
|
|
ECOSYSTEM
MAJOR
2026-06-05
Google to Pay SpaceX $920M/Month for 110,000 NVIDIA GPUs Through 2029
Google rents 110,000 NVIDIA GPUs from SpaceX for $920M a month to fill a Gemini Enterprise capacity gap through mid-2029.
What is it?
A 33-month compute supply contract between Google and SpaceX, disclosed in a SpaceX SEC free-writing prospectus filed June 5, 2026. The agreement covers roughly 110,000 NVIDIA GPUs plus accompanying CPUs, memory and infrastructure components.
How does it work?
SpaceX provides the GPU fleet from one of its data center sites starting October 2026 through June 2029. Google can invoke a 90-day cancellation window after December 31, 2026, and reduce fees if SpaceX misses the September 30, 2026 delivery milestone.
Why does it matter?
Google rarely buys frontier compute from a third party — it usually builds. The filing is hard evidence that demand for Gemini Enterprise is outrunning Google's own TPU buildout. Combined with Anthropic's $1.25B/month Colossus 1 lease, SpaceX is now the single largest discretionary compute landlord for two of the top four labs.
Who is it for?
AI infrastructure investors, hyperscaler capacity planners, and anyone tracking the compute arms race between frontier labs.
|
|
|
|
SECURITY
MAJOR
2026-06-05
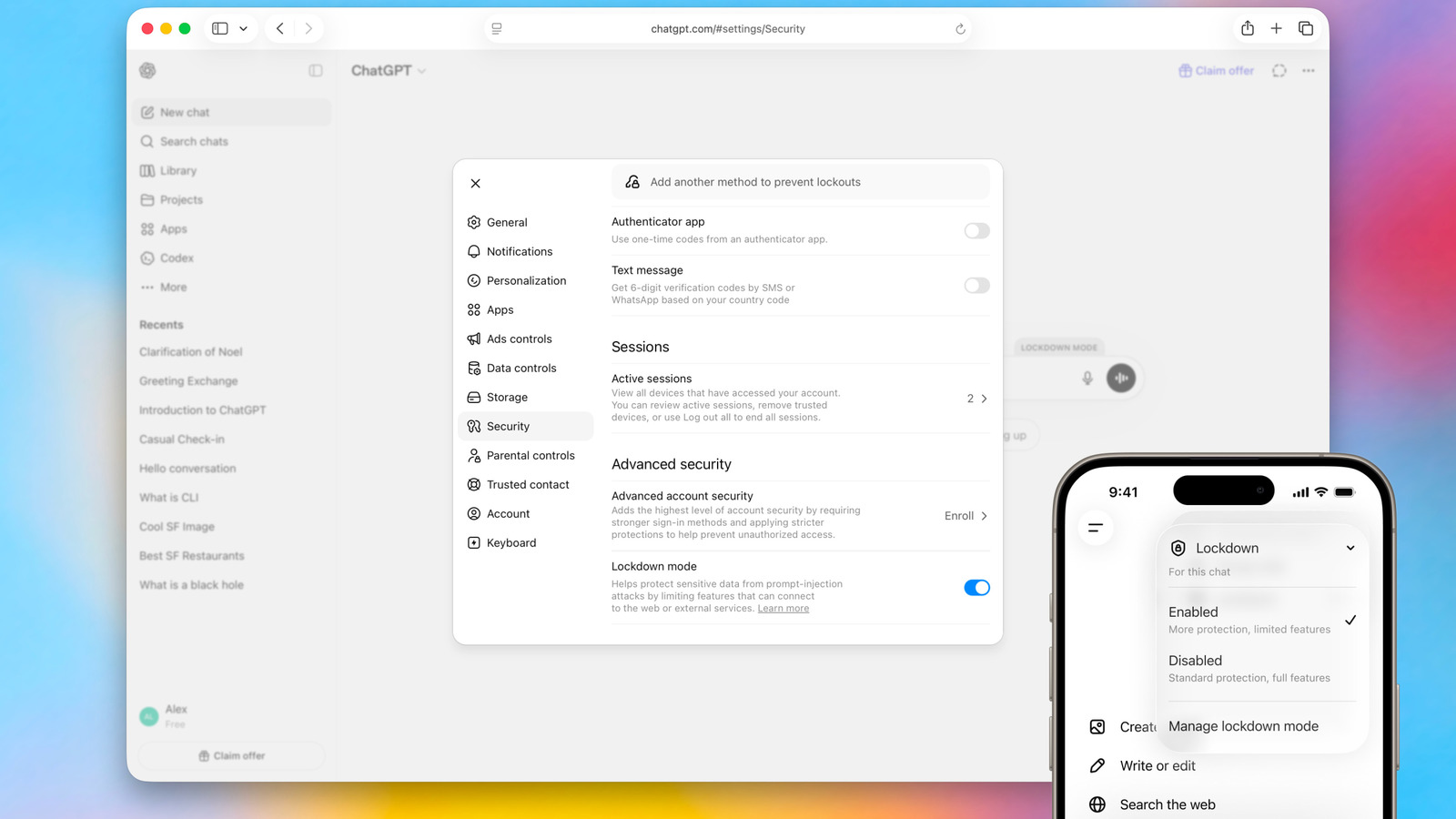
OpenAI Rolls Out Lockdown Mode to Free, Plus, Pro, and Self-Serve Business
OpenAI's deterministic patch on the "final stage" of prompt-injection attacks now reaches free ChatGPT users.
What is it?
Lockdown Mode is an optional security toggle in ChatGPT that switches off the network-enabled features attackers use to exfiltrate data once a prompt injection lands. First teased in February 2026 for enterprise plans, it is now rolling out to Free, Go, Plus, Pro, and self-serve ChatGPT Business accounts.
How does it work?
Enabled from Settings → Safety and security → Advanced security, the mode blocks outbound network requests, disables Deep Research and Agent Mode, refuses file downloads for analysis, and stops the model from pulling images from the open web. OpenAI describes the controls as deterministic — not gated by another AI that could itself be subverted.
Why does it matter?
Pushing the hardened mode to the free tier puts a prompt-injection-resistant ChatGPT in front of anyone who handles sensitive content. The toggle directly attacks the "data exfiltration" leg of the Lethal Trifecta — private data plus untrusted content plus an outbound channel.
Who is it for?
People and teams handling sensitive data in ChatGPT — legal, finance, HR, and anyone pasting confidential content into AI chat interfaces.
|
|

|
|
MODEL
MAJOR
2026-06-05
Google Ships Gemma 4 QAT Checkpoints — E2B Under 1GB of RAM on Mobile
Gemma 4 shrinks to under 1GB on phones via a custom 2-bit mobile quantization format trained with QAT.
What is it?
Post-training checkpoints for Gemma 4 compressed using Quantization-Aware Training (QAT) instead of standard post-training quantization. Two formats ship: the popular Q4_0 used by llama.cpp, and a new Google mobile format using 2-bit decoding layers with static activations.
How does it work?
QAT simulates integer rounding during fine-tuning so the model learns to be robust to the quality drop that post-training quantization introduces. Google reports QAT yields higher quality than PTQ baselines at matching bit-widths. The mobile format pushes generation layers to 2 bits while keeping activations static.
Why does it matter?
The E2B text-only variant fits in under 1GB of RAM, putting a real multimodal-trained Google LLM inside the budget of mid-range phones. Day-one support across Ollama, LM Studio, vLLM, MLX, and Transformers.js means new weights drop straight into the existing local-LLM tooling stack.
Who is it for?
Local-LLM hobbyists, on-device app builders, and mobile ML engineers targeting sub-1GB model budgets.
|
|

|
|
MODEL
MAJOR
2026-06-04
NVIDIA Nemotron 3.5 ASR Streaming 0.6B — ~17× More Concurrent Streams, 40 Locales
A 600M-param open ASR model that streams 40 locales from one checkpoint and squeezes ~17× more concurrent voice sessions onto an H100.
What is it?
NVIDIA's first open multilingual streaming speech recognizer, successor to the English-only Nemotron 3 ASR. One checkpoint handles 40 language-locales including English, Spanish, German, French, Japanese, Korean, and Mandarin — with built-in punctuation and casing, under the commercial-friendly OpenMDW-1.1 license.
How does it work?
A Cache-Aware FastConformer-RNNT encoder processes each audio frame exactly once and reuses cached encoder states for new chunks, eliminating overlapping computation found in traditional buffered streaming. Runtime-tunable context size lets developers pick latency points between 80ms and 1.12s.
Why does it matter?
Real-time voice agents have been bottlenecked on either accuracy (cloud APIs) or throughput (open streaming models). A 0.6B model that fits 17× more concurrent streams onto an H100 collapses the per-session cost of voice assistants, call-center transcription, and live captioning.
Who is it for?
Voice-agent and call-center teams, real-time captioning products, and on-prem deployers who need high-throughput multilingual ASR.
|
|

|
|
REPO
MAJOR
2026-06-05
Nous Research Ships Hermes Agent v0.16.0 'The Surface Release'
Nous Research's self-improving agent gets a native desktop client and a no-config web admin panel; the project crossed 183K stars on the same day.
What is it?
Hermes Agent is Nous Research's open-source self-improving AI agent that runs across CLI, terminal UI, messaging platforms (Telegram, Discord, Slack, WhatsApp, Signal), and now native desktop. It learns user-specific skills, persists memory across sessions, and spawns parallel subagents through 40+ integrated tools and MCP server support.
How does it work?
The Surface Release adds an Electron-based desktop app with one-click installation, in-app self-updates, drag-and-drop file support, and multi-profile sessions that connect to local or remote Hermes instances via OAuth. A new browser admin panel replaces manual config-file editing for messaging channels, MCP catalog, credentials, and webhooks.
Why does it matter?
Hermes has been one of the most prolific open-source agent harnesses but was previously CLI/TUI-first, blocking non-technical users. A native desktop binary and zero-config web admin meaningfully widen the addressable surface for self-hosted agents.
Who is it for?
Developers and power users who want a self-hosted, multi-platform AI agent with messaging integrations — without touching YAML config files.
|
|

|
|
ECOSYSTEM
MAJOR
2026-06-05
Ladybird Browser Stops Accepting Public Pull Requests — AI-Generated Code Breaks the Good-Faith Assumption
An indie browser project pulls up the drawbridge: no more public PRs, citing AI-generated contributions and supply-chain risk.
What is it?
Ladybird, the independent C++/Rust web browser led by SerenityOS creator Andreas Kling, announced it will no longer accept public pull requests. All open public PRs will be closed; going forward only project maintainers can land code. The change lands as the project moves toward its first alpha release.
How does it work?
Kling frames the change as a response to two pressures: AI coding tools have made it trivially cheap to generate substantial-looking patches, so a large PR no longer correlates with effort or skill. And browsers run untrusted code from the entire internet — one well-disguised vulnerability is enough to compromise users. The team explicitly rules out shadow contribution via issues or email.
Why does it matter?
Ladybird joins SQLite — which hardened its "does not accept agentic code" stance in May — in treating AI-generated contributions as a load-bearing reason to change maintainer policy. For agent operators whose users routinely fire off PRs at open-source projects, it's a concrete signal that some maintainers will reject the workflow outright.
Who is it for?
OSS maintainers, security-sensitive project leads, and agent operators who need to update how they communicate AI-assisted contributions to upstream projects.
|
|

|
|
ECOSYSTEM
MAJOR
2026-06-06
Sriram Krishnan Stepping Down as White House Senior AI Policy Advisor at End of June
Trump's top AI policy advisor exits the White House at month-end to build an outside institution shaping US AI policy on energy, data centers, and AI access.
What is it?
Sriram Krishnan, the ex-Andreessen Horowitz partner who has been senior policy advisor on AI at the White House for roughly 18 months, announced he will step down at the end of June 2026. He is the second high-profile AI staffer to leave Trump's AI policy operation this year.
How does it work?
Krishnan's portfolio covered the administration's AI Action Plan, federal posture on state-level AI regulation, data center buildout, chip and export controls, and US government equity stakes in AI companies. His departure leaves no announced successor as the administration negotiates state-preemption legislation and an OpenAI equity stake.
Why does it matter?
The senior AI advisor seat coordinates AI-related work across federal agencies and is the primary funnel for industry input into White House policy. A vacancy at the top — coupled with Krishnan's plan to keep influencing the same agenda from outside via a new institution — reshapes how labs, infrastructure providers, and state regulators reach the administration.
Who is it for?
AI policy watchers, lab government-affairs teams, and infrastructure investors tracking federal AI regulatory posture.
|
|
|
All releases at ai-tldr.dev
Simple explanations • No jargon • Updated daily
|
|