The Three Places for Data in an LSM

We have talked before about how to conceptualize what an LSM does. I want to talk about another way to think through how we put together this data structure.
One way to think about what we want from a general purpose database is that it should provide three things:
- fast reads,
- fast writes,
- durability.
A BTree can sort of provide all of these at once, which I think is part of its appeal for introductory database materials: it’s a one stop shop. LSMs don’t work this way though: they have three different places they store data.
The Write Ahead Log
A log which can be appended to and read in full is the first place that data lives in an LSM. Think of it as a big list of the operations that we’ve performed against the database, like “set x to 5,” or “delete y.” In the event of a crash, we can replay these operations as though we are seeing them for the first time in order to recover them. However, we don’t have an index on the WAL: we can’t easily find the final place that x is set to some value. So the WAL provides fast writes and durability, but no fast reads.
The Memtable
The Memtable is simply an in-memory data structure that stores our data. This can be basically any classical, general-purpose data structure. Hashmaps, Btrees, and Skiplists are all things I’ve seen used here before. The purpose of the Memtable is to patch the hole left by the WAL: fast reads. The Memtable once against supports fast writes, but no durability.
On-Disk Indexes
The last piece of the puzzle is an on-disk, immutable index. These are often called SSTs, or Sorted String Tables. When our memtable gets too big (because memory is relatively limited compared to disk), or our log gets too long (because it contains too much redundant data, or because replaying the whole thing will cause our recovery to take too long), we then flush out the contents of the memtable to some sort of read-optimized immutable data structure on disk. Since this is an immutable data structure, it can be simpler than a traditional on-disk Btree, in both design and opportunities for concurrency. Later, when we have enough of these, we can merge several smaller SSTs into a larger SST to reduce the overhead of having to look at multiple files every time we do a read. If we’re careful we can generally keep the number of files logarithmic.
To summarize:
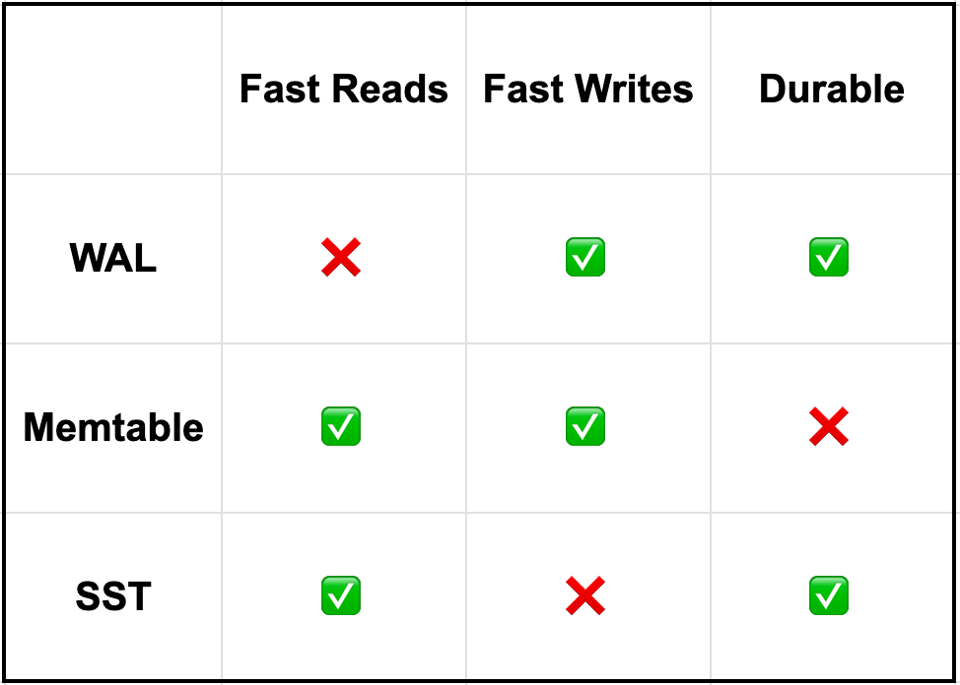
I think this is a pretty good way to think about a somewhat subtle, compound data structure: breaking it down into its constituent pieces and seeing what utility each of those provide in isolation.
This also hints at the customizability of the LSM as a general design space. The needs outlined here are specifically for a fully general-purpose database, in which we legitimately do need fast reads, fast writes, and durability. In a database that doesn’t need to provide low-latency reads, the memtable can be omitted. In a database that doesn’t need to provide durability (either because data loss is acceptable, or because durability is endowed by some external, replayable system like Kafka), the WAL can be omitted. I struggle to think of a problem space that needs a WAL and doesn’t also eventually need on disk indexes.
Add a comment: