AI for them vs. AI for me
by Matt May
Happy Monday! I’m back from a long swing through California, and I am resolved to never ever leave home again. For at least a couple weeks.
Today, I want to talk about the economics of modern tech. You should be aware by now that software is now, more often than not, offered a service rather than a purchase. Every modern operating system (save Linux) is now essentially subsidized by the sale price of the device it runs on, as well as the (usually) 30% cut the OS vendors take from apps sold via their own app stores. You can still buy console video games on discs for $60 or $70 a pop, but online play requires a monthly subscription to the game console vendor, and sometimes a second one to the maker of the game. And don’t get me started on streaming.
Understanding the finances that sustain operating systems and apps is important, because it indicates the precise nature of your business relationship with the vendor. Take Facebook, for example. Obviously, Facebook and other Meta apps like Instagram and WhatsApp are “free” from every app store. But when you look at what kind of data they collect, you will see it is not so much a social network as a no-holds-barred clearinghouse for just about anything it can get to on your device (including the device’s hardware ID, your health data, purchases, sites visited, app usage, precise location, contacts, and so on).
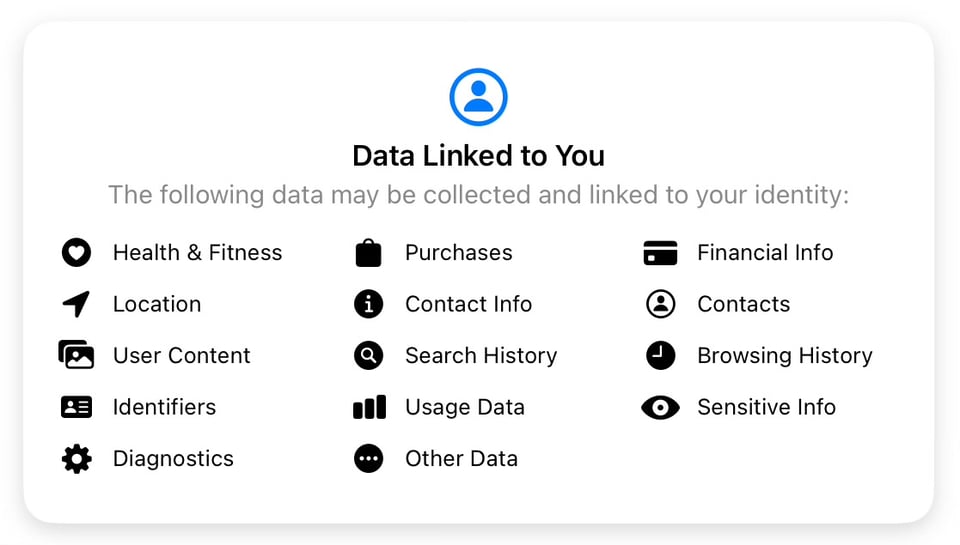
I’ve often joked that the number one solution to any device’s battery life problem is “delete Facebook.” Give it a try. You’d be amazed at how much of your system resources Meta apps take up, running in the background, turning on your GPS and phoning home.
Bottom line: apps cost more to operate than they charge you to use, which means they commonly use all manner of tricks to turn a profit. It’s been a common refrain dating back to the 1970s that “if you’re not paying for the product, you are the product.” But in 2024, it’s safe to say that even in most paid and subscription apps (including streaming services), you are both the customer and the product.
I’ve been thinking about this lately because I believe we’re reaching a point where just about any new device is more or less good enough for any general computing task. But more and more, those devices are weighed down by processes that don’t serve us, the users, but are used instead to capture our data in order to sell us out. This good-enough hardware is also being artificially obsoleted by end-of-life announcements and CPU throttles, forcing unnecessary upgrades that fuel excess device capacity, and the environmental damage that ensues.
And that’s the setting for the AI wave. In a way, large language models are just a bulk form of surveillance capitalism: they’ve scraped the internet to grab everything they can find out about us as a society, in order to sell it back to us one prompt at a time. Generative AI has a tremendously high barrier to entry, where model training can cost tens of millions of dollars per run. This has fueled a technology boom, mostly in data centers, where they can’t deploy GPUs fast enough for the demand, which in turn has led to one set of trillion-dollar companies—Google, Microsoft (and by extension, OpenAI), Amazon, Meta—giving rise to another in Nvidia, their main supplier. You can call AI a lot of things, but “democratic” isn’t among them.
That said, there’s at least some hope to make AI useful to individuals, without a lifelong dependency on big tech. I’m a fan of both Simon Willison and his blog, where he documents many of his own experiments with AI. Simon really likes running models on his own hardware, and has talked about his early experiments running models on his iPhone. (Edit: I originally wrote that he was doing code generation on-device, but Simon has corrected me: he was running a model remotely from his phone.) I’m actually reasonably confident that within a couple years, and maybe even by the end of 2024, I’ll be running a GPT-4-equivalent LLM on my MacBook Pro. I already have a few, including Mixtral 8x7B and Rubra, which run at a decent clip, as well as OpenAI’s Whisper speech-to-text model. What I’d really love is to see more multimodal models, which would open up lots of cool image recognition and manipulation capabilities.
(I’m struck with the irony that Meta, the company I don’t trust to run code on my phone, is also the creator of Llama, the very technology that enables these models to be run without ever contacting a server. I wonder how that’s going to work out for them, now that the horse is out of the barn. But I digress.)
Back to the economics: as of right now, you have a small number of enormous companies in control of large and capable models, along with most of the capacity to build and host them. Running on top of those is a staggering number of “AI companies” who do little more but pipe the models they’ve licensed into chatbots and the like. I believe a lot of those will fail over the next year because they don’t understand the models they’re relying on, and they’ll get undercut or Sherlocked as soon as OpenAI et al. decide they want more revenue.
It seems to me that what we’ve seen so far could be classified as “AI for them.” These repackagers of the AI models are selling a single solution to business customers as a one-size-fits-all approach for what they consider low-value work: content writing, graphics, basic coding, captioning, translation, marketing tasks, and so on. Some of the momentum here is already starting to fizzle. Once the cost of a task has gone from dollars to pennies, there’s not much more you can squeeze out of it.
Where I think the real value, if any, will be in AI is in what I’d call “AI for me.” I want a model that gives me a good enough experience out of the box, but that gets fine-tuned on my own interaction with it. We’re still beholden to large providers for training these models for the foreseeable future, so I’d want to be assured the base model is trained ethically (though my thoughts on what this would entail is a whole other post). Above all, I want it to be mine: completely private, growing with me in capability, absorbing more about me, including my capacities, needs and preferences, but not spilling it to any third parties. An assistant that I direct, not an intelligence that directs me.
I think I’m going to get it. But how soon? And when will this be something that can run on the commodity hardware of the day, worldwide? Only time will tell.