Pivoted Query Synthesis

We love generative testing in the world of query languages, because languages in general are in a lot of ways, too complex to test by hand. There's an exponential number of combinations of features that could be involved in any given query. Database query optimizers do a lot of work to detect when those features are used together in ways that permit better execution. This is great, and important, especially when queries are generated by the composition of various tools that might not be aware of what goes on past optimization boundaries. But it also means that there's a lot of potential places to go wrong.
Metamorphic testing is one of the more popular techniques for testing databases out there, especially using the techniques pioneered by Manuel Rigger and co like Ternary Logic Partitioning (TLP). That group has not only developed metamorphic testing techniques though; today we will take a quick look at Pivoted Query Synthesis (PQS), another technique they developed for testing query planners.
Let's review the notion of metamorphic testing and TLP.
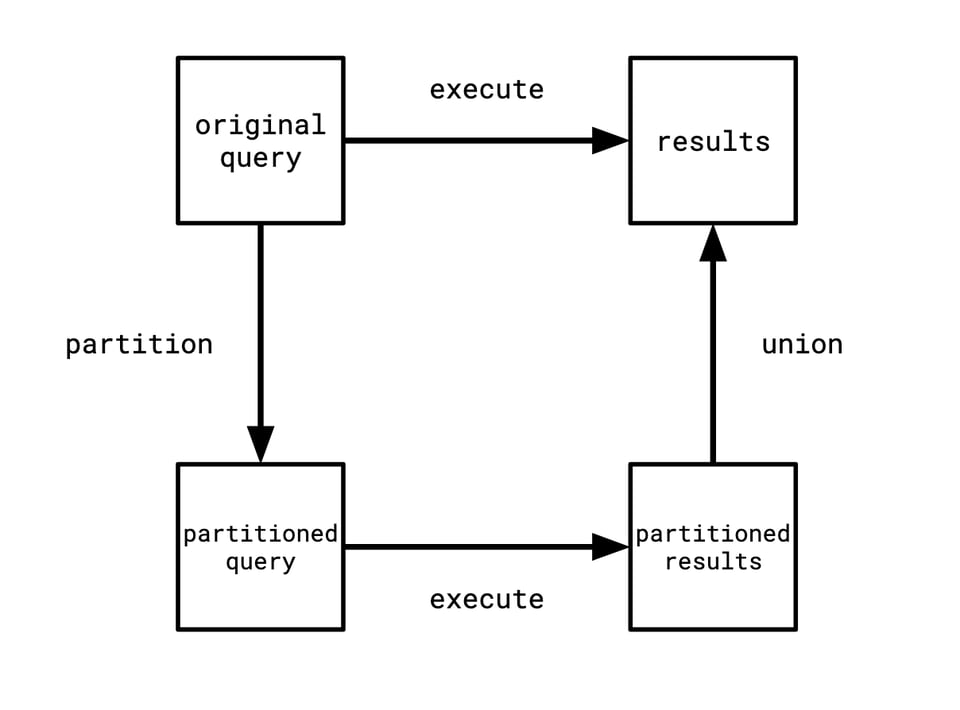
In TLP, we take a query q and a predicate p and then we generate the three queries:
q WHERE p
q WHERE NOT p
q WHERE p IS NULL
And then we run the query q and the three augmented queries and see if the results are the same. Since the three queries partition the set of rows that q returned, taking their union should give us the original value. The hope is that since databases love to tinker with predicates, splitting up a predicate this way is likely to tickle some buggy optimization that lives in the database.
Now, I know the category theory/PL people have poisoned the the well here, so that even if I'm going to say something very normal and reasonable you're going to be like "oh he's one of those." I'm not!!! But this is the right way to think about it. This is making use of a metamorphic relation that says that both ways of traveling through this diagram should give the same result.
Pivoted query synthesis approaches generating tests a different way, but we want to accomplish a similar thing: we want a query that we can assert some nontrivial fact about. With TLP, we do this by slapping some predicates on top of it. This is good for catching many bugs but also has blind spots. So let's now look at how PQS works.
The idea is that we want to have a nontrivial fact we can assert about a given query. In this case, it will be "the query returns this row." We can then turn this test case into a value: a pair of a query and a row it must return. We call this pair a pivoted query.
For example, if we have a table t that has the rows ['foo', 1], ['bar', 2], and ['baz', 3], we might have the pivoted query (Scan(t), ['bar', 2]). This was trivial to generate: we just looked at the table we were scanning and grabbed one of its rows.
The key insight is that we can inductively make a more complex pivoted query from a simpler one. We can look at a pivoted query and say "I want to put a filter on top of this." We could just put any old filter on top of it, but remember we want to generate a new pivoted query from it, so we need to find ourselves a row that we know it must return. Luckily: we know at least one row the original query will return, since our input was a pivoted query. So, we can just make sure the predicate we use will succeed on that row, and we have a row that our filtered query must return:
def pivoted_filter(expr, schema, row):
pred = gen_true_expr(schema, row)
return PivotedQuery(Filter(expr, pred), schema, row)
We can pull similar tricks for other operators. Some of them, we need to modify the row. Say we want to do a projection where we render a new column, we need to do something like this:
def pivoted_project(expr, schema, row):
new_col = gen_expr(schema, row)
schema.add_col(new_col.typ)
new_row = row + [new_col.val]
return PivotedQuery(Project(expr, new_col), schema, new_row)
This is just another tool in the "testing planners" toolbox. It has obvious blind spots, just like TLP does: it's not very good at testing operations that operate over multiple rows, like aggregations. And furthermore, you, in a lot of cases, need to re-implement a bunch of the database's logic in order to know what the result will be. This is undesirable in general, you don't want your test generator to be in the business of litigating internally-consistent-but-weird behaviour from the database. But doing so does give you a lot of power.
Add a comment: