Chapter 3 & 4 of Feedback Control

We are reading Feedback Control for Computer Systems: Introducing Control Theory to Enterprise Programmers by Philipp K. Janert. For discussion, please see the NULL BITMAP Discord.
Now that we are bought into the idea of feedback control, chapters three and four are about getting more comfortable with the framework. To that end, chapter three is about system dynamics and chapter four is about controllers.
Let's take a brief detour.
I am going to work on a little pet problem of mine as we go. It might not end up working! I don't really know what I'm doing with it and I'm kind of just throwing stuff at the wall here. I'm interested in throttling writes to an Log-Structured Merge tree in order to maintain a particularly nice shape.
I will generally assume you know the main idea behind how a log-structured merge tree works here, if not, I've written about it in the past:
I have written a little simulation that I'm going to use to simulate a bare bones tiered LSM. It writes data to the memtable, and when that's full, it writes that out to an L0 file. When there are too many files in L0, it writes them all out to L1. When there are too many files in L1, it writes them out to L2. If we plot a run of this, we can see the shape of things look basically how we expect:
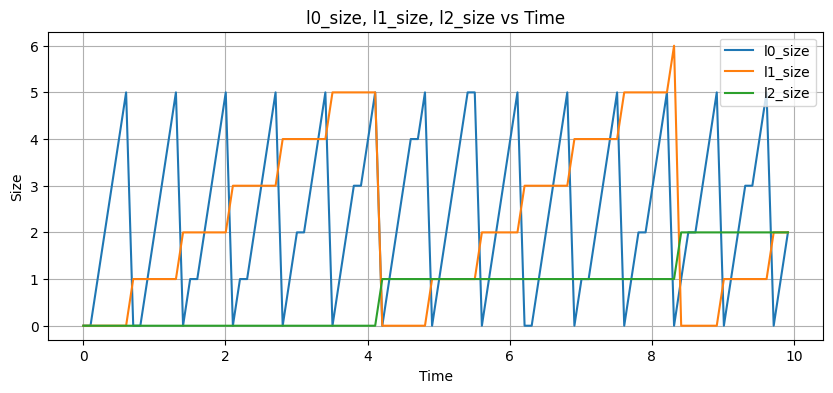
This sawtooth pattern is common in tiered LSMs: when a level gets too full, it empties out and fills up the next level.
Implementation-wise, I have a task that plucks compaction jobs out of a queue and performs them:
func (d *db) runCompactor() {
for job := range d.compactionJobs {
size := 0
for _, s := range job.ssts {
size += s.size
}
// do the compaction
time.Sleep(time.Millisecond * time.Duration(size))
d.mu.Lock()
d.nextId++
id := d.nextId + 1
d.nextId++
d.installSst(job.ssts, sst{
id: id,
size: size,
}, job.targetLevel)
d.mu.Unlock()
}
}
So we can only do one compaction at a time, and it takes time proportional to the input SSTables. This might not be ideal: we might want to take a break from doing a big compaction to clean up some smaller ones, for example, but it's a simple enough model to be a starting point.
Now let's see what happens if we ramp up the write rate:
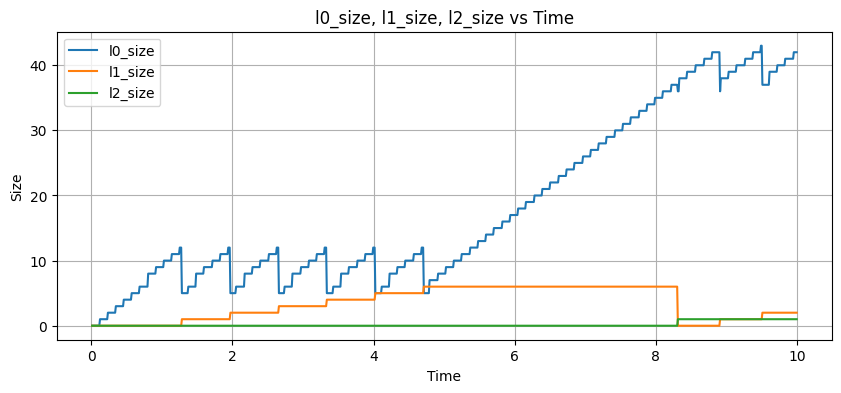
Wuh-woh! Now that our writes are faster, our compactions can't go fast enough to keep up with the number of writes we have. As the L0 size grows and we have too many files, we have to consult more files on every read, which means our read amplification is going to grow unboundedly.
We can attempt to fix this by adding a throttle to each write to slow down the rate of writes:
func (d *db) write(n int) {
time.Sleep(2 * time.Millisecond)
...
}
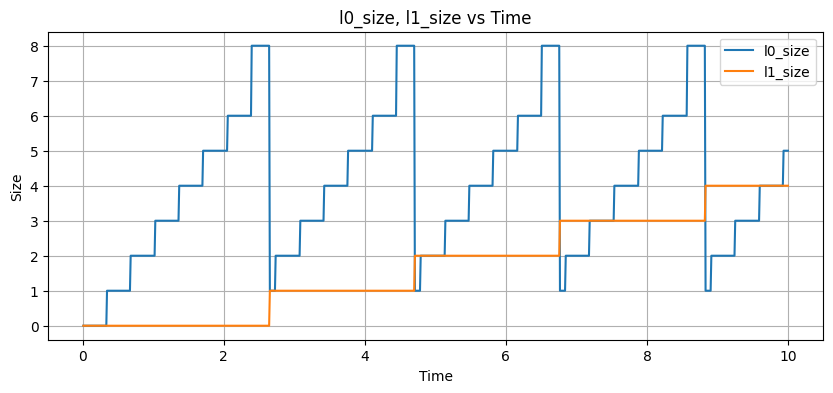
We're back to a manageable rate of writes that doesn't cause things to grow unboundedly. However, we're probably not reaching our full throughput: what we'd like is for the system to adaptively pick the throttle value for us in a way that doesn't cause the number of files to balloon out of control, but lets us write as fast as we can.
Sounds like a control problem to me!
This will be a work in progress, as you can see, my first attempt to do this has not worked out so well:
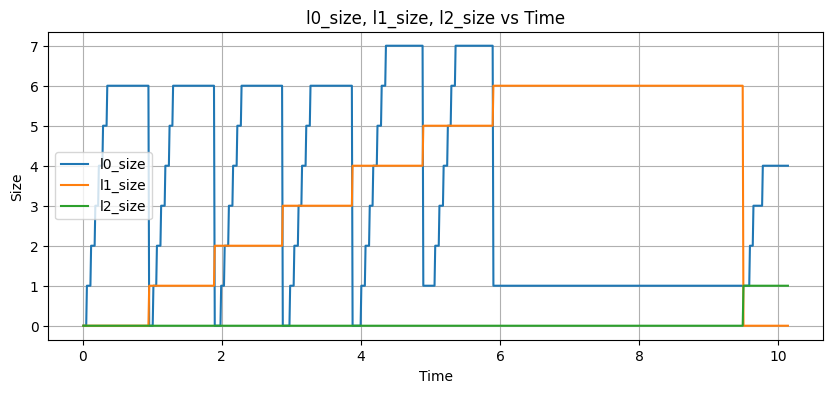
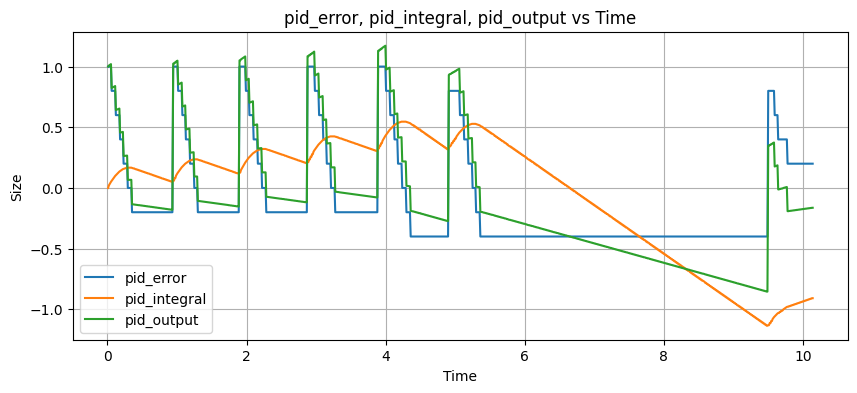
And worst of all, absolute clownery:
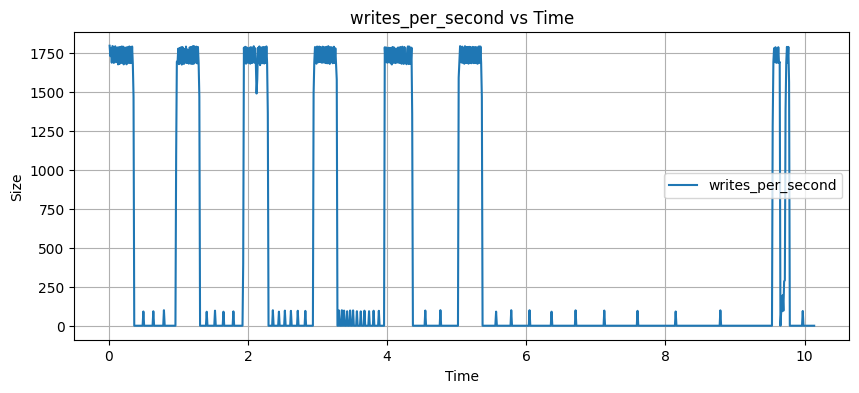
It's possible the simulation has got its own problems, but I think there's enough interesting stuff there for me to continue to tinker around with and try to get something passable. If you have any thoughts on how to improve it I'd be curious to hear more.
It doesn't seem to me there's a super obvious quantity to use for the output signal. We could use the number of L0 files, but this ignores the other levels. In the end I hacked together a janky measure that I want to revisit:
func (d *db) health() float64 {
h := float64(len(d.levels[0])) / float64(maxSstsInLevel)
for i := 1; i < len(d.levels); i++ {
if len(d.levels[i]) > maxSstsInLevel {
h += float64(len(d.levels[i])) / float64(maxSstsInLevel)
}
}
return h
}
It computes the ratio of the size of L0 to the max size, and then for any levels beneath that it adds them as well if they're above the max size.
Anyway, it doesn't work very well yet, but I want to keep tinkering with it. On to the chapters of the book and how they relate to this problem.
I got some nice notes from user hazard-pointer in the NULL BITMAP Discord server.
Chapter 3: System Dynamics
The system dynamics of a system we are trying to control is the way it responds to stimuli and also the lack of stimuli. Janert uses the example of a heated object sitting on a stovetop: it will heat up if exposed to heat from the stove, and it will also cool down in the absence of heat from the stove (though not all at once).
The thing that Janert focuses most on here is the presence of lags and delays.
A lag is when the system responds to the stimulus, but slowly over time, and not all at once. You can probably see its effects right away, but not fully.
A delay is different: you might see its effects all at once, but they'll take some amount of time to come into effect.
I'm not immediately sure how to classify the behaviour in the LSM. If we bump up the throttle time, the system will still have to chew through a bunch of compactions before we start to observe any impact from the writes. The system will still have to chew through a bunch of extant compactions before it starts to see a benefit, which smells to me more like a delay than a lag. But there are some lag elements as well, since having fewer new files will also start to reduce the amount of work done by those compactions.
The rest of the chapter talks about ways to reduce the impacts of delays and lags, and also about the steady state behaviour of a system. Something that strikes me is that in a lot of "difficult" cases that might show up in these kinds of problems, the answer isn't "we have a way to work around that," but "you should try to not have that problem."
Chapter 4
This is where we get into actually pushing at the idea of what a "controller" even is. He draws some block diagrams which, if you are just seeing them here, you might think are an informal visual aid to describe how a system behaves. It turns out (and this book touches on it a bit later) through the magic of generating functions there is a nice way to interpret these things algebraically. Which I'm sure we will get into.
Besides that he describes a bunch of "kinds" of controllers. We talk briefly about "on-off control" and then this is our actual introduction to what a "PID controller" is. We've touched on it before but this is where the money is.
I liked that he built up that in a precise sense, a PID controller is just a P controller plus an I controller plus a D controller. It's nice when a fancy thing is actually just a completely independent combination of less fancy things.
In two weeks we will talk about the next two chapters: please send me your thoughts in the meantime!
Add a comment: