Reification and Exchange

One thing I really like about the parse-plan-execute cycle of queries is the ability to reify various computations in a way that are often invisible, or hard to find, in a codebase.
"Where does the data in R get decompressed?"
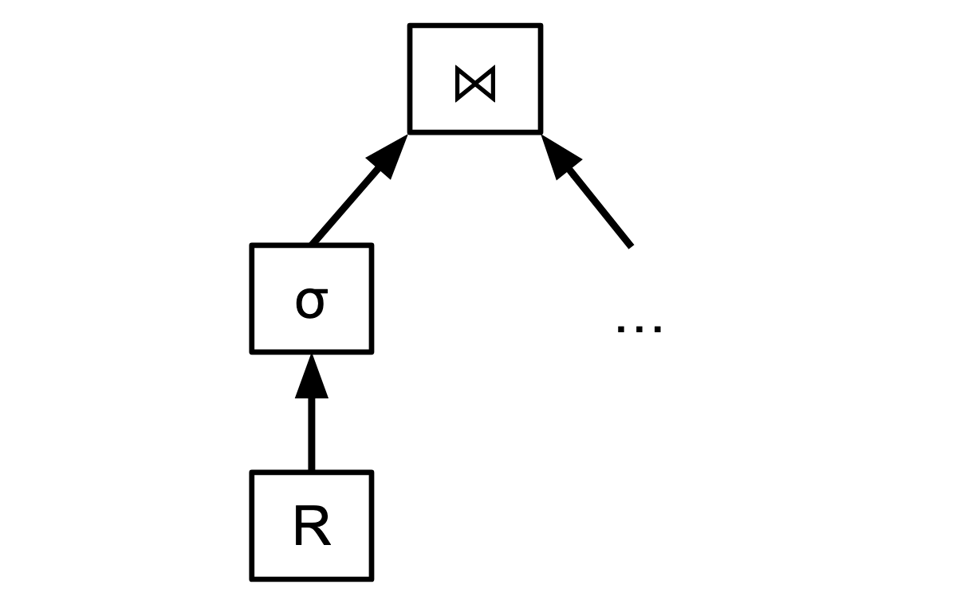
"Ah, well, the TableReader checks the metadata of the file to see if it has been compressed, and if it has, then when it reads the data, it emits the decompressed rows instead of the compressed ones."
An alternative design that having a plan stage opens up, is to have an explicit operator whose job it is to decompress the data:
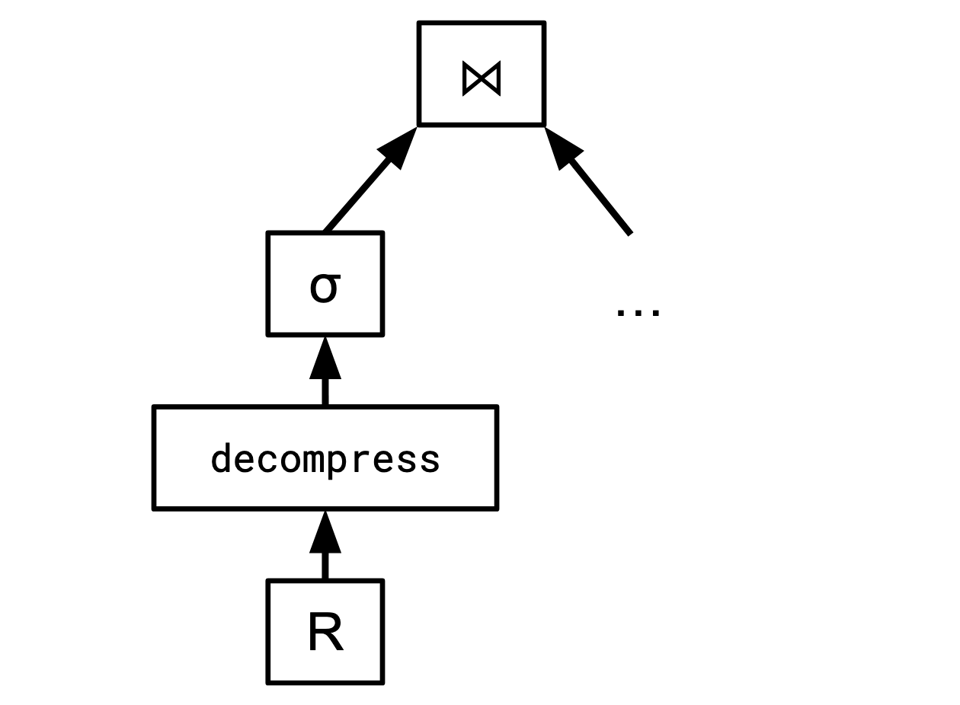
This reification doesn't have to persist beyond the planning phase (if you're worried about another operator boundary that rows would have to cross)—it can simply get absorbed into the TableReader at render time in the form of reconfiguring it.
I don't think this is obviously a superior design, though I think as a query engine matures and develops a broader set of orthogonal features the scale tips in the direction of this kind of thing being desirable since more behaviour becomes visible as data rather than some kind of invisible dynamic dispatch, as these things often go.
Lots of things that don't seem like they could be encoded this way actually can fall out somewhat naturally with the right abstraction.
One of the real gems of query processing is the exchange operator, which is a way to represent parallellism as a relational operator.
The idea is that many operations we want to perform in a query engine are naturally "data-parallel," meaning we can, without much or any coordination, easily perform them across multiple CPU cores at once (think things like, maps, filters, etc.). This contrasts with "operator parallelism," where we run various operators in the same tree across multiple CPUs.
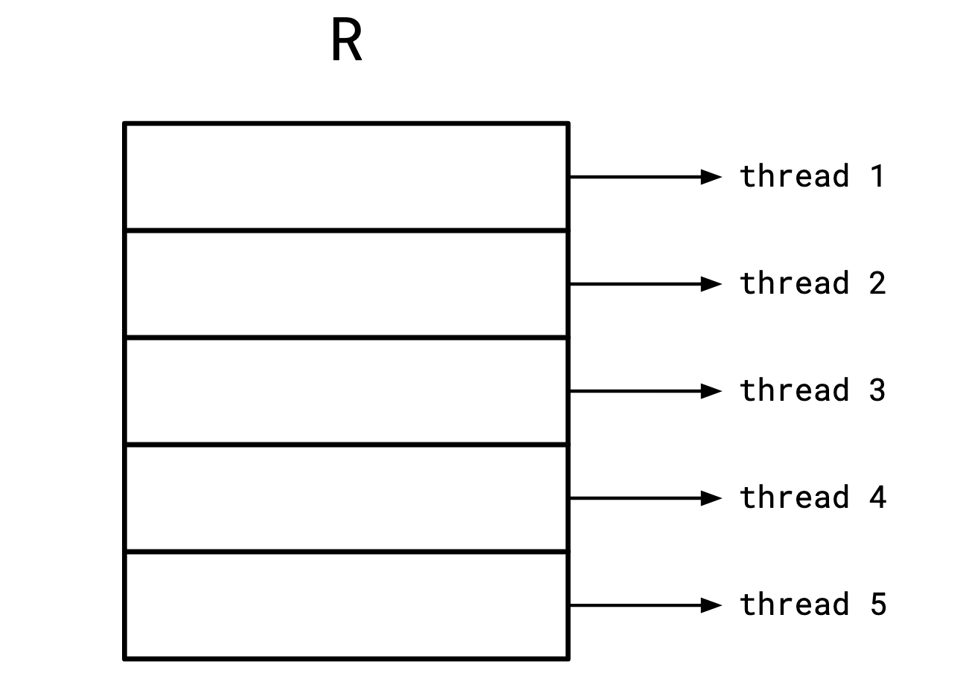
The idea being we want to slice up our base data, and then operate on it in parallel as much as we can before we have to ever shuffle across CPU cores:
The way we do this is via a new operator called exchange:
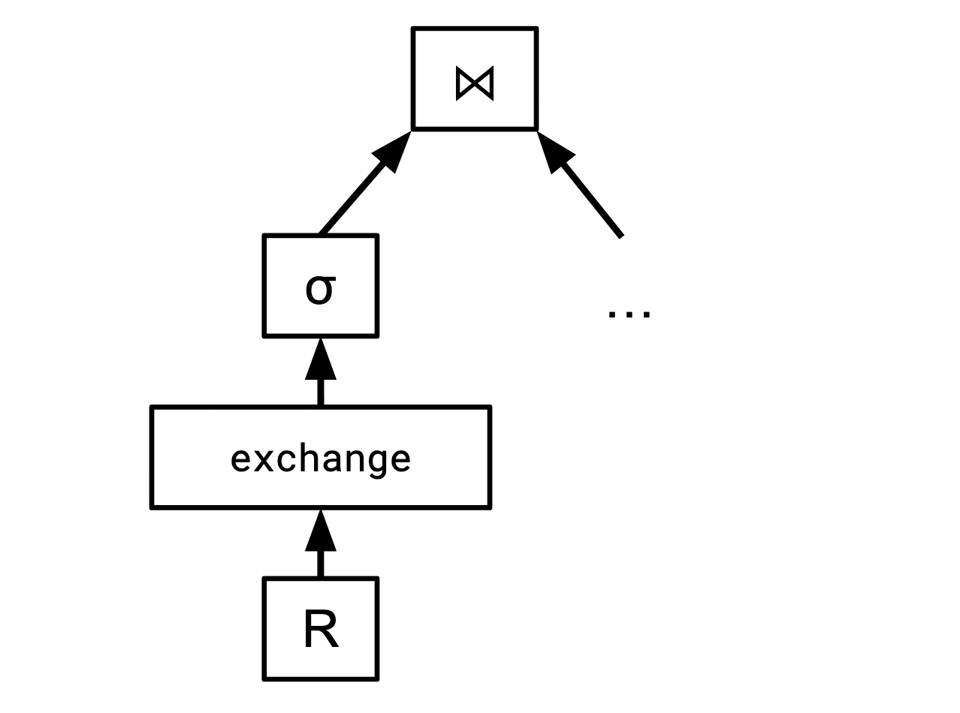
exchange is parameterized by some hash function row -> thread, and rearranges all the data between the threads so that rows having the same value under the hash function are grouped together.
Theoretically, if we want to do work in parallel, we sort of want to just make n copies of our tree and have a different thread own each copy. This works great as long as all the computations are data-parallel, and don't need to interact with other rows, or need some guarantee that certain rows live in the same copy of the tree. Sometimes we do need that, though, and that's where exchange comes in.
Consider a join—all the rows that a given row will join with must live in the same copy of the tree. We can use exchange to guarantee this. Simply shuffle all the rows to live on the same copy as other rows with the same join key, then none of our join rows will miss each other.
I think this is a cool trick, and I like the general technique of encapsulating entire chunks of behaviour into concrete operators, since it lets everything be understood as compositions of other behaviour. Of course this is not always possible, but it's nice when it is.
Links
- DuckDB video on Query Execution where they talk about why they moved away from exchange.
- These articles by an ex-colleague Andres Senac cover building a SQL query planner. I'm biased as he links to this newsletter but I think they're quite good!
Add a comment: