V4-Flash drops to roughly $12 — making always-on coding agents affordable for solo developers without cloud infrastructure.
Who is it for?
Developers using DeepSeek's API who want a cheap, long-running coding agent they can run from the terminal with npx reasonix code.
|
|

|
|
SECURITY
MAJOR
2026-05-22
Anthropic's Project Glasswing — ~50 Partners, 10,000+ Vulnerabilities Found, 90.6% True-Positive Rate
Anthropic's one-month report on its ~50-partner program to find software flaws before AI models can exploit them.
What is it?
Project Glasswing is Anthropic's coordinated effort with about 50 partners to use its Claude Mythos Preview model to find and fix security flaws in critical software ahead of attackers. This is the program's first public results, covering its opening month.
How does it work?
Partners run Claude Mythos against their own codebases and a sweep of open-source projects. An automated scan of 1,000+ projects flagged 6,202 high- or critical-severity issues; independent assessment confirmed 1,587 as valid at a 90.6% true-positive rate.
Why does it matter?
It is a concrete data point on whether frontier models can do useful defensive security at scale. Maintainers get real fixes — 530 bugs reported, 75 patched so far — and Claude Security now enters public beta alongside an open vulnerability dashboard.
Who is it for?
Security researchers and open-source maintainers who can try the workflow through the new Claude Security public beta.
|
|

|
|
MODEL
MAJOR
2026-05-22
DeepSeek Makes Its 75% V4-Pro API Discount Permanent — $0.435/M Input, $0.87/M Output
DeepSeek makes its 75%-off V4-Pro API pricing permanent instead of letting the promo expire on May 31.
What is it?
DeepSeek-V4-Pro's 75% promotional discount was set to expire May 31, 2026. DeepSeek confirmed the cut is now permanent — the standing price stays at one-quarter of the original sticker rate after the promo window closes.
How does it work?
Cache-miss input is $0.435 per million tokens and output $0.87 — a quarter of the original $1.74 and $3.48 list prices. Cache-hit input falls to $0.003625 per million, roughly a 90% reduction from the cache list price.
Why does it matter?
The cache-hit price reshapes the cost math for agentic workloads that re-read large prompts repeatedly. Teams can run a capable, OpenAI-compatible API on open harnesses without contract lock-in.
Who is it for?
API developers, agent builders, and cost-sensitive teams who want frontier-grade reasoning at a permanent discount — use model ID deepseek-v4-pro.
|
|

|
|
MODEL
MAJOR
2026-05-20
Cohere Command A+ — 218B Sparse MoE, Apache 2.0, Runs on Two H100s
An open-weight 218B MoE that runs agentic, multimodal, multilingual workloads on as few as two H100 GPUs.
What is it?
Command A+ is Cohere's new open-weight LLM released under Apache 2.0. It folds four earlier Command models — base, reasoning, vision, and translate — into one mixture-of-experts model aimed at enterprise agents that organizations can self-host for data sovereignty.
How does it work?
218B total parameters but only 25B activate per token; a 4-bit W4A4 build fits on one B200 or two H100 GPUs. It supports a 128K-token input window and generates native citation grounding spans that tie each factual claim back to the source document.
Why does it matter?
Enterprises and public-sector teams that need data residency can run a capable agentic, vision-capable model on-prem without per-token API fees. Apache 2.0 lets them modify and redeploy freely — and the two-H100 footprint keeps hardware costs reachable.
Who is it for?
Enterprise and public-sector AI teams needing sovereignty, plus any organization that wants a powerful open-weight model for agentic workflows without cloud lock-in.
|
|

|
|
SECURITY
MAJOR
2026-05-20
Microsoft Open-Sources RAMPART and Clarity — Red-Teaming Framework for AI Agents and a Pre-Code Design Sounding Board
Two open-source tools that bake agent red-teaming and design review into the development workflow.
What is it?
RAMPART is a pytest-native framework for writing repeatable safety and security tests against AI agents, built on PyRIT. Clarity is a planning assistant that interrogates a system design before any code is written, using multiple independent AI thinkers from security and operational angles.
How does it work?
Developers write standard pytest cases describing threat scenarios; RAMPART connects to the agent, orchestrates the interaction, and returns pass/fail signals that can gate CI/CD. It supports statistical trials — e.g., requiring an action to be safe in ≥80% of runs — focusing on cross-prompt injection.
Why does it matter?
Agent safety testing has been largely ad hoc and manual. Putting red-team checks into pytest and CI lets teams catch prompt-injection regressions automatically on every commit, while Clarity pushes failure analysis upstream to the design phase where fixes are cheaper.
Who is it for?
AI agent developers and security teams who want to stop treating safety as a one-off audit and start catching regressions in CI — both tools are MIT-licensed at github.com/microsoft/RAMPART.
|
|

|
|
MODEL
NOTABLE
2026-05-21
Tencent Hy-MT2 — Open-Weight Translation Family (1.8B / 7B / 30B MoE), 33 Languages, 1.8B Quantizes to 440MB
An open-weight family of Tencent translation models spanning 1.8B to a 30B MoE, covering 33 languages.
What is it?
Hy-MT2 is a family of multilingual machine-translation models from Tencent's Hunyuan team in 1.8B, 7B, and 30B-A3B sizes. All three handle 33 languages and follow translation instructions for terminology, style, and personalization written in multiple languages.
How does it work?
The models use a fast-thinking decoding mode tuned for translation rather than open-ended chat. The 30B-A3B is a sparse MoE that activates ~3B parameters per token. The 1.8B is compressed with 1.25-bit quantization to about 440MB for on-device deployment with ~1.5x faster inference.
Why does it matter?
Tencent reports the 7B and 30B beat DeepSeek-V4-Pro and Kimi K2.6 on translation benchmarks, while the 1.8B surpasses commercial translation APIs from Microsoft and Doubao — all available as open weights to run locally.
Who is it for?
Developers and teams building multilingual translation pipelines who want open weights they can fine-tune or self-host instead of paying per-call translation APIs.
|
|
|
|
TOOL
NOTABLE
2026-05-21
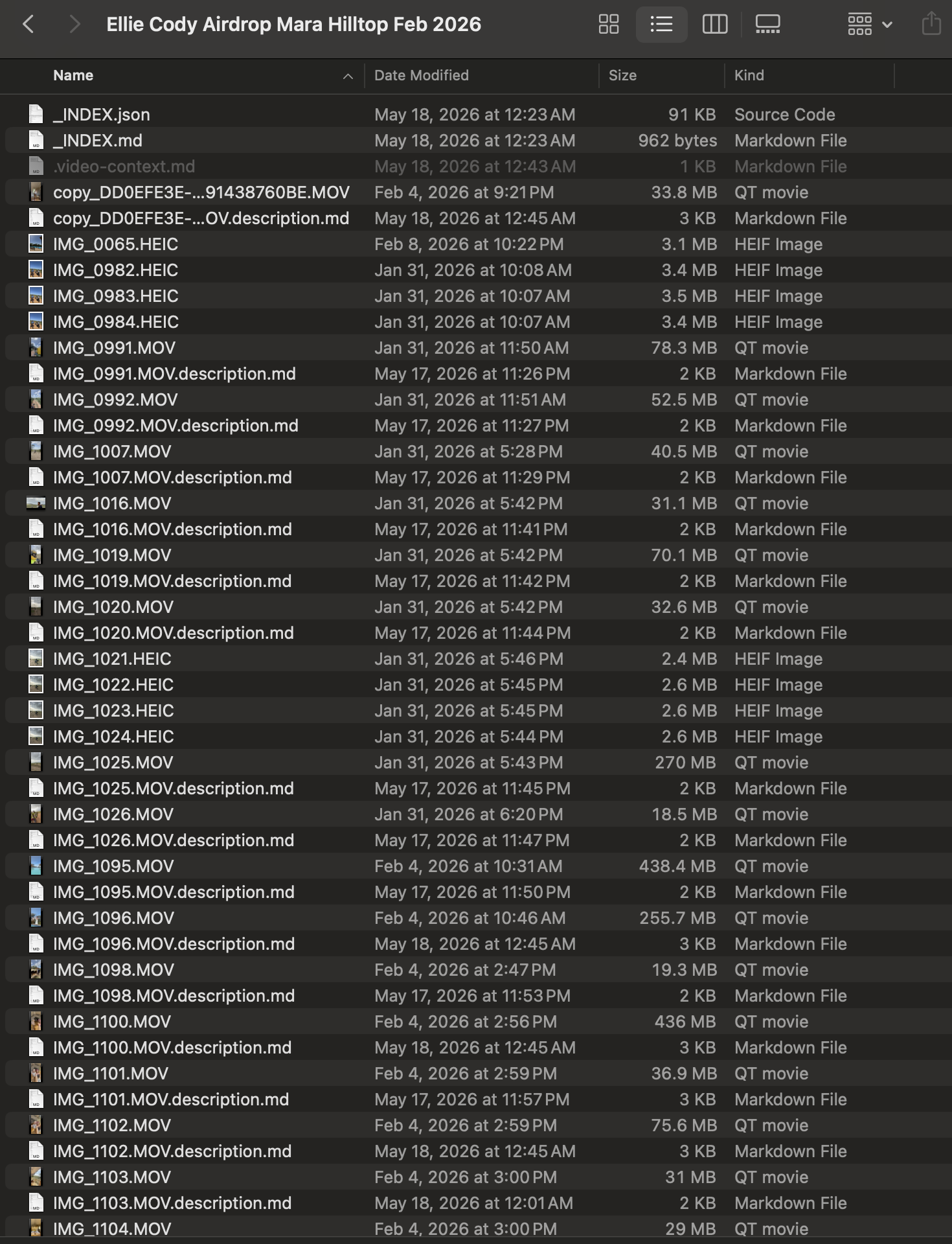
Framedex — A MacBook Runs Gemma 4 31B Locally to Index a Year of Video Into a Plain-English Knowledge Base
Local-first tool that turns an unlabeled video archive into a plain-English searchable knowledge base — no cloud upload needed.
What is it?
Framedex is an open-source Python tool that catalogs a personal video archive instead of editing it. For every clip it writes a markdown sidecar describing the footage in plain English, so the whole library becomes searchable. Everything runs locally on consumer hardware.
How does it work?
It runs Gemma 4 31B locally via LM Studio for prose scene descriptions, WhisperX for transcripts, and insightface for face embeddings — then extracts metadata like lighting, time of day, and GPS coordinates. Output is plain markdown saved next to each video file.
Why does it matter?
A five-year-old MacBook can index a year of footage overnight with no cloud upload of personal video. The author's argument: the valuable layer is the searchable index, not an AI editor — and once it's searchable, finding the right clip stops being the bottleneck.
Who is it for?
Local-AI tinkerers and videographers who want to reclaim their own archives without sending footage to a cloud service.
|
|
|
All releases at ai-tldr.dev
Simple explanations • No jargon • Updated daily
|
|