Caching is an Abstraction, not an Optimization

I've always been told that caching is a tool to make software faster. That, given some careful considerations to consistency, caching makes it so that when you want to read a given piece of data, you don't have to go all the way back to some backend database or API server or SSD and can instead just read from some faster location like memory for the same data. Caching is thus a tool to improve performance.
My feelings now are that that perspective on caching is wrong, or at least incomplete. Having worked on software recently chiefly concerned with moving data between object storage, disk, and memory, I think now caching is probably best understood as a tool for making software simpler.
Something that always struck me as weird is, how come we have all these pre-baked caching algorithms, LRU, LFU, and so on. It seems like for my application I should have a much more fine-grained understanding of how things should work. Why am I outsourcing the understanding of my data to a generic "policy?" If I fetch some data, it seems like I know whether I'll need that data again in the near future, so I should explicitly be telling the system whether or not to hold on to it, and for how long.
One good reason is that it's a clean abstraction boundary!
Coming to caching from the belief that "I will personally manage when my data needs to be stored in faster storage" rather than the "naïve" belief ("I will go to disk every time"), caching much more resembles an abstraction rather than an optimization.
Two programs could have similar behaviour but structured very differently, the difference being that one utilizes caching as an abstraction and one explicitly has the concept of different tiers of storage.
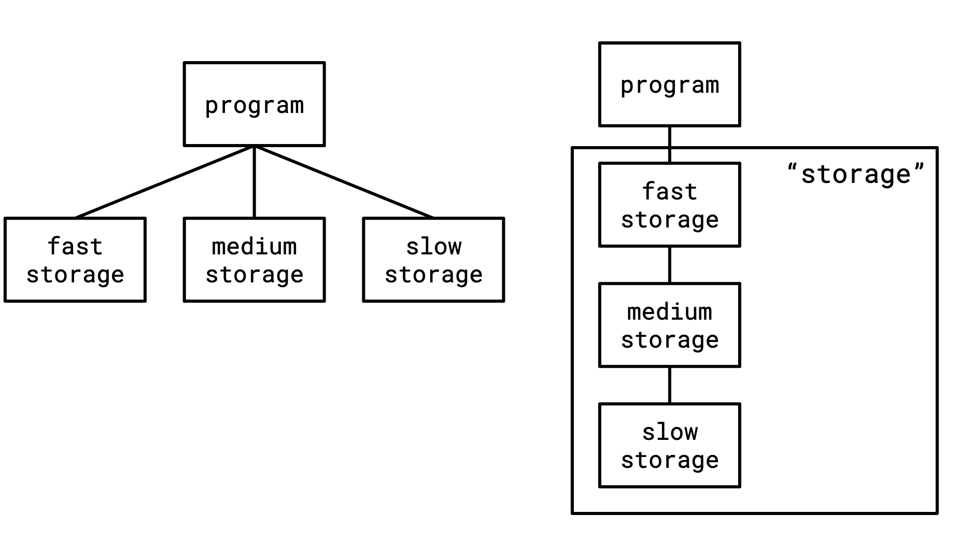
As an existence proof, if you look at the systems, databases, which have to carefully manage the dance between memory and disk, you'll find they work this way. The way a buffer pool works is that any time you try to read data you first pull it into memory if it's not already there. The way OS disk access works is that any data you read first gets pulled into the page cache (unless you're using direct IO).
(As an aside that calculus may change somewhat for many workloads, with ever faster SSDs and ever faster APIs for accessing them, but that’s a story for a different time.)
My takeaway from this is that it's a reminder that it's possible to come up with a design that works, and that satisfies the functional requirements of a system from the perspective of "having adequate fast access to the data it needs" that nonetheless could be designed more cleanly and having more separated concerns.
Of course there are downsides to this particular abstraction, classically the OS page cache and fsync causes a lot of problems via misuse. It raises the question of "are these concerns truly separate."
Whenever I heard about people understanding caching algorithms better and spending more time on caching algorithms, it often seemed to me like a misdirection. This isn't the problem you want to solve, the problem you want to solve is "I want my data in fast storage as often as possible," not "I want to game this system that is holding my data access hostage." It feels like an unholy manipulation of implementation details secondary to what I actually want to do.
But I think two things are true that make this belief incorrect:
- Data access is sufficiently unpredictable in real-world workload that we are forced to rely on heuristics, and fitting of heuristics, that we have to do this in any remotely realistic system. The belief that I'm doing this to the exclusion of some smarter, bespoke data movement strategy is an illusion.
- Caching is in fact, such a good abstraction, that it merits this kind of arcane study to make it function better in practice. Caching can not fail, it can only be failed.
Maybe it's the curse of very successful abstractions that they're invisible until they hurt you, which means it's easy to undervalue them and in cases like mine, not even realize they're abstractions in the first place.
Add a comment: