Performance! Outside the box? (This Old Pony #106)
Howdy! You signed up for this newsletter once and I haven’t sent anything in a long time. This will be the last issue for the foreseeable future.
Technically and specifically speaking, this issue is about PostGIS and geographic queries, ArrayField and intarray, but at root it's about working both through and around performance problems. So while the nitty gritty is about geospatial data, conceptually it's not even Django specific!
This is, however, based on a real problem and a real solution in a real Django app used by, you guessed it, real people.
Filtering by district
The app in question has a CRM component that lets customers create various kind of sublists in their account, including managed lists by directly adding and removing contacts, and dynamic lists that function like views into other lists using filter criteria.
The most valuable of these options is the ability to show contacts who are located inside of (or outside of) one or more select geographic boundaries (e.g. US states, cities, legislative districts, etc.). For context, these locations are known when the contact's addresses are geocoded[x] resulting in a single familiar point value for latitude and longitude.
Oh, and the contact addresses are actually relations from another model, allowing contacts to have more than one address.
So you end up with a queryset - simplified here! - that looks something like this:
Contact.objects.filter(address__location__within=selected_boundary)Or perhaps (still simplified for concision):
Contact.objects.filter(Q(address__location__within=boundary_one) | Q(address__location__within=boundary_two) | Q(address__location__within=boundary_three))
This will accurately return contacts who are located in any one of the three selected boundaries.
However, it gets very slow, very quickly - indexes be damned.
Geospatial querying
If we're trying to find all locations that are within the district, the database will use bounding boxes to reduce the area searched, but then it will need to look at each point individually. If you're looking at something like counties in a midwestern US state, this might be pretty simple! Just rectangular county after rectangular county.
But quite a few boundaries are not like that at all. They jut out one way, interlock with another boundary, maybe even have islands - physical or otherwise. This makes the query complex to execute, period.
To give a taste for why this is the case, here's a map of the former boundary for state of Illinois's 4th Congressional district.
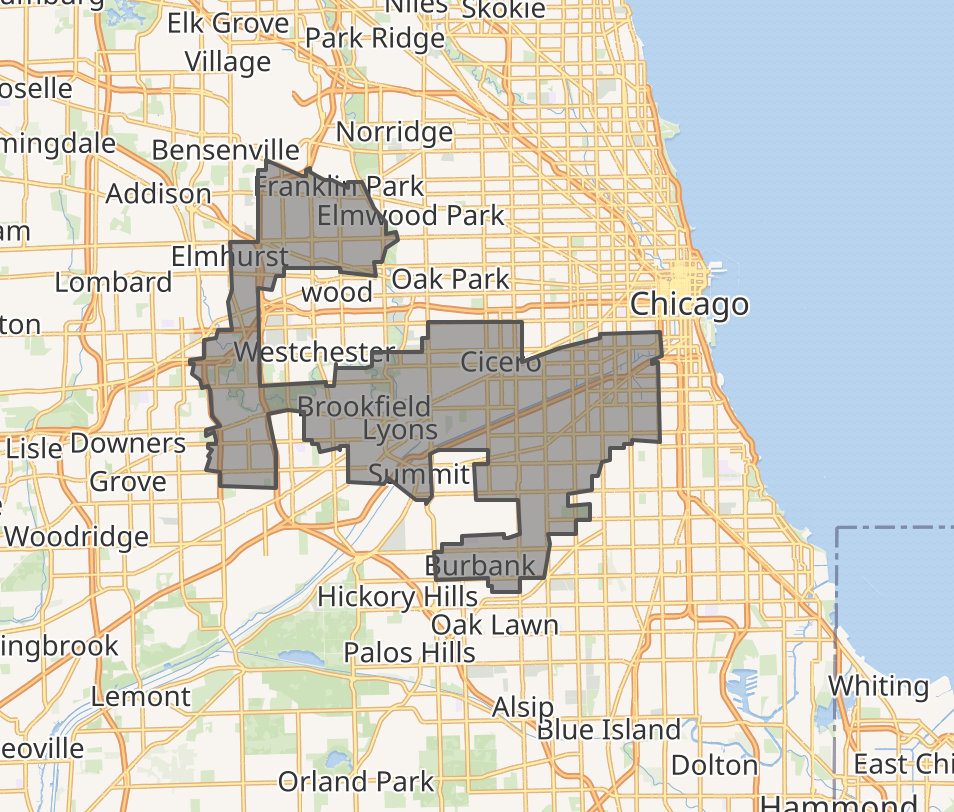
The bounding boxes needed to calculate inclusion and exclusion here are not simple and queries may be slow, indexes be damned.[0]
Denormalize
You know what is pretty fast though? Joins on foreign keys! What if instead of performing the geospatial query for every boundary, we just looked up the addresses’s related boundaries once, stored the results using a ManyToMany field, and then at query time look up the matches?
After building out a prototype and testing it, it turned out to be much faster than the original query using the geospatial fields. This was not a terribly surprising result.
This does require constantly keeping the intermediate data updated, however. For this we can simply assume the judicious use of signals and asynchronous tasks.
While this was faster, it was not as faster-er as expected. Probably because we're still joining across several tables.
So… what if we, you know, just didn't do that?
Faster still
Part of the problem is that we're tracking data across child tables. Since we're always interested in the contact, what if we used the association there?
And what if, instead of just a table relationship to the contact, we tried a different lookup? We just want to know which contacts match which boundary based on the relationship of the point to the polygon. We've denormalized this, in effect, by extracting it to a tabular relationship. We can go further and try just tracking the IDs of the related boundary directly on the contact.
This, too, needs to be kept updated, but we were already going to do that. So instead of using a M2M model (or in addition to it) we can just throw the IDs of the related boundaries of a contact's related addresses and then filter on those. We can use an overlaps operator.
Contacts.objects.filter(boundaries__overlaps=[b1.id, b2.id, ...])This is okay! It's about the same as the first optimization performance wise. But let's speed it up some more! We could try taking advantage of PostgreSQL's intarray extension[1]. If we do that then we get even faster, more fast, more faster-er results.
create extension intarray;Decomposition Interlude!
There is actually another way of breaking down this problem, one that we tried early and showed significant improvement. That involves breaking up the boundaries into many more pieces, reducing the complexity of individual polygons, and reducing query times by more than a magnitude of order (if memory serves correctly).
I was reminded of this - and nudged to finish this long idle draft - after reading Paul Ramsey’s post on the Crunchy Data blog, PostGIS Performance: Improve Bounding Boxes with Decompose and Subdivide[2].
In practice the decomposition step required maintaining another table of decomposed boundaries and keeping this up to date as boundaries in the core table are added or replaced. For an improvement in excess of a magnitude of order or more, that’s well worth it! Except it turned out that the intarray strategy was yet faster and required no decomposition…
The “inline” decomposition might actually yet be of use here, but has probably more utility for less structured querying.
Conclusions and ciao amici!
None of this was rocket science, but it also wasn't obvious from trying to optimize the original query.
And if anything, that’s the lesson here. Sometimes the solution to a performance issue is to keep refining, slim down a query, tweak an index. And sometimes you just gotta channel your inner Dick Fosbury and try a different way altogether[3].
And that’s a wrap! Life has intervened to steer me away from regular newsletter writing for now and the topics that occupy me most have veered enough from the original theme. Nobody wants a pivoted newsletter!
If your enjoyed this or any previous issue, hit Reply and let me know. Think I’m dead wrong? Working on something really cool? Have a nagging Django or related question? Hit Reply and share - I love a spicy inbox.
Historically yours,
Ben
[0]: There’s actually an added challenge if you’re using Django’s ORM, which is that instead of querying against the boundary like you would writing the SQL query with a join, e.g. WHERE address.location ST_Within boundary.geometry, the ORM loads the entire geometry and then inserts it as a value into the query. So you’re retrieving and sending from the database at least one potentially large polygon (or multipolygon), which adds measurable latency.
[1]: intarray: https://www.postgresql.org/docs/current/intarray.html