
|
|
TOOL
MAJOR
2026-06-04
ChatGPT Dreaming V3 Memory
ChatGPT's memory finally runs in the background — no more 'remember this' prompts, with free-tier rollout queued behind a 5x compute cut.
What is it?
Dreaming V3 is OpenAI's third-generation memory architecture for ChatGPT that replaces the saved-memories list with an automatic background process synthesizing preferences and facts from every conversation.
How does it work?
After each chat, a background pipeline pulls salient context into a structured memory state and rewrites stale entries instead of accumulating them. Plus and Pro users get 2x the prior memory capacity; a 5x compute cut makes free-tier rollout feasible.
Why does it matter?
OpenAI's internal evals show factual recall climbing from 41.5% in 2024 to 82.8% in 2026 — making long-running personalization the default so chats from months ago shape today's answers without manual bookkeeping.
Who is it for?
Long-term ChatGPT users, prosumer subscribers, and builders relying on consumer ChatGPT memory.
|
|

|
|
MODEL
MAJOR
2026-06-05
Google Gemma 4 QAT — Under 1GB on Phones
Gemma 4 shrinks to under 1GB on phones via a custom 2-bit mobile quantization format trained with QAT.
What is it?
A set of QAT-compressed checkpoints for Gemma 4 in two formats: the popular Q4_0 used by llama.cpp, and a new Google mobile format using 2-bit decoding layers with static activations for on-device inference.
How does it work?
QAT simulates integer rounding during fine-tuning so the model is robust to quantization loss, outperforming post-training quantization baselines at matching bit-widths. The E2B text-only path drops audio and vision encoders, slimming it below 1GB RAM.
Why does it matter?
Day-one support across llama.cpp, Ollama, LM Studio, vLLM, SGLang, MLX, and Hugging Face Transformers means the weights drop straight into existing local-LLM stacks — and a real Google LLM now fits mid-range phones with no GPU.
Who is it for?
Local-LLM hobbyists, on-device app builders, and mobile ML engineers.
|
|
|
|
SECURITY
MAJOR
2026-06-05
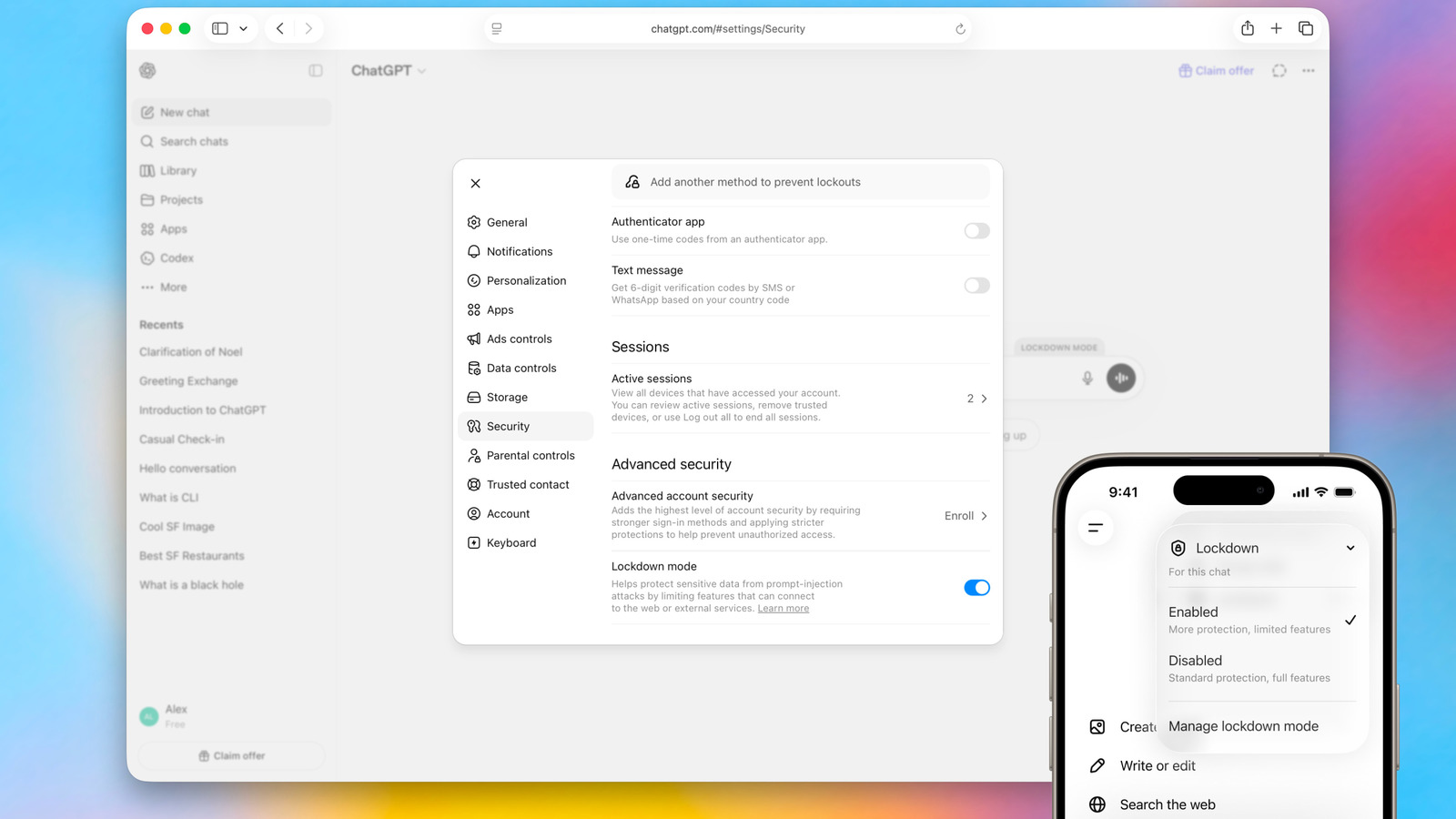
OpenAI Lockdown Mode Goes Wide
OpenAI's deterministic patch on the 'final stage' of prompt-injection attacks now reaches free ChatGPT users.
What is it?
An optional security toggle in ChatGPT that switches off the network-enabled features attackers use to exfiltrate data after a prompt injection — now rolling out to Free, Go, Plus, Pro, and self-serve ChatGPT Business accounts.
How does it work?
Enable it via Settings → Safety and security → Advanced security. The mode blocks outbound network requests, disables Deep Research and Agent Mode, refuses file downloads, and stops the model from fetching open-web images — controls are deterministic, not gated by another AI.
Why does it matter?
Pushing the hardened mode to the free tier puts a prompt-injection-resistant ChatGPT in front of anyone handling sensitive content. Note: it cuts the exfiltration channel but does not stop injected instructions from being read in the first place.
Who is it for?
People and teams handling sensitive data in ChatGPT.
|
|

|
|
REPO
MAJOR
2026-06-05
Hermes Agent v0.16.0 — Native Desktop App
Nous Research's self-improving agent gets a native desktop client and a no-config web admin panel; the project crossed 183K stars on the same day.
What is it?
Hermes Agent is Nous Research's open-source self-improving AI agent that now ships a native Electron desktop app for macOS, Linux, and Windows alongside a full browser-based admin panel — 874 commits and 542 merged PRs in this release.
How does it work?
The new desktop binary provides one-click install, in-app self-updates, drag-and-drop file support, and multi-profile sessions. A new web admin replaces YAML config for messaging channels, the MCP catalog, credentials, and webhooks.
Why does it matter?
Hermes has been CLI/TUI-first, blocking non-technical users. A native desktop binary and zero-config web admin meaningfully widen the addressable surface for self-hosted agents, especially for users who want messaging integrations without touching YAML.
Who is it for?
Developers and teams wanting a self-hosted, self-improving AI agent with messaging-platform integrations (Telegram, Discord, Slack, WhatsApp).
|
|

|
|
MODEL
MAJOR
2026-06-04
NVIDIA Nemotron 3.5 ASR Streaming 0.6B
A 600M-param open ASR model that streams 40 locales from one checkpoint and squeezes ~17× more concurrent voice sessions onto an H100.
What is it?
NVIDIA's first open multilingual streaming speech recognizer, covering 40 language-locales from a single 600M-parameter checkpoint under OpenMDW-1.1, with built-in punctuation and casing.
How does it work?
A Cache-Aware FastConformer-RNNT encoder processes each audio frame exactly once and reuses cached encoder states for new chunks, eliminating overlapping computation. Runtime-tunable latency lets developers choose points between 80ms and 1.12s.
Why does it matter?
A 0.6B model that fits 17× more concurrent streams onto an H100 collapses per-session cost for voice assistants, call-center transcription, and live captioning. OpenMDW-1.1 weights are commercial-friendly out of the box.
Who is it for?
Voice-agent and call-center teams, real-time captioning products, and on-premises deployers.
|
|
|
|
MODEL
MAJOR
2026-06-04
Magenta RealTime 2 — Open Live Music Model
An open-weights live music model that responds to MIDI, text, and audio in ~200ms and runs entirely on your MacBook.
What is it?
Google's second-generation open-weights model for continuous, low-latency musical audio generation — 2.4B base and 230M small variants under CC BY 4.0, with a DAW plugin bundle included.
How does it work?
MRT2 switches from v1's 2-second chunks to 40ms frames with frame-level autoregression and sliding-window attention, cutting end-to-end control latency from ~3s to ~200ms. A C++/MLX engine runs the base model natively on M3 Pro / M2 Max MacBooks.
Why does it matter?
MRT2 is the only open-weights model supporting real-time continuous music generation, making it usable as an actual live instrument rather than a render-and-listen tool — no cloud API required.
Who is it for?
Musicians, producers, music-software developers, and generative audio researchers.
|
|

|
|
ECOSYSTEM
MAJOR
2026-06-05
Google Pays SpaceX $920M/Month for 110,000 GPUs
Google rents 110,000 NVIDIA GPUs from SpaceX for $920M a month to fill a Gemini Enterprise capacity gap through mid-2029.
What is it?
A 33-month compute supply contract between Google and SpaceX, disclosed in a SpaceX SEC filing on June 5, covering roughly 110,000 NVIDIA GPUs plus CPUs, memory, and infrastructure starting October 2026.
How does it work?
SpaceX supplies the GPU fleet from one of its data center sites through June 2029. Google can invoke a 90-day cancellation window after December 31, 2026, and can reduce fees if SpaceX misses the September 30, 2026 delivery milestone.
Why does it matter?
Google rarely buys frontier compute from a third party — the SEC filing is hard evidence that Gemini Enterprise demand is outrunning Google's own TPU buildout. SpaceX is now the largest discretionary compute landlord for two top-four labs (also Anthropic's $1.25B/month Colossus deal).
Who is it for?
AI infrastructure analysts, hyperscaler-watchers, and anyone tracking the economics of frontier compute.
|
|
|
All releases at ai-tldr.dev
Simple explanations • No jargon • Updated daily
|
|