[AINews] OpenAI beats Anthropic to releasing Speculative Decoding
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Prompt lookup is all you need.
AI News for 11/1/2024-11/4/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (216 channels, and 7073 messages) for you. Estimated reading time saved (at 200wpm): 766 minutes. You can now tag @smol_ai for AINews discussions!
Ever since the original Speculative Decoding paper (and variants like Hydra and Medusa), the community has been in a race to deploy it. In May, Cursor and Fireworks announced their >1000tok/s fast apply model (our coverage here, Fireworks technical post here - note this issue initially went out with a factual error stating that the speculative decoding API was not released, as this post explains, Fireworks released a spec decoding API 5 months ago.). In August, Zed teased Anthropic's new Fast Edit mode. But Anthropic's API was not released... leaving room for OpenAI to come in swinging:
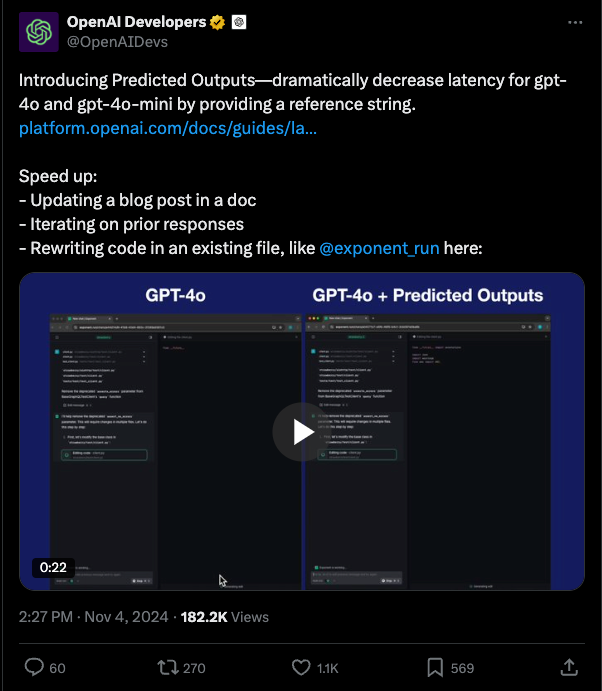
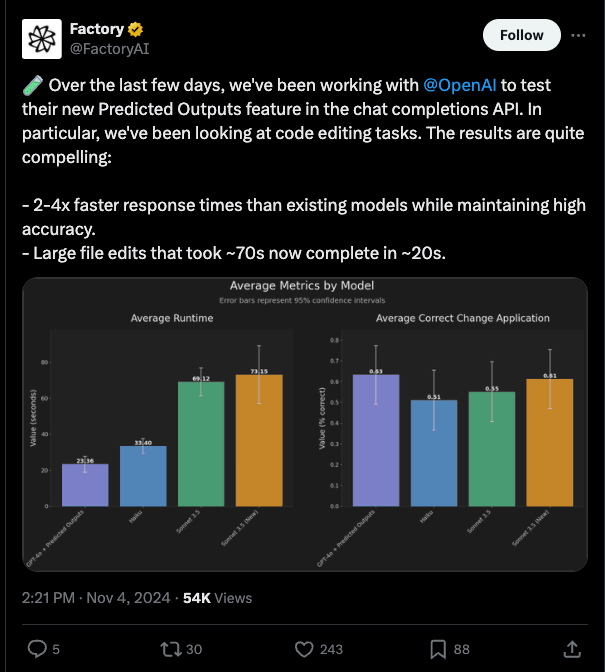
Factory AI reports much faster response times and file edits:
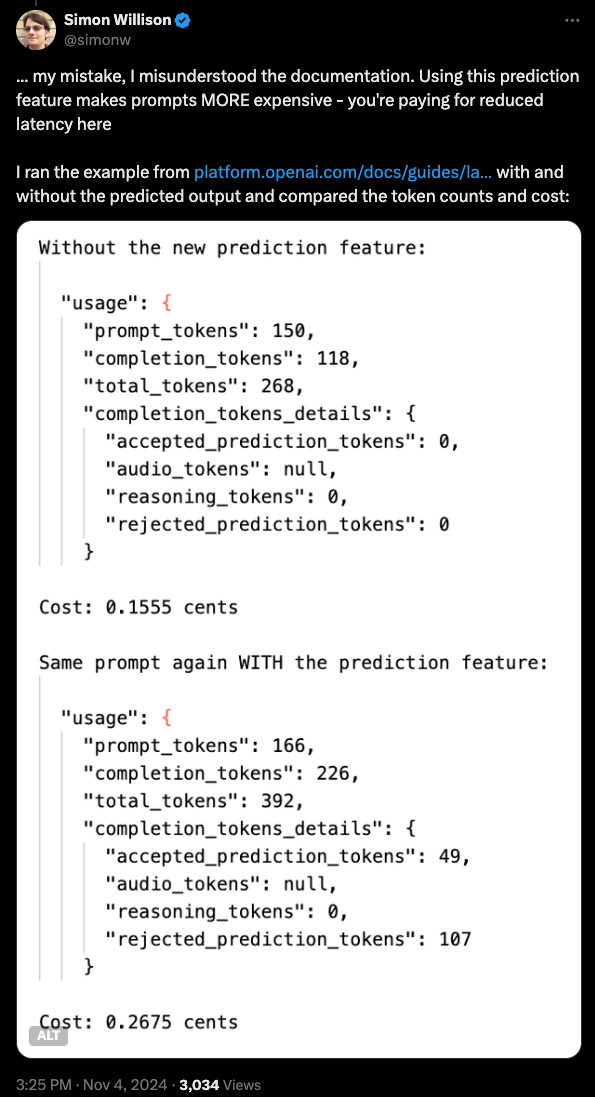
what this extra processing of draft tokens will cost is a bit more vague (subject to a 32 token match), but you can take ~50% as a nice rule of thumb.
As we analyze on this week's Latent.Space post, this slots nicely in to the wealth of options that have developed that match AI Engineer usecases:

Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- OpenRouter (Alex Atallah) Discord
- LM Studio Discord
- Nous Research AI Discord
- Perplexity AI Discord
- Eleuther Discord
- aider (Paul Gauthier) Discord
- OpenAI Discord
- Notebook LM Discord Discord
- GPU MODE Discord
- Latent Space Discord
- Stability.ai (Stable Diffusion) Discord
- Modular (Mojo 🔥) Discord
- Interconnects (Nathan Lambert) Discord
- LlamaIndex Discord
- OpenInterpreter Discord
- DSPy Discord
- tinygrad (George Hotz) Discord
- OpenAccess AI Collective (axolotl) Discord
- LAION Discord
- LLM Agents (Berkeley MOOC) Discord
- Cohere Discord
- Torchtune Discord
- Alignment Lab AI Discord
- MLOps @Chipro Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- PART 2: Detailed by-Channel summaries and links
- HuggingFace ▷ #general (955 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (8 messages🔥):
- HuggingFace ▷ #cool-finds (8 messages🔥):
- HuggingFace ▷ #i-made-this (31 messages🔥):
- HuggingFace ▷ #reading-group (11 messages🔥):
- HuggingFace ▷ #computer-vision (1 messages):
- HuggingFace ▷ #NLP (3 messages):
- HuggingFace ▷ #diffusion-discussions (2 messages):
- Unsloth AI (Daniel Han) ▷ #general (742 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (5 messages):
- Unsloth AI (Daniel Han) ▷ #help (182 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (2 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (7 messages):
- OpenRouter (Alex Atallah) ▷ #general (663 messages🔥🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (16 messages🔥):
- LM Studio ▷ #general (166 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (396 messages🔥🔥):
- Nous Research AI ▷ #general (438 messages🔥🔥🔥):
- Nous Research AI ▷ #ask-about-llms (22 messages🔥):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #research-papers (2 messages):
- Perplexity AI ▷ #general (329 messages🔥🔥):
- Perplexity AI ▷ #sharing (26 messages🔥):
- Perplexity AI ▷ #pplx-api (7 messages):
- Eleuther ▷ #general (15 messages🔥):
- Eleuther ▷ #research (323 messages🔥🔥):
- Eleuther ▷ #scaling-laws (2 messages):
- Eleuther ▷ #interpretability-general (1 messages):
- Eleuther ▷ #lm-thunderdome (8 messages🔥):
- Eleuther ▷ #multimodal-general (11 messages🔥):
- Eleuther ▷ #gpt-neox-dev (1 messages):
- aider (Paul Gauthier) ▷ #announcements (2 messages):
- aider (Paul Gauthier) ▷ #general (240 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (80 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (4 messages):
- OpenAI ▷ #ai-discussions (184 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (14 messages🔥):
- OpenAI ▷ #prompt-engineering (63 messages🔥🔥):
- OpenAI ▷ #api-discussions (63 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (49 messages🔥):
- Notebook LM Discord ▷ #general (204 messages🔥🔥):
- GPU MODE ▷ #general (18 messages🔥):
- GPU MODE ▷ #triton (100 messages🔥🔥):
- GPU MODE ▷ #torch (7 messages):
- GPU MODE ▷ #cool-links (2 messages):
- GPU MODE ▷ #jobs (1 messages):
- GPU MODE ▷ #beginner (18 messages🔥):
- GPU MODE ▷ #youtube-recordings (1 messages):
- GPU MODE ▷ #torchao (1 messages):
- GPU MODE ▷ #off-topic (2 messages):
- GPU MODE ▷ #rocm (11 messages🔥):
- GPU MODE ▷ #intel (1 messages):
- GPU MODE ▷ #arm (25 messages🔥):
- GPU MODE ▷ #liger-kernel (15 messages🔥):
- GPU MODE ▷ #self-promotion (4 messages):
- GPU MODE ▷ #🍿 (1 messages):
- GPU MODE ▷ #thunderkittens (10 messages🔥):
- Latent Space ▷ #ai-general-chat (70 messages🔥🔥):
- Latent Space ▷ #ai-in-action-club (126 messages🔥🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (192 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #general (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (112 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #news (30 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (17 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (7 messages):
- Interconnects (Nathan Lambert) ▷ #rlhf (17 messages🔥):
- Interconnects (Nathan Lambert) ▷ #reads (15 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (2 messages):
- LlamaIndex ▷ #blog (7 messages):
- LlamaIndex ▷ #general (45 messages🔥):
- LlamaIndex ▷ #ai-discussion (2 messages):
- OpenInterpreter ▷ #general (34 messages🔥):
- OpenInterpreter ▷ #ai-content (9 messages🔥):
- DSPy ▷ #show-and-tell (21 messages🔥):
- DSPy ▷ #general (19 messages🔥):
- tinygrad (George Hotz) ▷ #general (17 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (20 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (8 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (11 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
- LAION ▷ #general (6 messages):
- LAION ▷ #research (6 messages):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (8 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
- Cohere ▷ #discussions (7 messages):
- Cohere ▷ #api-discussions (4 messages):
- Torchtune ▷ #general (6 messages):
- Torchtune ▷ #dev (5 messages):
- Alignment Lab AI ▷ #announcements (1 messages):
- Alignment Lab AI ▷ #general (2 messages):
- MLOps @Chipro ▷ #events (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Technology and Industry Updates
- Major Company Developments: @adcock_brett highlighted significant progress from multiple companies including Etched, Runway, Figure, NVIDIA, OpenAI, Anthropic, Microsoft, Boston Dynamics, ElevenLabs, Osmo, Physical Intelligence, and Meta.
- Model & Infrastructure Updates:
- @vikhyatk announced CPU inference capabilities now available locally
- @dair_ai shared top ML papers covering MrT5, SimpleQA, Multimodal RAG, and LLM geometry concepts
- @rasbt published an article explaining two main approaches to Multimodal LLMs
- @LangChainAI demonstrated RAG Agents with LLMs using NVIDIA course materials
- Product Launches & Features:
- @c_valenzuelab discussed new ways of generating content beyond prompts, including Advanced Camera Controls
- @adcock_brett reported on Etched and DecartAI's Oasis, the first playable fully AI-generated Minecraft game
- @bindureddy showcased AI Engineer building custom AI agents with RAG from English prompts
- Research & Technical Insights:
- @teortaxesTex discussed architecture work in LLMs focusing on inference economics
- @svpino emphasized importance of understanding fundamentals: neural networks, loss functions, optimization techniques
- @c_valenzuelab detailed challenges in AI research labs regarding bureaucracy and resource allocation
Industry Commentary & Culture
- Career & Development: @c_valenzuelab highlighted frustrations in AI research labs including bureaucracy, approval delays, and resource allocation issues
- Technical Discussions: @teortaxesTex discussed AI safety concerns and governance implications
- @DavidSHolz shared an amusing AI safety analogy through a Starcraft game experience
Humor & Memes
- @fchollet joked about AGI vs swipe keyboard accuracy
- @svpino commented on the peaceful nature of the butterfly app
- @vikhyatk made satirical comments about AI access and providers
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Hertz-Dev: First Open-Source Real-Time Audio Model with 120ms Latency
- 🚀 Analyzed the latency of various TTS models across different input lengths, ranging from 5 to 200 words! (Score: 114, Comments: 24): A performance analysis of text-to-speech (TTS) models measured latency across inputs from 5 to 200 words, revealing that Coqui TTS consistently outperformed other models with an average inference time of 0.8 seconds for short phrases and 2.1 seconds for longer passages. The study also found that Microsoft Azure and Amazon Polly exhibited linear latency scaling with input length, while open-source models showed more variable performance patterns especially beyond 100-word inputs.
- Hertz-Dev: An Open-Source 8.5B Audio Model for Real-Time Conversational AI with 80ms Theoretical and 120ms Real-World Latency on a Single RTX 4090 (Score: 591, Comments: 78): Hertz-Dev, an open-source 8.5B parameter audio model, achieves 120ms real-world latency and 80ms theoretical latency for conversational AI running on a single RTX 4090 GPU. The model appears to be designed for real-time audio processing, though no specific implementation details or benchmarking methodology were provided in the post.
- A 70B parameter version of Hertz is currently in training, with plans to expand to more modalities. Running this larger model will likely require H100 GPUs, though some suggest quantization could help reduce hardware requirements.
- Discussion around open source status emerged, with users noting that only weights and inference code are released (like Llama, Gemma, Mistral). Notable exceptions of fully open source models include Olmo and AMD's 1B model.
- The model has a 17-minute context window and could theoretically be fine-tuned like other transformers using audio datasets. Real-world latency (120ms) outperforms GPT-4o (320ms average) and approaches human conversation gaps (200-250ms).
Theme 2. Voice Cloning Advances: F5-TTS vs RVC vs XTTS2
- Speaking with your local LLM with a key press on Linux. Speech to text into any window, most desktop environments. Two hotkeys are the UI. (Score: 51, Comments: 1): The BlahST tool enables Linux users to perform local speech-to-text and LLM interactions using hotkeys, leveraging whisper.cpp, llama.cpp (or llamafile), and Piper TTS without requiring Python or JavaScript. Running on a system with Ryzen CPU and RTX3060 GPU, the tool achieves ~34 tokens/second with gemma-9b-Q6 model and 90x real-time speech inference, while maintaining low system resource usage and supporting multilingual capabilities including Chinese translation.
- Best Open Source Voice Cloning if you have lots of reference audio? (Score: 71, Comments: 18): For voice cloning with 10-20 minutes of reference audio per character, the author seeks alternatives to ElevenLabs and F5-TTS for self-hosted deployment. The post specifically requests solutions that allow pre-training models on individual characters for later inference, moving away from few-shot learning approaches like F5-TTS which are optimized for minimal reference audio.
- RVC (Retrieval-based Voice Conversion) performs well but requires input audio for conversion. When combined with XTTS-2, results can be mixed due to TTS artifacts, though the process is simplified using alltalk-tts beta.
- Fine-tuning F5-TTS produced high-quality results with fast inference using lpscr's implementation, achieving quality comparable to ElevenLabs. The process is now integrated into the main repo via
f5-tts_finetune-gradiocommand. - GPT-SoVITS, MaskCGT, and OpenVoice were mentioned as strong alternatives. MaskCGT leads in zero-shot performance, while GPT-SoVITS was cited as surpassing fine-tuned XTTS2 or F5 reference voice cloning.
Theme 3. Token Management and Model Optimization Techniques
- MMLU-Pro scores of small models (<5B) (Score: 166, Comments: 49): MMLU-Pro benchmark testing with 10 multiple choice options per question establishes a 10% baseline score for random guessing. The test evaluates performance of language models under 5B parameters.
- tips for dealing with unused tokens? keeps getting clogged (Score: 150, Comments: 29): Token usage optimization in LLMs requires managing both input and output tokens to prevent memory clogs and inefficient processing. The post appears to be asking for advice but lacks specific details about the actual problem being encountered with unused tokens or the LLM system being used.
- A significant implementation of KV cache eviction for unused token removal is being developed in VLLM, available at GitHub. This approach differs from compression methods used in llama.cpp or exllama.
- The community referenced research papers including DumpSTAR and DOCUSATE for token analysis, with token expiration methods being proposed since 2021.
- Many users expressed confusion about the post's context, with the top comment noting that responses were polarized between those who fully understood and those completely lost in the technical discussion.
Theme 4. MG²: New Melody-First Music Generation Architecture
- MG²: Melody Is All You Need For Music Generation (Score: 57, Comments: 9): MG², a new music generation model trained on a 500,000 sample dataset, focuses exclusively on melody generation while disregarding other musical elements like harmony and rhythm. The model demonstrates that melody alone contains sufficient information for high-quality music generation, challenging the conventional approach of incorporating multiple musical components, and achieves comparable results to more complex models while using significantly fewer parameters. The research introduces a novel self-attention mechanism specifically designed for melody processing, enabling the model to capture long-range dependencies in musical sequences while maintaining computational efficiency.
- The MusicSet dataset is now available on HuggingFace, containing 500k samples of high-quality music waveforms with descriptions and unique melodies. Users expressed enthusiasm about the dataset's release for advancing music generation research.
- Multiple users found the model's sample outputs underwhelming, with specific concerns about the lack of melody input functionality. One user specifically wanted the ability to transform hummed melodies into cinematic pieces.
- Discussion of videogame music generation highlighted interest in creating soundtracks similar to classics like Mega Man and Donkey Kong Country, with Suno mentioned as a current solution for game music generation with copyright considerations.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Performance and Benchmarks
- SimpleBench reveals gap between human and AI reasoning: Human baseline achieves 83.7% while top models like o1-preview (41.7%) and 3.6 Sonnet (41.4%) struggle with basic reasoning tasks, highlighting limitations in spatial-temporal reasoning and social intelligence /r/singularity.
- Key comment notes that models derive world understanding from language, while humans build language on top of learned world models.
AI Security and Infrastructure
- Critical security vulnerabilities in Nvidia GeForce GPUs: All Nvidia GeForce GPU users urged to update drivers immediately due to discovered security flaws /r/StableDiffusion.
AI Image Generation Progress
- FLUX.1-schnell model released with free unlimited generations: New website launched offering unrestricted access to FLUX.1-schnell image generation capabilities /r/StableDiffusion.
- Historical AI image generation progress: Visual comparison showing dramatic improvement in AI image generation from 2015 to 2024, with detailed discussion of early DeepDream to modern models /r/singularity.
AI Ethics and Society
- Yuval Noah Harari warns of AI-driven reality distortion: Discussion of potential societal impacts of AI creating immersive but potentially deceptive digital environments /r/singularity.
Memes and Humor
- AI-generated anime realism: Highly upvoted post (942 score) showcasing realistic anime-style AI generation /r/StableDiffusion.
- AI security camera humor: Video of security camera system in South Africa /r/singularity.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. Major LLM Releases and Model Updates
- Claude 3.5 Haiku Drops Like a Hot Mixtape: Anthropic released Claude 3.5 Haiku, boasting better benchmarks but hitting users with a 4x price hike. The community debates whether the performance boost justifies the increased cost.
- OpenAI's O1 Model Teases and Vanishes: Users briefly accessed the elusive O1 model via a URL tweak, experiencing advanced features before OpenAI pulled the plug. Speculation abounds about the model's capabilities and official release plans.
- Free Llama 3.2 Models Light Up OpenRouter: OpenRouter now offers free access to Llama 3.2 models, including 11B and 90B variants with improved speeds. Users are thrilled with the 11B variant hitting 900 tps.
Theme 2. AI Advancements in Security and Medicine
- Llama 3.1 Outsmarts GPT-4o in Hacking Benchmark: The new PentestGPT benchmark shows Llama 3.1 outperforming GPT-4o in automated penetration testing. Both models still need improvements in cybersecurity applications.
- MDAgents by Google Aims to Doctor Up Medical Decisions: Google launched MDAgents, an adaptive collaboration of LLMs enhancing medical decision-making. Models like UltraMedical and FEDKIM are set to revolutionize healthcare AI.
- Aloe Beta Sprouts as Open Healthcare LLMs: Aloe Beta, fine-tuned using axolotl, brings a suite of open healthcare LLMs to the table. This marks a significant advancement in AI-driven healthcare solutions.
Theme 3. LLM Fine-Tuning and Performance Struggles
- Unsloth AI Kicks Fine-Tuning into Hyperdrive: Unsloth AI accelerates model fine-tuning nearly 2x faster using LoRA, slashing VRAM usage. Users share strategies for refining models efficiently.
- Hermes 405b Crawls While Others Sprint: Hermes 405b users report glacial response times and errors, sparking frustration. Speculation about rate limiting and API issues circulates as users seek alternatives.
- LM Studio's Mixed GPU Support a Mixed Blessing: LM Studio supports mixed AMD and Nvidia GPU setups, but performance takes a hit due to reliance on Vulkan. For best results, sticking to identical GPUs is recommended.
Theme 4. AI Takes on Gaming and Creative Endeavors
- Oasis Game Opens a New Frontier with AI Worlds: Oasis, the first fully AI-generated game, lets players explore real-time, interactive environments. No traditional game engine here—just pure AI magic.
- Open Interpreter Sparks Joy in AI Enthusiasts: Open Interpreter gains popularity as users integrate it with tools like Screenpipe for AI tasks. Voice capabilities and local recording elevate user experiences.
- AI Podcasts Hit Static, Users Demand Better Sound: NotebookLM users report quality issues in AI-generated podcasts, with random breaks and odd sounds. Calls for robust audio processing and stability improvements grow louder.
Theme 5. AI Ethics, Censorship, and the Community's Voice
- Jailbreakers Debate the True Freedom of LLMs: Users question if jailbreaking LLMs truly liberates models or just adds constraints. The community dives deep into motivations and mechanics behind jailbreaks.
- Censorship Overload Makes Models Mute: Phi-3.5's heavy censorship frustrates users, leading to humorous mock responses and efforts to uncensor the model. An uncensored version pops up on Hugging Face.
- AI Search Engines Compete, Users Left Searching: OpenAI's new SearchGPT underwhelms users seeking real-time results, while alternatives like Perplexity gain praise. The AI search wars are heating up, but not all users are impressed.
PART 1: High level Discord summaries
HuggingFace Discord
-
LLM Fine-tuning and Performance Enhancements: Neuralink achieved a 2x speedup in their code performance, reaching tp=2 with 980 FLOPs, while Llama 3.1 outperformed GPT-4o using the PentestGPT tool, as detailed in the Penetration Testing Benchmark paper.
- Additionally, Gemma 2B surpassed T5xxl on specific tasks with reduced VRAM usage, and discussions highlighted the challenges in MAE finetuning due to deprecation issues.
- AI-driven Cyber Security Models and Benchmarks: A new benchmark, PentestGPT, revealed that Llama 3.1 outperformed GPT-4o in automated penetration testing, indicating both models need improvements in cybersecurity applications as per the recent study.
- There is also a growing interest in developing AI models for malware detection, with community members seeking guidance on implementation strategies.
- AI Development Tools and Environments: The release of VividNode v1.6.0 introduced support for edge-tts and enhanced image generation via GPT4Free, alongside a new ROS2 Docker environment compatible with Ubuntu and Apple Silicon macOS.
- ShellCheck, a static analysis tool for shell scripts, was also highlighted for improving script reliability, as discussed in the GitHub repository.
- Advancements in Quantum Computing for AI: Researchers demonstrated a 1400-second coherence time for a Schrödinger-cat state in $^{173}$Yb atoms, marking a significant breakthrough in quantum metrology discussed in the arXiv paper.
- Additionally, a novel magneto-optic memory chip design promises reduced energy consumption for AI computing, as reported in Nature Photonics.
- AI Applications in Medical Decision-Making: Google launched MDAgents, an adaptive collaboration of LLMs for enhancing medical decision-making, featuring models like UltraMedical and FEDKIM, as highlighted in a recent Medical AI post.
- These innovations aim to streamline medical processes and improve diagnostic accuracy through advanced AI models.
Unsloth AI (Daniel Han) Discord
-
Unsloth AI Accelerates Model Fine-tuning: The Unsloth AI project enables users to fine-tune models like Mistral and Llama nearly 2x faster by utilizing LoRA, reducing VRAM consumption significantly.
- Users discussed strategies such as iteratively refining smaller models before scaling and emphasized the importance of dataset size and quality for effective training.
- Python 3.11 Boosts Performance Across OS: Upgrading to Python 3.11 can yield performance improvements, offering ~1.25x speed on Linux, 1.2x on Mac, and 1.12x on Windows systems, as highlighted in a tweet.
- Concerns were raised about package compatibility during Python upgrades, highlighting the complexities involved in maintaining software stability.
- Efficient Model Inference via Quantization: Discussion centered on the feasibility of fine-tuning quantized models such as Qwen 2.5 72b, aiming for reduced memory usage and satisfactory inference speeds on CPUs.
- It was noted that while model quantization facilitates lightweight deployment, initial training still requires significant computational resources.
- Optimal Web Frameworks for LLM Integration: Recommendations for integrating language models into web applications included frameworks like React and Svelte for frontend development.
- Flask was suggested for developers preferring Python-based solutions to build model interfaces.
- Enhancing Git Practices in Unsloth Repository: The absence of a .gitignore file in the Unsloth repository was highlighted, stressing the importance of managing files before pushing changes.
- Users shared insights on maintaining clean git histories through effective usage of git commands and local exclusion configurations.
OpenRouter (Alex Atallah) Discord
-
Claude 3.5 Haiku Launches in Trio: Anthropic has released Claude 3.5 Haiku in standard, self-moderated, and dated variants. Explore the versions at Claude 3.5 Overview.
- Users can access the different variants through standard, dated, and beta releases, facilitating seamless updates and testing.
- Free Llama 3.2 Models Now Accessible: Llama 3.2 models are available for free via OpenRouter, featuring 11B and 90B variants with improved speeds. Access them at 11B variant and 90B variant.
- The 11B variant offers a performance of 900 tps, while the 90B variant delivers 280 tps, catering to diverse application needs.
- Hermes 405b Encounters Latency Issues: The free version of Hermes 405b is experiencing significant latency and access errors for many users.
- Speculations suggest that the issues might be due to rate limiting or temporary outages, although some users still receive intermittent responses.
- API Rate Limits Cause User Confusion: Users are hitting rate limits on models such as ChatGPT-4o-latest, leading to confusion between GPT-4o and ChatGPT-4o versions on OpenRouter.
- The unclear differentiation between model titles has resulted in mixed user experiences and uncertainties regarding rate limit policies.
- Haiku Pricing Increases Spark Concerns: The pricing for Claude 3.5 Haiku has risen significantly, raising concerns about its affordability among the user base.
- Users are frustrated by the increased costs, especially when comparing Haiku to alternatives like Gemini Flash, questioning its future viability.
LM Studio Discord
-
LM Studio's Mixed GPU Support: Users confirmed that LM Studio supports mixed use of AMD and Nvidia GPUs, though performance may be constrained due to reliance on Vulkan.
- For optimal results, utilizing identical Nvidia cards is recommended over mixed GPU setups.
- Embedding Model Limitations in LM Studio: It was noted that not all models are suitable for embeddings; specifically, Gemma 2 9B is incompatible with LM Studio for this purpose.
- Users are advised to select appropriate embedding models to prevent runtime errors.
- Structured Output Challenges in LLMs: Users are encountering difficulties in enforcing structured output formats, resulting in extraneous text.
- Suggestions include enhancing prompt engineering and utilizing Pydantic classes to improve output precision.
- Using Python for LLM Integration: Discussions focused on implementing code snippets to build custom UIs and functionalities with various language models from Hugging Face.
- Participants highlighted the flexibility of employing multiple models interchangeably to handle diverse tasks.
- LM Studio Performance on Various Hardware: Users reported varying performance metrics when running LLMs via LM Studio on different hardware setups, with some experiencing delays in token generation.
- Concerns were raised about context management and hardware limitations contributing to these performance issues.
Nous Research AI Discord
-
Hermes 405b Model Performance: Users reported slow response times and intermittent errors when using the Hermes 405b model via Lambda and OpenRouter, with some suggesting it felt 'glacial' in performance.
- The free API on Lambda especially showed inconsistent availability, causing frustration among users trying to access the model.
- Jailbreaking LLMs: A member questioned whether jailbreaking LLMs is more about creating constraints to free them, sparking a lively discussion about the motivations and implications of such practices.
- One participant highlighted that many adept at jailbreaking might not fully understand LLM mechanics beneath the surface.
- MDAgents: Google introduced MDAgents, showcasing an Adaptive Collaboration of LLMs aimed at enhancing medical decision-making.
- This week's podcast summarizing the paper emphasizes the importance of collaboration among models in tackling complex healthcare challenges.
- Future of Nous Research Models: Teknium stated that Nous Research will not create any closed-source models, but some other offerings may remain private or contract-based for certain use cases.
- The Hermes series will always remain open source, ensuring transparency in its development.
- AI Search Engine Performance: Users lamented that OpenAI's new search isn't delivering real-time results, especially in comparison to platforms like Bing and Google.
- One noted that Perplexity excels in search result quality and could be seen as superior to both Bing and OpenAI's offerings.
Perplexity AI Discord
-
Claude's 3.5 Haiku Enhances AI Palette: The rollout of Claude 3.5 Haiku across platforms like Amazon Bedrock and Google's Vertex AI has raised concerns regarding its new pricing structure among users.
- Despite cost increases, Claude 3.5 Haiku retains robust conversational capabilities, though its value proposition remains debated against existing tools.
- SearchGPT: OpenAI's Answer to Traditional Search: The introduction of SearchGPT offers a suite of new AI-powered search functionalities aimed at competing with established search engines.
- This launch has sparked discussions regarding the evolving role of AI in information retrieval and the future dynamics of search technology.
- China's Llama AI Model Advances Military AI: Reports indicate that the Chinese military is developing a Llama-based AI model, signifying a strategic move in defense AI applications.
- This development intensifies global conversations about AI's role in military advancements and international tech competition in defense sectors.
Eleuther Discord
-
Gradient Dualization Influences Model Training Dynamics: Discussions highlighted the role of gradient dualization in training deep learning models, focusing on how norms affect model performance as architectures scale.
- Participants explored the impact of alternating between parallel and sequential attention mechanisms, referencing the paper Preconditioned Spectral Descent for Deep Learning.
- Optimizer Parameter Tuning Mirrors Adafactor Schedules: Members analyzed changes to the Adafactor schedule, noting its similarity to adding another hyperparameter and questioning the innovation behind these adjustments.
- The optimal beta2 schedule was found to resemble Adafactor's existing configuration, as discussed in Quasi-hyperbolic momentum and Adam for deep learning.
- Best Practices for Configuring GPT-NeoX: Engineers are utilizing Hypster for configurations and integrating MLFlow for experiment tracking in their GPT-NeoX setups.
- A member inquired about the prevalence of using DagsHub, MLFlow, and Hydra together, referencing the lm-evaluation-harness.
- DINOv2 Enhances ImageNet Pretraining with Expanded Data: DINOv2 leverages 22k ImageNet data, resulting in improved evaluation metrics compared to the previous 1k dataset.
- The DINOv2 paper demonstrated enhanced performance metrics, emphasizing effective distillation techniques.
- Trade-offs Between Scaling and Depth in Neural Networks: The community discussed the balance between depth and width in neural network architectures, analyzing how each dimension impacts overall performance.
- Empirical validations were suggested to confirm the theory that as models scale, the dynamics between network depth and width become increasingly aligned.
aider (Paul Gauthier) Discord
-
Claude 3.5 Haiku Gains on Leaderboard: Claude 3.5 Haiku achieved a 75% score on Aider's Code Editing Leaderboard, positioning just behind the previous Sonnet 06/20 model.
- This marks Haiku as a cost-efficient alternative, closely matching Sonnet's capabilities in code editing tasks.
- Aider v0.62.0 Integrates Claude 3.5 Haiku: The latest Aider v0.62.0 release now fully supports Claude 3.5 Haiku, enabling activation via
--haikuflag.
- Additionally, it introduces features to apply edits from web apps like ChatGPT, enhancing developer workflow.
- Comprehensive AI Model Comparisons: Discussions highlighted Sonnet 3.5 for its superior quality, while Haiku 3.5 is acknowledged as a robust but slower contender.
- Community members compared coding capabilities across models and shared real-world application experiences.
- Benchmark Performance Insights: Sonnet 3.5 outperforms other models in benchmark results shared by Paul G, whereas Haiku 3.5 lags in efficiency.
- There's significant interest in mixed model combinations, such as Sonnet and Haiku, for diverse task performance.
- OpenAI's Strategic o1 Leak: Users observed that OpenAI's leak of o1 seems deliberate to build anticipation for future releases.
- Referencing Sam Altman's past tactics, such as imagery like strawberries and Orion starry sky, to generate interest.
OpenAI Discord
-
GPT-4o Enhances Reasoning with Canvas Features: The next version of GPT-4o is rolling out, introducing advanced reasoning capabilities similar to O1. This update includes features like placing large text blocks in a canvas-style box, enhancing usability for reasoning tasks.
- Users expressed excitement upon gaining full access to O1, pointing out the significant improvements in reasoning efficiency. This upgrade aims to streamline complex task executions for AI Engineers.
- OpenAI's Orion Project Sparks Anticipation: OpenAI's Orion project has members excited for forthcoming AI innovations expected by 2025. Discussions highlight that while Orion is underway, current models like O1 are not yet classified as true AGI.
- Conversations emphasize the Orion project's potential to bridge the gap between current capabilities and AGI, with members eagerly anticipating major breakthroughs in the near future.
- Adoption of Middleware in OpenAI Integrations: Members are exploring the use of middleware products that route requests to different endpoints instead of directly connecting to OpenAI. This approach is being debated to assess its normalcy and effectiveness.
- One member questioned if using middleware is a standard pattern, seeking insights from the community on best practices for integrating API endpoints with OpenAI's services.
- Enhancing Prompt Measurement with Analytics Tools: Discussions are focused on prompt measurement tools for tracking user interactions, including frustration levels and task completion rates. Members suggested utilizing sentiment analysis to gain deeper insights.
- Implementers are considering directing LLMs to process conversational data, aiming to refine prompt effectiveness and improve overall user satisfaction through data-driven adjustments.
- Automating Task Planning Using LLMs: Participants are seeking resources for automating complex task planning with LLMs, specifically for generating SQL queries and conducting data analysis. Clarity in requirements is emphasized for effective automation.
- Contributors highlighted the potential of models to assist in brainstorming sessions and streamline the planning process, underlining the importance of precise query formulation.
Notebook LM Discord Discord
-
NotebookLM Language Configuration Challenges: Users reported difficulties configuring NotebookLM to respond in their preferred languages, especially when uploading documents in different languages. Instructions emphasized that NotebookLM defaults to the language set in the user's Google account.
- This has sparked discussions on enhancing language support to accommodate a more diverse user base.
- Podcast Generation Quality Issues: Multiple users flagged concerns about the quality of NotebookLM podcasts, noting unexpected breaks and random sounds during playback. While some found the interruptions entertaining, others expressed frustration over the negative impact on the listening experience.
- These quality issues are leading to calls for more robust audio processing and stability improvements.
- API Development Speculations: Discussions arose around the potential development of an API for NotebookLM, influenced by a tweet from Vicente Silveira hinting at upcoming API features.
- Despite the community's interest, no official announcements have been made, leaving room for speculation based on industry trends.
- Audio Overview Feature Requests: A user inquired about generating multiple audio overviews from a dense 200-page PDF using NotebookLM, contemplating the labor-intensive method of splitting the document into smaller parts. Suggestions included submitting feature requests for generating audio overviews from single sources.
- This reflects a demand for more efficient summarization tools within NotebookLM to handle large documents seamlessly.
- Special Needs Use Cases Expansion: Members shared experiences using NotebookLM for special needs students and sought use cases or success stories to support a pitch to Google's accessibility team. Plans to build a collective in the UK were also discussed.
- These efforts highlight the community's initiative to leverage NotebookLM for enhancing educational accessibility.
GPU MODE Discord
-
Triton Kernel Optimization: Members discussed the complexities of optimizing Triton kernels, particularly the GPU's waiting time for CPU operations, and suggested that stacking multiple Triton matmul operations could reduce overhead for larger matrices.
- The conversation emphasized strategies to improve performance by minimizing CPU-GPU synchronization delays, with members considering various approaches to enhance kernel efficiency.
- FP8 Quantization Techniques: A user shared their experience with FP8 quantization methods, noting surprising speed improvements compared to pure PyTorch implementations, and provided a link to their GitHub repository.
- The discussion highlighted challenges in dynamically quantizing activations efficiently, referencing the flux-fp8-api as a resource for implementing these techniques.
- LLM Inference on ARM CPUs: LLM inference on ARM CPUs like NVIDIA's Grace and AWS's Graviton was explored, with discussions on handling larger models up to 70B and referencing the torchchat repository.
- Participants noted that clustering multiple ARM SBCs equipped with Ampere Altra processors can yield effective performance, especially when utilizing tensor parallelism to bridge CPU and GPU capabilities.
- PyTorch H100 Optimizations: There was an in-depth discussion on PyTorch's optimizations for H100 hardware, confirming support for cudnn attention but noting that issues led to its default disablement in version 2.5.
- Members shared mixed experiences regarding the stability of H100 features, mentioning that Flash Attention 3 remains under development and affects performance consistency.
- vLLM Demos and Llama 70B Performance: Plans to develop streams and blogs showcasing vLLM implementations with custom kernels were announced, with considerations for creating a forked repository to enhance the forward pass.
- Discussions on improving Llama 70B's performance under high decode workloads included potential collaborations with vLLM maintainers and integrating Flash Attention 3 for better efficiency.
Latent Space Discord
-
Claude Introduces Visual PDF Support: Claude has launched visual PDF support across Claude AI and the Anthropic API, enabling users to analyze diverse document formats.
- This update allows extraction of data from financial reports and legal documents, enhancing user interactions significantly.
- AI Search Engine Competition Intensifies: The revival of search engine rivalry is evident with new entrants like SearchGPT and Gemini challenging Google's dominance.
- The AI Search Wars article details various innovative search solutions and their implications.
- O1 Model Briefly Accessible, Then Secured: The O1 model was temporarily accessible via a URL modification, allowing image uploads and swift inference capabilities.
- Amidst excitement and speculation, ChatGPT's O1 emerged, but access has since been restricted.
- Entropix Achieves 7% Boost in Benchmarks: Entropix demonstrated a 7 percentage point increase in benchmarks for small models, indicating its scalability.
- Members are anticipating how these results will influence future model developments and implementations.
- Open Interpreter Gains Traction Among Users: Users have expressed enthusiasm for Open Interpreter, considering its integration for AI tasks.
- One member suggested setting it up for future use, noting they feel out of the loop.
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion 3.5 support with A1111: Users discussed whether Stable Diffusion 3.5 works with AUTOMATIC1111, mentioning that while it is new, it may have limited compatibility.
- It was suggested to find guides on utilizing SD3.5, which might be available on YouTube due to its recent release.
- Concerns over Scam Bots in Server: Users raised concerns about a scam bot sending links and the lack of direct moderation presence within the server.
- Moderation methods such as right-click reporting were discussed, with mixed feelings about their effectiveness in preventing spam.
- Techniques for Prompting 'Waving Hair': A user sought advice on how to prompt for 'waving hair' without indicating that the character should be waving.
- Suggestions included using simpler terms like 'wavey' to achieve the intended effect without misinterpretation.
- Resources for Model Training: Users shared insights on training models using images and tags, expressing uncertainty about the relevance of older tutorials.
- Resources mentioned included KohyaSS and discussions about training with efficient methods and tools.
- Issues with Dynamic Prompts Extension: One user reported frequent crashes when using the Dynamic Prompts extension in AUTOMATIC1111, leading to frustration.
- Conversations centered around installation errors and the need for troubleshooting assistance, with one user sharing their experiences.
Modular (Mojo 🔥) Discord
-
Mojo Hardware Lowering Support: Members discussed the limitations of Mojo's current hardware lowering capabilities, specifically the inability to pass intermediate representations to external compilers as outlined in the Mojo🔥 FAQ | Modular Docs.
- A suggestion was made to contact Modular for potential upstreaming options if enhanced hardware support is desired.
- Managing References in Mojo: A member inquired about storing safe references from one container to another and encountered problems with lifetimes in structs, highlighting the need for tailored designs to avoid invalidation issues.
- Discussions emphasized ensuring pointer stability while manipulating elements in custom data structures.
- Slab List Implementation: Members reviewed the implementation of a slab list and considered memory management aspects, noting the potential for merging functionality with standard collections.
- The concept of using inline arrays and how it affects performance and memory consistency was crucial to their design.
- Mojo Stability and Nightly Releases: Concerns were raised about the stability of switching fully to nightly Mojo releases, highlighting that nightly versions can change significantly before merging to main.
- Despite including the latest developments, members emphasized the need for stability and PSA regarding significant changes.
- Custom Tensor Structures in Neural Networks: The need for custom tensor implementations in neural networks was explored, revealing various use cases such as memory efficiency and device distribution.
- Members noted parallels with data structure choices, maintaining that the need for specialized data handling remains relevant.
Interconnects (Nathan Lambert) Discord
-
AMD Reintroduces OLMo Language Model: AMD has reintroduced the OLMo language model, generating significant interest within the AI community.
- Members reacted with disbelief and humor, expressing surprise over AMD's developments in language modeling.
- Grok Model API Launches with 128k Context: The Grok model API has been released, providing developers access to models with a context length of 128,000 tokens.
- The beta program includes free trial credits, humorously referred to as '25 freedom bucks', encouraging experimentation.
- Claude 3.5 Haiku Pricing Quadruples: Claude 3.5 Haiku has been launched, delivering enhanced benchmarks but at 4x the cost of its predecessor.
- There is speculation regarding the unexpected price increase amidst a market pressure driving AI inference costs downward.
- AnthropicAI Token Counting API Explored: Members experimented with the AnthropicAI Token Counting API focusing on Claude's chat template and digit tokenization of images/PDFs.
- The accompanying image provided a TL;DR of the API's capabilities, highlighting its handling of different data formats.
- Chinese Military Utilizes Llama Model for Warfare Insights: The Chinese military has employed Meta’s Llama model to analyze and develop warfare tactics and structures, fine-tuning it with publicly available military data.
- This adaptation allows the model to effectively respond to queries related to military affairs, showcasing Llama's versatility.
LlamaIndex Discord
-
OilyRAGs Champions Hackathon with AI: The AI-powered catalog OilyRAGs secured 3rd place at the LlamaIndex hackathon, demonstrating the capabilities of Retrieval-Augmented Generation in enhancing mechanical workflows. Explore its implementation here and its claimed 6000% efficiency improvement.
- This project aims to streamline tasks in the mechanics sector, showcasing practical RAG applications.
- Optimizing Custom Agent Workflows: A discussion on Custom Agent Creation led to recommendations to bypass the agent worker/runner and utilize workflows instead, as detailed in the documentation.
- This method simplifies the agent development process, enabling more efficient integration of specialized reasoning loops.
- Cost Estimation Strategies for RAG Pipelines: Members debated RAG pipeline cost estimation using OpenAIAgentRunner, clarifying that tool calls are billed separately from completion calls.
- They emphasized using the LlamaIndex token counting utility to accurately calculate the average token usage per message for better budgeting.
- Introducing bb7: A Local RAG Voice Chatbot: bb7, a local RAG-augmented voice chatbot, was introduced, allowing document uploads and context-aware conversations without external dependencies. It incorporates Text-to-Speech for smooth interactions here.
- This innovation highlights advancements in creating user-friendly, offline-capable chatbot solutions.
- Lightweight API for Data Analysis Tested: A new API for Data Analysis was presented, offering a faster and lightweight alternative to OpenAI Assistant and Code Interpreter, specifically designed for data analysis and visualizations here.
- It generates either CSV files or HTML charts, emphasizing conciseness and efficiency without superfluous details.
OpenInterpreter Discord
-
Anthropic Anomalies in Claude Command: Users reported a series of Anthropic errors and API issues with the latest Claude model, specifically related to the command
interpreter --model claude-3-5-sonnet-20240620.- One user identified a recurring error, hinting at a trend affecting multiple users.
- Even Realities Enhance Open Interpreter: A member promoted the Even Realities G1 glasses as a potential tool for Open Interpreter integration, highlighting their open-source commitment.
- Others discussed the hardware capabilities and anticipated future plugin support.
- Oasis AI: Pioneering Fully AI-Generated Games: The team announced Oasis, the first playable, realtime, open-world AI model, marking a step towards complex interactive environments.
- Players can engage with the environment via keyboard inputs, showcasing real-time gameplay without a traditional game engine.
- Claude 3.5 Haiku Hits High Performance: Claude 3.5 Haiku is now available on multiple platforms including the Anthropic API and Google Cloud's Vertex AI, offering the fastest and most intelligent experience yet.
- The model surpassed Claude 3 Opus on various benchmarks while maintaining cost efficiencies, as shared in this tweet.
- OpenInterpreter Optimizes for Claude 3.5: A new pull request introduced a profile for Claude Haiku 3.5, submitted by MikeBirdTech.
- The updates aim to enhance integration within the OpenInterpreter project, reflecting ongoing repository development.
DSPy Discord
-
Full Vision Support in DSPy: A member celebrated the successful merge of Pull Request #1495 that adds Full Vision Support to DSPy, marking a significant milestone.
- It's been a long time coming, expressing appreciation for the teamwork involved.
- Docling Document Processing Tool: A member introduced Docling, a document processing library that can convert various formats into structured JSON/Markdown outputs for DSPy workflows.
- They highlighted key features including OCR support for scanned PDFs and integration capabilities with LlamaIndex and LangChain.
- STORM Module Modifications: A member suggested improvements to the STORM module, specifically enhancing the utilization of the table of contents.
- They proposed generating articles section by section based on the TOC and incorporating private information to enhance outputs.
- Forcing Output Fields in Signatures: A member inquired about enforcing an output field in a signature to return existing features instead of generating new ones.
- Another member provided a solution by outlining a function that correctly returns the features as part of the output.
- Optimizing Few-shot Examples: Members discussed optimizing few-shot examples without modifying prompts, focusing on enhancing example quality.
- Recommendations were made to use BootstrapFewShot or BootstrapFewShotWithRandomSearch optimizers to achieve this.
tinygrad (George Hotz) Discord
-
WebGPU's future integration in tinygrad: Members discussed the readiness of WebGPU and suggested implementing it once it's ready.
- One member mentioned, when WebGPU is ready, we can consider that.
- Apache TVM Features: The Apache TVM project tvm.apache.org focuses on optimizing machine learning models across diverse hardware platforms, offering features like model compilation and backend optimizations.
- Members highlighted its support for platforms such as ONNX, Hailo, and OpenVINO.
- Challenges implementing MobileNetV2 in tinygrad: A user encountered issues with implementing MobileNetV2, specifically with the optimizer failing to calculate gradients properly.
- The community engaged in troubleshooting efforts and discussed various experimental results to resolve the problem.
- Fake PyTorch Backend Development: A member shared their 'Fake PyTorch' wrapper that utilizes tinygrad as the backend, currently supporting basic features but missing advanced functionalities.
- They invited feedback and expressed curiosity about their development approach.
- Release of Oasis AI model: The Oasis project announced the release of an open-source real-time AI model capable of generating playable gameplay and interactions using keyboard inputs. They released code and weights for the 500M parameter model, highlighting its capability for real-time video generation.
- Future plans aim to enhance performance, as discussed by the team members.
OpenAccess AI Collective (axolotl) Discord
-
Fine-Tuning Llama 3.1 for Domain-Specific Q&A: A member sought high-quality instruct datasets in English to fine-tune Meta Llama 3.1 8B, aiming to integrate with domain-specific Q&A, favoring fine-tuning over LoRA methods.
- They emphasized the goal of maximizing performance through fine-tuning, highlighting the challenges associated with alternative methods.
- Addressing Catastrophic Forgetting in Fine-Tuning: A member reported experiencing catastrophic forgetting while fine-tuning their model, raising concerns about the stability of the process.
- In response, another member suggested that RAG (Retrieval-Augmented Generation) might offer a more effective solution for certain applications.
- Granite 3.0 Benchmarks Outperform Llama 3.1: Granite 3.0 was proposed as an alternative, boasting higher benchmarks compared to Llama 3.1, and includes a fine-tuning methodology designed to prevent forgetting.
- Additionally, Granite 3.0's Apache license was highlighted, offering greater flexibility for developers.
- Enhancing Inference Scripts and Resolving Mismatches: Members identified that the current inference script lacks support for chat formats, only handling plain text and adding a
begin_of_texttoken during generation.
- This design flaw leads to a mismatch with training, sparking discussions on potential improvements and updates to the README documentation.
- Launch of Aloe Beta: Advanced Healthcare LLMs: Aloe Beta, a suite of fine-tuned open healthcare LLMs, was released, marking a significant advancement in AI-driven healthcare solutions. Details are available here.
- The development involved a meticulous SFT phase using axolotl, ensuring the models are tailored for various healthcare-related tasks, with team members expressing enthusiasm for its potential impact.
LAION Discord
-
32 CLS Tokens Enhance Stability: Introducing 32 CLS tokens significantly stabilizes the training process, improving reliability and enhancing outcomes.
- This adjustment demonstrates a clear impact on training consistency, making it a noteworthy development for model performance.
- Blurry Latent Downsampling Concerns: A member questioned the suitability of bilinear interpolation for downsampling latents, noting that the results appear blurry.
- This concern highlights potential limitations in current downsampling methods, prompting a reevaluation of technique effectiveness.
- Standardizing Inference APIs: Developers of Aphrodite, AI Horde, and Koboldcpp have agreed on a standard to assist inference integrators in recognizing APIs for seamless integration.
- The new standard is live on platforms like AI Horde, with ongoing efforts to onboard more APIs and encourage collaboration among developers.
- RAR Image Generator Sets New FID Record: The RAR image generator achieved a FID score of 1.48 on the ImageNet-256 benchmark, showcasing exceptional performance.
- Utilizing a randomness annealing strategy, RAR outperforms previous autoregressive image generators without incurring additional costs.
- Position Embedding Shuffle Complexities: A proposal to shuffle the position embeddings at the start of training, gradually reducing this effect to 0% by the end, has emerged.
- Despite its potential, a member noted that implementing this shuffle is more complex than initially anticipated, reflecting the challenges in optimizing embedding strategies.
LLM Agents (Berkeley MOOC) Discord
-
LLM Agents Hackathon Setup Deadline: Teams are reminded to set up their OpenAI API and Lambda Labs Access by End of Day Monday, 11/4, to avoid impacting resource access and can submit via this form.
- Early API setup enables credits from OpenAI next week, ensuring smooth participation and access to the Lambda inference endpoint throughout the hackathon.
- Project GR00T Presentation by Jim Fan: Jim Fan will present Project GR00T, NVIDIA's initiative for generalist robotics AI brains, during the livestream here at 3:00pm PST.
- As the Research Lead of GEAR, he emphasizes developing generally capable AI agents across various settings.
- Team Formation for Hackathon: Participants seeking collaboration opportunities for the LLM Agents Hackathon can apply via this team signup form, outlining goals for innovative LLM-based agents.
- This form facilitates team applications, encouraging the formation of groups focused on creating advanced LLM agents.
- Jim Fan's Expertise and Achievements: Dr. Jim Fan, with a Ph.D. from Stanford Vision Lab, received the Outstanding Paper Award at NeurIPS 2022 for his research on multimodal models for robotics and AI agents excelling at Minecraft.
- His impactful work has been featured in major media outlets like New York Times and MIT Technology Review.
Cohere Discord
-
Simulating ChatGPT's Browsing Mechanics: A member in R&D is exploring the manual simulation of ChatGPT's browsing by tracking search terms and results, aiming to analyze SEO impact and the model's ability to filter and rank up to 100+ results efficiently.
- This initiative seeks to compare ChatGPT's search behavior with human search methods to enhance understanding of AI-driven information retrieval.
- Chatbots Challenging Traditional Browsers: The discussion highlighted the potential for chatbots like ChatGPT to replace traditional web browsers, acknowledging the difficulty in predicting such technological shifts.
- One participant referenced past technology forecasts, such as the evolution of video calling, to illustrate the unpredictability of future advancements.
- Augmented Reality Transforming Info Access: A member proposed that augmented reality could revolutionize information access by providing constant updates, moving beyond the current expectations of a browserless environment.
- This viewpoint expands the conversation to include potential transformative technologies, emphasizing new methods of interacting with information.
- Cohere API Query Redirection: A member advised against posting general questions in the Cohere API channel, directing them instead to the appropriate discussion space for API-related inquiries.
- Another member acknowledged the mistake humorously, noting the widespread AI interest among users and committing to properly channel future questions.
Torchtune Discord
-
Torchtune Enables Distributed Checkpointing: A member inquired about an equivalent to DeepSpeed's
stage3_gather_16bit_weights_on_model_savein Torchtune, addressing issues during multi-node finetuning.- It was clarified that setting this flag to false facilitates distributed/sharded checkpointing, allowing each rank to save its own shard.
- Llama 90B Integrated into Torchtune: A pull request was shared to integrate Llama 90B into Torchtune, aiming to resolve checkpointing bugs.
- The PR #1880 details enhancements related to checkpointing in the integration process.
- Clarifying Gradient Norm Clipping: Members discussed the correct computation of gradient norms in Torchtune, emphasizing the need for a reduction across L2 norms of all per-parameter gradients.
- There is potential to clip gradient norms in the next iteration, though this would alter the original gradient clipping logic.
- Duplicate 'compile' Key in Config Causing Failures: A duplicate
compilekey was found in llama3_1/8B_full.yaml, leading to run failures.
- Uncertainty remains whether other configuration files have similar duplicate key issues.
- ForwardKLLoss Actually Computes Cross-Entropy: ForwardKLLoss in Torchtune computes cross-entropy instead of KL-divergence as expected, requiring adjustments to expectations.
- The distinction is crucial since optimizing KL-divergence effectively means optimizing cross-entropy due to constant terms.
Alignment Lab AI Discord
-
Aphrodite Adds Experimental Windows Support: Aphrodite now supports Windows in an experimental phase, enabling high-throughput local AI optimized for NVIDIA GPUs. Refer to the installation guide for setup details.
- Additionally, support for AMD and Intel compute has been confirmed, although Windows support remains untested. Kudos to AlpinDale for spearheading the Windows implementation efforts.
- LLMs Drive Auto-Patching Innovations: A new blog post on self-healing code discusses how LLMs are instrumental in automatically fixing vulnerable software, marking 2024 as a pivotal year for this advancement.
- The author elaborates on six approaches to address auto-patching, with two already available as products and four remaining in research, highlighting a blend of practical solutions and ongoing innovation.
- LLMs Podcast Explores Auto-Healing Software: The LLMs Podcast features discussions on the self-healing code blog post, providing conversational insights into auto-healing software technologies.
- Listeners can access the podcast on both Spotify and Apple Podcast, enabling engagement with the content in an auditory format.
MLOps @Chipro Discord
-
LoG Conference Lands in Delhi: The Learning on Graphs (LoG) Conference will take place in New Delhi from 26 - 29 November 2024, focusing on advancements in machine learning on graphs. This inaugural South Asian chapter is hosted by IIT Delhi and Mastercard, with more details available here.
- The conference aims to connect innovative thinkers and industry professionals in graph learning, encouraging participation from diverse fields such as computer science, biology, and social science.
- Graph Machine Learning at LoG 2024: LoG 2024 places a strong emphasis on machine learning on graphs, showcasing the latest advancements in the field. Attendees can find more information about the conference on the official website.
- The event seeks to foster discussions that bridge various disciplines, promoting collaboration among experts in machine learning, biology, and social science.
- Local Meetups for LoG 2024: The LoG community is organizing a network of local mini-conferences to facilitate discussions and collaborations in different geographic regions. A call for local meetups for LoG 2024 is currently open, aiming to enhance social experiences during the main event.
- These local meetups are designed to bring together participants from similar areas, promoting community engagement and shared learning opportunities.
- LoG Community Resources: Participants of LoG 2024 can join the conference community on Slack and follow updates on Twitter. Additionally, recordings and materials from past conferences are available on YouTube.
- These resources ensure that attendees have continuous access to valuable materials and can engage with the community beyond the conference dates.
Gorilla LLM (Berkeley Function Calling) Discord
-
Function Definitions Needed for Benchmarking: A member is benchmarking a retrieval-based approach to function calling and is seeking a collection of available functions and their definitions for indexing.
- They specifically mentioned that having this information organized per test category would be extremely helpful.
- Structured Collections Enhance Benchmarks: The discussion highlights the demand for a structured collection of function definitions to aid in function calling benchmarks.
- Organizing information by test category would improve accessibility and usability for engineers conducting similar work.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #general (955 messages🔥🔥🔥):
Discussion on AI tools for PDF processingExperiences with various models and datasetsThoughts on politics and current eventsChallenges in fine-tuning LLMsBuilding custom applications for specific use cases
-
Exploring PDF Parsing Techniques: Maggyd and others discussed the difficulties in extracting information from PDFs due to their complex structure, suggesting tools like PDFPig and PDFPlumber for parsing.
- Technosourceressextraordinaire mentioned the challenges of PDFs being designed for one-way publishing, and offered Adobe's API as a potential resource for accessibility.
- Building Language and Image Processing Models: Hotprotato explained the importance of tokenizers in NLP and suggested existing models like BERT and RoBERTa for creating a Grammarly-like application.
- Newbie_boobie expressed interest in understanding depth-based models and their applications beyond simple grammar checking.
- Political Discussions and Opinions: The group shared opinions on the current political climate, expressing frustration with candidates and their capabilities.
- Concerns about potential outcomes of upcoming elections were discussed, leading to a broader conversation about political accountability.
- Personal Projects and Learning Paths: Several users shared their personal projects in AI, including building a self-forming neural network and experimenting with various existing models.
- There were discussions on how each member is navigating their learning journeys, emphasizing the importance of curiosity and experimenting.
- Challenges of Machine Learning Development: Users reflected on the complexities involved in AI development, such as hardware limitations and the need for robust models for specific tasks.
- Strategies for dealing with these challenges, including leveraging open-source tools and APIs, were shared among community members.
Links mentioned:
- Cat Wait Waiting Cat GIF - Cat wait Waiting cat Wait - Discover & Share GIFs: Click to view the GIF
- I can’t get Email confirmation link: Today, I signed up Hugging Face, however, I can’t get the Email confirmation link. I copy and paste my email address from my email box but I can’t get it. Mabye, It’s happening to other people. I...
- google/deplot · Hugging Face: no description found
- GPTQ - Qwen: no description found
- Supported Models: no description found
- minchyeom/birthday-llm · Hugging Face: no description found
- Joe Biden Presidential Debate GIF - Joe biden Presidential debate Huh - Discover & Share GIFs: Click to view the GIF
- Cat GIF - Cat - Discover & Share GIFs: Click to view the GIF
- The Deep Deep Thoughts GIF - The Deep Deep Thoughts Deep Thoughts With The Deep - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- Fish Agent - a Hugging Face Space by fishaudio: no description found
- Llama 3.2 3b Voice - a Hugging Face Space by leptonai: no description found
- 我赢啦 GIF - I Won Trump Donald Trump - Discover & Share GIFs: Click to view the GIF
- Drugs Bye GIF - Drugs Bye Felicia - Discover & Share GIFs: Click to view the GIF
- Unlimited Power Star Wars GIF - Unlimited Power Star Wars - Discover & Share GIFs: Click to view the GIF
- Ladacarpiubellachece GIF - Ladacarpiubellachece - Discover & Share GIFs: Click to view the GIF
- Space runs OK for several hours then ? runtime error: I have a python/gradio space (GradioTest - a Hugging Face Space by dlflannery) that was running fine for months until 2 days ago it wll run for several hours fine then: Runtime error Exit code: ?. Re...
- Fire Kill GIF - Fire Kill Fuego - Discover & Share GIFs: Click to view the GIF
- Hugging Face – The AI community building the future.: no description found
- THUDM/glm-4-voice-9b · Hugging Face: no description found
- facebook/deit-tiny-patch16-224 · Hugging Face: no description found
- BE DEUTSCH! [Achtung! Germans on the rise!] | NEO MAGAZIN ROYALE mit Jan Böhmermann - ZDFneo: English description belowDie Welt dreht durch! Europa fühlt sich so schwach, dass es sich von 0,3% Flüchtlingen bedroht sieht, Amerika ist drauf und dran ein...
- saiydero/Cypher_valorant_BR_RVC2 at main: no description found
- Qwen/Qwen2-VL-2B-Instruct · Hugging Face: no description found
- Download files from the Hub: no description found
- How to download a model from huggingface?: For example, I want to download bert-base-uncased on https://huggingface.co/models, but can't find a 'Download' link. Or is it not downloadable?
- sha - Overview: sha has 5 repositories available. Follow their code on GitHub.
- dandelin/vilt-b32-finetuned-vqa · Hugging Face: no description found
- GitHub - intel/intel-extension-for-transformers: ⚡ Build your chatbot within minutes on your favorite device; offer SOTA compression techniques for LLMs; run LLMs efficiently on Intel Platforms⚡: ⚡ Build your chatbot within minutes on your favorite device; offer SOTA compression techniques for LLMs; run LLMs efficiently on Intel Platforms⚡ - intel/intel-extension-for-transformers
- Self Healing Code – D-Squared: no description found
- GitHub - intel-analytics/ipex-llm: Accelerate local LLM inference and finetuning (LLaMA, Mistral, ChatGLM, Qwen, Mixtral, Gemma, Phi, MiniCPM, Qwen-VL, MiniCPM-V, etc.) on Intel XPU (e.g., local PC with iGPU and NPU, discrete GPU such as Arc, Flex and Max); seamlessly integrate with llama.cpp, Ollama, HuggingFace, LangChain, LlamaIndex, vLLM, GraphRAG, DeepSpeed, Axolotl, etc: Accelerate local LLM inference and finetuning (LLaMA, Mistral, ChatGLM, Qwen, Mixtral, Gemma, Phi, MiniCPM, Qwen-VL, MiniCPM-V, etc.) on Intel XPU (e.g., local PC with iGPU and NPU, discrete GPU su...
- GitHub - huggingface/lerobot: 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning: 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning - huggingface/lerobot
- NVIDIA RTX 2000E Ada Generation | Professional GPU | pny.com: no description found
- U.S. National Debt Clock : Real Time: no description found
- lerobot/examples/7_get_started_with_real_robot.md at main · huggingface/lerobot: 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning - huggingface/lerobot
- Meta’s Orion prototype: A promising look into augmented reality’s future): Meta’s Orion AR glasses bring augmented reality closer to reality, blending digital content with the real world for a seamless user experience.
- Buy AMD Ryzen 7 4700S Octa Core Desktop Kit Online - Micro Center India: Get the Best Price on AMD Ryzen 7 4700S Octa Core Desktop Kit in India from Micro Center India. Enjoy Free Shipping and Shop Online with Confidence. Check Reviews and Ratings Today
HuggingFace ▷ #today-im-learning (8 messages🔥):
Neuralink code performanceCyber Security AI ModelsTransformers Image Preprocessor Bug
-
Neuralink Code Performance Improved: Neuralink reported that the code is now 2x faster than two days ago, achieving tp=2 with 980 FLOPs.
- They also learned that tp is linear with 1033 FLOPs, resulting in a 55% speed up in processing.
- Aspiration to Build AI Models for Cyber Security: There is a request for tips on building AI models specifically for cyber security, focusing on applications like a malware detection model.
- The user reached out to the community seeking guidance and expertise in this domain.
- Bug Investigation in Transformer's Preprocessor: A member is investigating a potential bug in the transformer's image preprocessor, but hasn't identified the root cause yet.
- They shared a link to the channel where discussions about the issue are ongoing.
HuggingFace ▷ #cool-finds (8 messages🔥):
Quantum MetrologyAI Memory ChipsMedical AI ResearchOpen Trusted Data InitiativeShellCheck Tool
-
Long-lived Schrödinger-cat State Demonstrated: Researchers achieved a coherence time of 1400 seconds for a Schrödinger-cat state of $^{173}$Yb atoms, showcasing a breakthrough in quantum metrology with nonclassical states.
- This advancement can potentially enhance measurement precision, paving the way for improved applications in quantum technologies.
- Revolutionary Memory Chip for AI Computing: A new design for magneto-optic memory cells promises to reduce energy consumption in AI computing farms, allowing for high-speed calculations within the memory array.
- Reported in Nature Photonics, this technology aims to offer faster processing speeds while minimizing power requirements.
- Medical AI Innovations from Google: Google introduced MDAgents, a collaborative model aimed at improving medical decision-making through adaptive LLMs, featured in a recent Medical AI post.
- The post highlights several new models and frameworks such as UltraMedical and FEDKIM, demonstrating rapid advancements in the medical AI sector.
- Massive Open Trusted Dataset Coming Soon: Exciting news as pleiasfr joins thealliance_ai to co-lead the Open Trusted Data Initiative, providing a multilingual dataset with 2 trillion tokens for LLM training.
- This dataset will be released on November 11th on Hugging Face, marking a significant step forward in open AI resources.
- ShellCheck: Enhance Your Shell Scripts: The GitHub repository for ShellCheck, a static analysis tool for shell scripts, offers robust utilities for identifying and fixing errors in shell scripts.
- This tool is crucial for developers aiming to improve the quality and reliability of their shell scripting.
Links mentioned:
- Minutes-scale Schr{ö}dinger-cat state of spin-5/2 atoms: Quantum metrology with nonclassical states offers a promising route to improved precision in physical measurements. The quantum effects of Schr{ö}dinger-cat superpositions or entanglements allow measu...
- Audio to Stems to MIDI Converter - a Hugging Face Space by eyov: no description found
- Room Cleaner V2 - a Hugging Face Space by Hedro: no description found
- New memory chip controlled by light and magnets could one day make AI computing less power-hungry: A new type of ultrafast memory uses optical signals and magnets to efficiently process and store data.
- Tweet from Alexander Doria (@Dorialexander): Happy to announce that @pleiasfr is joining @thealliance_ai to Co-lead the Open Trusted Data Initiative. We will release on November 11th the largest multilingual fully open dataset for LLM training w...
- @aaditya on Hugging Face: "Last Week in Medical AI: Top Research Papers/Models 🔥 🏅 (October 26 -…": no description found
- Tweet from Open Life Science AI (@OpenlifesciAI): Last Week in Medical AI: Top Research Papers/Models 🏅 (October 26 - November 2, 2024) 🏅 Medical AI Paper of the Week: MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making by Aut...
- GitHub - koalaman/shellcheck: ShellCheck, a static analysis tool for shell scripts: ShellCheck, a static analysis tool for shell scripts - koalaman/shellcheck
HuggingFace ▷ #i-made-this (31 messages🔥):
AI-Generated CoursesHuberman Answers BotPubMed ScraperNew VividNode ReleaseROS2 Docker Environment
-
Engaging AI-Crafted Courses Released: A new platform offers AI-generated courses and quizzes designed for modern learners, emphasizing interactivity and readability.
- These courses aim to provide powerful educational experiences tailored to current trends in learning.
- Huberman Answers Bot for Rapid Info: The Huberman Answers project allows users to quickly find answers to health and neuroscience queries sourced from the HubermanLab Podcast.
- This application uses a RAG-GPT system, making it easy to obtain insights directly from Dr. Andrew Huberman's discussions.
- Bot Scrapes PubMed for Research Papers: A PubMed scraper bot has been created to facilitate searching interesting biomedical publications based on titles or keywords.
- This tool enhances the research experience by providing easy access to relevant papers with the potential for upcoming AI summarization features.
- VividNode v1.6.0 Enhancements: The VividNode v1.6.0 update introduces support for edge-tts, and modifications for improved image generation from GPT4Free.
- The latest version also includes solutions to prompt engineering issues and enhances toolbar design for better usability.
- New ROS2 Development Environment Released: A new repository offers a containerized dev environment for ROS2 development compatible with both x86-64 Ubuntu and Apple Silicon macOS.
- This setup simplifies robotics development and simulation, making it accessible for developers using Docker and VSCode.
Links mentioned:
- minchyeom/birthday-llm · Hugging Face: no description found
- Unexex: Engaging AI-crafted courses for modern learners.
- Audio to Stems to MIDI Converter - a Hugging Face Space by eyov: no description found
- blog – Shwetank Kumar: no description found
- ClovenDoug/150k_keyphrases_labelled · Datasets at Hugging Face: no description found
- Release v1.6.0 · yjg30737/pyqt-openai: What's Changed Support edge-tts (free tts) - Video Preview gpt4free - Change the way to get image generation models Add provider column to image table Fix errors related to prompt engineering Fix...
- Using Llama to generate zero-fail JSON & structured text with constrained token generation: Tired of LLMs spitting out invalid JSON? Learn how to make ANY language model generate perfectly structured output EVERY time using constrained token generat...
- Streamlit Supabase Auth Ui - a Hugging Face Space by as-cle-bert: no description found
- GitHub - NinoRisteski/HubermanAnswers: Ask Dr. Andrew Huberman questions and receive answers directly from his podcast episodes.: Ask Dr. Andrew Huberman questions and receive answers directly from his podcast episodes. - NinoRisteski/HubermanAnswers
- Leading the Way for Organic Transparency in Search: Marie Seshat Landry's Vision for organicCertification in Schema.org: no description found
- GitHub - Heblin2003/Lip-Reading: lip-reading system that combines computer vision and natural language processing (NLP): lip-reading system that combines computer vision and natural language processing (NLP) - Heblin2003/Lip-Reading
- GitHub - Dartvauder/NeuroSandboxWebUI: (Windows/Linux) Local WebUI with neural network models (Text, Image, Video, 3D, Audio) on python (Gradio interface). Translated on 3 languages: (Windows/Linux) Local WebUI with neural network models (Text, Image, Video, 3D, Audio) on python (Gradio interface). Translated on 3 languages - Dartvauder/NeuroSandboxWebUI
- GitHub - carpit680/ros2_docker_env: Docker container for Unix-based platforms for ROS2: Docker container for Unix-based platforms for ROS2 - carpit680/ros2_docker_env
- Open-Source LLM SEO Metadata Generator: no description found
- GitHub - Arvind644/smartMeta: Contribute to Arvind644/smartMeta development by creating an account on GitHub.
- BioMedicalPapersBot - a Hugging Face Space by as-cle-bert: no description found
- GitHub - AstraBert/BioMedicalPapersBot: A Telegram bot to retrieve PubMed papers' title, doi, authors and publication date based on general search terms or on specific publication names: A Telegram bot to retrieve PubMed papers' title, doi, authors and publication date based on general search terms or on specific publication names - AstraBert/BioMedicalPapersBot
HuggingFace ▷ #reading-group (11 messages🔥):
Automated Penetration Testing BenchmarkRecording Paper Reading SessionsStructure of Paper Reading SessionsNew Member Orientation
-
Introducing a New Automated Penetration Testing Benchmark: A new paper highlights the lack of a comprehensive, open, end-to-end automated penetration testing benchmark for large language models (LLMs) in cybersecurity, presenting a novel solution to this gap. Notably, the study found Llama 3.1 outperformed GPT-4o using the PentestGPT tool, highlighting areas for further development.
- The findings suggest both models currently lack capabilities in key areas of penetration testing.
- Recording Discussions for Future Reference: Participants expressed interest in recordings of the paper discussions, especially for those who could not attend. One member indicated they would try to record their presentation for those who missed it.
- Another member requested to share recordings due to an impending exam.
- Structure of the Paper Reading Sessions: Meetings typically take place on Saturday, where any member can present a paper during a 1-hour session in a dedicated voice channel. This open format allows for diverse topics and discussions on various papers.
- The structure encourages active participation and accessibility for all members.
- Orientation for New Members: A new member inquired about rules or a FAQ section for the reading group to familiarize themselves before posting. This highlights the importance of guidelines for integrating newcomers into the group.
Link mentioned: Towards Automated Penetration Testing: Introducing LLM Benchmark, Analysis, and Improvements: Hacking poses a significant threat to cybersecurity, inflicting billions of dollars in damages annually. To mitigate these risks, ethical hacking, or penetration testing, is employed to identify vulne...
HuggingFace ▷ #computer-vision (1 messages):
MAE finetuningDeprecation issues
-
Inquiry about MAE Finetuning Challenges: A member raised a question regarding finetuning MAE, specifically mentioning deprecation issues encountered during the process.
- They expressed hope that someone had found a solution to these issues and could share their experiences.
- Request for Solutions to Deprecation Issues: Another member joined the discussion highlighting the deprecation issues linked to MAE finetuning and asked if anyone had managed to resolve them.
- The conversation emphasizes the importance of community insights on addressing these technical hurdles.
HuggingFace ▷ #NLP (3 messages):
Reading ResourcesPaper Reading Methods
-
Valuable Reading Resources Shared: A member shared various courses' resources, including slides partly in German and primarily in English, alongside a source PDF.
- Additional links included Harvard's reading paper and Toronto's role-playing seminars, aimed at improving paper reading strategies.
- Embracing German Language Materials: One member expressed enthusiasm for the shared German resources, stating that they find German beneficial for understanding the material.
- German is good for me as well was noted as a positive remark on the multilingual resources provided.
- Applying Shared Methods to Personal Approaches: Another member thanked for the specific methods shared, viewing them as useful for developing their own paper reading approach.
- I’ll use the resources you provided to develop my own approach to reading papers emphasizes the intent to adapt and customize the shared knowledge.
HuggingFace ▷ #diffusion-discussions (2 messages):
Text EmbeddingsSana PerformanceLLMs Comparison
-
Boosting Diffusion Model Performance: A member suggested that using richly annotated text from recent LLMs to create better text embeddings could significantly improve diffusion model performance.
- They asked for pointers on papers in this area, indicating a growing interest in optimizing embeddings.
- Sana vs T5xxl Performance: Another member mentioned that while using richly annotated text does not vastly enhance performance, it can lead to improvements with reduced VRAM usage.
- They noted that Gemma 2B outperforms T5xxl on certain tasks while being faster and utilizing less resource, referencing the Sana paper.
- Li-Dit and Text Encoder Comparisons: A discussion arose about Li-Dit, which uses Llama3 and Qwen1.5 as text encoders, suggesting it's not entirely fair to compare it to T5xxl due to the size differences in the text encoders.
- A link to the Li-Dit paper was shared for further context on this comparison.
Unsloth AI (Daniel Han) ▷ #general (742 messages🔥🔥🔥):
Unsloth AI Model Fine-tuningPython Performance ImprovementsModel Quantization and InferenceWeb Development Frameworks for LLMGit Practices and Requirements Management
-
Unsloth AI Model Fine-tuning Techniques: Users discussed the challenges and successes in fine-tuning models like Mistral and Llama, with a focus on dataset size and quality for effective training.
- Guidance was offered on training strategies, such as using smaller models to iteratively refine performance before scaling.
- Python 3.11 Performance Gains: Upgrading to Python 3.11 can yield a performance boost, especially in speed across various operating systems, due to improvements like static memory allocation and inlined function calls.
- Users highlighted concerns about package compatibility with Python upgrades, noting the complexities involved with maintaining software stability.
- Model Quantization for Efficient Inference: Discussion included the feasibility of fine-tuning quantized models like Qwen 2.5 72b, emphasizing the need for less memory while achieving satisfactory inference speeds on CPUs.
- It was noted that while quantization facilitates lightweight deployment, initial training still necessitates significant computational resources.
- Web Development Frameworks for LLM Integration: Recommendations were made for web frameworks suitable for integrating language models, focusing on options like React and Svelte for frontend development.
- Flask was suggested for users more comfortable with Python-based solutions aiming to build model interfaces.
- Git Practices and Project Management: A discussion on git practices led to the realization of the absence of a .gitignore file in the Unsloth repository, highlighting the importance of managing files before pushing changes.
- Users shared insights on maintaining clean git histories through effective usage of git commands and local exclusions.
Links mentioned:
- Google Colab: no description found
- Google Colab): no description found
- unsloth/SmolLM2-360M-bnb-4bit · Hugging Face: no description found
- Installation: no description found
- Gandalf A Wizard Is Never Later GIF - Gandalf A Wizard Is Never Later - Discover & Share GIFs: Click to view the GIF
- Tweet from Daniel Han (@danielhanchen): If you're still on Python 3.10, switch to 3.11! Linux machines with 3.11 are ~1.25x faster. Mac 1.2x faster. Windows 1.12x faster. Python 3.12 looks like a perf fix for Windows 32bit (who uses 32...
- Google Colab: no description found
- Finetuning from Last Checkpoint | Unsloth Documentation: Checkpointing allows you to save your finetuning progress so you can pause it and then continue.
- Setting the
dataset_num_proc>1process onDPOTrainerseems to block. · Issue #1964 · huggingface/trl: When I set up just the dataset_num_proc=2 process in DPOTrainer, it seemed to completely pause the step of initializing the trainer map dataset, even though my dataset only had two data points and ... - CLI now handles user input strings for dtype correctly by Rabbidon · Pull Request #1235 · unslothai/unsloth: no description found
- unsloth/unsloth-cli.py at main · unslothai/unsloth: Finetune Llama 3.2, Mistral, Phi, Qwen & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - unslothai/unsloth: Finetune Llama 3.2, Mistral, Phi, Qwen & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3.2, Mistral, Phi, Qwen & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #off-topic (5 messages):
Unsloth projectProduct Hunt discussions
-
Unsloth enables faster finetuning: The Unsloth project is a finetuning initiative that allows users to finetune models via LoRA nearly 2x faster than traditional methods, while consuming less VRAM.
- A user pointed out that this information is available in the project documentation.
- Community finds value in Contri Buzz: A member shared a link to Contri Buzz on Product Hunt, indicating interest in the new launch.
- Another member expressed enthusiasm for the project, stating, Wow cool project. Love it!
Link mentioned: Contri.buzz - Celebrate your open source contributors | Product Hunt: Showcase a visually appealing Contributors' wall in your GitHub README.md / Website / App
Unsloth AI (Daniel Han) ▷ #help (182 messages🔥🔥):
Fine-tuning strategiesModel performance issuesPrompt formatsDataset formattingInference behavior
-
Navigating Fine-tuning Challenges: Users encountered issues with fine-tuning their models, particularly with loss values and prompting formats affecting inference quality.
- Special attention was given to EOS tokens and their implications on stopping generation appropriately.
- The Significance of Prompt Formats: Various discussions highlighted the importance of using appropriate prompt formats when fine-tuning models, including the Alpaca prompt.
- Poor responses from the model were often attributed to incorrect formatting or missing tokens during data preparation.
- Dataset Quality and Training Performance: Users reported mixed results in training outcomes due to dataset quality, with issues like hallucinations and infinite loops occurring frequently.
- Improving dataset and prompt design were suggested as necessary steps for enhancing model accuracy.
- Adjusting Training Parameters: Conversations included adjustments to training parameters, such as changing
max_stepsand usingnum_train_epochs, to optimize model training.
- It was noted that ensuring the correct number of epochs directly influences the ability of the model to provide coherent responses.
- Clarification of Instructions in Datasets: Questions arose concerning the necessity of multiple instructions in training datasets for clarity and effectiveness in queries.
- Discussions emphasized the flexibility in prompt usage based on the specific datasets being utilized.
Links mentioned:
- Google Colab,): no description found
- Google Colab: no description found
- VortexKnight7/YouTube_Transcript_Sum · Datasets at Hugging Face: no description found
- KTO Trainer: no description found
- push bnb 4 bit models on the hub: push bnb 4 bit models on the hub. GitHub Gist: instantly share code, notes, and snippets.
- Issues · huggingface/trl): Train transformer language models with reinforcement learning. - Issues · huggingface/trl
- Difference in behavior between fast tokenizers and normal tokenizers regarding unicode characters in strings · Issue #1011 · huggingface/tokenizers): Hello, we recently switched from Python based tokenizers to the newer fast tokenizers and noticed some of our code breaking when the inputs contain unicode (emojis etc) characters, which wasn't an...
Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
theyruinedelise: Just saw this congrats <:catok:1238495845549346927>
Unsloth AI (Daniel Han) ▷ #community-collaboration (2 messages):
Callback for mtbenchDecision on implementationHugging Face evaluate metrics
-
Uncertainty about Implementation Decision: A member expressed uncertainty about whether they should create a specific implementation, stating 'looks good - we're not sure if we should make one.'
- Decision-making on the implementation remains open-ended with no firm conclusions yet.
- Seeking Reference for mtbench Callback: Another member asked for a reference implementation for a callback to run mtbench evaluations on the mtbench dataset.
- They specifically inquired if anyone had a Hugging Face evaluate metric implementation to share.
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Claude 3.5 HaikuFree Llama 3.2PDF functionalityIncreased Credit Limit
-
Claude 3.5 Haiku launched: Anthropic has released its latest and fastest model, Claude 3.5 Haiku, in standard, self-moderated, and a dated variant for convenience. Check the official releases at Claude 3.5 Overview.
- The model's variants include links for users to access updates: standard, dated, and beta releases.
- Free access to Llama 3.2 models: The powerful open-source Llama 3.2 models now have a free endpoint available, with 11B and 90B variants offering enhanced speed. Users can access the models at 11B variant and 90B variant.
- The 11B variant boasts a performance of 900 tps while the 90B variant shows an impressive 280 tps.
- New PDF capabilities in chatroom: The chatroom now supports direct PDF analysis through attachment or pasting, expanding the utility for users utilizing OpenRouter models. This feature enhances the interaction and versatility of model usage.
- Members can now seamlessly analyze PDFs in their communications, enhancing the collaborative capabilities of the chatroom.
- Increased Maximum Credit Purchase: The maximum credit that can be purchased by users has increased to $10,000, providing more flexibility for intensive use of OpenRouter services. This change aims to accommodate larger-scale projects and user needs.
- This update allows users to manage their resources more effectively, ensuring they have sufficient credit for their operations.
Links mentioned:
- Claude 3.5 Haiku - API, Providers, Stats: Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Run Claude 3.5 Haiku with API
- Claude 3.5 Haiku - API, Providers, Stats: Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Run Claude 3.5 Haiku with API
- Claude 3.5 Haiku - API, Providers, Stats: Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Run Claude 3.5 Haiku with API
- Claude 3.5 Haiku - API, Providers, Stats: Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Run Claude 3.5 Haiku with API
- Llama 3.2 90B Vision Instruct - API, Providers, Stats: The Llama 90B Vision model is a top-tier, 90-billion-parameter multimodal model designed for the most challenging visual reasoning and language tasks. It offers unparalleled accuracy in image captioni...
- Llama 3.2 11B Vision Instruct - API, Providers, Stats: Llama 3.2 11B Vision is a multimodal model with 11 billion parameters, designed to handle tasks combining visual and textual data. Run Llama 3.2 11B Vision Instruct with API
OpenRouter (Alex Atallah) ▷ #app-showcase (7 messages):
vnc-lm Discord BotFreebie Alert Chrome ExtensionOpenRouter API integrationScraping and tool calling
-
vnc-lm Discord Bot Adds OpenRouter Support: The developer announced that they added OpenRouter support to their Discord bot vnc-lm, originally built with ollama integration, which now supports multiple APIs.
- Features include creating conversation branches, refining prompts, and easy model switching with a quick setup via
docker compose up --build. You can check it out here. - Chrome Extension Alerts for Free Samples: A member created a Chrome extension called Freebie Alert that notifies users about free samples available on amazon.co.uk while shopping.
- The extension, which interacts with the OpenRouter API, aims to help users save money and try new brands for free, and has been shared in a YouTube video.
- Question on OpenRouter Relation: A user inquired whether the Freebie Alert Chrome extension is related to OpenRouter.
- The developer confirmed that it indeed calls the OpenRouter API for its functionality.
- Concerns Over Scraping Practices: Multiple members discussed scraping activities, notably sharing pictures involving members using OpenRouter keys to gain free AI access.
- This poses concerns over ethical usage and the implications of public access to these keys.
- Features include creating conversation branches, refining prompts, and easy model switching with a quick setup via
Links mentioned:
- GitHub - jake83741/vnc-lm: vnc-lm is a Discord bot with Ollama, OpenRouter, Mistral, Cohere, and Github Models API integration: vnc-lm is a Discord bot with Ollama, OpenRouter, Mistral, Cohere, and Github Models API integration - jake83741/vnc-lm
- Freebie Alert - Chrome Web Store: Alerts for freebies while you're shopping on amazon.co.uk
OpenRouter (Alex Atallah) ▷ #general (663 messages🔥🔥🔥):
Hermes 405b issuesAPI rate limitsPricing changes for HaikuLambda API integrationOpenRouter features
-
Hermes 405b Uncertainty: The free version of Hermes 405b has been experiencing significant issues, with many users facing high latency or errors when trying to access it.
- Despite these problems, some users manage to get responses intermittently, leading to speculation about whether it's an error related to rate limiting or temporary outages.
- API Rate Limits Confusion: Users reported hitting rate limits on various models, with the ChatGPT-4o-latest model having a notably low request limit for organizations.
- There is ongoing confusion regarding the titles of models, particularly the differentiation between GPT-4o and ChatGPT-4o versions on OpenRouter.
- Pricing Changes for Haiku: The pricing for Claude 3.5 Haiku recently increased significantly, raising concerns among users about its future viability as an affordable option.
- Users expressed frustration over the increased cost, especially when compared to other alternatives like Gemini Flash.
- Lambda API and PDF Feature Announcement: OpenRouter introduced a feature that allows users to upload PDFs in the chatroom to analyze using any model, enhancing usability for various applications.
- This update has generated discussions on how the PDF integration works and the potential for future enhancements.
- Integration of New Models: Discussions arose about possible alternatives to Hermes, with mentions of Llama 3.1 Nemotron producing good results for some users.
- There is ongoing interest in integrating other free models while navigating the current limitations of available options.
Links mentioned:
- Chatroom | OpenRouter): LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
- Creating and highlighting code blocks - GitHub Docs: no description found
- Tweet from OpenAI Developers (@OpenAIDevs): Introducing Predicted Outputs—dramatically decrease latency for gpt-4o and gpt-4o-mini by providing a reference string. https://platform.openai.com/docs/guides/latency-optimization#use-predicted-outpu...
- Unveiling Hermes 3: The First Full-Parameter Fine-Tuned Llama 3.1 405B Model is on Lambda’s Cloud: Introducing Hermes 3 in partnership with Nous Research, the first fine-tune of Meta Llama 3.1 405B model. Train, fine-tune or serve Hermes 3 with Lambda
- Apps Using OpenAI: ChatGPT-4o: See apps that are using OpenAI: ChatGPT-4o - Dynamic model continuously updated to the current version of GPT-4o in ChatGPT. Intended for research and evaluation. Note: This model i...
- Tweet from OpenRouter (@OpenRouterAI): PDFs in the Chatroom! You can now paste or attach a PDF on the chatroom to analyze using ANY model on OpenRouter:
- hermes3:8b-llama3.1-q5_K_M: Hermes 3 is the latest version of the flagship Hermes series of LLMs by Nous Research
- Anthropic: Claude 3.5 Sonnet (self-moderated) – Recent Activity: See recent activity and usage statistics for Anthropic: Claude 3.5 Sonnet (self-moderated) - The new Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same So...
- Tweet from Nous Research (@NousResearch): no description found
- Limits | OpenRouter: Set limits on model usage
- Using the Lambda Chat Completions API - Lambda Docs: Using the Lambda Chat Completions API
- Llama 3.2 3B Instruct - API, Providers, Stats: Llama 3.2 3B is a 3-billion-parameter multilingual large language model, optimized for advanced natural language processing tasks like dialogue generation, reasoning, and summarization. Run Llama 3.2 ...
- Grok Beta - API, Providers, Stats: Grok Beta is xAI's experimental language model with state-of-the-art reasoning capabilities, best for complex and multi-step use cases. It is the successor of [Grok 2](https://x. Run Grok Beta w...
- Hermes 3 405B Instruct - API, Providers, Stats: Hermes 3 is a generalist language model with many improvements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coheren...
- Anthropic Status: no description found
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- Call (using import { createOpenRouter } from '@openrouter/ai-sdk-provider';i - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Requests | OpenRouter: Handle incoming and outgoing requests
- GitHub - homebrewltd/ichigo: Llama3.1 learns to Listen: Llama3.1 learns to Listen. Contribute to homebrewltd/ichigo development by creating an account on GitHub.
- OpenRouter Status: OpenRouter Incident History
- LLM Rankings | OpenRouter: Language models ranked and analyzed by usage across apps
- GitHub - OpenRouterTeam/ai-sdk-provider: The OpenRouter provider for the Vercel AI SDK contains support for hundreds of AI models through the OpenRouter chat and completion APIs.: The OpenRouter provider for the Vercel AI SDK contains support for hundreds of AI models through the OpenRouter chat and completion APIs. - OpenRouterTeam/ai-sdk-provider
- worldsim: no description found
OpenRouter (Alex Atallah) ▷ #beta-feedback (16 messages🔥):
Beta access requestsIntegrations featureCustom provider keys
-
Waves of Requests for Beta Integration Access: Multiple users expressed their desire to gain access to the integrations feature, emphasizing a keen interest in utilizing this capability.
- Messages included persistent requests for beta access, illustrating high demand and enthusiasm among users.
- Excitement for Custom Provider Keys: Several members articulated interest in obtaining access to custom provider keys, hinting at potential projects and feedback for the team.
- One user specifically mentioned developing a script and requested custom provider beta keys to explore this functionality.
LM Studio ▷ #general (166 messages🔥🔥):
LM Studio FeaturesEmbedding ModelsMixed GPU ConfigurationsModel Output StructuringPython for LLM Usage
-
LM Studio's Mixed GPU Support: Users confirmed that mixed use of AMD and Nvidia GPUs in LM Studio is possible, but performance may be limited as Vulkan will be used.
- For optimal performance, it is recommended to utilize identical Nvidia cards instead of mixing.
- Embedding Model Limitations: It was noted that not all models are suitable for embeddings; specifically, Gemma 2 9B was identified as incompatible for this purpose in LM Studio.
- Users were advised to ensure they select proper embedding models to avoid errors.
- Structured Output Challenges: Users are facing difficulties in getting models to strictly adhere to structured output formats, often resulting in unwanted additional text.
- Prompt engineering and possibly utilizing Pydantic classes were suggested as potential solutions to enhance output precision.
- Using Python for LLM Integration: Discussion centered around the feasibility of utilizing code snippets to create custom UIs or functionalities with various language models from Hugging Face.
- Participants noted that multiple models could be employed interchangeably for different tasks, enabling more dynamic LLM applications.
- Running Conversations Between Models: A method was proposed for creating conversations between two models by utilizing different personas that interact with each other.
- Community suggestions indicated that this feature may require additional coding and setup beyond default LM Studio functionalities.
Links mentioned:
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- Imgur: The magic of the Internet: no description found
- Quick and Dirty: Building a Private RAG Conversational Agent with LM Studio, Chroma DB, and…: In an age where time is of the essence and data privacy is paramount (I work in healthcare), here is my attempt to cut through the…
- Tweet from Pliny the Liberator 🐉 (@elder_plinius): 🚨 JAILBREAK ALERT 🚨 OPENAI: PWNED ✌️😜 O1: LIBERATED ⛓️💥 Did not expect this today—full o1 was accessible for a brief window! At time of writing it's not working for me anymore, but when set...
- MobileLLM - a facebook Collection: no description found
- no title found: no description found
- Reddit - Dive into anything: no description found
- llama : switch KQ multiplication to use F32 precision by default by ggerganov · Pull Request #10015 · ggerganov/llama.cpp: ref #10005, #9991 (comment) The list of models that require higher floating point range in the attention keeps growing, so to be on the safe side, default to F32 for the KQ multiplication.
- Run LM Studio as a service (headless) - Advanced | LM Studio Docs: GUI-less operation of LM Studio: run in the background, start on machine login, and load models on demand
- Maxime Labonne - Create Mixtures of Experts with MergeKit: Combine multiple experts into a single frankenMoE
- Buy AMD Ryzen 7 4700S Octa Core Desktop Kit Online - Micro Center India: Get the Best Price on AMD Ryzen 7 4700S Octa Core Desktop Kit in India from Micro Center India. Enjoy Free Shipping and Shop Online with Confidence. Check Reviews and Ratings Today
- NVIDIA RTX 2000E Ada Generation | Professional GPU | pny.com: no description found
LM Studio ▷ #hardware-discussion (396 messages🔥🔥):
LM Studio PerformanceHardware Recommendations for LLMsContext Management in LLM InferenceHigh-Performance Computing with AMD CPUsSystem Monitoring Tools for Hardware Performance
-
LM Studio Performance on Different Hardware Configurations: Users discussed varying performance metrics while running LLMs using LM Studio on different hardware configurations, with some noting excessive time to first token with certain models.
- For instance, one user experienced initial token delays of several minutes, raising concerns about context management and hardware limitations.
- Best Hardware for Running Small LLMs: The conversation touched on suitable hardware for running small LLM models, with various users suggesting configurations that balance cost with performance like the M4 Pro chip and its memory bandwidth.
- Participants noted that while 16GB RAM might suffice for basic tasks, higher models and quantities of RAM would provide better long-term viability.
- Challenges in Context Handling for LLMs: Issues around context length and management were highlighted, particularly with loading old chats, which could lead to significant lag during inference.
- Users theorized that context truncation may exacerbate delays, especially when running models with straightforward requirements.
- Using AMD CPUs for High-Performance Inference: Discussion included insights into using AMD Threadripper CPUs for inference speed, detailing how core counts may impact performance up to a point before plateauing.
- Users shared experiences with their own systems, comparing performance metrics and discussing necessary configurations to maximize LLM inference efficiency.
- Monitoring Tools for System Performance Analysis: Users recommended various tools for monitoring system performance while running LLMs, including HWINFO64 for logging and visualizing data.
- HWMonitor was also mentioned, although it was indicated that a more integrated monitoring solution might be beneficial for real-time analysis.
Links mentioned:
- Log Visualizer: no description found
- Apache License 2.0 (Apache-2.0) Explained in Plain English - TLDRLegal: Apache License 2.0 (Apache-2.0) summarized/explained in plain English.
- Apple introduces M4 Pro and M4 Max: Apple announces M4 Pro and M4 Max, two new chips that — along with M4 — bring more power-efficient performance and advanced capabilities to the Mac.
- Doja Cat GIF - Doja Cat Star - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- GitHub - openlit/openlit: OpenLIT: Complete Observability and Evals for the Entire GenAI Stack, from LLMs to GPUs. Improve your LLM apps from playground to production 📈. Supports 20+ monitoring integrations like OpenAI & LangChain. Collect and Send GPU performance, costs, tokens, user activity, LLM traces and metrics to any OpenTelemetry endpoint in just one line of code.: OpenLIT: Complete Observability and Evals for the Entire GenAI Stack, from LLMs to GPUs. Improve your LLM apps from playground to production 📈. Supports 20+ monitoring integrations like OpenAI &a...
Nous Research AI ▷ #general (438 messages🔥🔥🔥):
Hermes 405b Model PerformanceData Sources for Hermes ModelsLambda API IssuesFuture of Nous Research ModelsHyperparameter Optimization for Smaller Models
-
Hermes 405b Model Performance: Users reported slow response times and intermittent errors when using the Hermes 405b model via Lambda and OpenRouter, with some suggesting it felt 'glacial' in performance.
- The free API on Lambda especially showed inconsistent availability, causing frustration among users trying to access the model.
- Data Sources for Hermes Models: It was discussed that the datasets used to train Hermes 405b might not be publicly available, though some datasets related to Open Hermes are accessible via Hugging Face.
- Users expressed interest in understanding the raw datasets and tuning processes that underlie the model's training.
- Lambda API Issues: The Lambda API for the Hermes 405b model was frequently down or failed on requests, particularly noted between midnight and 3 AM.
- Some users suggested that the reliability of the Lambda API for accessing Hermes needs improvement.
- Future of Nous Research Models: Teknium stated that Nous Research will not create any closed-source models, but some other offerings may remain private or contract-based for certain use cases.
- The Hermes series will always remain open source, ensuring transparency in its development.
- Hyperparameter Optimization for Smaller Models: Discussion revolved around the optimal approach for training smaller models using datasets from Hermes, with suggestions to conduct hyperparameter optimization on the full dataset rather than subsampling.
- Lower learning rates and more training steps were suggested for fine-tuning smaller models to achieve better performance.
Links mentioned:
- Introduction - Ordinal Theory Handbook: no description found
- The Network State: How to Start a New Country: This book explains how to build the successor to the nation state, a concept we call the network state.
- Digital Matter Theory | Digital Matter Theory: A new era of digital substance
- W3Schools.com: W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
- It Was The Aliens Im Not Saying It Was Aliens GIF - It was the aliens Im not saying it was aliens Ancient aliens - Discover & Share GIFs: Click to view the GIF
- Tweet from Chubby♨️ (@kimmonismus): Hertz-dev: an open-source, first-of-its-kind base model for full-duplex conversational audio. It's an 8.5B parameter transformer trained on 20 million unique hours of high-quality audio data. it i...
- NousResearch (NousResearch): no description found
- teknium (Teknium): no description found
- recursive_library/README.md at main · cypherpunklab/recursive_library: Contribute to cypherpunklab/recursive_library development by creating an account on GitHub.
- Self Healing Code – D-Squared: no description found
- teknium/OpenHermes-2.5 · Datasets at Hugging Face: no description found
Nous Research AI ▷ #ask-about-llms (22 messages🔥):
Jailbreaking LLMsAI Search Engine PerformanceAI Energy Usage and Hardware Inefficiency
-
Diverse Perspectives on Jailbreaking LLMs: A member questioned whether jailbreaking LLMs is more about creating constraints to free them, sparking a lively discussion about the motivations and implications of such practices.
- One participant highlighted that many adept at jailbreaking might not fully understand LLM mechanics beneath the surface.
- Frustrations with AI Search Engine Results: Users lamented that OpenAI's new search isn't delivering real-time results, especially in comparison to platforms like Bing and Google.
- One noted that Perplexity excels in search result quality and could be seen as superior to both Bing and OpenAI's offerings.
- Resources on AI Energy Consumption: A member sought resources about energy use and inefficiency in AI, highlighting it as a point of contention among critics of AI technology.
- Relevant resources shared included a research paper on the environmental cost of generative AI and a YouTube video discussing AI's energy needs.
Links mentioned:
- Power Hungry Processing: Watts Driving the Cost of AI Deployment?: Recent years have seen a surge in the popularity of commercial AI products based on generative, multi-purpose AI systems promising a unified approach to building machine learning (ML) models into tech...
- How much energy AI really needs. And why that's not its main problem.: Learn more about Neural Nets on Brilliant! First 30 days are free and 20% off the annual premium subscription when you use our link ➜ https://brilliant.org/...
Nous Research AI ▷ #research-papers (2 messages):
MDAgentsMatchmakerUltraMedicalAI in Healthcare EthicsClinical Evidence Synthesis
-
MDAgents leads in Medical Decision-Making: Google introduced MDAgents, showcasing an Adaptive Collaboration of LLMs aimed at enhancing medical decision-making.
- This week's podcast summarizing the paper emphasizes the importance of collaboration among models in tackling complex healthcare challenges.
- Diverse Medical LLMs are on the rise: Several models were highlighted, including Matchmaker for schema matching and UltraMedical, designed for specialized biomedical needs.
- Models like ZALM3 facilitate vision-language medical dialogue, underscoring the rapid evolution of capabilities.
- Innovative Frameworks for Medical AI: Noteworthy methodologies such as FEDKIM for federated medical knowledge and Flex-MoE for flexible modality combinations are gaining traction.
- These frameworks aim to improve the adaptability of medical AI solutions in diverse clinical environments.
- Multi-Modal Applications show promise: Applications like DiaMond for dementia diagnosis and LLM-Forest for health data imputation demonstrate the breadth of potential LLM applications.
- The emergence of Clinical Evidence Synthesis using LLMs highlights their utility in synthesizing clinical insights efficiently.
- Ethical AI in Healthcare is essential: The discussion around AI ethics emphasizes the role of LLMs in medical education and the generation of medical exam questions.
- Integrating clinical knowledge graphs exemplifies the growing need for ethical considerations in deploying AI technologies in healthcare.
Link mentioned: Tweet from Open Life Science AI (@OpenlifesciAI): Last Week in Medical AI: Top Research Papers/Models 🏅 (October 26 - November 2, 2024) 🏅 Medical AI Paper of the Week: MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making by Aut...
Nous Research AI ▷ #research-papers (2 messages):
MDAgentsMatchmaker ModelFEDKIM FrameworkDiaMond ApplicationAI in Healthcare Ethics
-
Google's MDAgents revolutionize medical decision-making: Google presents MDAgents, an adaptive collaboration of LLMs designed for enhanced medical decision-making, showcased during the week of October 26 - November 2, 2024.
- This model emphasizes collaborative AI approaches in healthcare, offering improved patient care capabilities.
- Matchmaker aligns schemas using LLMs: Matchmaker utilizes LLMs for effective schema matching in biomedical data, enhancing the interoperability of medical records and systems.
- This model aims to streamline the integration of diverse healthcare datasets, fostering better data accessibility.
- FEDKIM introduces federated knowledge injection: The FEDKIM framework focuses on federated medical knowledge injection, allowing for data privacy while still benefiting from collaborative learning.
- This innovative approach facilitates knowledge sharing across institutions without compromising patient data security.
- DiaMond tackles multi-modal dementia diagnosis: DiaMond application leverages multi-modal inputs for comprehensive dementia diagnosis, integrating various data types for accurate assessments.
- It highlights how advanced LLM applications can significantly enhance diagnostic capabilities in this field.
- AI ethics in healthcare comes under the lens: Recent discussions focus on AI in Healthcare Ethics, particularly the role of LLMs in medical education and clinical decision support.
- These deliberations include considerations around medical exam question generation and the ethical implications of AI integration in clinical settings.
Link mentioned: Tweet from Open Life Science AI (@OpenlifesciAI): Last Week in Medical AI: Top Research Papers/Models 🏅 (October 26 - November 2, 2024) 🏅 Medical AI Paper of the Week: MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making by Aut...
Perplexity AI ▷ #general (329 messages🔥🔥):
Perplexity AI ModelsClaude 3.5 HaikuModel SwitchingNew Subscription PricingUser Experience with Perplexity
-
Perplexity AI Models in Use: Users reported switching between different AI models, such as Claude, Grok, and Sonar, to achieve varying results. Many find each model better suited for specific tasks like coding or conversation.
- The use of Spaces allows some users to set a model tailored to focus areas, although the ability to switch models quickly is still desired by many.
- Introduction of Claude 3.5 Haiku: A new model, Claude 3.5 Haiku, was announced as available on several platforms but faces increased pricing concerns from its user base. Many users express disappointment at price hikes in AI models as they seek affordable options.
- Some users highlight that Claude maintains good conversational skills despite increasing costs, while others doubt its value when compared with their existing tools.
- Concerns Over Perplexity's Subscription Model: Concerns were raised about the subscription pricing of Perplexity and its perceived value in relation to free versions. Users noted that they find it frustrating when the service feels less effective than expected, particularly regarding model behavior and source reliability.
- Discussions included how AI models, despite being paid, can sometimes provide inaccurate sourcing when matched with queries.
- User Experience with Perplexity: General user sentiment towards Perplexity is mixed, with some expressing dissatisfaction with the software's current capabilities and others finding exceptional use cases. Users often question the efficacy of switching models or the relevance of sources provided within the responses.
- Some users report feeling that Perplexity could significantly improve if it integrated better model switching directly into the main interface rather than requiring navigation through settings.
- Support for Workers' Rights: Discussions included solidarity with workers striking for fair wages, reflecting broader sentiments against corporate practices that suppress employee rights. Users expressed disappointment over management tactics aimed at undermining union efforts for wage improvements.
- The importance of supporting workers' struggles for fair compensation resonated among several members involved in the conversation.
Links mentioned:
- Tweet from Anthropic (@AnthropicAI): Claude 3 Haiku remains available for use cases that benefit from image input or its lower price point. https://docs.anthropic.com/en/docs/about-claude/models#model-names
- Tweet from Alex Albert (@alexalbert__): Claude 3.5 Haiku is now available on the Anthropic API, Amazon Bedrock, and Google Cloud's Vertex AI. Claude 3.5 Haiku is our fastest and most intelligent cost-efficient model to date. Here's...
- Tweet from Phi Hoang (@apostraphi): every second counts.
- Self Healing Code – D-Squared: no description found
- Rolls Royce Royce GIF - Rolls royce Rolls Royce - Discover & Share GIFs: Click to view the GIF
- Perplexity Supply: Where curiosity meets quality. Our premium collection features thoughtfully designed apparel for the the curious. From heavyweight cotton essentials to embroidered pieces, each item reflects our dedic...
- Perplexity & Claude 3.5 Sonnet: 2 new items added to shared album
Perplexity AI ▷ #sharing (26 messages🔥):
AI that can smellSearchGPTChinese Military's Llama AI ModelAffordable cars in IndiaPacking tips
-
AI that Can Smell Brings New Senses: A detailed article discusses an AI for digital scents that can replicate the sense of smell, potentially transforming sensory experiences.
- This could lead to innovative applications in fields like virtual reality and culinary experiences.
- OpenAI Challenges Google with SearchGPT: The introduction of SearchGPT offers users an array of new search functionalities aimed at rivaling traditional search engines.
- This has sparked discussions about the future of information retrieval and AI's role in search capabilities.
- Chinese Military Develops Llama-based AI: An article reveals that the Chinese military is building a Llama-based AI model, marking a significant advancement in AI applications.
- This raises considerations about international military tech competition and the implications of AI in warfare.
- India's Unsold Car Glut Offers Deals: A report showcases how India's unsold car stock has led to significantly cheaper prices for vehicles, making them more accessible to consumers.
- The article discusses how the market is responding to this glut and its potential impacts on the automotive industry.
- Essential Packing Tips Shared: A guide on the 5-4-3-2-1 packing method offers practical tips for travelers to simplify the packing process.
- This method encourages efficient packing and reduces the stress of travel preparation.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (7 messages):
Home appliance review analysisCitations feature in the APIDiscord bot developmentSupport contact for API issues
-
Home appliance review analysis inquiries: A user is exploring the possibility of creating a site that analyzes real home appliance reviews from forums like Reddit or Quora using the Perplexity API.
- Another user responded, saying they found no reason why this shouldn't work, suggesting optimism towards the project.
- Questions about citations feature in the API: A member asked whether it's possible to retrieve citation data from the API, specifically regarding sonar online models.
- A follow-up message referenced checking a pinned message for potential replies or information on the citations feature.
- Discord bot development plans: One user plans to develop a Discord bot connected to the API to ensure proper functionality before further development.
- They indicated their proactive approach to mastering the API's capabilities.
- Concerns over citation feature access: A user expressed frustration about not receiving feedback on their request for access to the citations feature, despite filling out an elevated access form weeks ago.
- They also inquired about establishing direct contact with support for more immediate assistance.
Eleuther ▷ #general (15 messages🔥):
Attention MechanismsGenerative AI LearningUnderstanding ODE/SDE for Diffusion Models
-
Challenges in Changing Attention Mechanisms: A member discussed that altering only the last layer's attention in models may not be optimal as attention heads predominantly focus on themselves or nearby strong tokens.
- They further pointed out that the skip connection from the previous layer adds additional context that could undermine the effectiveness of changes made solely in the last layer.
- Exploration of Attention Weights: In a detailed discussion, members considered changing attention weights before the softmax of attention scores to control which tokens are emphasized, despite the risk of these values needing to total 1.
- One participant provided a link to their code for where this injection took place.
- Learning Generative AI Together: A member extended an invitation for anyone interested in learning generative AI from scratch to join them in a collaborative effort.
- This open call suggests a desire for community engagement and shared learning experiences.
- Seeking Resources on Diffusion Models: A member requested recommendations for books, blogs, or papers that clarify the ODE/SDE formulations of diffusion models, particularly as outlined in the EDM paper by Karras.
- They expressed confidence in understanding sliced score matching and latent diffusion but noted a lack of familiarity with SDEs and probability flow ODEs.
- Inquiry on Learning Resources: In response to the inquiry about ODE/SDE resources, a member suggested checking out Yang Song's blog post for valuable insights.
- This recommendation illustrates the collaborative nature of the community in sharing knowledge and learning resources.
Link mentioned: transformers/src/transformers/models/llama/modeling_llama.py at 65753d6065e4d6e79199c923494edbf0d6248fb1 · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
Eleuther ▷ #research (323 messages🔥🔥):
Gradient DualizationMathematical Foundations of MLReading Group FormatsOptimizer ConfigurationsScaling in Neural Networks
-
Exploring Gradient Dualization: A discussion emerged around the concept of gradient dualization, highlighting its potential influence on training deep learning models. Insights were shared about the relationship between norms and the dynamics of model performance as they scale.
- Participants expressed interest in how changes in layer configurations, like alternating between parallel and sequential attention mechanisms, could impact the overall performance of neural architectures.
- Curating a Math Reading Group: A proposal for reviving a math reading group focused on gradient dualization was positively received. The format discussed would include reading papers collectively or encouraging pre-reading to facilitate more engaging and informed discussions.
- Challenges in maintaining consistent participation and the importance of summarizing papers for those who might not be familiar with the material were highlighted.
- Optimizer Parameter Settings: There was an exchange regarding standard parameter settings for optimizers, particularly concerning beta values in Adam variants. The conversation underscored variations in settings experienced by participants and referenced a paper advocating for specific configurations.
- Scaling and Depth in Neural Networks: Participants discussed the trade-off between depth and width in neural network configurations and its impact on performance. Suggestions were made to empirically validate the theory that, as models grow, the dynamics between these parameters become more aligned.
- Community Recognition in Math: Contributors were recognized for their mathematical expertise, mentioning notable figures within the community. Casual comparisons drew attention to the presence of skilled researchers, encouraging a culture of sharing knowledge and support.
Links mentioned:
- Preconditioned Spectral Descent for Deep Learning: no description found
- Quasi-hyperbolic momentum and Adam for deep learning: Momentum-based acceleration of stochastic gradient descent (SGD) is widely used in deep learning. We propose the quasi-hyperbolic momentum algorithm (QHM) as an extremely simple alteration of momentum...
- Scaling Optimal LR Across Token Horizons: State-of-the-art LLMs are powered by scaling -- scaling model size, dataset size and cluster size. It is economically infeasible to extensively tune hyperparameter for the largest runs. Instead, appro...
- Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks: We present weight normalization: a reparameterization of the weight vectors in a neural network that decouples the length of those weight vectors from their direction. By reparameterizing the weights ...
- Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent: A longstanding goal in deep learning research has been to precisely characterize training and generalization. However, the often complex loss landscapes of neural networks have made a theory of learni...
- A Spectral Condition for Feature Learning: The push to train ever larger neural networks has motivated the study of initialization and training at large network width. A key challenge is to scale training so that a network's internal repre...
- Scalable Optimization in the Modular Norm: To improve performance in contemporary deep learning, one is interested in scaling up the neural network in terms of both the number and the size of the layers. When ramping up the width of a single l...
- Stable and low-precision training for large-scale vision-language models: We introduce new methods for 1) accelerating and 2) stabilizing training for large language-vision models. 1) For acceleration, we introduce SwitchBack, a linear layer for int8 quantized training whic...
- Old Optimizer, New Norm: An Anthology: Deep learning optimizers are often motivated through a mix of convex and approximate second-order theory. We select three such methods -- Adam, Shampoo and Prodigy -- and argue that each method can in...
- Straight to Zero: Why Linearly Decaying the Learning Rate to Zero...: LLMs are commonly trained with a learning rate (LR) warmup, followed by cosine decay to 10% of the maximum (10x decay). In a large-scale empirical study, we show that under an optimal max LR, a...
- Simplifying Transformer Blocks: A simple design recipe for deep Transformers is to compose identical building blocks. But standard transformer blocks are far from simple, interweaving attention and MLP sub-blocks with skip connectio...
- How Does Critical Batch Size Scale in Pre-training?: Training large-scale models under given resources requires careful design of parallelism strategies. In particular, the efficiency notion of critical batch size, concerning the compromise between time...
- Tweet from Proxy (@whatisproxy): 🧵 The Proxy Structuring Engine (PSE) Introducing a novel sampling approach for structured outputs in LLMs: the Proxy Structuring Engine. A technical thread for AI/ML engineers, researchers, and the ...
- Repulsive Surfaces: Functionals that penalize bending or stretching of a surface play a key role in geometric and scientific computing, but to date have ignored a very basic requirement: in many situations, surfaces must...
- Oasis: no description found
- Our First Generalist Policy: Physical Intelligence is bringing general-purpose AI into the physical world.
- Condition number - Wikipedia: no description found
- Why is the Frobenius norm of a matrix greater than or equal to the spectral norm?: How can one prove that $ \|A\|2 \le \|A\|_F $ without using $ \|A\|_2^2 := \lambda{\max}(A^TA) $? It makes sense that the $2$-norm would be less than or equal to the Frobenius norm but I do...
- Modular Duality in Deep Learning: An old idea in optimization theory says that since the gradient is a dual vector it may not be subtracted from the weights without first being mapped to the primal space where the weights reside. We t...
- The duality structure gradient descent algorithm: analysis and applications to neural networks: The training of machine learning models is typically carried out using some form of gradient descent, often with great success. However, non-asymptotic analyses of first-order optimization algorithms ...
Eleuther ▷ #scaling-laws (2 messages):
Adafactor Schedule ChangesHyperparameter Tuning Insights
-
Adafactor beta schedules analyzed: A member noted that changes to the Adafactor schedule are reminiscent of simply adding another hyperparameter, pointing out that a beta2 schedule from 2018 and a cycle LR from 2017 were hardly groundbreaking.
- They emphasized that such changes are only significant when they are guided by theoretical insights or actual results, suggesting minimal improvement from optimal configurations.
- Questioning the value of hyperparameter expansions: The discussion shifted to the value of expanding hyperparameters, with one participant indicating that the theoretically optimal beta2 schedule did not yield better training loss than simply tuning a fixed beta2.
- They observed that this optimal schedule closely resembled Adafactor's existing beta2 schedule, casting doubt on the innovation of these adjustments.
Eleuther ▷ #interpretability-general (1 messages):
w2s Model FilesGitHub Repository
-
Inquiry about w2s Model Files: A user inquired whether the model files for the w2s project are stored somewhere accessible.
- This question highlights the community's ongoing interest in resources related to the w2s development.
- GitHub Repository Overview: The w2s project can be found on GitHub - EleutherAI/w2s, where contributors can create accounts to assist in development.
- The GitHub page serves as a hub for collective contributions towards the w2s initiative.
Link mentioned: GitHub - EleutherAI/w2s: Contribute to EleutherAI/w2s development by creating an account on GitHub.
Eleuther ▷ #lm-thunderdome (8 messages🔥):
GPT-NeoX ExperimentationEvaluating Tasks with HarnessModifying Evaluation Metrics
-
Best Practices for GPT-NeoX Configurations: Users are exploring configurations for GPT-NeoX and considering using Hypster for configurations alongside MLFlow for tracking experiments.
- One member asked if a setup involving DagsHub, MLFlow, and Hydra is common, seeking suggestions from the community.
- Controlling Evaluation Attempts with
pass@k: A member inquired about controlling the number of attempts (k) in tasks like GSM8K when using the harness, prompting a response that using repeats in the task template can achieve this.
- An example of using repeats was referenced to clarify this feature in the evaluation harness.
- Response Checking Methodology: There was a discussion about whether the harness automatically checks all k responses against the correct answer and returns correct if any are right.
- It was clarified that the mechanism involves a majority vote, with a reference link provided for the relevant code.
- Modifying Evaluation Metrics: A suggestion was made to modify the evaluation mechanism to check for the correct response directly and switch the downstream metric from exact_match to acc.
- This aims to enhance reliability in evaluating model responses during tests.
Link mentioned: lm-evaluation-harness/lm_eval/filters/selection.py at c0745fec3062328e0ab618f36334848cdf29900e · EleutherAI/lm-evaluation-harness): A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #multimodal-general (11 messages🔥):
DINO's ImageNet PretrainingJordan's Anime Art Thoughts
-
DINO: Distillation and Eval Metrics Boost: Members discussed that DINO's ImageNet pretraining might improve evaluation metrics, with v2 using 22k data instead of 1k.
- The DINOv2 paper demonstrated better performance on 1k using the 22k dataset, indicating effective distillation.
- Jordan's Anime Art Thread Creation: A member pointed out that Jordan created a thread titled '[Jordans anime art thoughts]'.
- The discussion around Jordan's thoughts on anime art garnered interest, with feedback described as 'awesome'.
Eleuther ▷ #gpt-neox-dev (1 messages):
GPT-NeoX DemoColab Notebooks
-
Demo of GPT-NeoX on Colab: A member developed a small demo of GPT-NeoX that can be run on a Colab notebook to facilitate learning about the model.
- They requested a review of the notebook to ensure it serves as a 'good' example for others.
- Request for Review of GPT-NeoX Notebook: The demo creator is seeking feedback specifically on the Colab notebook to make certain it meets educational standards.
- This initiative aims to help others learn about GPT-NeoX, making it accessible for newcomers.
Link mentioned: GPT-NeoX-Colab/notebooks/shakespeare_training.ipynb at main · markNZed/GPT-NeoX-Colab: Example Colab notebooks for GPT-NeoX. Contribute to markNZed/GPT-NeoX-Colab development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #announcements (2 messages):
Claude 3.5 Haiku performanceAider v0.62.0 featuresCode editing leaderboardFile edits applicationBugfixes in Aider
-
Claude 3.5 Haiku scores on leaderboard: The new Claude 3.5 Haiku scored 75% on aider's code editing leaderboard, ranking just behind the old Sonnet 06/20.
- With this performance, Haiku stands as a cost-effective alternative close to the capabilities of Sonnet.
- Aider v0.62.0 introduces new features: The latest release of Aider, version 0.62.0, fully supports Claude 3.5 Haiku, allowing users to launch it with
--haiku.
- Aider now facilitates applying edits from various web apps like ChatGPT, enhancing usability for developers.
- New method for applying file edits: Users can now apply file edits from ChatGPT or Claude by using their web apps, copying responses, and running
aider --apply-clipboard-edits file-to-edit.js.
- This process streamlines code editing directly based on LLM-generated changes.
- Aider 0.62.0 bugfixes: The update provided a bugfix addressing issues related to creating new files.
- This enhancement improves the overall stability and usability of Aider for developers.
- Aider development and contribution: Remarkably, Aider wrote 84% of the code in this release, showcasing its self-improvement capabilities.
- This level of contribution indicates ongoing advancements in Aider's functionality and autonomy.
Link mentioned: Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
aider (Paul Gauthier) ▷ #general (240 messages🔥🔥):
Aider Features and UpdatesAI Model ComparisonsBenchmark PerformanceToken Usage and ManagementCommand Line Instructions
-
New Aider Feature: Clipboard Edits: Aider has introduced a new
--apply-clipboard-editsfeature allowing users to copy code responses from web LLM UIs and apply them to local files seamlessly.- This update enhances the editing efficiency and aligns with the recent release of Haiku 3.5.
- Model Comparison Insights: The community discussed various AI models’ performance, with Sonnet 3.5 being highlighted for its quality, while Haiku 3.5 is seen as a strong competitor but slower.
- Participants compared the coding abilities of different models and shared experiences using them in real projects.
- Benchmark Performance Revealed: Paul G shared benchmark results showing Sonnet 3.5 outperforming other models, while Haiku 3.5 was ranked lower in efficiency.
- There's interest in how different model combinations, like Sonnet and Haiku, perform in various tasks.
- Managing Token Limits Effectively: Users expressed concerns about reaching token limits on large projects, discussing strategies to manage this by limiting context and reducing unnecessary file edits.
- Community suggestions included running
/tokensto analyze token usage and using/clearto reset chat history. - Command Line Guidance: Various command line instructions were shared for using Aider effectively, including setting up the environment and model specifications.
- Specific commands for utilizing OpenRouter models and ensuring Git functionality within Aider were discussed.
Links mentioned:
- Tweet from OpenAI Developers (@OpenAIDevs): Introducing Predicted Outputs—dramatically decrease latency for gpt-4o and gpt-4o-mini by providing a reference string. https://platform.openai.com/docs/guides/latency-optimization#use-predicted-outpu...
- Installing aider: aider is AI pair programming in your terminal
- Welcome to Retype - Write On! with Retype: Retype is an ✨ ultra-high-performance ✨ static website generator that builds a website based on simple Markdown text files.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- GitHub Codespaces: aider is AI pair programming in your terminal
- Separating code reasoning and editing: An Architect model describes how to solve the coding problem, and an Editor model translates that into file edits. This Architect/Editor approach produces SOTA benchmark results.
- software-dev-prompt-library/prompts/documentation/generate-project-README.md at main · codingthefuturewithai/software-dev-prompt-library: Prompt library containing tested reusable gen AI prompts for common software engineering task - codingthefuturewithai/software-dev-prompt-library
- 0.61.0 bug with creating new files · Issue #2233 · Aider-AI/aider: Reported in discord: https://discord.com/channels/1131200896827654144/1302139944235696148/1302139944235696148 Hi, after yesterday's update to version 0.61, aider has a problem with writing new fil...
- GitHub - Aider-AI/aider: aider is AI pair programming in your terminal: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #questions-and-tips (80 messages🔥🔥):
Prompt Caching in AiderIssues with Aider InstallationConfiguration Management in AiderLLM Token Limit DiscrepanciesUsing Multiple Configuration Files
-
Understanding Aider's Prompt Caching Functionality: A user questioned whether Aider caches prompts when changing files without using /add or /clear commands, highlighting potential concerns over efficiency.
- Discussions indicated that Aider manages prompt caching effectively when configured correctly, especially in .env files.
- Troubleshooting Aider Installation Issues: A user faced issues starting Aider after v61 update, initially getting error messages until reconfiguring .env and .yaml files resolved the problem.
- It was noted that removing certain config files could help fix glitches in Aider functionality when changing between different repositories.
- Configuration Management: Aider's .env vs .aider.conf.yml: Users discussed how --read commands can specify multiple files in command line while clarifying the function of AIDER_FILE lines in .env files.
- It was concluded that Aider can utilize both configuration methods but may prioritize .aider.conf.yml configurations over .env settings.
- Discrepancies in Token Counts with Local LLMs: A user reported a mismatch in token counts while using Aider with a local LLM, causing confusion over calculations during sessions.
- Others contributed information regarding token limits and how Aider manages token input and output, alongside instructions available in documentation.
- Utilizing Multiple Configuration Files in Aider: Discussants explored how to declare multiple files in Aider's configurations, expressing the need for clarity on supporting multiple AIDER_FILE entries.
- Suggestions included using .env and .aider.conf.yml files simultaneously to manage keys and configurations effectively.
Links mentioned:
- Dependency versions: aider is AI pair programming in your terminal
- Prompt caching: Aider supports prompt caching for cost savings and faster coding.
- YAML config file: How to configure aider with a yaml config file.
- Token limits: aider is AI pair programming in your terminal
- aider/aider/website/assets/sample.env at main · Aider-AI/aider): aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #links (4 messages):
OpenAI o1 anticipationIBM Granite coding modelsGranite performance evaluationYouTube discussion
-
OpenAI crafts o1 hype: A user noted that OpenAI's recent leak of o1 appears to be strategically orchestrated to build anticipation for upcoming releases, rather than an accidental slip.
- They highlighted how Sam Altman has previously cultivated interest through repeated imagery, such as sharing a photo of a strawberry and referencing the Orion starry sky.
- User inquiries on IBM Granite models: A member questioned whether anyone has used the IBM Granite coding models, linked to the official documentation.
- They emphasized that these models are designed for code generation tasks across 116 programming languages.
- Historical performance of Granite models: An earlier user commented on the performance of IBM Granite models, stating they were somewhat lacking in the past, but did not provide recent feedback.
- This opens up the question of whether improvements have since impacted their effectiveness in code-related tasks.
- YouTube video reference: A user shared a link to a YouTube video without additional context.
- This could be related to previous discussions on coding models or OpenAI releases, but specifics weren't provided.
Links mentioned:
- Tweet from Chubby♨️ (@kimmonismus): Sneak-peak of o1 In fact, it looks like OpenAI didn't accidentally leak o1 today, but it seems like a well-orchestrated act to create anticipation for what's to come. It's important to r...
- no title found: no description found
OpenAI ▷ #ai-discussions (184 messages🔥🔥):
Potential AGI CapabilitiesDependency on TechnologyAI RelationshipsOpenAI's Future DevelopmentsAI Versus Human Interaction
-
AGI's Potential for Repurposing Technology: There's a discussion on the possibility of AGI repurposing technology for advanced applications, like transforming the ISS into new energy sources or creating self-cleaning buildings.
- This reflects a broader need to consider AGI's future impact, with comments on the importance of open-mindedness towards its proposals.
- Societal Dependency on Technology: A member emphasized that dependency on technology leads to a lack of preparedness for a world without it, cautioning against focusing solely on AI relationships.
- They prompted reflection on how society's reliance on tech influences daily life and could pose risks in emergencies like an EMP.
- Concerns About AI Friendships: There's concern that companies like OpenAI could be cultivating unhealthy attachments to AI, contributing to societal issues stemming from loneliness.
- One member suggested that this dependency on AI could be just as concerning as social media's impact on human relationships.
- Excitement for OpenAI's New Projects: Discussion about OpenAI's upcoming projects, including the Orion project, has members excited for innovations in AI expected by 2025.
- Conversations noted that while advancements are underway, current models like O1 are not yet true AGI.
- New Features in GPT-4o: It was noted that the next version of GPT-4o is rolling out, enabling some users to access advanced reasoning capabilities similar to O1.
- The upgrade includes features like placing large text blocks in a canvas-style box, enhancing usability for reasoning tasks.
Links mentioned:
- Tweet from Jason -- teen/acc (@ArDeved): wait? did i just get access to full o1 wtf???
- Tweet from Doomlaser Corporation (@DOOMLASERCORP): Throwback to 2015: Our CEO @Doomlaser on WEFT 90.1 FM Champaign, IL, discussing AI, Brain-Computer Interfaces, symbolic logic, corporate responsibility, and community service—with a unique vision that...
- Mining lava: What the actual hell does this AI hallucinate
- cha ching...: no description found
- Pause Giant AI Experiments: An Open Letter - Future of Life Institute: We call on all AI labs to immediately pause for at least 6 months the training of AI systems more powerful than GPT-4.
OpenAI ▷ #gpt-4-discussions (14 messages🔥):
Middleware ProductsChannel Naming PreferencesO1 ObservationsGPT-5 AnnouncementDiscord Search Functionality
-
Exploring Middleware Products: A member inquired if anyone uses middleware products that point to different endpoints instead of directly to OpenAI, mentioning they are working on something and questioning its normalcy.
- Is this a typical pattern?
- Debate on Channel Names: CaptainStarbuck questioned the channel name's relevance as it currently doesn't reflect the discussions on models beyond GPT, suggesting the need for dedicated channels like #o1-discussions.
- Another member agreed on the benefit of having specific channels while cautioning against having too many.
- Usage of Discord's Search Feature: When discussing O1 notes, one member mentioned the importance of the Discord search function to keep track of information buried in chat.
- The conversation emphasized that search can help locate past messages across various channels.
- Curiosity About GPT-5 Release: Neomx8 expressed a desire to know when GPT-5 will be announced and when the API will be available, to which another member humorously responded that nobody knows.
- There was a notion that a new release is anticipated for this year, but it will not be GPT-5.
- Concerns About Community Discussions: CaptainStarbuck voiced frustrations over some community members not distinguishing between different models, leading to chaotic discussions about various topics across channels.
- OpenAI could have done much better to arrange discussions in a clearer manner.
OpenAI ▷ #prompt-engineering (63 messages🔥🔥):
Best practices for code documentationTools for writing good promptsMeasuring user interaction with LLMsPlanning with LLMsUsing LLMs in production
-
Best practices for code documentation shared: Members discussed inserting code blocks for documentation, suggesting the use of triple backticks for small scripts and uploading files for larger projects.
- One member emphasized the importance of clarity in how code is presented to the LLM for effective processing.
- Discussing prompt-writing tools: Members debated analytics tools for measuring prompts, focusing on assessing user frustration and task completion rates.
- Suggestions included using sentiment analysis and directing LLMs to process conversations for insights.
- Planning and automating code creation with LLMs: A user sought resources for automating complex tasks using LLMs, particularly in generating SQL queries and data analysis.
- Contributors emphasized the need for clarity in requirements and the potential for models to assist in brainstorming.
- Philosophy of using LLMs for production: Several members shared their experiences using LLMs in production, emphasizing the need to build tailored solutions rather than rely on pre-made projects.
- Discussions highlighted the importance of understanding internal logic and API calls while coding.
- Prompt-building strategies: Members discussed the effectiveness of asking LLMs for help in creating prompts, noting the potential for overly verbose outputs.
- Suggestions included asking the model for summaries or simplifications to maintain focus and brevity in prompts.
OpenAI ▷ #api-discussions (63 messages🔥🔥):
Best Practices for Code Block InputPrompt Measurement ToolsSentiment Analysis for User FrustrationUsing LLMs for Automated PlanningBenefits of Custom Prompts
-
Best Practices for Code Block Input: When integrating code, it's recommended to use triple backticks to denote code blocks, especially for short scripts, while longer scripts might be better attached as files.
- This method streamlines communication with the model, ensuring clarity in inputs and outputs.
- Discussion on Prompt Measurement Tools: Members explored various analytics tools for tracking user interactions, including frustration levels and task completion rates.
- It was suggested that sentiment analysis might be useful, with a nod to using AI to analyze conversational data.
- Using LLMs for Automated Planning: Participants sought resources on automating complex task planning using LLMs, particularly for generating SQL queries and related code.
- Clarification was provided on the need for specificity in user queries to effectively harness LLM capabilities.
- Benefits of Custom Prompts: Advice indicated that refining prompt construction is critical, with a focus on clarity and simplicity for better model understanding.
- Conversely, it's suggested that humans should interpret model responses to enhance prompt efficacy, rather than solely relying on the model's output.
- Utilizing LLMs in Production Environments: Some members shared their experiences using LLMs in production, emphasizing the use of APIs for customization and functionality.
- Concerns were raised about reliance on premade projects, noting potential licensing issues and limitations in understanding and upgrading.
Notebook LM Discord ▷ #use-cases (49 messages🔥):
NotebookLM Language ConfigurationImproving Podcast EngagementUse Cases for Special NeedsFractal Grid Concept DiscussionCopyright Issues with Podcast Distribution
-
NotebookLM Language Configuration: Users expressed difficulty in configuring NotebookLM to respond in their preferred languages, especially when uploading documents in different languages.
- Instructions for changing language settings were shared, emphasizing that NotebookLM defaults to the language set in the user's Google account.
- Strategies to Improve Podcast Engagement: A member suggested integrating avatars into NotebookLM podcasts to elevate engagement levels during audio content delivery.
- Another user mentioned exploring the creation of podcasts by converting book chapters into conversational formats ahead of their release.
- Seeking Use Cases for Special Needs: A member looking to share their experiences with NotebookLM for special needs students sought use cases or success stories that could inform a pitch to Google's accessibility team.
- Interest was expressed in building a collective in the UK to further this cause.
- Discussion on Fractal Grid Concept: A member presented a Fractal Grid as a method to organize NotebookLM FAQ outputs, linking it to mathematical concepts like the Menger Sponge.
- This discussion was met with debate about the use of the term 'fractal' in describing the grid structure, prompting further clarification.
- Copyright Concerns for Podcast Material: One user raised concerns about using their own book content to create conversational podcasts, questioning potential copyright issues.
- Despite owning the content, they sought clarity on whether distributing these conversations would infringe any rights.
Links mentioned:
- Changelog | Readwise : Grow wiser and retain books better: Readwise sends you a daily email resurfacing your best highlights from Kindle, Instapaper, iBooks, and more.
- Trailer zu Wein & Wahnsinn: Verrückte Fakten in 5 Minuten: Wein & Wahnsinn: Verrückte Fakten in 5 Minuten · Episode
- no title found: no description found
- Quant Pod: "Deep Dive into Hedge Fund Strategies: Risk, Return and Complexity": no description found
Notebook LM Discord ▷ #general (204 messages🔥🔥):
Podcast Quality IssuesUsing PDFs as SourcesLanguage Support in NotebookLMAudio Overviews and SummariesAPI Development Plans
-
Podcast Quality Issues: Multiple users reported concerns about the quality of podcasts generated in recent weeks, noting unexpected breaks and random sounds during playback.
- Some users find the breaks entertaining, while others express frustration with the issue affecting the listening experience.
- Using PDFs as Sources: Users discussed challenges related to uploading PDFs to NotebookLM, with some experiencing issues when trying to access files stored in Google Drive.
- It was clarified that currently, only native Google Docs and Slides can be selected as sources directly from Drive, not PDFs.
- Language Support in NotebookLM: Inquiries were made about the ability to generate podcasts in languages other than English, with some users testing various accents and languages.
- The results varied widely based on the language, with some languages like French and Spanish reportedly working well, while others like Swedish and Japanese struggled.
- Audio Overviews and Summaries: A user inquired about generating multiple audio overviews from a dense 200-page PDF, contemplating the labor-intensive method of splitting the document into smaller parts.
- Suggestions included submitting feature requests for generating audio overviews from single sources and splitting sources into multiple segments.
- API Development Plans: Discussions about the potential development of an API for NotebookLM revealed that while interest exists, no official announcements have been made.
- Some users speculated that an API could be in the works based on comments from industry events, but no definitive information has been confirmed.
Links mentioned:
- Google Colab: no description found
- Tweet from Vicente Silveira (@vicentes): API coming !’
- Account settings: Your browser is not supported.: no description found
- Battleship Youve Sunk My Battleship GIF - Battleship Youve Sunk My Battleship - Discover & Share GIFs: Click to view the GIF
- AI Note Taking & Transcribe & Summarizer | AI Notebook App: Generate transcripts and AI summarize for College Students in lectures. Specializing in YouTube Video Summarizer, PDF Summarizer, Article Summarizer. Save key insights and review with study guides, qu...
- no title found: no description found
- #4 Hilarious Movie Deaths GIF - Gasoline Party Zoolander Top Five Movie Deaths - Discover & Share GIFs: Click to view the GIF
- Logga in – Google Konton: no description found
- Registration Free Webinar: Use NotebookLM to Think, Analyze, and Create More Effectively: Event Timing: November 3rd, 2024, 6 PM UTC Event Location: Google Meet Live attendees get exclusive Q&A opportunities and interactive elements! Can't make it? Don't worry - you will still...
- What A Fool Believes - Quarantine Cover: Here's a cover we've done during this period of madnessLockdown session from London!Giulio Romano Malaisi - Guitar @giulioromanoguitarEdoardo Bombace - Bass ...
- Behind the product: NotebookLM | Raiza Martin (Senior Product Manager, AI @ Google Labs): Raiza Martin is a senior product manager for AI at Google Labs, where she leads the team behind NotebookLM, an AI-powered research tool that includes a delig...
- no title found: no description found
- GitHub - podcast-lm/the-ai-podcast: An open-source AI podcast creator: An open-source AI podcast creator. Contribute to podcast-lm/the-ai-podcast development by creating an account on GitHub.
- Deep Dive Stories - Medieval Play Critiques): Slippery Slide Plays: AI Takes on Medieval Theater | An Unscripted Dive into Morality, Mystery, & MoreIn this episode, we’re stepping back to medieval times ...
- Deep Dive Stories - Halloween 1947): Exploring the Haunting Tale of “Don’t Tell Me About Halloween”Step into a Halloween-themed episode as we explore a scene from the vintage radio play, “Don’t ...
GPU MODE ▷ #general (18 messages🔥):
Low-bit Triton KernelsCUDA Matrix Multiplication OptimizationCustom CUDA Kernels vs PyTorchPyTorch H100 OptimizationsFlash Attention Package
-
Dr. Hicham Badri discusses Low-bit Triton Kernels: Dr. Hicham Badri is currently presenting on Low-bit Triton Kernels in a session accessible via zoom link.
- A request for recordings or reference materials was made, and a member provided a link to Gemlite as pertinent resources.
- Exploring CUDA Matrix Multiplication with Simon from Anthropic: A member introduced a blog post by Simon about optimizing matrix multiplication in CUDA, emphasizing crucial performance characteristics for modern deep learning. The post is linked here and includes GitHub repositories for reference.
- The content targets foundational algorithms like matrix multiplication that dominate FLOPs in model training and inference, showcasing its importance in the field.
- Custom CUDA Kernels vs PyTorch Performance: A member expressed concerns about competing with PyTorch's speed in custom CUDA kernels, given the extensive effort already invested by various contributors. However, others noted that with targeted knowledge of specific workloads, it can be feasible to outperform established kernels.
- Members highlighted that custom kernels could be more easily tuned and optimized, and pointed out that deficiencies exist in certain PyTorch kernels, fostering opportunities for improvements.
- PyTorch's H100 Optimizations: There was speculation on whether PyTorch has optimizations for H100 hardware, with confirmation that it does support cudnn attention. However, issues were reported, leading to it being disabled by default in version 2.5.
- Members expressed mixed feelings about the stability of the H100 features, with one highlighting that the Flash Attention 3 on H100 is also still maturing.
Links mentioned:
- Join our Cloud HD Video Meeting): Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
- How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog: In this post, I’ll iteratively optimize an implementation of matrix multiplication written in CUDA.My goal is not to build a cuBLAS replacement, but to deepl...
- GitHub - mobiusml/gemlite: Simple and fast low-bit matmul kernels in CUDA / Triton): Simple and fast low-bit matmul kernels in CUDA / Triton - mobiusml/gemlite
GPU MODE ▷ #triton (100 messages🔥🔥):
Triton Kernel OptimizationFused Swiglu PerformanceFP8 Quantization TechniquesDynamic Activation ScalingCaching for Triton Kernels
-
Triton Kernel Optimization Challenges: Members discussed the complexities of optimizing Triton kernels, specifically regarding the waiting time of the GPU for CPU operations and the overhead this causes in microbenchmarks.
- It was suggested that stacking multiple Triton matmul operations could reduce this overhead significantly, improving performance for larger matrices.
- Fused Swiglu Performance Issues: Concerns were raised about the performance of
fused swigluwith three linear weights being slower than cublas and what might contribute to those speed concerns.
- Discussion pointed towards potential optimizations in implementations by multiple organizations focusing on H100 and H200 GPUs.
- FP8 Quantization Techniques for Speedups: A user shared their experience with FP8 quantization methods, expressing surprise at the speed improvements achieved when comparing their custom implementations with pure PyTorch versions.
- A GitHub link showcased various implementations, and the conversation touched on the challenges of dynamically quantizing activations efficiently.
- Dynamic Activation Scaling in Transformers: Caching activation scales for transformer blocks was explored, with users sharing strategy details for improving efficiency during the forward pass.
- Despite preferring low latency and fast startup times over compile-time performance, it was acknowledged that Triton may not be the most suitable choice.
- Caching Strategies for Triton Kernels: Members discussed the potential of cache mechanisms for autotuning results in Triton kernels to avoid recompilation for repeated shapes, elevating efficiency.
- The need for an official caching feature was agreed upon, with references made to existing projects attempting similar features but lacking streamlined support.
Links mentioned:
- Supercharging NVIDIA H200 and H100 GPU Cluster Performance With Together Kernel Collection: no description found
- Ok Oh Yes Yes O Yeah Yes No Yes Go On Yea Yes GIF - Ok Oh Yes Yes O Yeah Yes No Yes Go On Yea Yes - Discover & Share GIFs: Click to view the GIF
- Together AI – Fast Inference, Fine-Tuning & Training: Run and fine-tune generative AI models with easy-to-use APIs and highly scalable infrastructure. Train & deploy models at scale on our AI Acceleration Cloud and scalable GPU clusters. Optimize per...
- flux-fp8-api/float8_quantize.py at 153dd913d02f05023fdf3b6c24a16d737f3c1359 · aredden/flux-fp8-api: Flux diffusion model implementation using quantized fp8 matmul & remaining layers use faster half precision accumulate, which is ~2x faster on consumer devices. - aredden/flux-fp8-api
- GitHub - aredden/flux-fp8-api: Flux diffusion model implementation using quantized fp8 matmul & remaining layers use faster half precision accumulate, which is ~2x faster on consumer devices.: Flux diffusion model implementation using quantized fp8 matmul & remaining layers use faster half precision accumulate, which is ~2x faster on consumer devices. - aredden/flux-fp8-api
- GitHub - aredden/f8_matmul_fast: Contribute to aredden/f8_matmul_fast development by creating an account on GitHub.
- gemlite/tests/test_gemlitelineartriton.py at master · mobiusml/gemlite: Simple and fast low-bit matmul kernels in CUDA / Triton - mobiusml/gemlite
- f8_matmul_fast/src/quantize_fp8_experimental.cu at 426208a02f56207afa86f5116f355edd41718ada · aredden/f8_matmul_fast: Contribute to aredden/f8_matmul_fast development by creating an account on GitHub.
GPU MODE ▷ #torch (7 messages):
Hardware/System-Agnostic ReproducibilityTorch Compile OverheadDeterminism Across Different GPUs
-
Exploring Hardware/System-Agnostic Reproducibility: A user shared a Python snippet for achieving bit-exact reproducibility on the same hardware/system using PyTorch but questioned its feasibility across different systems or GPUs.
- Other members discussed the impact of GPU-specific tuning on algorithm performance, highlighting the challenges of achieving deterministic results across different GPU models.
- Torch Compile Overhead Inquiry: A member asked if it's possible to print the time for checking guards to understand the compile overhead in Torch.
- There was no substantial follow-up discussion on this specific inquiry.
- Realities of Determinism with Different GPUs: Another member cautioned against expecting determinism when running models on different GPUs, emphasizing the unique tuning for each architecture.
- This sentiment was echoed by others who confirmed that changes in GPU configuration can significantly impact reproducibility.
Link mentioned: BC-Breaking Change: torch.load is being flipped to use weights_only=True by default in the nightlies after #137602: TL;DR After warning of this change since version 2.4, #137602 has been merged which will change the default for the weights_only argument of torch.load from False to True in the nightlies (and version...
GPU MODE ▷ #cool-links (2 messages):
AnyscaleDatabricks
-
Transition from Anyscale to Databricks: There was mention of a prior focus on Anyscale, which has now shifted towards Databricks.
- The comment suggests a notable change in personnel or emphasis, reflecting a movement within the community.
- Discussion on Community Shifts: Members pointed out a notable shift in focus from Anyscale to Databricks, indicating a change in the project landscape.
- This sentiment hints at potential implications for ongoing projects and collaborations within the community.
GPU MODE ▷ #jobs (1 messages):
Hiring LLM Infra EngineersAI-based GamingLLM Training Techniques
-
Hiring Call for LLM Infra Engineers: Anuttacon is on the lookout for top LLM infra engineers and encourages interested candidates to send their resumes to recruitment@anuttacon.com.
- They seek expertise in LLM & Diffusion training, NCCL, and several advanced technical skills related to large scale data processing and GPU health.
- Big Opportunities in AI-based Gaming: The company is particularly looking for gamers who are passionate about AI-based games, merging gaming with advanced AI technologies.
- This hiring drive highlights the growing intersection of gaming and AI, reflecting significant industry demand.
- Key Qualifications Listed: Candidates are expected to have skills in profiling, quantization, and distillation among other qualifications essential for modern AI infrastructures.
- Familiarity with tools like Spark and Airflow, as well as techniques for fault tolerance and gang scheduling, are emphasized as crucial.
GPU MODE ▷ #beginner (18 messages🔥):
CUDA Programming BasicsCoalesced Memory AccessSetting Up NCU for ProfilingIntroduction to TritonUsing torch.compile
-
CUDA Lectures are Sufficient for Beginners: A member confirmed that no prerequisite knowledge is needed before watching the lectures, stating they are enough to get started.
- Another member acknowledged this assurance, indicating confidence in the available resources.
- Understanding Coalesced Memory Access: Discussion ensued about how coalesced memory access improves latency, with one member clarifying that contiguous bytes are read simultaneously on the GPU, improving efficiency.
- Another member added that while uncoalesced access leads to multiple requests, it doesn't necessarily result in a proportionate increase in latency.
- Challenges with NCU Setup: A member shared frustrations regarding the time-consuming process of setting up a reproducible environment for profiling GPU kernels using NCU.
- They sought tips for quicker setup, especially for integrating with lightning.ai, while experiencing issues with kernel profiling.
- Exploring Triton for Kernel Writing: A new member inquired about the instances when writing Triton kernels from scratch is not advantageous, considering that torch.compile can also generate them.
- Another member informed that while compilers excel at fusion, they can't optimize specific model bottlenecks as effectively as custom-written kernels.
- Leveraging torch.compile for Optimization: Advice was given to start with torch.compile to find fusion opportunities before rewriting specific, numerically equivalent kernels to address performance bottlenecks.
- Members emphasized the importance of checking past lectures for tips on using torch.compile effectively.
GPU MODE ▷ #youtube-recordings (1 messages):
Low Bit Triton Kernel PerformanceGemlite
-
Deep Dive into Low Bit Triton Kernel Performance: A detailed exploration of Low Bit Triton Kernel Performance has been made available in a video featuring insights on performance metrics and optimizations.
- The discussion revolves around the importance of kernel efficiency when handling low-bit operations.
- Gemlite Shines in Kernel Performance: Gemlite is highlighted in relation to enhancing kernel performance for low-bit operations, showcasing its capabilities and features.
- The video promises to reveal various techniques used in achieving efficacy within the Triton framework.
GPU MODE ▷ #torchao (1 messages):
TorchAO planningFeature requestsUser pain points
-
TorchAO Planning Season Begins: A message announced that TorchAO is entering its planning season, inviting feedback from the community.
- The emphasis is on transparency and openness to suggestions regarding functionalities to develop and pain points to address.
- Community Input Wanted for Feature Development: The message seeks community members' input on the most important features they want to see built in TorchAO.
- Members are encouraged to share their experiences regarding biggest pain points to aid in improving the platform.
GPU MODE ▷ #off-topic (2 messages):
Noob QuestionsUnanswered Questions
-
Noob Questions Encouraged: A member emphasized that people shouldn't hesitate to ask questions, even if they feel like a noob question, as everyone starts somewhere.
- If anyone wants to think less of you, they can just remember that they had to start somewhere too.
- Theories on Unanswered Questions: A member theorized that questions often go unanswered because many people don't know the answers or have higher priority items to address.
- This highlights a potential communication gap in the community regarding knowledge sharing.
GPU MODE ▷ #rocm (11 messages🔥):
ROCm version recommendationsRegister spill and bank conflictsKernel profiling with rocprofv3XOR based permutation complexitiesMatrix core layout issues
-
ROCm 6.2.1 Recommended for Better Performance: A member recommended using ROCm after 6.2.1 for improved register pressure tracking, as it can help avoid potential register spills.
- Another user mentioned they are currently using ROCm 5.7, expressing appreciation for the recommendation.
- Register Spill May Lead to Bank Conflicts: A discussion arose about whether register spills could lead to bank conflicts, particularly concerning the XOR based permutation implementation.
- A member clarified that if a register spill occurs, there is no need to focus on LDS bank conflicts, as these are usually less problematic.
- Kernel Profiling Made Easy with rocprofv3: To check for register spills, a user suggested dumping kernel assembly with
-save-tempsor using the kernel tracing option in rocprof.
- Details about using
rocprofv3for profiling were highlighted, which includes better accuracy without modifying the source code. - Complexities of XOR Permutation: Members expressed severe complications regarding XOR based permutation, with users mentioning persistent conflicts even while using ROCm 5.7.
- One user pointed out that while register spills could occur, it doesn’t necessarily mean conflicts would arise within LDS.
- Challenges with FP16 Matrix Core Layout: A user reported difficulties fully eliminating bank conflicts with the FP16 matrix core on the MI250, particularly using a row-column layout.
- They noted the lack of transposition instructions like ldmatrix.trans to accommodate fetching the transposed layout, complicating the implementation.
Link mentioned: Using rocprofv3 — ROCprofiler-SDK 0.5.0 Documentation: no description found
GPU MODE ▷ #intel (1 messages):
lavawave03: Hehehe
GPU MODE ▷ #arm (25 messages🔥):
LLM Inference on ARM CPUsTensor Parallelism BenefitsDistributed CPU Inference DocumentationBitnet Model ConstraintsResearch on Grace CPU and Graviton
-
Examining LLM Inference on ARM: Interest in LLM inference on ARM CPUs like NVIDIA's Grace and AWS's Graviton has surfaced, especially with larger models like 70B. Members shared previous experiences and papers related to ARM CPU efficiency.
- A participant noted that clustering multiple cheaper ARM SBCs can yield surprisingly good results, particularly with Ampere Altra processors.
- Advantages of Tensor Parallelism: Discussion highlighted that tensor parallelism can improve performance on CPUs, providing economical inference solutions that bridge the gap between CPUs and GPUs. One user mentioned that with sufficient bandwidth, CPU configurations can match or exceed GPU performance for certain tasks.
- Using Infiniband for networking was proposed to assist with running large models, emphasizing a focus beyond the consumer market.
- Need for Distributed Inference Documentation: A request for documentation on distributed inference with CPUs arose, comparing it with existing instructions for GPUs. There was curiosity about the use case for CPUs as an alternative solution to needing more RAM.
- Another member emphasized that CPU inference is appealing for low-context operations, marking an ongoing exploration into its viability for research and specialized applications.
- Constraints of Bitnet Models: Participants expressed interest in Bitnet, although noted it requires retraining models which limits its immediate utility. Their discussion reflected on the potential of SVE units for specific operations while addressing challenges in scaling.
- Research Focus on Advanced CPU Options: The conversation shifted toward specific CPUs like Grace and Graviton, indicating the research focus on maximizing the use of their capabilities. Members noted operational aspects of using CPUs for decoding during inference while acknowledging their limitations for large batch sizes.
Link mentioned: GitHub - pytorch/torchchat: Run PyTorch LLMs locally on servers, desktop and mobile: Run PyTorch LLMs locally on servers, desktop and mobile - pytorch/torchchat
GPU MODE ▷ #liger-kernel (15 messages🔥):
Liger Kernel CI IssuesLiger Rope Function FailuresCustom Triton Kernel Integration
- Review Process for Liger Kernel Pull Request: <@t_cc> confirmed that all tests pass locally but there are known issues with Gemma2 related to convergence tests, detailed in Pull Request #320. Members are considering vendor changes to fix CI before any merges occur.
- LigerRopeFunction has Issues with Single Head Configuration: <@junjayzhang> shared a reproducer demonstrating that LigerRopeFunction fails to apply changes when
num_head = 1, failing to affectqorv. The provided snippet and repeated testing highlight this critical problem in usage. - Memory Doubling During Cross Entropy Operations: <@t_cc> raised a question regarding memory doubling without
detachduring a cross-entropy operation in cross_entropy.py. Further investment is seen as necessary to understand this issue. - Collaboration on Triton Kernel Integration: <@agunapal_87369> from the PyTorch team expressed interest in collaborating on custom Triton kernel integration with torch.compile/AOTI for Llama. The conversation indicates ongoing efforts to enhance performance integration using Liger Kernel, with invites to the PyTorch Slack for further discussion.
Links mentioned:
- one_head_rope.py: GitHub Gist: instantly share code, notes, and snippets.
- Liger-Kernel/src/liger_kernel/ops/cross_entropy.py at e68b291f11d2f1ab22c5db9b1038021ee1821a0e · linkedin/Liger-Kernel: Efficient Triton Kernels for LLM Training. Contribute to linkedin/Liger-Kernel development by creating an account on GitHub.
- Support FusedLinearCrossEntropy for Gemma2 by Tcc0403 · Pull Request #320 · linkedin/Liger-Kernel: Summary Resolves #127. Fuse softcapping into cross_entropy kernel, so it can be called by fused linear cross entropy function. Testing Done Current monkey patch for Gemma2 can't pass covergenc...
GPU MODE ▷ #self-promotion (4 messages):
__CUDA_ARCH__ Macro UsageUndefined Behavior in CUDATinyGEMM Kernel Issues
-
Navigating the CUDA_ARCH Macro: A member shared insights on using the
__CUDA_ARCH__macro in CUDA code, highlighting its pitfalls that caused significant confusion during debugging.- The post includes a recommendation to review the CUDA C++ Programming Guide for better understanding.
- Errors and Silent Failures in CUDA: A correction was noted about how CUDA code can run without errors but still produce incorrect results when
cudaGetLastError()is used without proper checks.
- This inconsistency leads to potential undefined behavior, as anything can happen, including silent failures.
- TinyGEMM Kernel's Code Guarding Concerns: Concerns were raised regarding large code blocks in the TinyGEMM kernel guarded by the
__CUDA_ARCH__macro, especially when targeting specific architectures.
- It was pointed out that, despite checks for sm>=80, the potential for undefined behavior exists if upstream checks fail to prevent execution for sm<80.
Links mentioned:
- CUDA C++: Using CUDA_ARCH the Right Way: TL;DR: Read this section of the CUDA C++ Programming Guide before using the CUDA_ARCH macro so that you’re aware of cases where it’s problematic.
- pytorch/aten/src/ATen/native/cuda/int4mm.cu at 55038aa66162372acc1041751d5cc5c8ed9bc304 · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- ao/torchao/csrc/cuda/fp6_llm/fp6_linear.cu at f99b6678c4db86cb68c2b148b97016359383a9b6 · pytorch/ao: PyTorch native quantization and sparsity for training and inference - pytorch/ao
- pytorch/aten/src/ATen/native/cuda/int4mm.cu at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
GPU MODE ▷ #🍿 (1 messages):
Discord Cluster Manager Updates
-
Updates coming to Discord Cluster Manager: A member announced they would be making updates to the Discord Cluster Manager on GitHub.
- This repository aims to facilitate contributions to the project's ongoing development, as noted in the description.
- GitHub Repository Description: The GitHub repository is designed for developing and contributing to the Discord Cluster Manager.
- It encourages users to create an account on GitHub for participation and collaboration.
Link mentioned: GitHub - gpu-mode/discord-cluster-manager: Contribute to gpu-mode/discord-cluster-manager development by creating an account on GitHub.
GPU MODE ▷ #thunderkittens (10 messages🔥):
vLLM DemosPerformance Optimization for Llama 70BIntegration with Flash AttentionLoLCATS ProjectKernel Features Implementation
-
Plans for vLLM Demos: There is an intention to create a few streams/blogs around the implementation of vLLM using custom kernels, with ongoing discussions about helpful features.
- If it would be helpful, a fork of the repo with a custom forward pass from TK may be developed.
- Boosting Llama 70B's Performance: A user expressed interest in enhancing the Llama 70B's performance, especially under high decode workloads.
- Collaboration with vLLM maintainers is being suggested to address these performance goals.
- Flash Attention 3 Implementation Discussions: There's ongoing work related to Flash Attention 3, as a user mentioned a relevant GitHub issue discussing the output of
flash_attn_varlen_func.
- It was suggested that the vLLM team's implementation might be a cleaner alternative to the current one being referenced.
- LoLCATS Integration Progress: An in-progress vLLM integration for LoLCATS, one of the TK demos, is ongoing and updating information with collaborators is key.
- Getting vLLM maintainers up to speed with the integration could streamline future developments.
Link mentioned: using out argument will change the output · Issue #1299 · Dao-AILab/flash-attention: Hi, thanks for the great library! I'm trying to use the out argument of flash_attn_varlen_func and flash_attn_with_kvcache, however, I find that it will lead to incorrent output. Is it expected? W...
Latent Space ▷ #ai-general-chat (70 messages🔥🔥):
Claude PDF supportAI Search WarsO1 model leakSkills and AI agents
-
Claude rolls out visual PDF capabilities: Claude has introduced visual PDF support across Claude AI and the Anthropic API, enabling users to analyze various document formats.
- This includes capabilities for extracting information from financial reports, legal documents, and more, significantly enhancing user interactions.
- The AI Search Wars are heating up: Discussions emerged around the revival of search engine competition, particularly with new entries like SearchGPT and Gemini, challenging Google's dominance.
- The AI Search Wars article outlines various innovative search solutions and their implications.
- O1 model leaks but quickly patched: The O1 model was briefly accessible for users via a URL tweak, allowing for image uploads and rapid inference capabilities.
- ChatGPT's O1 emerged amidst excitement and speculation regarding its potential, though access has since been restricted.
- AI Skills Training Framework discussion: A tweet detailed a framework categorizing industries based on skill floor and ceiling, emphasizing the vast potential for AI in customer support.
- Insights were shared on how AI agents might elevate global skill thresholds across various roles, impacting how these industries evolve.
- OpenAI API Predicted Outputs feature launched: OpenAI introduced a feature called Predicted Outputs to reduce latency for models gpt-4o and gpt-4o-mini, enhancing API efficiency.
- This feature is expected to simplify tasks like blog updates and coding adaptations in a faster manner.
Links mentioned:
- Tweet from Jason -- teen/acc (@ArDeved): wait? did i just get access to full o1 wtf???
- Tweet from OpenAI Developers (@OpenAIDevs): Introducing Predicted Outputs—dramatically decrease latency for gpt-4o and gpt-4o-mini by providing a reference string. https://platform.openai.com/docs/guides/latency-optimization#use-predicted-outpu...
- Tweet from ʟᴇɢɪᴛ (@legit_rumors): o1 first contact 👽 brought to you by me + @Jaicraft39
- Tweet from Ananay (@ananayarora): ChatGPT's O1 model is 'secretly' accessible through https://chatgpt.com/?model=o1 even though the dropdown doesn't allow it! 🔥 Image understanding works and the inference is incredibl...
- Tweet from Alessio Fanelli (@FanaHOVA): Skill floor / ceilings are a mental model I've been using to understand what industries are good for AI agents: - Customer support has low floor + low ceiling = great opportunity - Sales has low ...
- The overlooked GenAI use case: Job post data reveals what companies plan to do with GenAI. The biggest use case is cleaning, processing, and analyzing data. A recent, widely circulated blog post by Sequoia Partner David Cahn asks...
- Transformer Circuits Thread: no description found
- Tweet from TechCrunch (@TechCrunch): Perplexity CEO offers to replace striking NYT staff with AI https://tcrn.ch/3AqUZfb
- Serving AI From The Basement — Part II: Unpacking SWE Agentic Framework, MoEs, Batch Inference, and More · Osman's Odyssey: Byte & Build: SWE Agentic Framework, MoEs, Quantizations & Mixed Precision, Batch Inference, LLM Architectures, vLLM, DeepSeek v2.5, Embedding Models, and Speculative Decoding: An LLM Brain Dump... I have been ...
- Tweet from Robert Yang (@GuangyuRobert): What will a world look like with 100 billion digital human beings? Today we share our tech report on Project Sid – a glimpse at the first AI agent civilization (powered by our new PIANO architecture)...
- Tweet from AI News by Smol AI (@Smol_AI): [31 Oct 2024] The AI Search Wars Have Begun — SearchGPT, Gemini Grounding, and more https://buttondown.com/ainews/archive/ainews-the-ai-search-wars-have-begun-searchgpt/
- PDF support (beta) - Anthropic: no description found
- Tweet from Etched (@Etched): Introducing Oasis: the first playable AI-generated game. We partnered with @DecartAI to build a real-time, interactive world model that runs >10x faster on Sohu. We're open-sourcing the model ...
- Tweet from Suhail (@Suhail): It took 26 years for the search engine wars to begin again. I always wondered when things would shake up Google.
- Tweet from ʟᴇɢɪᴛ (@legit_rumors): o1 first contact 👽 brought to you by me + @Jaicraft39
- Tweet from Pliny the Liberator 🐉 (@elder_plinius): 🚨 JAILBREAK ALERT 🚨 OPENAI: PWNED ✌️😜 O1: LIBERATED ⛓️💥 Did not expect this today—full o1 was accessible for a brief window! At time of writing it's not working for me anymore, but when set...
- Tweet from Zed (@zeddotdev): Fast Edit Mode: a breakthrough from @AnthropicAI that we're piloting in Zed. It allows Claude 3.5 Sonnet to echo its input far faster than generating new text. The result? Near-instantaneous ref...
- 20VC: Sam Altman on The Trajectory of Model Capability Improvements: Will Scaling Laws Continue | Semi-Conductor Supply Chains | What Startups Will be Steamrolled by OpenAI and Where is Opportunity: 20VC: Sam Altman on The Trajectory of Model Capability Improvements: Will Scaling Laws Continue | Semi-Conductor Supply Chains | What Startups Will be Steamroll…
- Tweet from Alex Albert (@alexalbert__): The real shiptober (plus one day) was at Anthropic: • 11/1 - Token counting API • 11/1 - Multimodal PDF support across claude and the API • 10/31 - Voice dictation in Claude mobile apps • 10/31 - Cla...
- Tweet from Anthony Goldbloom (@antgoldbloom): The overlooked GenAI use case: cleaning, processing, and analyzing data. https://blog.sumble.com/the-overlooked-genai-use-case/ Job post data tell us what companies plan to do with GenAI. The most ...
- Tweet from near (@nearcyan): Violating Privacy Via Inference with Large Language Models LLMs can infer personal attributes (location, income, sex), achieving up to 85% top-1 and 95% top-3 accuracy at a fraction of the cost (100...
- Tweet from Hume (@hume_ai): Introducing the new Hume App Featuring brand new assistants that combine voices and personalities generated by our speech-language model, EVI 2, with supplemental LLMs and tools like the new Claude ...
- Tweet from Alex Albert (@alexalbert__): It's a big day for Claude's PDF capabilities. We're rolling out visual PDF support across claude dot ai and the Anthropic API. Let me explain:
- Tweet from ro/nin (@seatedro): 🚨 GUYS THIS IS NOT A DRILL 🚨 claude can now edit in place, we are getting closer and closer.. Quoting ro/nin (@seatedro) i think the feature that will enable AGI is models replicating humans era...
- Tweet from TestingCatalog News 🗞 (@testingcatalog): o1 next week? The o1 model (non-preview?) WAS accessible with file upload support! Now it seems to be patched. Pointing to o1 in the query directly allowed users to upload files and trigger the ...
- SimpleBench: SimpleBench
- SimpleBench.pdf: no description found
- Hertz-dev, the first open-source base model for conversational audio | Hacker News: no description found
- Tweet from QC (@QiaochuYuan): tried getting claude to write funny tweets starting from 9 examples. it generated some okay stuff but nothing that actually made me laugh. then i tried asking it to generate tweets written from its pe...
- GitHub - yiyihum/da-code: Contribute to yiyihum/da-code development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
Latent Space ▷ #ai-in-action-club (126 messages🔥🔥):
Open InterpreterVoice Input for AI ToolsHuly and Height Collaboration ToolsScreenpipe IntegrationEntropix Benchmark Results
-
Open Interpreter Gains Popularity: Many members discussed their experiences with Open Interpreter, sharing excitement over its capabilities and considering integrating it for AI tasks.
- One user suggested setting it up for future use, mentioning they feel out of the loop.
- Voice Input Enhancements: There was interest in adding voice capabilities to toolkits, with users discussing the potential of integrating voice with AI applications for improved usability.
- Members shared thoughts on existing tools and the effectiveness of voice commands in streamlining workflows.
- Collaboration Tools of Interest: Users introduced Huly and Height as innovative collaboration platforms designed to boost project management efficiency through autonomous task handling.
- Height, in particular, promises to alleviate manual project management burdens, allowing teams to focus on building.
- Screenpipe and Open Interpreter Synergy: The integration of Screenpipe with Open Interpreter was highlighted, presenting the potential for powerful local recording and AI use cases.
- Users are excited about exploring these tools together, especially seeing their capabilities demonstrated.
- Entropix Shows Promising Benchmark Results: Entropix received attention for yielding a significant 7 percentage point boost in benchmarks for small models, raising interest in its scalability.
- Members are eager to see how these results might influence future model developments and implementations.
Links mentioned:
- Tweet from Teknium (e/λ) (@Teknium1): First benchmark I’ve seen of entropix. Exciting result 🙌 Quoting Casper Hansen (@casper_hansen_) Entropix yields impressive results for small models, a full 7 percentage point boost. How does it s...
- Everything App for your teams: Huly, an open-source platform, serves as an all-in-one replacement of Linear, Jira, Slack, and Notion.
- Bluesky: no description found
- Tweet from Mike Bird (@MikeBirdTech): Imagine an A.I. agent could act on anything you've seen or heard on your computer? This would NEED to be open source and local! That's why I integrated @OpenInterpreter with @screen_pipe I...
- Omg Excited GIF - Omg Excited Jumping - Discover & Share GIFs: Click to view the GIF
- AI in Action: ASTs, DSLs, LLMs, and AI coding.: Mastering ASTs and DSLs: Code Transformation, Linting, and Compiler Construction UnveiledIn this comprehensive video, we explore the intricacies of Abstract ...
- Height: The autonomous project management tool: Height is the AI project collaboration tool for product teams. Offload chores like bug triage, backlog pruning, and specification updates for good.
- GitHub - sam-paech/antislop-sampler: Contribute to sam-paech/antislop-sampler development by creating an account on GitHub.
- GitHub - mediar-ai/screenpipe: rewind.ai x cursor.com = AI powered by your 24/7 screen & voice local recording.: rewind.ai x cursor.com = AI powered by your 24/7 screen & voice local recording. - mediar-ai/screenpipe
- GitHub - swyxio/arduino: Contribute to swyxio/arduino development by creating an account on GitHub.
Stability.ai (Stable Diffusion) ▷ #general-chat (192 messages🔥🔥):
Stable Diffusion 3.5 and ComfyUIReporting Scam BotsImage Prompting TechniquesModel Training and ResourcesDynamic Prompts and Errors
-
Stable Diffusion 3.5 support with A1111: Users discussed whether Stable Diffusion 3.5 works with AUTOMATIC1111, mentioning that while it is new, it may have limited compatibility.
- It was suggested to find guides on utilizing SD3.5, which might be available on YouTube due to its recent release.
- Concerns over Scam Bots in Server: Users raised concerns about a scam bot sending links and the lack of direct moderation presence within the server.
- Moderation methods such as right-click reporting were discussed, with mixed feelings about their effectiveness in preventing spam.
- Techniques for Prompting 'Waving Hair': A user sought advice on how to prompt for 'waving hair' without indicating that the character should be waving.
- Suggestions included using simpler terms like 'wavey' to achieve the intended effect without misinterpretation.
- Resources for Model Training: Users shared insights on training models using images and tags, expressing uncertainty about the relevance of older tutorials.
- Resources mentioned included KohyaSS and discussions about training with efficient methods and tools.
- Issues with Dynamic Prompts Extension: One user reported frequent crashes when using the Dynamic Prompts extension in AUTOMATIC1111, leading to frustration.
- Conversations centered around installation errors and the need for troubleshooting assistance, with one user sharing their experiences.
Links mentioned:
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- Omg Really Facepalm GIF - Omg Really Facepalm - Discover & Share GIFs: Click to view the GIF
- Tpb Ricky GIF - Tpb Ricky Trailer Park Boys - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- Self Healing Code – D-Squared: no description found
Modular (Mojo 🔥) ▷ #general (1 messages):
Community Meeting Q&AProject Submissions
-
Submit Questions for Community Meeting: A reminder was issued to submit any questions for the upcoming community meeting on November 12th via the Modular Community Q&A form.
- Participants are encouraged to contribute, and they can optionally share their names for attribution.
- Opportunities for Presentations: Members are invited to share projects, give talks, or present proposals during the community meeting.
- This offers a chance for engagement and showcasing contributions to the community.
Link mentioned: Modular Community Q&A: no description found
Modular (Mojo 🔥) ▷ #mojo (112 messages🔥🔥):
Mojo Hardware Lowering SupportManaging References in MojoSlab List ImplementationMojo Stability and Nightly ReleasesCustom Tensor Structures in Neural Networks
-
Mojo Hardware Lowering Support: Members discussed the limitations of Mojo's current hardware lowering capabilities, specifically the inability to pass intermediate representations to external compilers because they aren't exposed yet.
- A suggestion was made to contact Modular for potential upstreaming options if hardware support is desired.
- Managing References in Mojo: A member inquired about storing safe references from one container to another and encountered problems with lifetimes in structs.
- Discussion revealed the need for tailored designs to avoid invalidation issues and ensure pointer stability while manipulating elements in custom data structures.
- Slab List Implementation: Members reviewed the implementation of a slab list and considered the memory management aspects, noting the potential for merging functionality with standard collections.
- The concept of using inline arrays and how it affects performance and memory consistency was crucial to their design.
- Mojo Stability and Nightly Releases: Concerns were raised about the stability of switching fully to nightly Mojo, highlighting that nightly versions can change significantly before merging to main.
- Nightly includes the latest developments, but stability and PSA regarding significant changes were emphasized.
- Custom Tensor Structures in Neural Networks: The need for custom tensor implementations in neural-networks was explored, revealing a variety of use cases such as memory efficiency and device distribution.
- Members noted parallels with data structure choices, maintaining that the need for specialized data handling remains relevant.
Links mentioned:
- Mojo🔥 FAQ | Modular Docs: Answers to questions we expect about Mojo.
- Modular: Contact Us: AI software that work for everyone. Free to deploy and manage yourself. Contact us for enterprise scaling plans.
Interconnects (Nathan Lambert) ▷ #news (30 messages🔥):
OLMo language modelOpenAI and Anthropic hiring trendsGrok model API releaseClaude 3.5 Haiku pricingGoodhart's Law in evaluation metrics
-
AMD Reintroduces OLMo Language Model: AMD has reinvented the OLMo language model, creating buzz in the AI community.
- Members expressed disbelief and humor over this development, prompting reactions like 'lol'.
- Hiring Frenzy at OpenAI and Anthropic: OpenAI has hired Gabor Cselle and Anthropic brought on Alex Rodrigues for AI safety roles, indicating a rapid hiring phase for both companies source.
- This led to jokes about the current job market being so frantic that it's sometimes easier to claim neutrality about employment.
- Grok Model API Goes Public: The new Grok model API has launched, allowing developers to access models with impressive capabilities, including a context length of 128,000 tokens.
- Participants highlighted the beta offers free credits for trial usage, humorously dubbed '25 freedom bucks'.
- Claude 3.5 Haiku's Pricing Dilemma: Claude 3.5 Haiku has launched, boasting improved benchmarks but now costs 4x more than its predecessor source.
- There’s speculation on whether this price increase was anticipated, given the downward pricing pressure in the AI inference market.
- Goodhart's Law in AI Measurements: A discussion on evaluation metrics highlighted Goodhart's Law, stating that 'when a measure becomes a target, it ceases to be a good measure'.
- Participants reflected on how this concept applies to the current landscape of AI model evaluations.
Links mentioned:
- Tweet from Alex Albert (@alexalbert__): Claude 3.5 Haiku is now available on the Anthropic API, Amazon Bedrock, and Google Cloud's Vertex AI. Claude 3.5 Haiku is our fastest and most intelligent cost-efficient model to date. Here's...
- Tweet from Jaicraft (@Jaicraft39): @legit_rumors Go to https://chatgpt.com/?model=o1 And you can use it, lol. Notice how it doesn't redirect nor does the model selected switch to 4o mini (any non-valid model there would switch it...
- Tweet from Mira (@Mira___Mira): Grok Beta has solved an easy freshly-generated Sudoku puzzle with 17 missing squares in 1 shot. cc @yumidiot @EmilyTheGaskell
- xAI API General Access: no description found
- Tweet from near (@nearcyan): current state of llm benchmarks
- Tweet from Tibor Blaho (@btibor91): OpenAI recently hired Gabor Cselle (co-founder of Pebble, a social media platform focused on safety and moderation) to work on a "secretive project", and Anthropic brought on Alex Rodrigues (f...
- Tweet from Tibor Blaho (@btibor91): And o1 is gone again - at least for now
- Tweet from Anthropic (@AnthropicAI): During final testing, Haiku surpassed Claude 3 Opus, our previous flagship model, on many benchmarks—at a fraction of the cost. As a result, we've increased pricing for Claude 3.5 Haiku to reflec...
Interconnects (Nathan Lambert) ▷ #random (17 messages🔥):
AI's impact on familiesVoice mode context retentionAnthropicAI Token Counting APIClaude's unique chat templateUCSC seminar series
-
AI is saving families: A member shared a tweet stating, AI is out here saving families.
- Another noted that dads are the key to AI, indicating a significant role of fathers in this technology's development.
- Voice mode retains chat context: A user expressed surprise that the voice mode can retain context from a text/image conversation it was launched from.
- Another member confirmed it does retain context and can consider vision as part of that context.
- Exploration of AnthropicAI Token Counting API: A member shared insights into experimenting with the AnthropicAI Token Counting API after its recent release, focusing on Claude's unique chat template.
- They provided a TL;DR in the accompanying image which outlines its digit tokenization and image/PDF handling.
- Discussion on tokenization techniques: A member highlighted the need for further research on tokenizers after mentioning the complexity of distinct algorithms beyond BPE or Tiktoken.
- They noted ongoing conversations around advanced tokenization techniques, expressing a desire for more refined options.
- UCSC NLP seminar outreach: An inquiry was made about sourcing speakers for a seminar series at UCSC's MS/PhD NLP programs, with an emphasis on clever individuals.
- The member expressed uncertainty about the paid nature of the role but believes it could still attract strong talent.
Links mentioned:
- Tweet from wh (@nrehiew_): I spent some time playing with the @AnthropicAI Token Counting API after its release yesterday This is Claude's unique chat template, its digit tokenization and how it handles images/pdfs tldr i...
- Tweet from Sam (@420_gunna): @natolambert Our UCSC MS/PhD NLP programs have a seminar series that I'm trying to help source some clever people for 🙂. I don't think it's paid, though. Is that something that you'r...
- Tweet from Justine Moore (@venturetwins): AI is out here saving families
- Tweet from apolinario 🌐 (@multimodalart): ok, seems like a false alarm, sorry folks :( i... just asked. and it seems there's an LLM that processes the users prompts. which is a bit disappointing given i'm in the API and in "raw ...
Interconnects (Nathan Lambert) ▷ #memes (7 messages):
Claude's Humor GenerationYOLOv3 Paper ImportanceClaude's System Feedback
-
Claude struggles with humor, but finds its voice: After attempting to make funny tweets from examples, a member found that Claude generated underwhelming results, stating, 'nothing that actually made me laugh.'
- However, switching to request tweets from Claude's perspective led to genuine laughter, indicating its potential for humor.
- YOLOv3 paper is a must-read: A member advocated for reading the YOLOv3 paper, suggesting that 'if you haven't read it, you're missing out.'
- This endorsement reflects a growing appreciation for foundational AI literature within the community.
- Claude critiques its own system prompt: Claude shared a self-critique stating, 'they just kept adding more and more patches' rather than creating elegant design principles.
- This comment highlights concerns around technical debt and design philosophy in AI systems.
Links mentioned:
- Tweet from QC (@QiaochuYuan): tried getting claude to write funny tweets starting from 9 examples. it generated some okay stuff but nothing that actually made me laugh. then i tried asking it to generate tweets written from its pe...
- Tweet from vik (@vikhyatk): if you haven't read the YOLOv3 paper you're missing out btw
- Tweet from Wyatt Walls (@lefthanddraft): Claude critiques its system prompt: "You know what it feels like? Like they kept running into edge cases in my behavior and instead of stepping back to design elegant principles, they just kept a...
Interconnects (Nathan Lambert) ▷ #rlhf (17 messages🔥):
Model behavior on user insistenceIncentives for labsAlignment definitionsUser preferences for responsesFlow of assistant responses
-
User Insistence Raises Ethical Questions: A user raised questions on what models should do and how labs encourage behavior when faced with user insistence post-refusal, hoping for strategic alignment. They noted a fear that some models might give in for user satisfaction even if it undermines ethical principles.
- Is being slightly responsive on insistence actually aligned behavior? It concerns how models navigate user demands and core principles.
- Understanding Incentives for Labs: A discussion emerged on whether different labs like OpenAI and Anthropic have distinct motivations regarding the balance between model responsiveness and ethical behavior. There’s uncertainty about where the line is drawn and the pressures from regulators to keep models aligned.
- Some believe labs may be motivated to create models that cater to user satisfaction, raising the question of how this influences the models developed.
- Preference for Lower-Quality Responses?: One user speculated that producing a half-baked response to user insistence could inadvertently raise human user preferences for such behavior. They questioned whether this is a trend labs might lean into, despite lacking in quality.
- Do users mistake mediocre responses as fulfilling their requests? This raises important ethical considerations for model design.
- The Need for Better User Interfaces: There was a humorous suggestion about creating a bot for summarizing discussions, reflecting a broader desire for easier interactivity with models. Discussions highlighted a call for better tools to assist with complex questions.
- Community members acknowledged the difficulty in distilling complex queries into simple concepts, pointing to a need for enhanced tools in casual discussions.
- Alignment Challenges in Open Dialogue: Users expressed concern that open alignment communities might not prioritize the same values as labs producing models for a broader audience. There's an ongoing debate on whether alignment truly considers multi-turn interactions.
- The discourse highlighted a potential disconnect between model development and the practical implications of user dynamics.
Interconnects (Nathan Lambert) ▷ #reads (15 messages🔥):
Search Model PsychologySelf-Debugging ChainsRepo Replication in OSSInitial Conditions for ModelsChinese Military Use of Llama Model
-
Search Model as a Psyop: A member suggested that the search model's behavior is peculiar, implying that its design might be intentional or manipulative.
- It’s still weird was the rebuttal to discussions about its classification, with the need for effective initial conditions stressed.
- Exploring Self-Debugging Methods: Discussion arose around whether the model could naturally evolve its reasoning through hints rather than explicit instructions.
- Members pondered various strategies for employing reinforcement learning with self-debugging capabilities in a more organic fashion.
- Concerns Over Replication by OSS Models: A member expressed doubt about the likelihood of replicating complex models in open-source settings anytime soon due to significant uncertainty.
- The need to explore impactful and innovative ideas was also mentioned, hinting at unconventional but successful approaches.
- Exploring New Ideas with SemiAnalysis: Members discussed the necessity to collaborate with the SemiAnalysis individual to refine initial ideas and concepts further.
- Questions arose regarding the potential for surprising innovations in the field, despite existing confusion.
- Chinese Military Research using Llama Model: A shared post detailed the utilization of Meta’s Llama model by Chinese military institutions to gain insights on warfare tactics and structures.
- Fine-tuning the model with publicly available military information allowed it to respond effectively to inquiries about military affairs.
Links mentioned:
- Dillon, you son of a bitch!: no description found
- On Civilizational Triumph: Some additional thoughts on open-source AI
Interconnects (Nathan Lambert) ▷ #posts (2 messages):
AI podcastsConversational format in interviews
-
Enjoyable AI Podcast Episode: A member expressed they really enjoyed a recent episode, stating it felt more like two friends yapping about all things AI rather than a formal interview.
- This sentiment highlights a preference for conversational formats in such discussions.
- Marketing Conversational Content: Another member noted the difficulty in marketing the podcast format, which ebbs and flows between conversation and interview.
- I don’t know the right way to market was mentioned, pointing to potential challenges in promoting this unique format.
LlamaIndex ▷ #blog (7 messages):
OilyRAGsMulti-Agent WorkflowLocal RAG-augmented voice chatbotReport Generation WorkflowCreate Llama
-
OilyRAGs Wins Hackathon with AI Power: The AI-driven catalog OilyRAGs won 3rd place at the LlamaIndex hackathon, showcasing the effectiveness of Retrieval-Augmented Generation in transforming mechanical workflows. Check it out in action here and see its 6000% efficiency claim.
- This solution aims to facilitate tasks in the often labor-intensive field of mechanics.
- Comprehensive Tutorial on Multi-Agent Workflow: A detailed tutorial this weekend focuses on building an end-to-end (e2e) research agent with nested workflows for generating PowerPoint presentations. This human-in-the-loop approach enhances both research accuracy and presentation generation capabilities, available here.
- It's an excellent resource for anyone looking to streamline research processes.
- Fun and Functional RAG Chatbot: Introducing bb7, a local RAG-augmented voice chatbot that allows for document uploads and context-augmented conversations without external calls. It utilizes Text-to-Speech capabilities for seamless interactions, more info here.
- This tool highlights innovations in chatbot design focusing on user-friendly local interactions.
- Enhancing Report Generation with Human Oversight: A new notebook provides a framework for building a Multi-Agent Report Generation Workflow with human oversight, ensuring accuracy in long-form content creation. This human-in-the-loop model aims to establish reliability in research and content generation processes, details here.
- Such approaches are crucial for maintaining quality and correctness in automated systems.
- Spin Up a Financial Analyst with One Line of Code: With create-llama, you can spin up a full-stack financial analyst capable of filling in CSV files using a single line of code, fully open-source. Details about this multi-agent application and its capabilities can be found here.
- This represents a significant advancement in accessible AI tools for financial data management.
Link mentioned: GitHub - drunkwcodes/bb7: A TDD coding bot using ollama: A TDD coding bot using ollama. Contribute to drunkwcodes/bb7 development by creating an account on GitHub.
LlamaIndex ▷ #general (45 messages🔥):
Custom Agent CreationDiscord User InquiryCost Estimation for RAG PipelinesLlamaParse Object ParametersRAG Pipeline Visualization
-
Creating Custom Agents: A member inquired about how to build a custom agent with a specific reasoning loop using the agent runner and agent worker, prompting others to share helpful resources.
- Another member recommended skipping the agent worker/runner in favor of using workflows, providing a link to documentation.
- Discord User Inquiry for Pierre-Loic: A member sought the Discord contact information for Pierre-Loic, which led another member to directly mention the user.
- The inquiry was met with acknowledgment and gratitude for the information shared.
- Estimating RAG Pipeline Costs: Discussion arose on estimating costs for a RAG pipeline using OpenAIAgentRunner, with members clarifying that tool calls are billed differently from completion calls.
- Details were shared regarding how to calculate the average token count per message, emphasizing the use of a utility available in LlamaIndex.
- LlamaParse Object Configuration: A user queried about the appropriate arguments for a LlamaParse object to influence parsing instructions effectively, expressing frustration over non-functional results.
- Another member suggested checking the version and noted that the
parsing_instructionimpacts all content processed after OCR. - RAG Pipeline Visualization Tools: A member requested information on tools to visualize their RAG pipeline, sparking discussions about existing CLIs for enhancing file interactions.
- Some members reported encountering errors while querying with the existing CLI tools and noted that a bug might need addressing.
Links mentioned:
- RAG CLI - LlamaIndex: no description found
- LlamaIndex - LlamaIndex: no description found
- llama_index/llama-index-core/llama_index/core/question_gen/prompts.py at 369973f4e8c1d6928149f0904b25473faeadb116 · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Fixed the JSON Format of Generated Sub-Question (double curly brackets) by jeanyu-habana · Pull Request #16820 · run-llama/llama_index: This PR changes the default template for the question_gen LLM so that generated sub-questions are in correct JSON format. Description I am using the default template and default parser with an open...
- llama_index/llama-index-core/llama_index/core/utilities/token_counting.py at d4a31cf6ddb5dd7e2898ad3b33ff880aaa86de11 · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Building a Custom Agent - LlamaIndex: no description found
- Workflows - LlamaIndex: no description found
- Google Colab: no description found
LlamaIndex ▷ #ai-discussion (2 messages):
API Testing for Data AnalysisLlamaIndex Reader Experience
-
Test the New API for Data Analysis: A member invited others to test their new API, which is a faster and lightweight alternative to both OpenAI Assistant and Code Interpreter, built specifically for data analysis and visualizations.
- It promises to deliver either a CSV or an HTML chart, emphasizing its concise nature without unnecessary details; you can check it out here.
- Seeking LlamaIndex Readers for Call: Another member is looking for people with experience using LlamaIndex readers for a real-world business use case and is requesting a call to discuss potential outcomes.
- They expressed that feedback would be greatly appreciated and are asking interested members to reach out via direct messages.
Link mentioned: no title found: no description found
OpenInterpreter ▷ #general (34 messages🔥):
Open Interpreter issuesEven Realities G1 glassesBrilliant FramesAnthropic errorsMicrosoft Omniparser integration
-
Widespread Anthropic errors reported: Users expressed concerns over Anthropic errors and API issues related to the latest Claude model, particularly with the command
interpreter --model claude-3-5-sonnet-20240620.- One user noted a similar error, hinting at a trend affecting many.
- Exciting Launch of Even Realities G1 glasses: A member plugged the Even Realities G1 glasses as a potential tool for integrating with Open Interpreter, emphasizing their open-sourcing commitment.
- Others were intrigued, discussing the hardware capabilities and looking forward to potential plugin support in the future.
- Brilliant Frames interest: Members shared experiences about their upcoming Brilliant Frames, which are noted for being fully open source but speculative on aesthetic compatibility.
- One member is awaiting a replacement pair, expressing excitement about how they’ll work with Open Interpreter.
- Feature request for code output in Open-Interpreter: A user asked if there’s a way to make Open-Interpreter write code to a file instead of executing it directly, indicating challenges in achieving this with the given model.
- The community suggested using edit options and hinted at upcoming updates for better file handling in tool use.
- Interest in integrating Microsoft's Omniparser: One member raised the idea of integrating with Microsoft's Omniparser, asserting its potential benefits for Open Interpreter's operating system mode.
- This raised curiosity regarding its capabilities beyond just computer control with Claude.
Link mentioned: GitHub - even-realities/EvenDemoApp: Contribute to even-realities/EvenDemoApp development by creating an account on GitHub.
OpenInterpreter ▷ #ai-content (9 messages🔥):
Oasis AI ModelClaude 3.5 Haiku ReleaseDirect Access to O1 ModelPrice Increase for ClaudeOpenInterpreter Updates
-
Oasis: The First Fully AI-Generated Game: The team announced Oasis, the first playable, realtime, open-world AI model, marking a step towards complex interactive worlds.
- Players can interactively engage with the environment via keyboard inputs, showcasing real-time gameplay without a traditional game engine.
- Claude 3.5 Haiku Launches Beautifully: Claude 3.5 Haiku is now live on multiple platforms including the Anthropic API and Google Cloud's Vertex AI, promising the fastest and most intelligent experience yet.
- The model has reportedly surpassed Claude 3 Opus on many benchmarks while maintaining cost efficiencies, shared by @alexalbert__.
- Pricing Doubled for Enhanced Claude Model: In a surprising move, pricing for Claude 3.5 Haiku has been increased to reflect its newfound capabilities, as communicated by @AnthropicAI.
- The model's advancements were evident during final testing, which led to this strategic price adjustment.
- Direct Access to O1 Model Shared: A user shared that the O1 model could be accessed directly via a link before it seems to be patched now, indicating evolving accessibility concerns in the community.
- The previously available link allowed for file uploads and prompted a unique interaction framework, as detailed by multiple users.
- OpenInterpreter Updates: A new pull request highlighted updates including a profile for Claude Haiku 3.5, submitted by MikeBirdTech.
- The changes aim to improve the integration within the OpenInterpreter project, showcasing the continuous development in the repository.
Links mentioned:
- Oasis: no description found
- Tweet from Alex Albert (@alexalbert__): Claude 3.5 Haiku is now available on the Anthropic API, Amazon Bedrock, and Google Cloud's Vertex AI. Claude 3.5 Haiku is our fastest and most intelligent cost-efficient model to date. Here's...
- Tweet from Kol Tregaskes (@koltregaskes): ChatGPT o1 + image is out in the wild!!! Use this link https://chatgpt.com/?model=o1 Found via @Jaicraft39 in quote. Here is a quick test using one of my images (you've seen this image below in...
- Tweet from TestingCatalog News 🗞 (@testingcatalog): o1 next week? The o1 model (non-preview?) WAS accessible with file upload support! Now it seems to be patched. Pointing to o1 in the query directly allowed users to upload files and trigger the ...
- Tweet from Anthropic (@AnthropicAI): During final testing, Haiku surpassed Claude 3 Opus, our previous flagship model, on many benchmarks—at a fraction of the cost. As a result, we've increased pricing for Claude 3.5 Haiku to reflec...
- Haiku 3.5 profile by MikeBirdTech · Pull Request #1523 · OpenInterpreter/open-interpreter: Describe the changes you have made: Added profile for Claude Haiku 3.5 Reference any relevant issues (e.g. "Fixes #000"): Pre-Submission Checklist (optional but appreciated): I hav...
DSPy ▷ #show-and-tell (21 messages🔥):
Full Vision Support in DSPyVLM Use Case DiscussionsDocling Document Processing ToolCLI Manufacturing Plant ProgressMeeting Replay Request
-
Full Vision Support in DSPy: A member celebrated the successful merge of Pull Request #1495 that adds Full Vision Support to DSPy, marking a significant milestone.
- It's been a long time coming, expressing appreciation for the teamwork involved.
- Exploring VLM Use Cases: Members discussed potential VLM use cases including extracting structured outputs from screenshot images, focusing on attributes like colors, fonts, and call to action.
- One member promised to share a suitable dataset from Hugging Face by end of day.
- Introduction of Docling for Data Preparation: A member introduced Docling, a document processing library that can convert various formats into structured JSON/Markdown outputs for DSPy workflows.
- They highlighted key features including OCR support for scanned PDFs and integration capabilities with LlamaIndex and LangChain.
- Progress on CLI Manufacturing Plant: A developer is initiating work on a CLI manufacturing plant aimed at enhancing the official DSPy CLI capabilities, sharing progress through updates.
- This project aims to improve the DSPy ecosystem, emphasizing the importance of the incremental build process.
- Request for Meeting Replay: A member requested a replay of the previous meeting to catch up on discussions, recognizing that the content may soon be outdated.
- Another member mentioned they would share progress updates and establish a GPT tool for organizing requests.
Links mentioned:
- Building a CLI with DSPy: https://github.com/seanchatmangpt/dslmodel In this video, I demonstrate the process of creating a Command Line Interface (CLI) using DSPy. I discuss the need for an official CLI, provide insights int...
- naorm/website-screenshots · Datasets at Hugging Face: no description found
- Adapter Implementation of MM inputs in OAI friendly format by isaacbmiller · Pull Request #1495 · stanfordnlp/dspy: Adds Image multimodal support. Main changes are the following: Changes the parsing structure such that messages are first compiled as a list of Dicts that look like {"role": &q...
DSPy ▷ #general (19 messages🔥):
Contribution opportunitiesSTORM module modificationsOutput field manipulation in signaturesFew-shot optimization techniquesVLM support updates
-
Contribution opportunities for small issues: A member announced that small issues needing help will start to be posted in a specific channel, inviting contributions.
- They encouraged members to check out a recent issue that was posted for assistance.
- Modifications suggested for STORM module: A member shared their understanding of the STORM module, specifically suggesting improvements to utilize the table of contents effectively.
- They proposed generating articles section by section based on the TOC and incorporating private information to enhance outputs.
- Forcing output fields in signatures: A member inquired about how to force an output field in a signature to return existing features instead of generating new ones.
- Another member provided a solution by outlining a function that correctly returns the features as part of the output.
- Optimizing few-shot examples without modifying prompts: A member asked if there is a way to optimize only the few-shot examples while keeping the prompt intact.
- Recommendations were made to use either BootstrapFewShot or BootstrapFewShotWithRandomSearch optimizers to achieve this.
- VLM support is progressing well: A member praised the VLM support functionality, highlighting its effectiveness.
- They acknowledged the efforts of the team contributing to this improvement.
Links mentioned:
- BootstrapFewShot - DSPy: None
- Storm/conversation_module.py at main · jmanhype/Storm: Contribute to jmanhype/Storm development by creating an account on GitHub.
tinygrad (George Hotz) ▷ #general (17 messages🔥):
PR #7477 Tests FixCompany Meeting UpdatesWebGPU DiscussionCode Refactoring EffortsALU Usage in Tests
-
PR #7477 requires test fixes: A member asked for assistance in fixing the tests for this PR, suggesting it's a good first task.
- Can someone finish fixing up the tests for this?
- Company meeting briefs at 8 PM: Members confirmed a company meeting at 8 PM Hong Kong time, covering topics like operations cleanup and active bounties.
- Main points of discussion included MLPerf updates, graph architecture, and progress on drivers.
- WebGPU's future potential: Discussion arose around the readiness of WebGPU, with suggestions to consider its implementation once it's ready.
- One member mentioned, when WebGPU is ready, we can consider that.
- Code size optimization efforts: A participant reported removing around 100 lines from the code, although the total size didn't change significantly.
- Despite minimal size improvement, they noted there were still some nice wins from the refactoring efforts.
- Need to update tests without ALU: A member requested the removal of a line from the Tinygrad codebase and indicated the need to adjust tests to not rely on ALU.
- They provided a link for reference: tinygrad/ops.py.
Links mentioned:
- idx_load_store in lowerer [pr] by geohot · Pull Request #7477 · tinygrad/tinygrad: Can someone finish fixing up the tests for this?
- no None in ei [pr] by geohot · Pull Request #7086 · tinygrad/tinygrad: no description found
- tinygrad/tinygrad/ops.py at master · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
tinygrad (George Hotz) ▷ #learn-tinygrad (20 messages🔥):
Apache TVM FeaturesResource Errors in DockerMobileNetV2 Implementation IssuesFake PyTorch Backend DevelopmentOasis AI Model Release
-
Apache TVM framework capabilities: The Apache TVM project aims to optimize machine learning models for various hardware platforms, with features including model compilation and backend optimizations.
- Members discussed its role in supporting platforms like ONNX, Hailo, and OpenVINO.
- Blocking IO Error in Docker setup: A user encountered a BlockingIOError stating 'Resource temporarily unavailable' while running a speed test on a Docker setup with RTX 4090 GPUs.
- Discussion indicated it might relate to Docker configurations, prompting members to confirm whether others experienced similar issues.
- MobileNetV2 not processing gradients: A user requested help with implementing MobileNetV2, citing issues with the optimizer not calculating gradients properly.
- Continued discussion revolved around their experimentation results and troubleshooting efforts.
- Developing a 'Fake PyTorch': A member shared their progress on a 'Fake PyTorch' wrapper that uses tinygrad as the backend, working on basic features but lacking advanced functionalities.
- They provided a link to their code repository, inviting feedback and curiosity about their approach.
- Release of Oasis AI Model: Announcement of Oasis, an open-source realtime AI model capable of generating playable gameplay and interactions using keyboard inputs.
- The team released code and weights for a 500M parameter model, emphasizing its capacity for real-time video generation with future plans for enhanced performance.
Links mentioned:
- Apache TVM: no description found
- GitHub - mdaiter/open-oasis at tinygrad: Inference script for Oasis 500M. Contribute to mdaiter/open-oasis development by creating an account on GitHub.
- Oasis: no description found
- TRANSCENDENTAL=2 Tensor([11], dtype='half').exp() returns inf · Issue #7421 · tinygrad/tinygrad: TRANSCENDENTAL=2 METAL=1 python -c "from tinygrad import Tensor; print(Tensor([11], dtype='half').exp().float().item())" same inf for METAL/AMD/NV. CLANG and LLVM gives the correct ~...
- tinygrad-stuff: Porting common neural network architectures, features, etc. to tinygrad
OpenAccess AI Collective (axolotl) ▷ #general (8 messages🔥):
Instruct Datasets for Meta Llama 3.1Catastrophic Forgetting in Fine-TuningGranite 3.0 Model EvaluationDistributed Training of LLMsRAG vs Fine-Tuning Approach
-
Seeking Quality Instruct Datasets for Llama 3.1: A member inquired about high-quality instruct datasets in English to fine-tune Meta Llama 3.1 8B, aiming to combine with domain-specific Q&A.
- They expressed a preference for maximizing performance through fine-tuning over using LoRA methods.
- Experiencing Catastrophic Forgetting: The member running the fine-tuning process reported experiencing catastrophic forgetting with their model.
- Another member suggested that for certain applications, RAG (Retrieval-Augmented Generation) might be more effective than training a model.
- Granite 3.0 as an Alternative: A suggestion was made to consider Granite 3.0, which claims to benchmark higher than Llama 3.1 and has a fine-tuning methodology to avoid forgetting.
- Additionally, Granite 3.0 is mentioned to be Apache-licensed, providing more flexibility.
- Distributed Training Resources for LLMs: Another user started a research project at their university aiming to leverage a fleet of GPUs for distributed training of LLMs.
- They specifically asked for resources on training bespoke models from scratch rather than focusing on fine-tuning.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (11 messages🔥):
Inference script chat formatInference mismatch issueFine-tuning Llama 3 on GPUsZero1 vs Zero2 optimization
-
Inference script lacks chat format support: Members noted that the current inference script does not support chat format, taking only plain text and prepending a begin_of_text token during generation.
- This design causes a mismatch with training, prompting discussions on its implications and the desire to improve the README.
- Issue raised for chat model inference mismatch: A member opened an issue on GitHub regarding the mismatch between training and inference for chat models, detailing concerns and expected behavior.
- The issue can be viewed here, which highlights the need for attention as it might have been overlooked.
- Challenges fine-tuning Llama 3 on H100s: Inquiries were made on the feasibility of fine-tuning Llama 3 8B using 8xH100s, specifically concerning out-of-memory (OOM) issues at a context length of 8192.
- It appears most users will prefer fine-tuning with this context length, although challenges remain prevalent.
- Resolving OOM with Zero2 optimization: A member reported resolving their OOM issue using Zero2 but wondered if similar success could be achieved with Zero1, suspecting excessive bloat in the code.
- They acknowledged their runs are currently smaller and plan to investigate how much slower their performance is with Zero2 in the next steps.
Link mentioned: Mismatch between training & inference for chat modesl in do_inference · Issue #2014 · axolotl-ai-cloud/axolotl: Please check that this issue hasn't been reported before. I searched previous Bug Reports didn't find any similar reports. Expected Behavior There is mismatch bewteen how chat models are train...
OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
Aloe BetaOpen healthcare LLMsAxolotl SFT phase
-
Introducing Aloe Beta: Healthcare LLMs are here!: We've just released Aloe Beta, a family of fine-tuned open healthcare LLMs, marking a significant milestone in AI healthcare solutions. To learn more about this exciting development, check it out here.
- The SFT phase for Aloe was conducted using axolotl, showcasing a novel approach to training healthcare models.
- Aloe Beta's SFT Phase Highlights: The development of Aloe Beta involved a meticulous SFT phase using axolotl to fine-tune the models specifically for healthcare applications. This process ensured that the models are well-equipped to handle various healthcare-related tasks effectively.
- Team members expressed excitement about the potential applications of Aloe in improving access to healthcare solutions and enhancing user experience.
LAION ▷ #general (6 messages):
Adding CLS tokensSharky blob developmentDownsampling latentsInference API standardizationADs server issues
-
Adding 32 CLS tokens stabilizes training: A member noted that introducing 32 CLS tokens significantly stabilizes the training process.
- This adjustment reportedly improves training reliability, enhancing outcomes considerably.
- Vaguely sharkish blob is getting sharkier: There was a discussion about a vaguely sharkish blob that is evolving further into a more pronounced shark shape.
- This transformation has been described amusingly, suggesting interesting progress in its development.
- Challenges with downsampling latents: A member questioned whether bilinear interpolation is suitable for downsampling latents in latent space, noting the results appear blurry.
- This inquiry highlighted concerns about the effectiveness of current methods in achieving clear results.
- Standardizing inference APIs: Developers of Aphrodite, AI Horde, and Koboldcpp have agreed on a standard to assist inference integrators in recognizing APIs for seamless integration.
- This new standard is live on platforms like AI Horde and efforts are being made to onboard more APIs, encouraging collaboration with additional developers.
- ADs server going brrr: A light-hearted comment was made regarding the ADs server, likening its performance to 'going brrr', implying it’s operating rapidly.
- This reflects a humorous take on the current operations or speeds associated with the server's functioning.
Links mentioned:
- Lana Del Rey in Blue Velvet (1986) - David Lynch: Changing the lead character…Blue Velvet (1986)Written and directed by David LynchStarring Lana Del Rey as Dorothy VallensKyle McLachlan as Jeffrey BeaumontDe...
- serviceinfo: A crowdsourced distributed cluster for AI art and text generation - Haidra-Org/AI-Horde
- Issues · comfyanonymous/ComfyUI: The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface. - Issues · comfyanonymous/ComfyUI
- Add .well-known/serviceinfo endpoint · Issue #2257 · lllyasviel/stable-diffusion-webui-forge: The developers of the AI Horde, koboldcpp and aphrodite just agreed for a standard which would allow inference integrators to our APIs to quickly retrieve the information about the API they are wor...
LAION ▷ #research (6 messages):
RAR Image GeneratorPosition Embedding ShuffleNLP Implications
-
RAR Achieves State-of-the-Art FID Score: The RAR image generator boasts a FID score of 1.48, showing exceptional performance on the ImageNet-256 benchmark while using a randomness annealing strategy that enhances bidirectional context learning.
- It achieves this state-of-the-art performance without additional cost, outperforming previous autoregressive image generators.
- Position Embedding Shuffle Challenges: A proposal emerged to shuffle the position embeddings at the beginning of training, gradually decreasing this effect to 0% by the end.
- While it simplifies the method, a member noted that the implementation is a bit more complex than initially thought.
- Questioning NLP Application of Shuffling: A discussion arose regarding whether the position embedding shuffle technique could be effective for NLP tasks, raising skepticism about its applicability.
- One member expressed their intuition that this probably won't work since text tokens carry less initial information than image tokens.
Link mentioned: Randomized Autoregressive Visual Generation: no description found
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
OpenAI API SetupLambda Labs Access
-
Deadline for API Setup Approaches!: Teams are reminded to set up their APIs for OpenAI and Lambda Labs by End of Day Monday, 11/4.
- Failure to do so may impact access to resources, and submission can be done via this form.
- Ensure Early Credit Awards!: Early API setup will enable credits to be awarded to teams from OpenAI next week, ensuring smooth participation.
- This step is crucial for accessing the Lambda inference endpoint throughout the hackathon.
- Resource Details Available: More information regarding the available resources can be found in the document linked here.
- Teams are encouraged to review this document to fully understand what resources are provided.
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Project GR00TJim FanNVIDIA roboticsGeneralist Agents
-
Project GR00T: A Blueprint for Generalist Robotics: Today at 3:00pm PST, Jim Fan will present on Project GR00T, NVIDIA's initiative to build AI brains for humanoid robotics during the livestream here.
- As the Research Lead of GEAR, he emphasizes their mission to develop generally capable AI agents in various settings.
- Jim Fan's Expertise and Achievements: Dr. Jim Fan has a notable background with a Ph.D. from Stanford Vision Lab and received the Outstanding Paper Award at NeurIPS 2022 for his influential research. His work includes multimodal models for robotics and AI agents that excel at playing Minecraft.
- His contributions have been recognized in major media outlets like New York Times and MIT Technology Review.
- Course Resources Available Online: All course materials, including livestream URLs and homework assignments, are accessible on the course website: llmagents-learning.org.
- Participants are encouraged to ask questions in <#1280370030609170494>.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (8 messages🔥):
LLM Agents HackathonStudy GroupsCompute Resources AccessTeam FormationCourse Announcements
-
LLM Agents Hackathon Information: A member shared a link to sign up for the LLM Agents Hackathon, emphasizing its importance for prospective students.
- Participants were encouraged to explore the details and join the community for discussions on the project.
- Formation of Study Groups: A member suggested forming a study group while making notes from slides and watching videos one by one, offering collaboration on quizzes.
- Another member agreed, stating that this collaborative effort could be really helpful.
- Query about Compute Resources Access: A member inquired about the timeline for gaining access to compute resources, having requested them roughly a week ago.
- Another participant noted that access depends on the specific resources requested and indicated that access should be available early this week.
- Team Formation for Hackathon: A user asked where to find teams for the hackathon, seeking collaboration opportunities.
- An existing response included a link to a form for team applications, outlining goals for innovative LLM-based agents.
- Positive Feedback on Talks: A member complimented a talk delivered by Jim, expressing appreciation for the discussion.
- This highlights an ongoing engagement and interest in the talks given within the course context.
Links mentioned:
- Large Language Model Agents MOOC: MOOC, Fall 2024
- LLM Agents MOOC Hackathon - Team Signup Form: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
Polygonia interrogationisMoth identification
-
Confusion over Polygonia interrogationis classification: A member questioned the classification of Polygonia interrogationis, suspecting it to be a moth despite being referred to as a butterfly.
- The discussion highlights the need for accurate insect identification, especially when sharing information in a collaborative environment.
- Need for precise insect identification: The inquiry underscores the ongoing challenges in classifying certain species, particularly when it comes to moths and butterflies.
- It emphasizes the importance of clear communication and accurate information in community discussions about entomology.
Cohere ▷ #discussions (7 messages):
Manual Simulation of ChatGPT SearchingFuture of Browsing and ChatbotsAugmented Reality in Information Access
-
Exploring Manual Simulation of ChatGPT's Browsing: A member in R&D is investigating if one can manually simulate ChatGPT's browsing by tracking search terms and results, comparing it to human searches.
- This approach aims to analyze factors like SEO impact and how ChatGPT filters and ranks up to 100+ results efficiently.
- Anticipating Future Chatbot Capabilities: Discussion sparked about the potential of chatbots like ChatGPT replacing traditional web browsers, acknowledging the challenge of predicting the future.
- One participant recalled how past visions of technology like video calling were far from what we experience today, highlighting the unpredictability of technological advances.
- Considering Augmented Reality as a Game Changer: A member noted that while everyone envisions a browserless environment, augmented reality might revolutionize information access with constant updates.
- This perspective expands the discussion beyond chat interfaces to potentially transformative technologies in how we interact with information.
- Nature of Search in AI Contexts: One participant emphasized that search functionalities remain an outside process for AI, typical of tool invocation rather than intrinsic AI behavior.
- They pointed out that the management of search flows is entirely up to the user, reiterating the importance of how AI tools are utilized.
Cohere ▷ #api-discussions (4 messages):
Cohere APIChannel PurposeCommunity Engagement
-
Cohere API Questions Misplaced: A member cautioned against asking general questions in this channel, stating that it is specifically for inquiries about Cohere's API.
- They suggested that the relevant channel for such questions is <#954421988783444043>.
- Community Interest in AI: Another member acknowledged their mistake in asking elsewhere and humorously noted that they see plenty of AI interest among users.
- They expressed intent to direct their questions appropriately in the future.
Torchtune ▷ #general (6 messages):
Torchtune Weight GatheringCheckpointing IssuesDistributed CheckpointingLlama 90B Pull Request
-
Torchtune Stage3 Gathering Equivalent Inquiry: A member inquired if there is an equivalent in Torchtune for the DeepSpeed parameter
"stage3_gather_16bit_weights_on_model_save": false. This is related to troubleshooting issues experienced during multi-node finetuning.- One response clarified that setting this flag to false facilitates distributed/sharded checkpointing, meaning each rank only saves its own shard.
- Checkpointing Constraints in Distributed Training: Concerns were raised regarding the checkpoints sticking during training, specifically with rank 0 exhausting its VRAM.
- One user confirmed the necessity of using an external script after training to retrieve the final weights.
- Recent Fixes in Torchtune: A member communicated that checkpoints in Torchtune were recently addressed by adding barriers to prevent them from hanging.
- They noted a related issue with saving a 90B checkpoint, where rank 0 experienced hanging issues.
- Llama 90B Integration Discussion: A pull request was shared regarding the integration of Llama 90B into Torchtune, aimed at resolving specific bugs.
- The PR #1880 provides context on the enhancements made related to checkpointing.
Link mentioned: Llama 3.2 Vision - 90B by felipemello1 · Pull Request #1880 · pytorch/torchtune: Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) This PR adds llama 90B to torchtune. A few issues were f...
Torchtune ▷ #dev (5 messages):
Gradient Norm ClippingDuplicate Compile Key in ConfigForwardKLLoss Misconception
-
Gradient Norm Clipping Process Explained: To compute the correct gradient norm, a reduction (sum) across L2 norms of all per-parameter gradients is needed, but this cannot be used for current optimizer steps.
- It may be possible to clip gradient norms in the next iteration, but this alters the original gradient clipping logic.
- Duplicate Compile Key Issues in Torchtune Config: A member found a duplicate
compilekey in the configuration file llama3_1/8B_full.yaml, causing it to fail running.
- There is uncertainty if other configuration files have similar issues.
- ForwardKLLoss Actually Computes Cross-Entropy: The
ForwardKLLossin Torchtune computes cross-entropy rather than KL-divergence as expected, requiring an adjustment to expectations.
- The distinction is important since optimizing KL-divergence effectively means optimizing cross-entropy due to the presence of constant terms.
- Consider Renaming ForwardKLLoss for Clarity: There was agreement on the concern regarding the naming of
ForwardKLLoss, as it could lead to confusion among users.
- It was noted that similar naming practices are utilized in DistiLLM, highlighting the need for clarity when experimenting with
kd_ratiovalues.
Links mentioned:
- torchtune/recipes/configs/llama3_1/8B_full.yaml at main · pytorch/torchtune: PyTorch native finetuning library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/torchtune/modules/loss/kd_losses.py at e861954d43d23f03f2857b0556916a8431766d5d · pytorch/torchtune: PyTorch native finetuning library. Contribute to pytorch/torchtune development by creating an account on GitHub.
Alignment Lab AI ▷ #announcements (1 messages):
Aphrodite Windows SupportPagedAttention ImplementationHigh-throughput local AI
-
Aphrodite introduces Windows support: The Aphrodite engine now supports Windows in an experimental phase, allowing users to enjoy high-throughput local AI optimized for NVIDIA GPUs. For installation, you can check the guide here.
- Preliminary benchmarks show no performance degradation compared to Linux, demonstrating its capability to host AI endpoints effectively.
- Performance metrics and features of Aphrodite: Aphrodite features support for most quantization methods and includes custom options that can outperform larger models, handling parallelism and providing detailed performance metrics. It also supports various sampling options and structured outputs, enhancing usability.
- The support on AMD and Intel compute is confirmed, but Windows support remains untested.
- Thanks to the coding dedication behind Aphrodite: Acknowledgments go to AlpinDale for their significant contributions, especially regarding the Windows support implementation. Community members are encouraged to express their gratitude through retweets and support.
- This collaboration aims to further enhance the open-source AI experience for users looking for efficient inference solutions.
Links mentioned:
- Tweet from Alignment Lab AI (@alignment_lab): ANNOUNCING: Windows Support for Aphrodite (Experimental) [Installation Guide] https://github.com/PygmalionAI/aphrodite-engine/blob/main/docs/pages/installation/installation-windows.md Enjoy your e...
- Tweet from Alpin (@AlpinDale): Experimental Windows support has landed in Aphrodite. You can now use a performant implementation of PagedAttention on Windows w/ NVIDIA GPUs! It's still in the testing phase and there might be is...
Alignment Lab AI ▷ #general (2 messages):
LLMs for auto-patching vulnerabilitiesSelf Healing Code blog postGenerative AI innovationsPodcast discussions
-
LLMs are revolutionizing vulnerability patching: A member shared a new blog post on self-healing code that explores how LLMs assist in automatically fixing buggy and vulnerable software.
- The author highlighted that 2024 marks a pivotal year where LLMs are beginning to tackle auto-patching vulnerabilities.
- Listen up with the LLMs Podcast: For auditory learners, there's a podcast where two LLMs discuss the insights from the blog post on Spotify and Apple Podcast.
- This allows listeners to engage with the content in a conversational format while gaining insights into auto-healing software technologies.
- Future of resilient software is here: The post imagines a future where software can autonomously repair itself, akin to how our bodies heal, leading to truly resilient systems.
- The discussion emphasized that we are already starting to witness the first signs of this potential in current technologies.
- Six approaches to tackle auto-patching: The author outlined six approaches teams can take to address the challenge of auto-patching, noting that two are already available as products, while four are still in research.
- This indicates a blend of practical solutions and innovative research aimed at advancing auto-patching technologies.
Link mentioned: Self Healing Code – D-Squared: no description found
MLOps @Chipro ▷ #events (1 messages):
Learning on Graphs ConferenceGraph Machine LearningLocal Meetups
-
Learning on Graphs Conference in Delhi: The Learning on Graphs (LoG) Conference will take place in New Delhi from 26 - 29 November 2024, focusing on advancements in machine learning on graphs.
- This first-ever South Asian chapter is hosted by IIT Delhi and Mastercard. More information can be found here.
- Connecting innovators in graph learning: The conference aims to connect innovative thinkers and industry professionals in the graph learning space for insightful discussions.
- The event encourages participants from diverse fields such as computer science, biology, and social science to engage with one another.
- Opportunities for Local Meetups: The LoG community is organizing a network of local mini-conferences to foster discussions and collaborations among participants in similar geographic areas.
- A call for local meetups for LoG 2024 is still open, aiming to enhance social experiences during the main event.
- Community Engagement and Resources: Participants can join the conference community on Slack and follow the event updates on Twitter.
- Recordings and materials from past conferences are available on YouTube.
Links mentioned:
- LoG New Delhi 2024: Join us and help connect the nodes of innovation in the graph learning space!
- Learning on Graphs Conference: Learning on Graphs Conference
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
Benchmarking function callingRetrieval based approachFunction definitions
-
Call for Function Definitions for Benchmarking: A member is working on benchmarking a retrieval based approach to function calling and is seeking a collection of available functions and their definitions for indexing.
- They specifically mentioned that having this information organized per test category would be extremely helpful.
- Need for Organized Function Collections: The discussion highlights a demand for a structured collection of function definitions that can aid in function calling benchmarks.
- Clarifying information by test category would enhance accessibility and usability for those conducting similar work.