Unified Memory Management

There's a trend in database memory management design that I'm really excited about, and that is rethinking the abstraction boundaries of the buffer pool.
I'm excited for it because, well, I'm a mark for the promise of a grand unified abstraction.
There are two main consumers of memory in a database. The first is the caching data from disk so it can be more easily accessed. Traditionally, databases solve this with what's called a buffer pool, which most people from other fields would most likely call a "write-through cache," but its semantics are generally specific enough that it's its own thing.
It's a big slab of memory composed of "pages," where each of those pages correspond to a page on disk. Then there's some careful logic to ensure that changes to these pages make it to the WAL and eventually back to disk itself once they're evicted from memory.
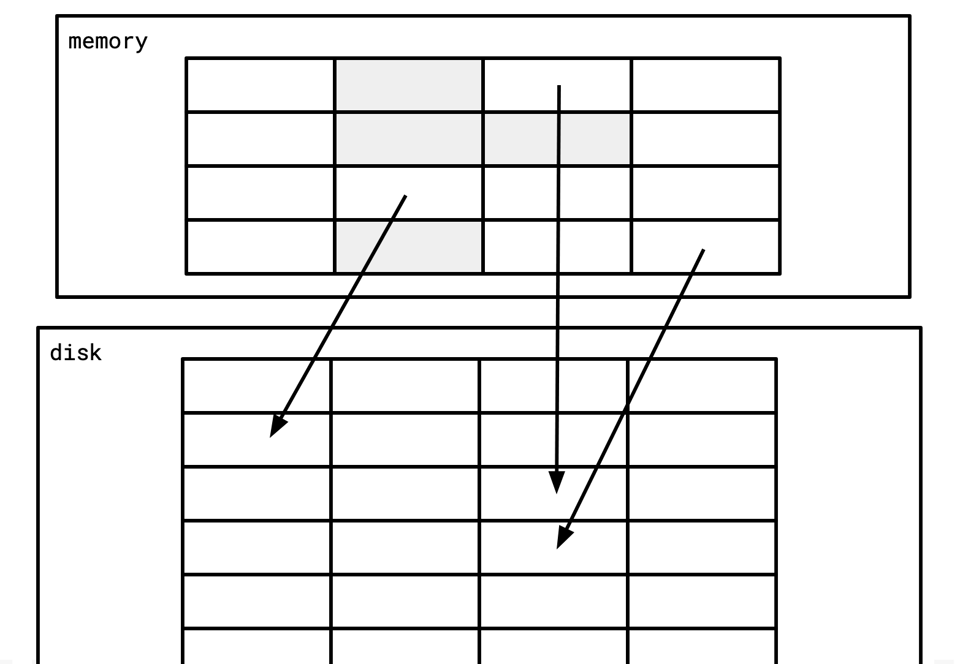
Tuning the buffer pool is a very important part of performance for a database. Tinkering with the buffer pool size is among the highest leverage knobs for tuning an installation of a database.
The second main consumer of memory is query processing. Lots of query operators use unbounded and unpredictable amounts of memory. Hash tables for aggregation, joins, scratch space for sorts—it in the realm of "basically impossible" to perfectly know the sizes of these ahead of time and so your database generally has to have some level of built in elasticity and flexibility when it comes to the amount of memory a query will use.
This means there are two mechanisms that are basically hard requirements of a query processing system:
- enforced memory limits so a query can be killed before causing the system to OOM, and
- spill-to-disk behaviour so a query can complete even if it would use more memory than available.
As an aside, this is a big reason I don't love Go for implementing databases, the language just doesn't really have great mechanisms to do the first thing. I've worked in a system where we made a "memory monitor" where we manually made note of any dynamic allocations that were occurring. This sucked (and everyone agreed) for a couple reasons.
- It was really easy to forget to track an allocation. Go makes dynamically allocating memory very quiet and just the normal process of writing Go code causes a lot of problems.
- It doesn't really...work. It's hard to predict how much actual memory, for example, a Go map will use. This is okay if you're willing to run the system with a lot of headroom but it doesn't make it super easy to sleep at night if you'd like to have tighter control over how memory is used.
Rust is better, but the standard library not having fallible allocations is also kind of annoying.
There is an emerging technique that recognizes that "hey, these two problems are actually pretty similar: they both want to carefully manage the dance of data between memory and disk and have some specific policies around how data can be moved between those two. What if we used the same mechanism for both of them?" What if we just used one big buffer pool for both of them?
DuckDB has a nice blog post about how and why they decided to implement something like this, and Otaki et. al have a really nice paper further exploring the idea and getting into some of the additional benefits and reasons why strictly bounding memory is good (multitenancy is a big one!)
I love this idea. It elegantly solves a lot of problems that I've personally experienced, and on top of that, opens up avenues to solve problems I hadn't even thought about: how can we cleanly serve workloads that are IO heavy and workloads that are query-heavy? Lots of general purpose SQL databases, especially for smaller deployments, are expected to do an adequate job on both of these things, and having a system that can allocate memory to whichever of these a system needs at a particular time without the operator having the manually resize things is pretty nice.
Obviously, this creates a lot of new problems too. Your buffer pool has to be more complicated to account for the fact that the pages need to be treated differently. The traditional buffer pool use of disk cares both about the fact that disk is both larger-than-memory and durable, but the query processing use cares only about the fact that it's larger-than-memory. Plus your query operators need to be written specifically against this kind of storage, I think you probably couldn't take an off-the-shelf query processor and easily have it work. You probably need to use a language with good manual memory management, like C++, Rust, or Zig to fully reap the benefits of it.
I hope we see more exploration of this idea in the future because I think it's really cool.
Add a comment: