Newsletter - November 2025
2025 NOVEMBER 28
In this month’s issue:
Switchover to AWS and Rabbit MQ
MPC Explorer updates: Names
Latest of the ADES GitHub repository
1. Switchover to AWS and RabbitMQ
On Wednesday, 12 November 2025, the MPC completed a major upgrade to our ingestion and processing system. This switchover represents a significant milestone for our team and is the result of many months and years of development, testing, and preparation.
Ingestion system - the legacy system
Until this transition, our legacy ingestion workflow operated across three partially independent components:
Observations reached our webserver through two primary pathways:
ADES submissions (via curl or the webforms available on our website), validated using the ADES schema and formatting checks.
MPC1992 80-column submissions sent by email to obs@cfa.harvard.edu
Both pathways included initial validation steps to ensure correct formatting and basic internal consistency.
After intake, submissions were transferred to our internal server where:
They were ingested into the appropriate PostgreSQL tables, and
Routed to the correct processing queue, such as, for example, NEOCP or extension processing for orbit fitting, as required.
Once validation and processing were completed successfully, a confirmation email was sent to the submitter. This marked the final step of the legacy pipeline.
Ingestion system - the AWS system
The upgraded system now cleanly separates the ingestion and processing components of our workflow.
Observation ingestion now takes place on an Amazon Web Services (AWS) EC2 instance. From the user’s perspective, nothing about the submission interface has changed, the same endpoints and formats are supported, but behind the scenes, all submissions are now redirected to the new AWS-based entrypoint.
Internally, this transition required a complete re-engineering and restoration of the underlying infrastructure. The legacy components have been fully replaced or reconstructed.
In preparation for the switchover, the new ingestion system had already been running in parallel with the legacy pipeline for an extended period. This allowed us to thoroughly test stability, identify edge cases, and implement performance improvements well before the cutover.
The system has also been exercised extensively through coordinated testing with the Vera Rubin Observatory/LSST and NEO Surveyor teams. These collaborations involved multiple rounds of end-to-end ingestion tests to ensure the new architecture would support high-volume, real-time data streams. Thanks to this preparation, the transition for our users has been designed to be as seamless as possible.
What changed for Users?
Several improvements were introduced with the new system to make the submission experience clearer and more informative:
The messages generated by the new ingestion pipeline now include additional diagnostic information. When a submission fails, the email should make it easier to understand why it failed and at which stage the issue occurred.
Every submission now receives a unique submission_id, even in cases where the data is rejected. This improves traceability and allows both users and the MPC team to reference and investigate issues more reliably.
Below is an example of how a rejected-submission email now appears in the new system:
The submission with the ACK line:
<Your ACK line>
has been rejected due to the following problems:
ADES schema validation failed: ERROR ON LINE <line number>:
<explanation of the error>
ingest failed
Please fix and resubmit.
Please note that the above list of problems may not be exhaustive.
For reference, the following submission ID was assigned to this submission:
<submission_id>
We also identified a change in the length of the trkIDs generated by the new system. These identifiers are now 12 characters long, rather than the previous 10. Our internal software is able to handle both formats seamlessly, which is why the change was not immediately apparent during testing. Once users reported the discrepancy, we were able to confirm the behavior and document it right away. We apologize for any inconvenience this may have caused and appreciate the community’s attention in helping us identify and resolve issues quickly.
Queueing and processing system - RabbitMQ & PyOrbFit
As described in our February 2025 Newsletter, we have been developing a fully modernized orbit-fitting and processing pipeline built using contemporary software engineering practices. This new system uses RabbitMQ, a high-performance messaging and streaming broker, to route each ingested tracklet into the correct processing path with far greater efficiency and transparency.
Implemented as a Python package and deployable through Docker, the pipeline offers a flexible, modular architecture. Its design supports dynamic scaling, making it well-suited to our new cloud-based infrastructure in which processing cores can be allocated on demand.
After observations are ingested through our AWS entrypoint, they are replicated to Cambridge (MA). From there, our RabbitMQ-based queuing system distributes each tracklet to the appropriate processing queue, such as NEOCP, extension, recovery, etc, ensuring a consistent and robust workflow.
While much of the new queuing system and orbit-fitting pipeline had already been running in parallel with the legacy system over the past several months, allowing us to test, validate, and refine substantial portions of the code, other components could not be exercised ahead of time due to structural limitations of the legacy pipeline.
As a result, following the switchover, some users may have encountered a higher-than-usual number of issues affecting a few highly specific services (e.g. the recovery page). These cases stem from modules that only became fully active once the legacy system was retired, and therefore could not be tested under real production conditions beforehand.
We have been working intensively over the past several weeks to address all outstanding problems, both those visible to users and those occurring only internally. Many of these fixes required substantial coordination across multiple components of the new system, and we appreciate the community’s patience as we resolved them.
The always awesome XKCD comic well describes our past months.

The new Grouping Mechanisms
One of the most significant improvements introduced with the new system is the ability to automatically group observations that are close in time, right ascension, and/or declination.
Historically, one of the major challenges for the MPC has been the automatic handling of exact duplicates (identical submissions) and near-duplicates (what many users refer to as remeasurements).
And if you believe you’ve never submitted the same observation twice, or never resubmitted a remeasurement without knowing it, well… you might want to reconsider!
With the upgraded ingestion system, these checks now occur immediately at submission time. The pipeline evaluates whether a newly submitted observation is an exact or near-duplicate of an existing one and then, after orbit fitting and cross-referencing with additional metadata such as program codes, automatically determines:
which observations should be included in the orbit fit, and
which observations should be used only for discovery credit, if applicable.
This capability is a huge step forward in reducing manual intervention, improving data consistency, and it helps ensure that the MPC continues to maintain a clean and reliable global dataset.
Several users have already begun taking advantage of this new functionality as we continue asking for remeasurements to help test and refine the system. We are also actively tuning the duplicate-detection logic to better handle a number of edge cases, some of which were nearly impossible to anticipate during the testing phase. (It turns out you can submit some truly remarkable combinations of observations that we never would have imagined!)
These ongoing adjustments are helping us strengthen the robustness of the new pipeline and ensure it performs reliably under all real-world scenarios.
Once we believe that the system is ready to support a large-scale ingestion of remeasurements, we will get in contact with some of our users that have been waiting for this feature for a long time.
We will also provide more detailed information in the next newsletters.
Nearly everyone at the MPC has played a role in this switchover, the scale of the transition simply would not have been possible without the dedication of the entire staff. However, a special shoutout is very much deserved for Brian Burt, whose work made a substantial portion of this upgrade possible.
As always, when you open a Jira ticket or report an issue, please remember that there are real people on the other side working hard to improve the system and to provide you with the most accurate, consistent, and easily usable dataset for your science.
The new Program Code policy
Not to forget that, while working on the switchover, the new program code policy took place (see our October 2025 Newsletter for more detailed information). We thank our users that already contacted the SARC committee and for your patience while we were working through this new system.
2. MPC Explorer updates: Names
As if the switchover were not enough, we have also introduced new features to MPC Explorer (see Fig. 1).
The latest update adds dedicated lists for all objects that have received an official name from the Working Group on Small Body Nomenclature (WGSBN).
As a reminder, the Minor Planet Center is not responsible for naming, we simply report and maintain the information provided by the IAU working group. These new lists make it easier for users to browse, search, and explore the catalog of named small bodies.
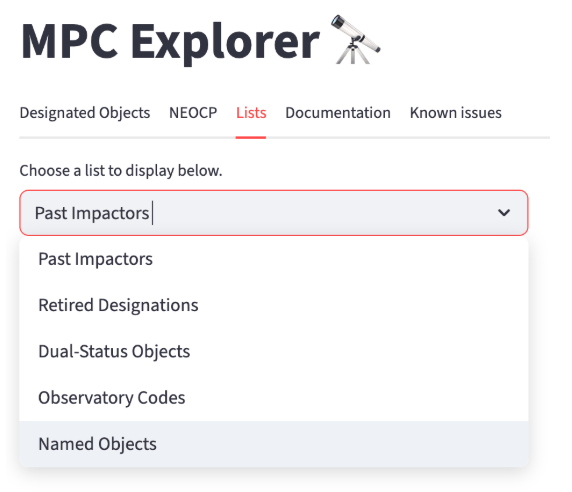
Objects are further organized into categories based on their object class (e.g., minor planets, comets, etc.). Each category can be selected directly from the menu, as shown in Fig. 2, allowing users to easily navigate and filter the lists according to their interests.
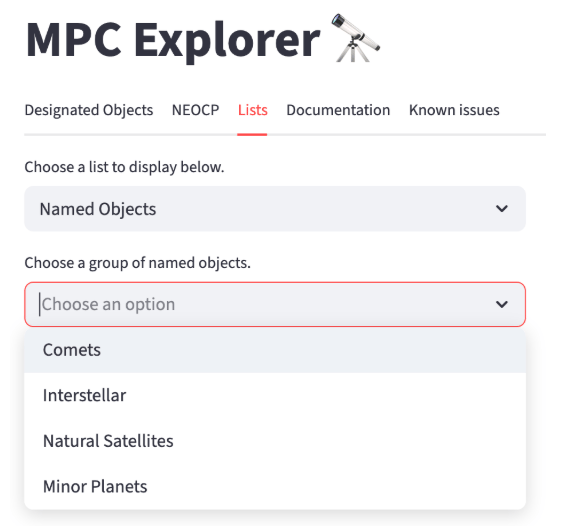
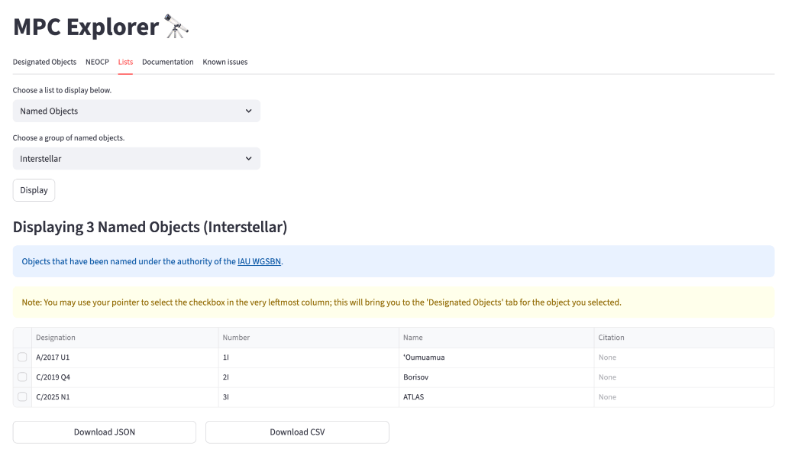
Figure 3 shows an example of the page layout when the “Interstellar” option is selected. Please note that all list pages share the same overall layout.
Selecting any object within the list automatically redirects you to its main object page, which includes designation information, available observations, orbital data (when available), and other relevant details.
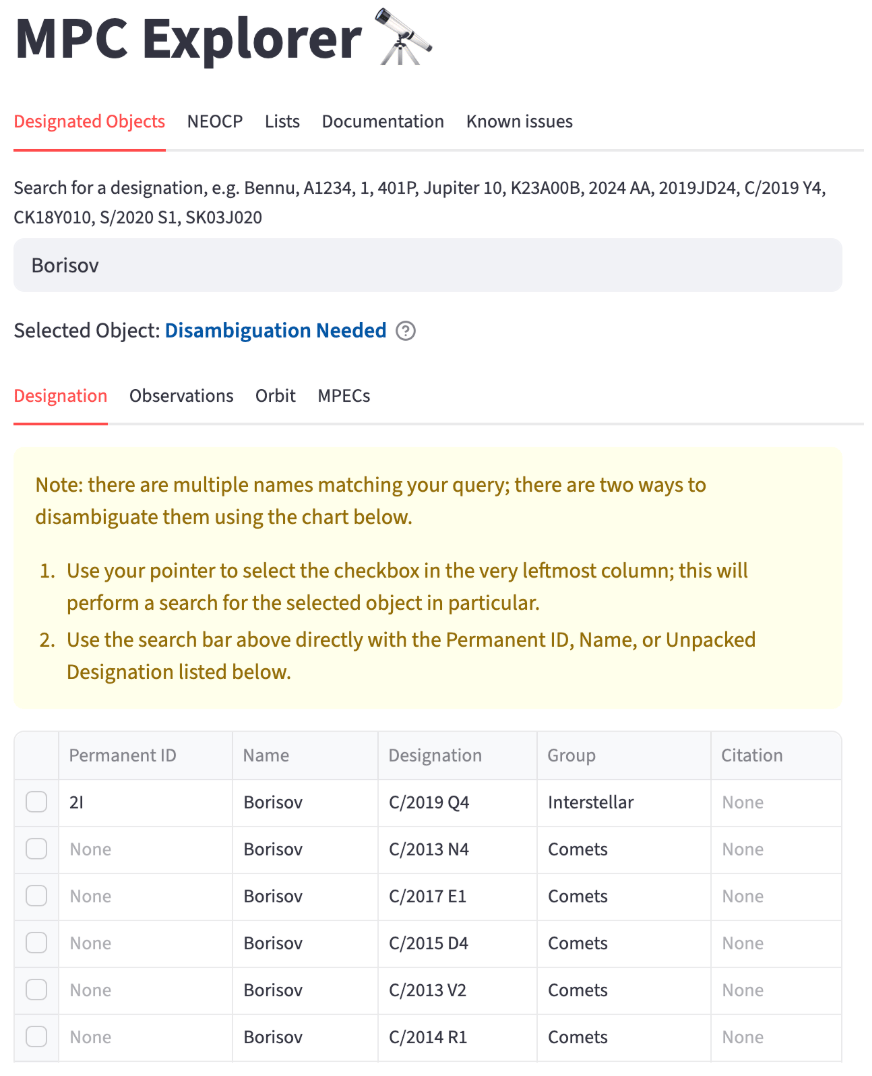
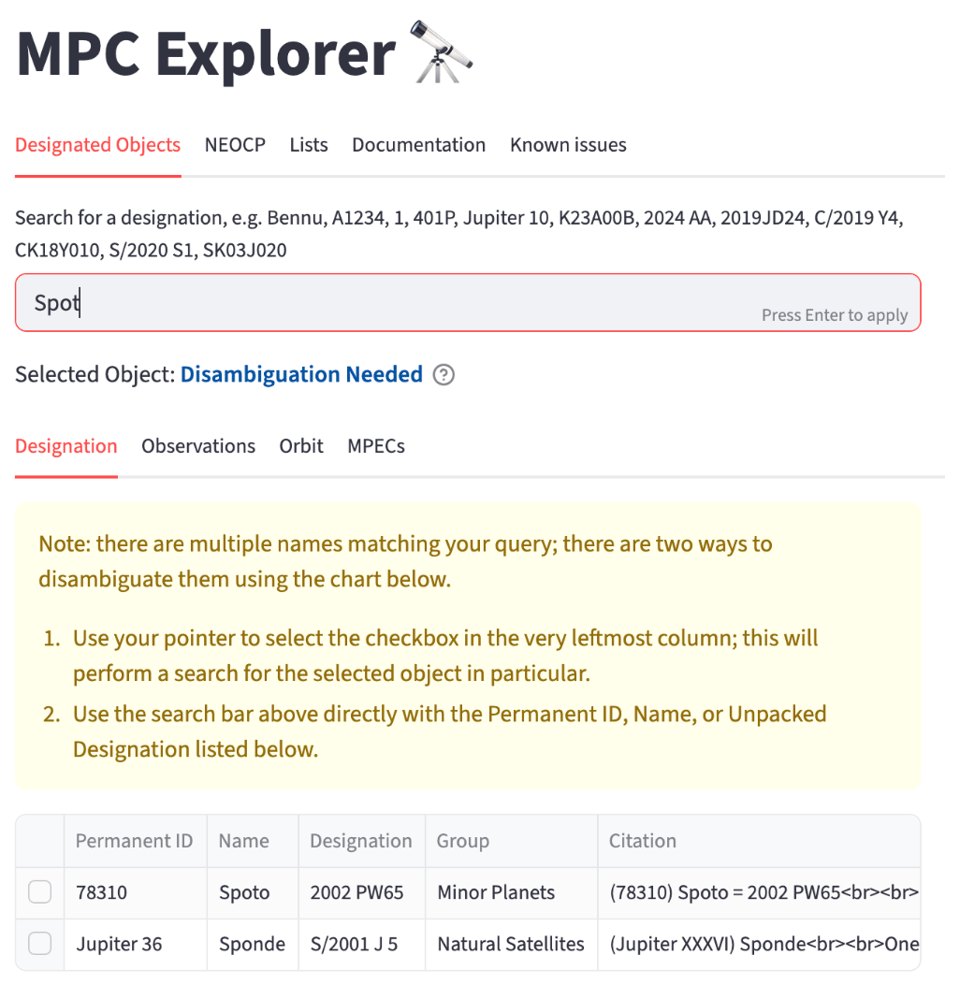
The MPC Explorer now includes the fuzzy name-matching capabilities. This allows users to find objects even when they are unsure of the exact spelling or formatting of the name. The updated name lookup provides a more flexible and user-friendly way to navigate the catalog (see Fig. 4 and Fig. 5).
APIs
The Designation Identifier API has also been expanded to support fuzzy matching and wildcards within queries, allowing more flexible ways to look up objects when only partial or approximate information is known. The documentation and examples have been updated to reflect these new options and can be found at:
https://minorplanetcenter.net/mpcops/documentation/designation-identifier-api/3. Latest on the ADES GitHub repository
The Python code in the ADES GitHub repository, jointly maintained by JPL and the MPC, is now available as the iau-ades package distributed via the Python Package Index (PyPI): credit to Steven Stezler at JPL for his work on this.
Installation is straightforward:
python -m pip install iau-ades
This improvement makes it significantly easier to use the ADES tools in your own workflows. For example, if you would like to convert your MPC1992 80-column observations into ADES XML (which we strongly encourage, if you are not already submitting in ADES format), you now have several convenient options:
1. From command line:
mpc80coltoxml.py <yourobs80filename> <thenewXMLfilename>
2. Inside your Python code:
from ades import mpc80coltoxml
mpc80coltoxml.mpc80coltoxml(obsfile, xmlfile)
If you have any questions about ADES, please feel free to contact us through Jira. For feature requests, bug reports, or suggestions related to the ADES tools themselves, please open an Issue in the ADES GitHub repository.
Add a comment: