Languages Without Abstraction

Implementing something like a compiler, there is the understanding that we want different representations of a program for different purposes. This is why we have stuff like a “control-flow graph” or “SSA form.” Some kinds of analyses and transformations are easier in more abstract representations that have thrown away certain information. But those aren’t good for all purposes. For example: we generally need a syntax tree that very directly corresponds to whatever it is the user wrote: we don’t really have the liberty to change it too much. This is because if we’re going to complain that the types in their program are wrong, we need to explain it to them in a way that makes sense to them with the context they have, which is precisely the program they wrote, not how we’d prefer to represent what they wrote in some more abstract form.
So we travel down the ladder of abstraction, moving our program further and further away from something recognizable as what the user gave us, into increasingly abstract representations closer and closer to how a computer would prefer to think about a program.
For example, the pipeline might look like this. Sometimes we'll have more than one IR (intermediate representation) if different IRs are good for different purposes.
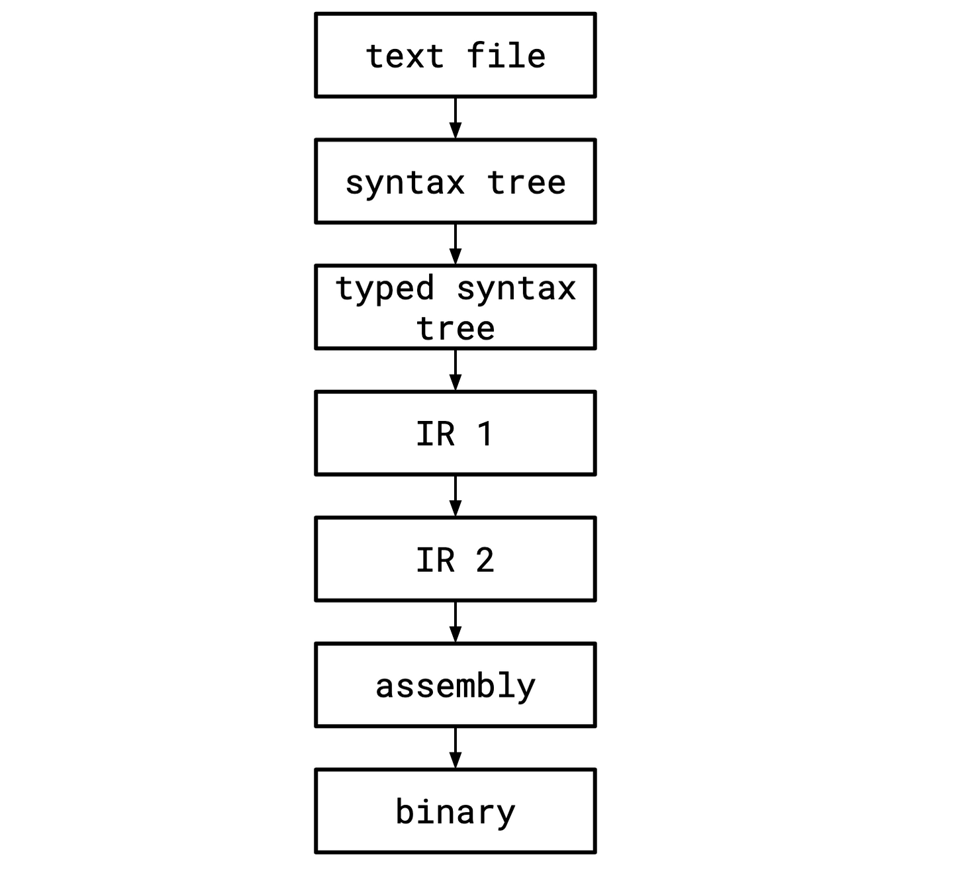
In short, we throw away information. Stuff like:
- the comments in the file,
- the names that a user gave a variable, which are liable to be replaced with some kind of opaque identifier,
- the parenthesization of an expression, which will become unnecessary as the barbarous, textual string is replaced with an unambiguous, blessed tree,
- the fact that a given function was once generic, as we substitute in concrete type values and monomorphize it.
I’ve been thinking lately about languages that, by necessity, do not have the luxury of abstraction in their representation.
Consider the LLVM IR. Here’s an excerpt from the introduction:
The LLVM code representation is designed to be used in three different forms: as an in-memory compiler IR, as an on-disk bitcode representation (suitable for fast loading by a Just-In-Time compiler), and as a human readable assembly language representation. This allows LLVM to provide a powerful intermediate representation for efficient compiler transformations and analysis, while providing a natural means to debug and visualize the transformations. The three different forms of LLVM are all equivalent.
“The three different forms of LLVM are all equivalent” is a deceptively interesting statement! It means that if you want to process the LLVM IR, like, slurp some text into memory and have it in the in-memory representation, or whatever, you kind of…can’t mess with it too much. Since there’s an understanding that these things are equivalent. Not a unidirectional “we can throw stuff away from A in the process of getting B” situation like we have in a typical programming language. If you read in the LLVM IR, then mess around with it by performing an optimization, you have to be able to spit back out LLVM IR that mostly resembles what you read in originally.
Having an IR with this property makes a lot of sense, because things like compilers are so complicated, it's important for people to be able to tweak and mess with and prod at generated code to see how the compiler behaves with it. And it's important to be able to copy and paste some sample code to send to a collaborator so they can also tweak and mess with and prod at it.
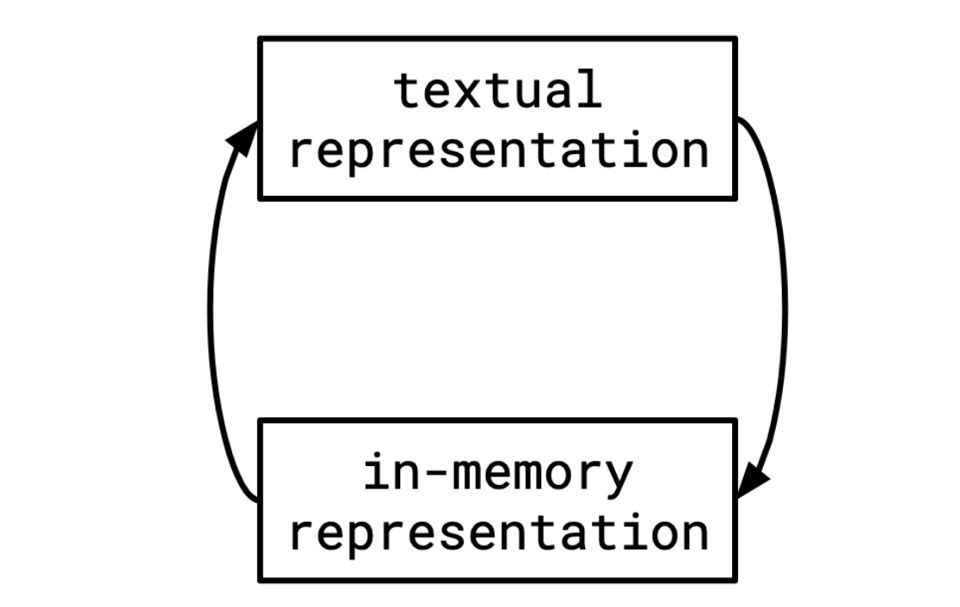
This kind of goes against the way I usually think about language implementation, which is much more similar to what I described initially, where things flow down from a start to a finish.
I’ve been really interested in designing this kind of an IR for a query language, where the form we use for manipulating and optimizing it is also representable in text. One place this would be really valuable is in writing tests. Because without that sort of thing, you’re forced to carefully craft queries in SQL or whatever your query language is with the knowledge of how they’ll get translated down into your lower-level IR if you want to test a particular transformation. My experience with this has mostly been with tests of this form (taken from CockroachDB):
norm expect=ConvertGroupByToDistinct
SELECT s, f FROM a GROUP BY s, f
----
distinct-on
├── columns: s:4!null f:3
├── grouping columns: f:3 s:4!null
├── key: (3,4)
└── scan a
└── columns: f:3 s:4!null
Which is fine. It works well. But it’s not really what you want. It’s kind of weird that the source language (SQL) is even involved here, since its only real role is that it’s convenient to write: we as the database implementor know how to write it, and we already have a parser for it. But we’re testing the optimizer here and the optimizer probably barely knows about SQL, modulo having to inherit a bunch of its semantic quirks (remember, we've lowered into a more abstract language at this point).
You might also want something like this for testing the query engine, rather than the optimizer, since you might want more control over what kind of query plan is getting executed, rather than having to pass a SQL query through the planner and give up a lot of control over what it is we’re actually executing.
In most databases I’ve seen, the IR that you optimize only has an in-memory representation. Or if it also has a textual representation, it’s some crappy mechanical translation to some JSON or XML that wasn't "designed" and isn’t pleasant to write or read or modify and really only serves as a way to serialize it.
I don’t really have anything concrete to share on the design of such an IR, I’ve played around with a couple of ideas over the years and nothing has really felt quite right to me. I have an ongoing one and if I wind up liking it maybe I will share an issue about it. I think there's a lot of subtlety, because you need to answer a lot of questions, like:
- Do you require every intermediate relation and column to be named? To what extent do you preserve those names if you ever rewrite expressions?
- How powerful is this language? Maybe it should be a full-fledged scripting language that includes facilities to define new operators and rewrite rules.
- Do you have a complete parser for scalar expressions with precedence like
2 * 1 + 3or do you have to write out trees explicitly using something like an S-expression? - Do you provide syntax sugar for common operations like joins and filters and projections? Queries can get very noisy without such things, but having multiple representations of the same thing is problematic, because do you need to keep track of that in the in-memory version? Or is it okay to desugar it?
- If you are making a cascades- or egraph-based optimizer, do you need to be able to write out multiple different expressions and express equivalences between them? Will the programs get very big and noisy and unmanageable then?
There’s a lot more questions to be answered in such a language, but those are just a few of the things that come up pretty fast. You’re trying to achieve two goals at the same time: an IR for a query optimizer should be designed such that it’s easy to express transformations over, but an IR for a human should be designed such that it’s easy to read and write, and there’s some push and pull between those things.
Experience has told me that NULL BITMAP readers are good at having references to literature on this sort of thing—if you have any pointers to terminology or papers or books that discuss these ideas please let me know!
Add a comment: