Lowering in SQL

In the land of compilers, going from a higher-level representation of a program (that's easier for a human to author) to a lower-level representation (that's easier for a compiler to manipulate) is called lowering.
In particular, in SQL, going from a syntax tree to a plan involves things like typechecking and name resolution and is sometimes called binding. I've also heard it called planning and indeed lowering. I personally don't really like the name "planning" for this process, I think it makes more sense for that to refer to the entire process of going from query text to query plan.
So, the phase of "lowering" here, is going from AST to a simple, unoptimized query plan. Basically translating the AST that represents the query into the IR.
Let's look at a simple SQL query to see what that might look like.
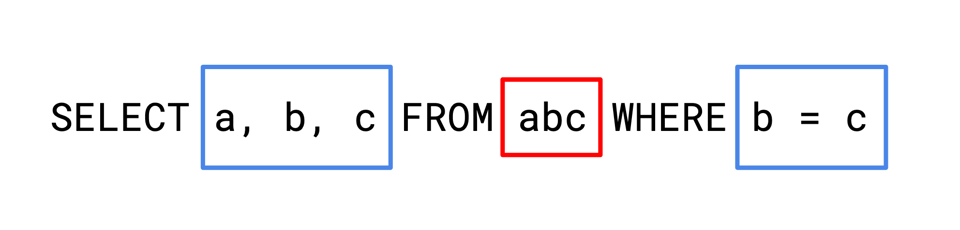
SELECT a, b, c FROM abc WHERE b = c
The way SQL queries are structured is that the tables "provide" some set of columns to the scope they're valid for, so in this image, the red box creates the scope for the blue boxes.
And it mostly doesn't get more complicated than that. There are two main places that break this rule, that I can think of, and they're sort of actually the same place.
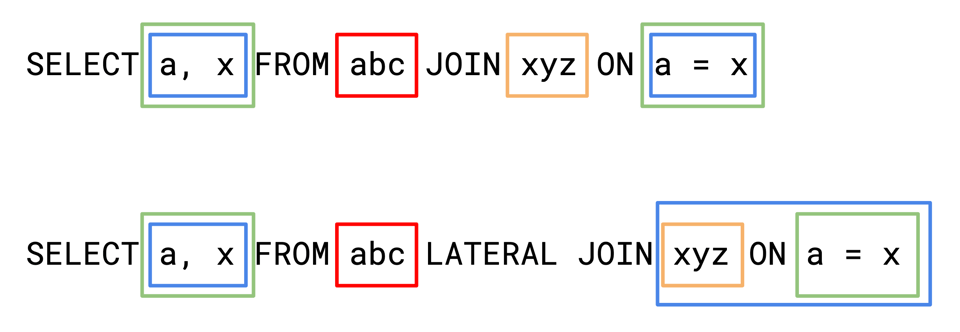
The first is correlated subqueries. Here, the rule is still the same, the scope from the red box provides columns that can be used in the blue boxes, and the orange box provides columns that can be used in the green boxes. So the inner green boxes can access columns from both abc and xyz.

The second is almost the same thing, it's lateral joins. A lateral join is like a join where the right side of the join can reference columns from the left side. Depending on what your conception of a join is, that might not sound like a coherent idea. It makes the most sense if you define a join b on p as
for ra in a:
for rb in b:
if p(ra + rb):
yield ra + rb
Then the computation of b can conceptually depend on the values of a:
for ra in a:
for rb in b(ra):
if p(ra + rb):
yield ra + rb
The scopes look different here:
It's no coincidence these are the two main places that this shows up, because they're really sort of the same concept, just shaped a little bit differently.
Now that we have this basic model of how SQL scoping works, we can implement it for a (very) small subset of SQL without too much ceremony:
// Lower builds a relational expression and adds its columns to `scope`.
func (l *Lowerer) Lower(r Rel, schema Schema, scope *Scope) (Plan, error) {
switch r := r.(type) {
case Select:
// *First*, build the input, so we know what columns are available to
// us.
input, err := l.Lower(r.From, schema, scope)
if err != nil {
return nil, err
}
// Now build the predicate, because only now do we know its entire
// environment.
predicate, err := l.LowerScalar(r.Where, scope)
if err != nil {
return nil, err
}
return Filter{
Input: input,
Predicate: predicate,
}, nil
case Table:
// First, look up the table in the schema:
table, err := schema.Get(r.Name)
if err != nil {
return nil, err
}
// Now add all of its columns to the scope.
for _, col := range table.Cols {
// Instantiate this column in the global scope and assign it a
// unique ID.
id := l.AddCol(col)
scope.Push(col, id)
}
return Scan{Id: table.Id}, nil
default:
panic(fmt.Sprintf("unhandled: %T", r))
}
return nil, nil
}
func (l *Lowerer) LowerScalar(s Scalar, scope *Scope) (ScalarExpr, error) {
switch s := s.(type) {
case ColumnName:
col, err := scope.Find(s.Name)
if err != nil {
return nil, err
}
return ColRef{col}, nil
default:
panic(fmt.Sprintf("unhandled: %T", s))
}
}
Following this, there are other steps, like optimization (plan-to-plan), and rendering (IR-to-executable plan), but this is in some sense where a lot of the rubber hits the road: where we define the semantics of the query language itself in terms of something with much simpler semantics, and thus make them explicit.
Anyway, this was just the result of me messing around over the weekend. I put the resulting code here but it's not likely to be that exciting.
Add a comment: