VLDB Reading List #1: TUM Edition

VLDB just happened! And I have been going through some of the papers that caught my eye. As it turns out, this week is TUM week.
What Modern NVMe Storage Can Do, And How To Exploit It: High-Performance I/O for High-Performance Storage Engines
I briefly met Viktor Leis at CIDR in 2019, and was very excited to tell him what an impression his paper How Good Are Query Optimizers, Really? had made on me, as far as giving me a base of intuition for how to think about query planning, which I had just started doing professionally. He told me that he was moving away from working on query planning to working on SSDs, which he thought deserved more attention than they had gotten. Luckily for me, my own professional journey of working on query planning to now working on storage has trailed his by a couple years, and this paper does a good job of giving me the same kind of intuition that one did (I'm less familiar with Gabriel Haas's work, but if he has more like this, I'll keep an eye out).
I have a confession, which is that I've generally always been terrible at back-of-the-napkin math for computer stuff. Those tables of "important latency numbers" to know have never really stuck with me. I've gone as far as making Anki cards to try and get things like "approximate cost of a branch mispredict" to stick and I have thus far been unsuccessful.
Something that has been effective for me in building intuitions around this sort of thing is narratives. And this paper provides a great one for me. "We concocted a monstrosity with the potential for 12 million IOPS. How hard is it to actually hit that number, and what engineering challenges does that bring?"
The paper is generally about whether the kinds of IOPS (I/Os Per Second) numbers reported by high-end flash drives are actually attainable in practice. For me, there was a lot of value in seeing how to do this kind of quantitative analysis of performance. I enjoyed the analysis of (and qualitative justifications for) various tradeoffs in storage:
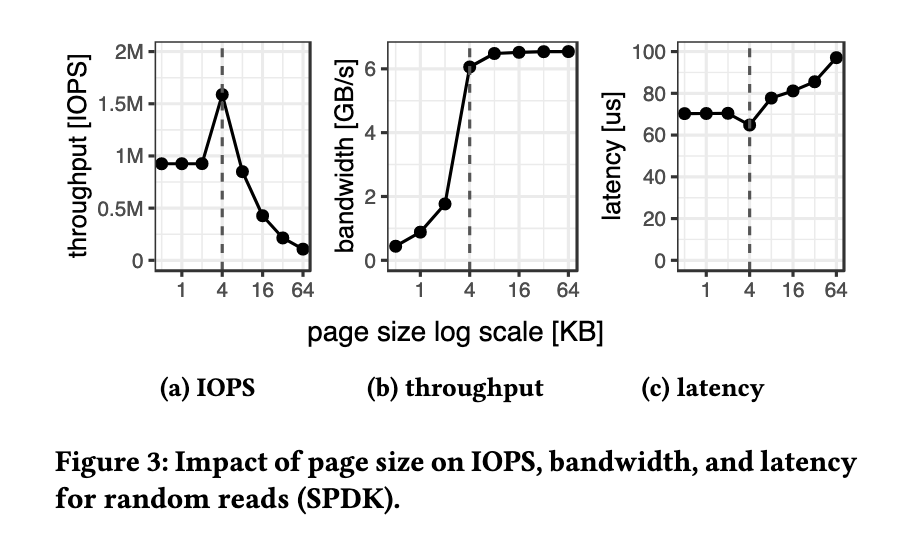
The conclusion of the paper is that, yes, it is possible to attain the IOPS advertised by these arrays of high-end drives, but it requires some additional engineering that wasn't essential when using slower, fewer drives.
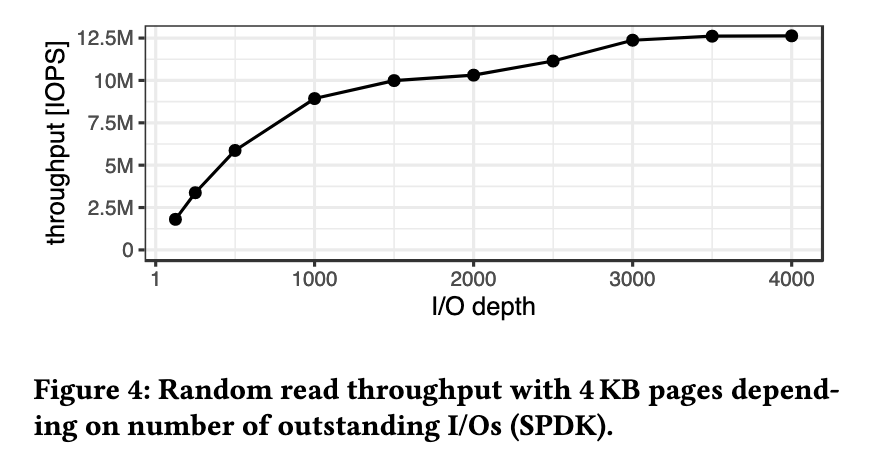
The other highlight for me was a comparison of the various IO interfaces that one might use to try to take full advantage of drives like this, and at least some kind of way of thinking quantitatively it:
The cost of not using SPDK in terms of CPU cycles is relatively high.
Figure 16 shows that in in-memory workloads all CPU time is used for actual transactional workload. Going out of memory in the usual setting with 1000 TPC-C warehouses and 16 GB of RAM, a lot of time is spent on eviction and I/O submission. Eviction is very similar in all out-of memory workloads around 14%, except with SPDK it is slightly higher (18%), as it is proportional to the transactional share, which is higher when using SPDK. This is mainly the case because submitting IO requests is much more efficient in SPDK (≈2% vs. 16-19%). This is less a matter of the interface, but the inefficient implementation of the I/O path in the Linux kernel (v5.19.0-26). We run the experiment also with I/O submission batching (+3% in throughput for kernel libraries) and with kernel mitigations disabled (+4% with kernel parameter mitigations=off). However, these two settings did not change the relative differences between kernel I/O libraries.
I don't know much about SPDK, though I do know that Jens Axboe (the author of io_uring) feels that it's not suitable for most use cases:
Research papers: "We're going to compare io_uring to {spdk,dpdk,whatever} and see what performs the best."
— Jens Axboe (@axboe) January 4, 2023
Also research papers: "We don't know how to configure polling, and we're on an ancient distro kernel."
I've yet to see one that is remotely interesting.
I always tell people to say no to spdk. It seems like a good idea until you realize what you have to give up. Spdk has its place, but it’s niche imho.
— Jens Axboe (@axboe) July 31, 2021
As far as I can tell, the criticism about outdated kernel versions doesn't apply here, they say they use kernel 5.19.0-26, which is fairly recent. They also explicitly use polling IO. I would be curious to know some of the specific criticisms around SPDK, because the results in this paper are fairly convincing to me.
I should emphasize that the drives being used here are extremely high end. They test using an array of 8 SSDs each providing 1.5 million IOPS, for a total of 12 million. This is a lot. According to the AWS docs I was able to find, that's roughly four of the highest end storage-optimized instance they offer. For the situations that most people find themselves in, a good comparison for this paper is probably Staring Into The Abyss, to the extent that it almost borders on thought experiment.
Asymptotically Better Query Optimization Using Indexed Algebra
Query plans are, for the most part, represented internal to planners as trees of "operators." You can think of these operators as providing the common interface of a stream of rows.
A common way to do analysis of these plans is that you have some kind of general set of properties that can be inferred about a given operator, such as "the set of columns produced by it," "the set of values that this column could take on," etc. This is pretty natural way to do things, but it does make some things difficult, especially if you're trying to keep your trees immutable.
As an example, say you have a tree that looks something like this:
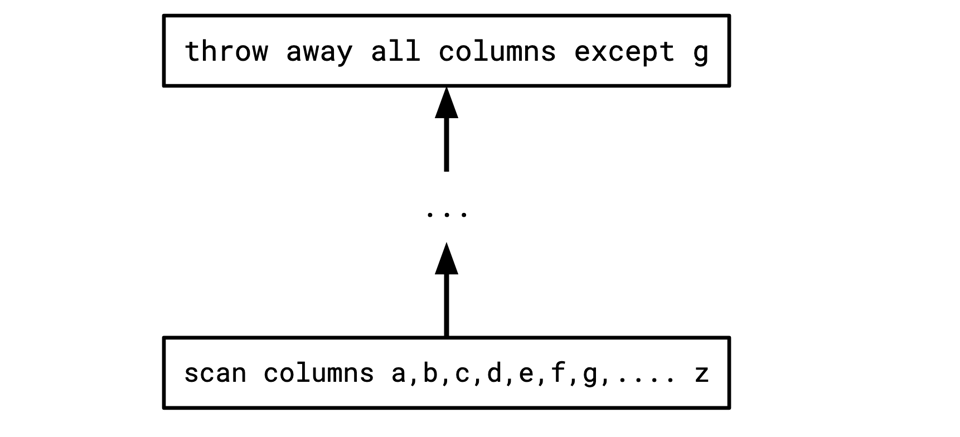
If we have the ability to scan more efficiently if we can ignore some columns, and none of the intermediate operators here make use of any columns besides g, we might want to rewrite this to something like this:
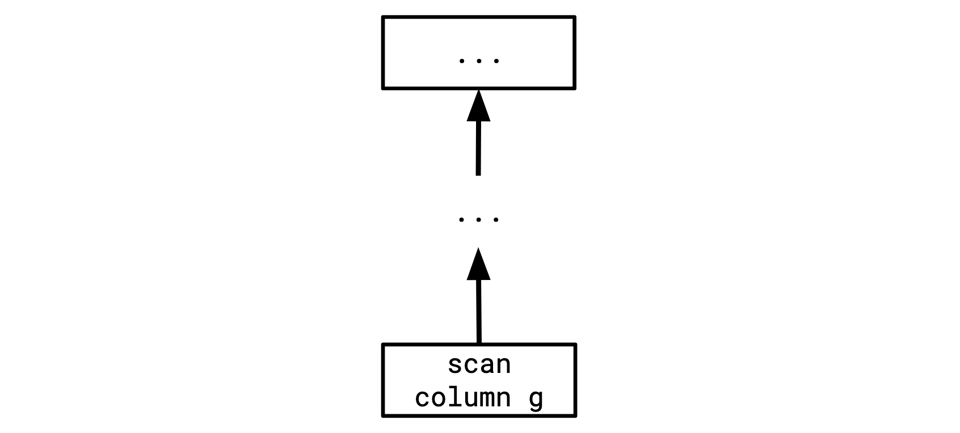
This kind of column pruning is desirable since it means we don't have to fetch the columns from the table, and we don't have to pass them along between every pair of operators, resulting in less data movement overall. In lots of planner architectures, I've found that this is actually a pretty annoying rewrite to do nicely. You often have to transmit information upwards operator-by-operator, and transmit information downwards via rewrites. This leads to some surprisingly complex code, and a lot of slow iterative rewrites of the tree.
I think one reason for the difficulty here is that this kind of rewrite is "non-local." It doesn't just involve an operator looking at its child, it has to go deep in the tree and make sure that the whole way down the tree is safe.
Asymptotically Better Query Optimization Using Indexed Algebra suggests another model for thinking about this kind of non-local reasoning. Instead of the fundamental unit being operators, and communication between operators, they propose that the fundamental unit of reasoning should be the path that a column takes through the tree:
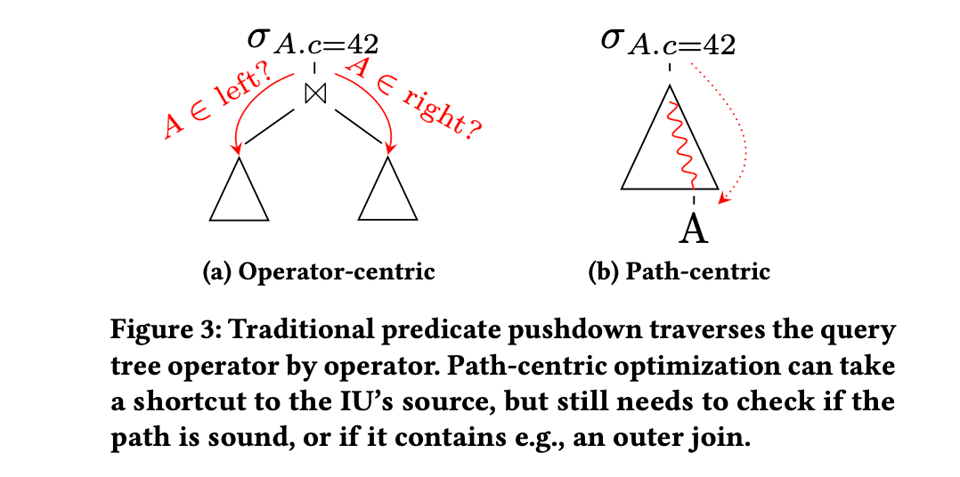
The paper talks about a number of optimizations that they claim this model makes simpler and also faster. They also cover a number of data structures for implementing this kind of design efficiently.
I haven't tried to implement this yet, or looked at any code, but it sounds plausible to me as a better, or at least a viable alternative to thinking about things in an operator-first way. The fact that each column effectively retains its identity as it travels through the tree always seemed like an indication of something structural. I definitely buy the argument that a lot of these things are a pain with the traditional approaches.
Conclusion
I'm planning on doing at least one more VLDB issue. If you have any additional context or corrections on any papers I call out, please feel free to reach out and let me know!
Add a comment: