Should We Have Been using LLMs for Our Test Queries This Whole Time?

Longtime readers of NULL BITMAP will know that I am bullish on metamorphic and in general, property-based testing for things that are SQL-shaped. I generally think that hoping to catch all of the edge cases and combinations of features by writing tests by hand, for something with such a wide surface area, is a bit of a fool's errand.
I like to describe techniques like this for testing as boiling the problem of testing down to two things:
- generating SQL queries, and
- turning those SQL queries into tests.
Metamorphic relations give us techniques for the latter. Things like Ternary Logic Partitioning are tools like this:
SELECT <foo>
=
SELECT <foo> WHERE <some_predicate>
UNION ALL
SELECT <foo> WHERE NOT <some_predicate>
UNION ALL
SELECT <foo> WHERE <some_predicate> IS NULL
The idea is to tickle the planner in such a way that issues are exposed automatically. And once you have your hands on a query, you can turn it into a test case like this "for free."
With enough good techniques like this, we can reduce the problem of testing to finding SQL queries to turn into test cases, which people have expended much effort on, using techniques that in effect, walk a randomly generated syntax tree.
One assumption you can pretty safely make about the requirements of such queries is that they don't actually need to be semantic. Ideally they return some data, and you probably want to finagle your query generator to generate queries that are likely to return some data, but they don't need to be like, meaningful in any way. As long as they match the grammar of a SQL query, they can expose bugs just as well as a query a user might actually want to run.
This assumption falls apart when we move from correctness testing to performance testing. Nobody really cares if a bit, monstrous, incomprehensible generated query is slow: I personally only care about queries that match my workload, and this matches nobody's workload.
Thus, the approach to performance testing for databases has typically been much more hand-tuned: a hand-written schema, and a small handful of hand-written queries, and maybe if you're feeling frisky, some parameters on top of that.
A recent TUM Paper asks: can we find a magic zone in the middle?
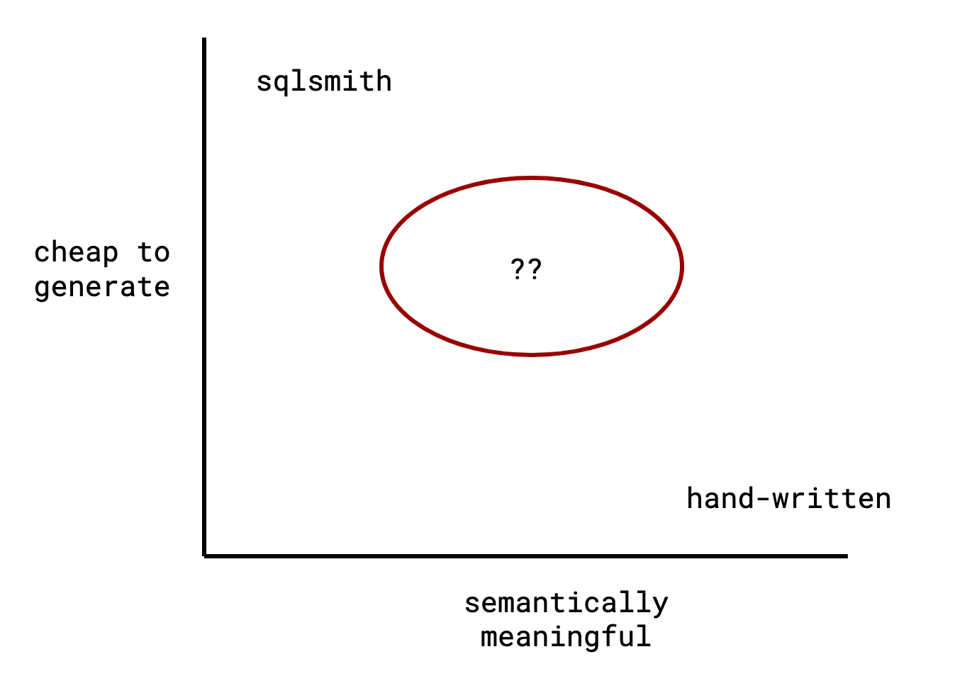
SQLStorm uses LLMs to generate large numbers of queries adhering to a particular schema:

The methodology is that the authors fix a schema (they use the StackOverflow dataset, you want a sufficiently rich schema that it's possible to compose a large number of nontrivial queries against it), and then ask an LLM to generate a query against it. They then filter out all the queries that don't run for whatever reason (as in, they use features that don't exist on a particular target database, or they don't parse, or they have runtime errors), and arrive at a core set of queries that run on all the databases they're interested in testing.
There are two things we can hope to get out of such a benchmark:
- that it's representative, as in, users can trust that the behaviour of a database on it is reflective of what their experience will be, and
- that it is revealing, as in, it has things to teach us about our own software.
For SQLStorm, (1) rests on the assumption that while the LLM queries are not necessarily representative of things that people want to do, they're closer to that then fully random queries, and if we generate enough of them, we can smooth out the noise and get something meaningful. I don't know if this is true, but it sounds plausible to me.
(2) is easier to verify empirically: if we can use these queries to find obvious performance problems, well, then, they're useful!
According to the authors, it was in fact very useful for such things:

TUM is not the only group interested in exploring the tradeoff space of "cheap to generate" and "semantically meaningful." IBM Research Europe has an interesting paper where they do something similar, and generate reasonable SQL queries for the purposes of training a different model to do cardinality estimation:

I'm generally quite bearish on the use of ML to do cardinality estimation: the implementations I've seen have seemed very fragile, hard to update, and expensive to generate compared to simpler, adaptive execution techniques. But I also know very little about ML stuff in general. I'm willing to believe this is a reasonable direction to go but I'm also willing to believe it's a trap, because it sounds so compelling.
It seems to me a trend of using LLMs in this particular way (generate test cases that sit in between "fully random" and "handwritten") is starting to pick up for databases, and, rather than bringing about the machine god or propping up the US economy, seems a very sane and exciting niche.
Add a comment: