Query Operator Structures

The way we usually like to think about operators in query plans is that they're just representative of "result sets." In the Volcano model, they're just iterators that we repeatedly next() until they're exhausted, and we have no insight at all into their underlying structure. In this model, a join merely has two inputs that it treats as black boxes it grabs rows from:
This is this opposite of how we think about queries during planning, though. The whole game when we're preparing a query to be executed is that certain subtrees of a query can be rewritten in a more optimized way.
Say one of our subtrees was composed of two chained filters, that only let through rows matching some predicate:
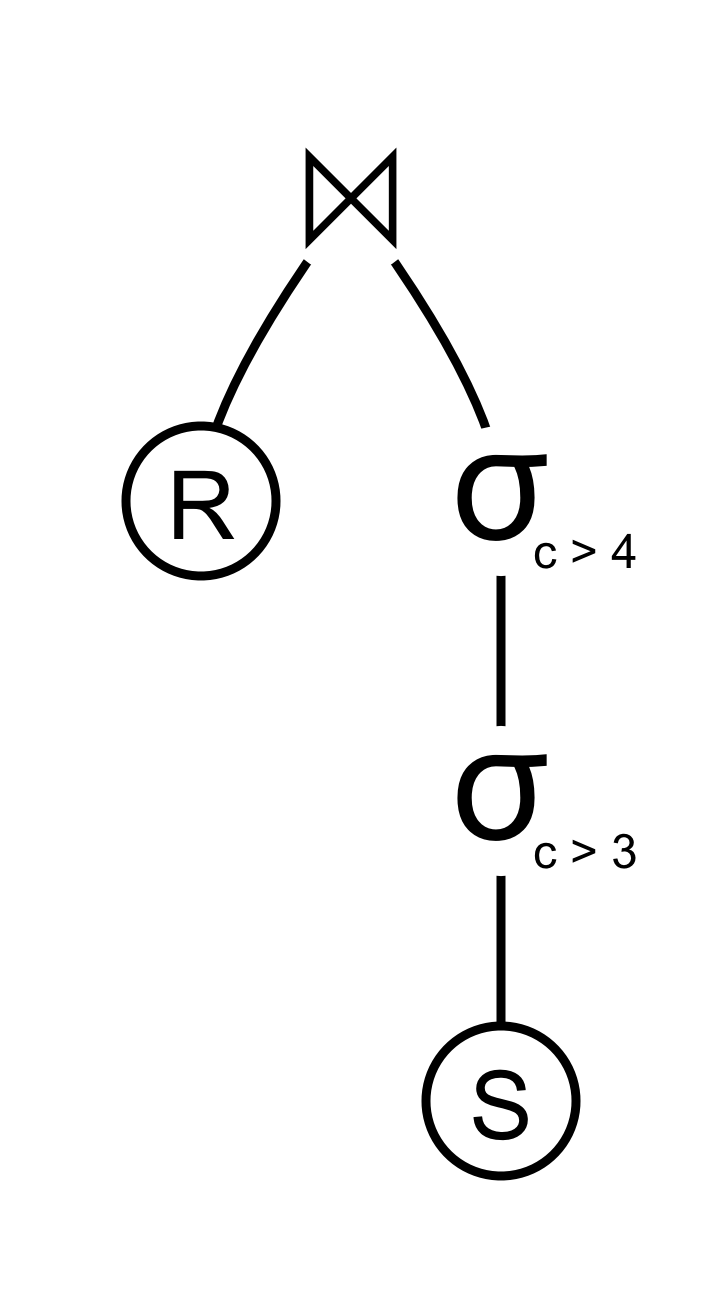
If, in this case, we were blind to the internal structure of our operators, we would miss the optimization of eliding the second filter, which is implied by the top filter.
What I've described here is the sort of platonic ideal of the query pipeline: the planner inspects the tree carefully and moves operators around so that the execution engine can just rip through rows as fast as it can. In practice, some of these things are more complicated.
One thing that is in hindsight simple, but in practice, took me a bit to wrap my head around, is the structural difference between the index nested loops join and a hash join. To review, to compute the query:
SELECT * FROM abc, xyz WHERE abc.a = xyz.x
The way a hash join works is that it guesses which of abc and xyz is smaller and picks that to be the "build" input. It then reads all of that input and builds a hash table on its key. Then it reads all of the "probe" input, for each row, looking its keys up in the hash table.
The way an index nested loops join works is that it guesses which of abc and xyz are smaller and loops over the whole thing, and for each row it encounters, looks up that row in an index to find any matching rows.
If you squint, you might notice that these are sort of the same, but also very different. The obvious similarity is that the index nested loops join is basically doing a hash join, it's just that it's relying on the database to provide some kind of fast lookup structure itself, rather than building a hash table on the fly.
The obvious difference is that the hash join is able to treat its build input as a black box, while the index nested loops join requires fast lookup into its other input. Fast lookup into an input...is not possible if we're treating our operator as a black box that just hands us rows one at a time!
So in some sense, structurally, the index nested loops join operator is actually not a binary operator, like the hash join operator is, since that would suggest that it is doing something with its inputs beyond just "asking them for rows," it's actually more like a unary operator that is configured to do a particular kind of lookup to find matching rows:
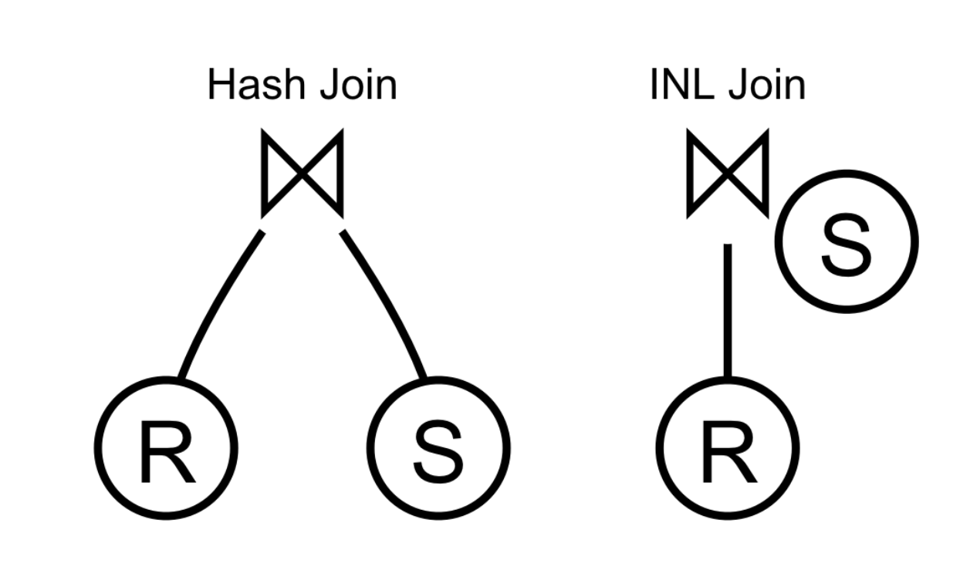
Oftentimes I've seen this just look like "the INL operator configured with an index ID which it then uses to do its lookups," but going one step further and having an arbitrary expression instead of lookup gets you pretty close to implementing Apply, which is sometimes a helpful tool in evaluating correlated subqueries (you might note that this resembles a flatMap).
Add a comment: