[AINews] Llama 3.2: On-device 1B/3B, and Multimodal 11B/90B (with AI2 Molmo kicker)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
9000:1 token:param ratios are all you need.
AI News for 9/24/2024-9/25/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (223 channels, and 3218 messages) for you. Estimated reading time saved (at 200wpm): 316 minutes. You can now tag @smol_ai for AINews discussions!
Big news from Mira Murati and FB Reality Labs today, but the actual technical news you can use today is Llama 3.2:

As teased by Zuck and previewed in the Llama 3 paper (our coverage here), the Multimodal versions of Llama 3.2 released as anticipated, adding a 3B and a 20B vision adapter on a frozen Llama 3.1:

The 11B is comparable/slightly better than Claude Haiku, and the 90B is comparable/slightly better than GPT-4o-mini, though you will have to dig a lot harder to find out how far it trails behind 4o, 3.5 Sonnet, 1.5 Pro, and Qwen2-VL with a 60.3 on MMMU.
Meta is being praised for their open source here, but don't miss the multimodal Molmo 72B and 7B models from AI2 also releasing today. It has not escaped /r/localLlama's attention that Molmo is outperforming 3.2 in vision:

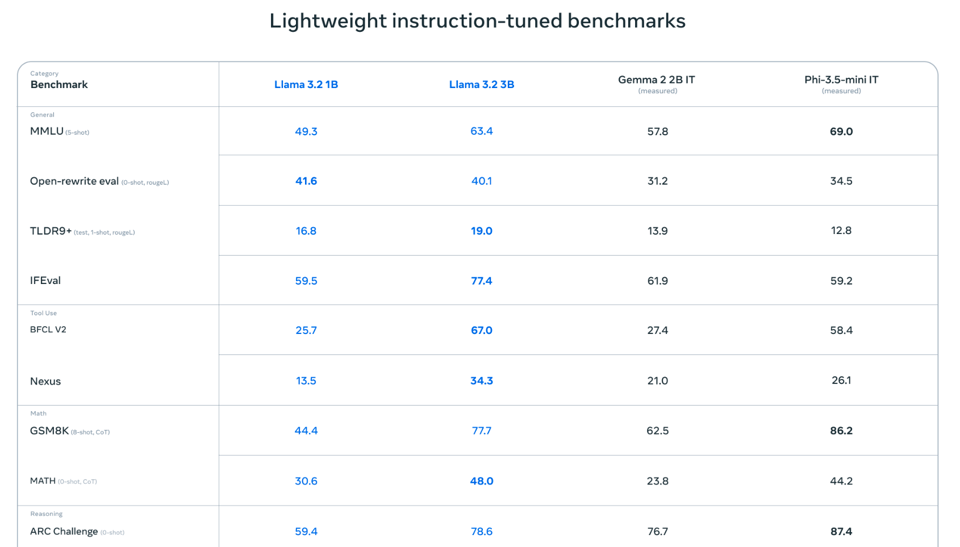
The bigger/pleasant/impressive surprise from Meta are the new 128k-context 1B and 3B models, which noew compete with Gemma 2 and Phi 3.5:
The release notes hint at some very tight on device collaborations with Qualcomm, Mediatek, and Arm:
The weights being released today are based on BFloat16 numerics. Our teams are actively exploring quantized variants that will run even faster, and we hope to share more on that soon.
Don't miss:
- launch blogpost
- Followup technical detail from @AIatMeta disclosing a 9 trillion token count for Llama 1B and 3B, and quick arch breakdown from Daniel Han
- updated HuggingFace collection including Evals
- the Llama Stack launch (see RFC here)
Partner launches:
- Ollama
- Together AI (offering FREE 11B model access rate limited to 5 rpm until end of year)
- Fireworks AI
This issue sponsored by RAG++: a new course from Weights & Biases. Go beyond RAG POCs and learn how to evaluate systematically, use hybrid search correctly and give your RAG system access to tool calling. Based on 18 months of running a customer support bot in production, industry experts at Weights & Biases, Cohere, and Weaviate show how to get to a deployment-grade RAG app. Includes free credits from Cohere to get you started!
Swyx commentary: Whoa, 74 lessons in 2 hours. I've worked on this kind of very tightly edited course content before and it's amazing that this is free! Chapters 1-2 cover some necessary RAG table stakes, but then it was delightful to see Chapter 3 teach important ETL and IR concepts, and learn some new things on cross encoding, rank fusion, and query translation in 4 and 5. We shall have to cover this on livestream soon!
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- HuggingFace Discord
- Nous Research AI Discord
- aider (Paul Gauthier) Discord
- OpenRouter (Alex Atallah) Discord
- OpenAI Discord
- LM Studio Discord
- Eleuther Discord
- Perplexity AI Discord
- Interconnects (Nathan Lambert) Discord
- GPU MODE Discord
- OpenAccess AI Collective (axolotl) Discord
- Cohere Discord
- LlamaIndex Discord
- Latent Space Discord
- Stability.ai (Stable Diffusion) Discord
- Torchtune Discord
- Modular (Mojo 🔥) Discord
- OpenInterpreter Discord
- LLM Agents (Berkeley MOOC) Discord
- DSPy Discord
- tinygrad (George Hotz) Discord
- LangChain AI Discord
- LAION Discord
- PART 2: Detailed by-Channel summaries and links
- Unsloth AI (Daniel Han) ▷ #general (510 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (42 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (52 messages🔥):
- HuggingFace ▷ #announcements (1 messages):
- HuggingFace ▷ #general (432 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (7 messages):
- HuggingFace ▷ #cool-finds (12 messages🔥):
- HuggingFace ▷ #i-made-this (125 messages🔥🔥):
- HuggingFace ▷ #computer-vision (3 messages):
- HuggingFace ▷ #NLP (12 messages🔥):
- HuggingFace ▷ #diffusion-discussions (4 messages):
- Nous Research AI ▷ #announcements (1 messages):
- Nous Research AI ▷ #general (214 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (25 messages🔥):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #interesting-links (2 messages):
- Nous Research AI ▷ #research-papers (2 messages):
- aider (Paul Gauthier) ▷ #general (95 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (104 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (4 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (169 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (2 messages):
- OpenAI ▷ #ai-discussions (110 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (8 messages🔥):
- OpenAI ▷ #prompt-engineering (24 messages🔥):
- OpenAI ▷ #api-discussions (24 messages🔥):
- LM Studio ▷ #general (145 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (17 messages🔥):
- Eleuther ▷ #general (19 messages🔥):
- Eleuther ▷ #research (70 messages🔥🔥):
- Eleuther ▷ #scaling-laws (9 messages🔥):
- Eleuther ▷ #interpretability-general (1 messages):
- Eleuther ▷ #lm-thunderdome (40 messages🔥):
- Eleuther ▷ #multimodal-general (1 messages):
- Perplexity AI ▷ #general (123 messages🔥🔥):
- Perplexity AI ▷ #sharing (6 messages):
- Perplexity AI ▷ #pplx-api (9 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (32 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (15 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (24 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (22 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (8 messages🔥):
- Interconnects (Nathan Lambert) ▷ #rl (2 messages):
- Interconnects (Nathan Lambert) ▷ #posts (25 messages🔥):
- GPU MODE ▷ #torch (22 messages🔥):
- GPU MODE ▷ #cool-links (17 messages🔥):
- GPU MODE ▷ #jobs (2 messages):
- GPU MODE ▷ #beginner (12 messages🔥):
- GPU MODE ▷ #torchao (1 messages):
- GPU MODE ▷ #off-topic (16 messages🔥):
- GPU MODE ▷ #triton-puzzles (3 messages):
- GPU MODE ▷ #llmdotc (13 messages🔥):
- GPU MODE ▷ #rocm (6 messages):
- GPU MODE ▷ #bitnet (2 messages):
- GPU MODE ▷ #arm (4 messages):
- GPU MODE ▷ #webgpu (1 messages):
- GPU MODE ▷ #liger-kernel (23 messages🔥):
- GPU MODE ▷ #metal (2 messages):
- GPU MODE ▷ #self-promotion (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (82 messages🔥🔥):
- OpenAccess AI Collective (axolotl) ▷ #general-help (9 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (5 messages):
- Cohere ▷ #discussions (52 messages🔥):
- Cohere ▷ #questions (6 messages):
- Cohere ▷ #api-discussions (15 messages🔥):
- Cohere ▷ #projects (11 messages🔥):
- LlamaIndex ▷ #announcements (1 messages):
- LlamaIndex ▷ #blog (5 messages):
- LlamaIndex ▷ #general (74 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (76 messages🔥🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (66 messages🔥🔥):
- Torchtune ▷ #announcements (1 messages):
- Torchtune ▷ #general (29 messages🔥):
- Torchtune ▷ #dev (9 messages🔥):
- Modular (Mojo 🔥) ▷ #general (4 messages):
- Modular (Mojo 🔥) ▷ #announcements (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (21 messages🔥):
- OpenInterpreter ▷ #general (12 messages🔥):
- OpenInterpreter ▷ #ai-content (5 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (13 messages🔥):
- DSPy ▷ #show-and-tell (2 messages):
- DSPy ▷ #general (5 messages):
- DSPy ▷ #examples (3 messages):
- tinygrad (George Hotz) ▷ #general (9 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
- LangChain AI ▷ #general (8 messages🔥):
- LangChain AI ▷ #share-your-work (1 messages):
- LAION ▷ #general (1 messages):
- LAION ▷ #research (7 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Advanced Voice Model Release
- OpenAI is rolling out an advanced voice model for ChatGPT Plus and Team users over the course of a week.
- @sama announced: "advanced voice mode rollout starts today! (will be completed over the course of the week)hope you think it was worth the wait 🥺🫶"
- @miramurati confirmed: "All Plus and Team users in ChatGPT"
- @gdb noted: "Advanced Voice rolling out broadly, enabling fluid voice conversation with ChatGPT. Makes you realize how unnatural typing things into a computer really is:"
The new voice model features lower latency, the ability to interrupt long responses, and support for memory to personalize responses. It also includes new voices and improved accents.
Google's Gemini 1.5 Pro and Flash Updates
Google announced significant updates to their Gemini models:
- @GoogleDeepMind tweeted: "Today, we're excited to release two new, production-ready versions of Gemini 1.5 Pro and Flash. 🚢They build on our latest experimental releases and include significant improvements in long context understanding, vision and math."
- @rohanpaul_ai summarized key improvements: "7% increase in MMLU-Pro benchmark, 20% improvement in MATH and HiddenMath, 2-7% better in vision and code tasks"
- Price reductions of over 50% for Gemini 1.5 Pro
- 2x faster output and 3x lower latency
- Increased rate limits: 2,000 RPM for Flash, 1,000 RPM for Pro
The models can now process 1000-page PDFs, 10K+ lines of code, and hour-long videos. Outputs are 5-20% shorter for efficiency, and safety filters are customizable by developers.
AI Model Performance and Benchmarks
- OpenAI's models are leading in various benchmarks:
- @alexandr_wang reported: "OpenAI's o1 is dominating SEAL rankings!🥇 o1-preview is dominating across key categories:- #1 in Agentic Tool Use (Enterprise)- #1 in Instruction Following- #1 in Spanish👑 o1-mini leads the charge in Coding"
- Comparisons between different models:
- @bindureddy noted: "Gemini's Real Superpower - It's 10x Cheaper Than o1!The new Gemini is live on ChatLLM teams if you want to play with it."
AI Development and Research
- @alexandr_wang discussed the phases of LLM development: "We are entering the 3rd phase of LLM Development.1st phase was early tinkering, Transformer to GPT-32nd phase was scaling3rd phase is an innovation phase: what breakthroughs beyond o1 get us to a new proto-AGI paradigm"
- @JayAlammar shared insights on LLM concepts: "Chapter 1 paves the way for understanding LLMs by providing a history and overview of the concepts involved. A central concept the general public should know is that language models are not merely text generators, but that they can form other systems (embedding, classification) that are useful for problem solving."
AI Tools and Applications
- @svpino discussed AI-powered code reviews: "Unpopular opinion: Code reviews are dumb, and I can't wait for AI to take over completely."
- @nerdai shared an ARC Task Solver that allows humans to collaborate with LLMs: "Using the handy-dandy @llama_index Workflows, we've built an ARC Task Solver that allows humans to collaborate with an LLM to solve these ARC Tasks."
Memes and Humor
- @AravSrinivas joked: "Should I drop a wallpaper app ?"
- @swyx humorously commented on the situation: "guys stop it, mkbhd just uploaded the wrong .IPA file to the app store. be patient, he is recompiling the code from scratch. meanwhile he privately dm'ed me a test flight for the real mkbhd app. i will investigate and get to the bottom of this as a self appointed auror for the wallpaper community"
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. High-Speed Inference Platforms: Cerebras and MLX
- Just got access to Cerebras. 2,000 token per second. (Score: 99, Comments: 39): The Cerebras platform has demonstrated impressive inference speeds, achieving 2,010 tokens per second with the Llama3.1-8B model and 560 tokens per second with the Llama3.1-70B model. The user expresses amazement at this performance, indicating they are still exploring potential applications for such high-speed inference capabilities.
- JSON outputs are supported by the Cerebras platform, as confirmed by the original poster. Access to the platform is granted through a sign-up and invite system, with users directed to inference.cerebras.ai.
- Potential applications discussed include Chain of Thought (CoT) + RAG with Voice, potentially creating a Siri/Google Voice competitor capable of providing expert-level answers in real-time. A voice demo on Cerebras is available at cerebras.vercel.app.
- The platform is compared to Groq, with Cerebras reportedly being even faster. SambaNova APIs are mentioned as an alternative, offering similar speeds (1500 tokens/second) without a waitlist, while users note the potential for real-time applications and security implications of such high-speed inference.
- MLX batch generation is pretty cool! (Score: 42, Comments: 15): The MLX paraLLM library enabled a 5.8x speed improvement for Mistral-22b generation, increasing from 17.3 tokens per second to 101.4 tps at a batch size of 31. Peak memory usage increased from 12.66GB to 17.01GB, with approximately 150MB required for each additional concurrent generation, while the author managed to run 100 concurrent batches of the 22b-4bit model on a 64GB M1 Max machine without exceeding 41GB of wired memory.
- Energy efficiency tests showed 10 tokens per watt for Mistral-7b and 3.5 tokens per watt for 22b at batch size 100 in low power mode. This efficiency is comparable to human brain performance in terms of words per watt.
- The library is Apple-only, but similar batching capabilities exist for NVIDIA/CUDA through tools like vLLM, Aphrodite, and MLC, though with potentially more complex setup processes.
- While not applicable for improving speed in normal chat scenarios, the technology is valuable for synthetic data generation and dataset distillation.
Theme 2. Qwen 2.5: Breakthrough Performance on Consumer Hardware
- Qwen2-VL-72B-Instruct-GPTQ-Int4 on 4x P100 @ 24 tok/s (Score: 37, Comments: 52): Qwen2-VL-72B-Instruct-GPTQ-Int4, a large multimodal model, is reported to run on 4x P100 GPUs at a speed of 24 tokens per second. This implementation utilizes GPTQ quantization and Int4 precision, enabling the deployment of a 72 billion parameter model on older GPU hardware with limited VRAM.
- DeltaSqueezer provided a GitHub repository and Docker command for running Qwen2-VL-72B-Instruct-GPTQ-Int4 on Pascal GPUs. The setup includes support for P40 GPUs, but may experience slow loading times due to FP16 processing.
- The model demonstrated reasonable vision and reasoning capabilities when tested with a political image. A comparison with Pixtral model's output on the same image was provided, showing similar interpretation abilities.
- Discussion on video processing revealed that the 7B VL version consumes significant VRAM. The model's performance on P100 GPUs was noted to be faster than 3x3090s, with the P100's HBM being comparable to the 3090's memory bandwidth.
- Qwen 2.5 is a game-changer. (Score: 524, Comments: 121): Qwen 2.5 72B model is running efficiently on dual RTX 3090s, with the Q4_K_S (44GB) version achieving approximately 16.7 T/s and the Q4_0 (41GB) version reaching about 18 T/s. The post includes Docker compose configurations for setting up Tailscale, Ollama, and Open WebUI, along with bash scripts for updating and downloading multiple AI models, including variants of Llama 3.1, Qwen 2.5, Gemma 2, and Mistral.
- Tailscale integration in the setup allows for remote access to OpenWebUI via mobile devices and iPads, enabling on-the-go usage of the AI models through a browser.
- Users discussed model performance, with suggestions to try AWQ (4-bit quantization) served by lmdeploy for potentially faster performance on 70B models. Comparisons between 32B and 7B models showed better performance from larger models on complex tasks.
- Interest in hardware requirements was expressed, with the original poster noting that dual RTX 3090s were chosen for running 70B models efficiently, expecting a 6-month ROI. Questions about running models on Apple M1/M3 hardware were also raised.
Theme 3. Gemini 1.5 Pro 002: Google's Latest Model Impresses
- Gemini 1.5 Pro 002 putting up some impressive benchmark numbers (Score: 102, Comments: 42): Gemini 1.5 Pro 002 is demonstrating impressive performance across various benchmarks. The model achieves 97.8% on MMLU, 90.0% on HumanEval, and 82.6% on MATH, surpassing previous state-of-the-art results and showing significant improvements over its predecessor, Gemini 1.0 Pro.
- Google's Gemini 1.5 Pro 002 shows significant improvements, including >50% reduced price, 2-3x higher rate limits, and 2-3x faster output and lower latency. The model's performance across benchmarks like MMLU (97.8%) and HumanEval (90.0%) is impressive.
- Users praised Google's recent progress, noting their publication of research papers and the AI Studio playground. Some compared Google favorably to other AI companies, with Meta being highlighted for its open-weight models and detailed papers.
- Discussion arose about the consumer version of Gemini, with some users finding it less capable than competitors. Speculation on when the updated model would be available to consumers ranged from a few days to October 8th at the latest.
- Updated gemini models are claimed to be the most intelligent per dollar* (Score: 291, Comments: 184): Google has released Gemini 1.5 Pro 002, claiming it to be the most intelligent AI model per dollar. The model demonstrates significant improvements in various benchmarks, including a 90% score on MMLU and 93.2% on HumanEval, while offering competitive pricing at $0.0025 per 1k input tokens and $0.00875 per 1k output tokens. These performance gains and cost-effective pricing position Gemini 1.5 Pro 002 as a strong contender in the AI model market.
- Mistral offers 1 billion tokens of Large v2 per month for free, with users noting its strong performance. This contrasts with Google's pricing strategy for Gemini 1.5 Pro 002.
- Users criticized Google's naming scheme for Gemini models, suggesting alternatives like date-based versioning. The announcement also revealed 2-3x higher rate limits and faster performance for API users.
- Discussions highlighted the trade-offs between cost, performance, and data privacy. Some users prefer self-hosting for data control, while others appreciate Google's free tier and AI Studio for unlimited free usage.
Theme 4. Apple Silicon vs NVIDIA GPUs for LLM Inference
- HF releases Hugging Chat Mac App - Run Qwen 2.5 72B, Command R+ and more for free! (Score: 54, Comments: 19): Hugging Face has released the Hugging Chat Mac App, allowing users to run state-of-the-art open-source language models like Qwen 2.5 72B, Command R+, Phi 3.5, and Mistral 12B locally on their Macs for free. The app includes features such as web search and code highlighting, with additional features planned, and contains hidden easter eggs like Macintosh, 404, and Pixel pals themes; users can download it from GitHub and provide feedback for future improvements.
- Low Context Speed Comparison: Macbook, Mac Studios, and RTX 4090 (Score: 33, Comments: 29): The post compares the performance of RTX 4090, M2 Max Macbook Pro, M1 Ultra Mac Studio, and M2 Ultra Mac Studio for running Llama 3.1 8b q8, Nemo 12b q8, and Mistral Small 22b q6_K models. Across all tests, the RTX 4090 consistently outperformed the Mac devices, with the M2 Ultra Mac Studio generally coming in second, followed by the M1 Ultra Mac Studio and M2 Max Macbook Pro. The author notes that these tests were run with freshly loaded models without flash attention enabled, and apologizes for not making the tests deterministic.
- Users recommend using exllamav2 for better performance on RTX 4090, with one user reporting 104.81 T/s generation speed for Llama 3.1 8b on an RTX 3090. Some noted past quality issues with exl2 compared to gguf models.
- Discussion on prompt processing speed for Apple Silicon, with users highlighting the significant difference between initial and subsequent prompts due to caching. The M2 Ultra processes 4000 tokens in 16.7 seconds compared to 5.6 seconds for the RTX 4090.
- Users explored options for improving Mac performance, including enabling flash attention and the theoretical possibility of adding a GPU for prompt processing on Macs running Linux, though driver support remains limited.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Releases and Improvements
- OpenAI releases advanced voice mode for ChatGPT: OpenAI has rolled out an advanced voice mode for ChatGPT that allows for more natural conversations, including the ability to interrupt and continue thoughts. Users report it as a significant improvement, though some limitations remain around letting users finish thoughts.
- Google updates Gemini models: Google announced updated production-ready Gemini models including Gemini-1.5-Pro-002 and Gemini-1.5-Flash-002. The update includes reduced pricing, increased rate limits, and performance improvements across benchmarks.
- New Flux model released: The creator of Realistic Vision released a Flux model called RealFlux, available on Civitai. Users note it produces good results but some limitations remain around facial features.
AI Capabilities and Benchmarks
- Gemini 1.5 002 performance: Reports indicate Gemini 1.5 002 outperforms OpenAI's o1-preview on the MATH benchmark at 1/10th the cost and with no thinking time.
- o1 capabilities: An OpenAI employee suggests o1 is capable of performing at the level of top PhD students, outperforming humans more than 50% of the time in certain tasks. However, some users dispute this claim, noting limitations in o1's ability to learn and adapt compared to humans.
AI Development Tools and Interfaces
- Invoke 5.0 update: The Invoke AI tool received a major update introducing a new Canvas with layers, Flux support, and prompt templates. This update aims to provide a more powerful interface for combining various AI image generation techniques.
AI Impact on Society and Work
- Job displacement predictions: Vinod Khosla predicts AI will take over 80% of work in 80% of jobs, sparking discussions about potential economic impacts and the need for universal basic income.
- AI in law enforcement: A new AI tool for police work claims to perform "81 years of detective work in 30 hours," raising both excitement about increased efficiency and concerns about potential misuse.
Emerging AI Research and Applications
- MIT vaccine technology: Researchers at MIT have developed a new vaccine technology that could potentially eliminate HIV with just two shots, showcasing the potential for AI to accelerate medical breakthroughs.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. New AI Model Releases and Multimodal Enhancements
- Llama 3.2 Launches with Multimodal and Edge Capabilities: Llama 3.2 introduces various model sizes including 1B, 3B, 11B, and 90B with multimodal support and a 128K context length, optimized for deployment on mobile and edge devices.
- Molmo 72B Surpasses Competitors in Benchmarks: The Molmo 72B model from Allen Institute for AI outperforms models like Llama 3.2 V 90B in benchmarks such as AI2D and ChatQA, offering state-of-the-art performance with an Apache license.
- Hermes 3 Enhances Instruction Following on HuggingChat: Hermes 3, available on HuggingChat, showcases improved instruction adherence, providing more accurate and contextually relevant responses compared to previous versions.
Theme 2. Model Performance, Quantization, and Optimization
- Innovations in Image Generation with MaskBit and MonoFormer: The MaskBit model achieves a FID of 1.52 on ImageNet 256 × 256 without embeddings, while MonoFormer unifies autoregressive text and diffusion-based image generation, matching state-of-the-art performance by leveraging similar training methodologies.
- Quantization Techniques Enhance Model Efficiency: Discussions on quantization vs distillation reveal the complementary benefits of each method, with implementations in Setfit and TorchAO addressing memory and computational optimizations for models like Llama 3.2.
- GPU Optimization Strategies for Enhanced Performance: Members explore TF32 and float8 representations to accelerate matrix operations, alongside tools like Torch Profiler and Compute Sanitizer to identify and resolve performance bottlenecks.
Theme 3. API Pricing, Integration, and Deployment Challenges
- Cohere API Pricing Clarified for Developers: Developers learn that while rate-limited Trial-Keys are free, transitioning to Production-Keys incurs costs for commercial applications, emphasizing the need to align API usage with project budgets.
- OpenAI's API and Data Access Scrutiny: OpenAI announces limited access to training data for review purposes, hosted on a secured server, raising concerns about transparency and licensing compliance among the engineering community.
- Integrating Multiple Tools and Platforms: Challenges in integrating SillyTavern, Forge, Langtrace, and Zapier with various APIs are discussed, highlighting the complexities of maintaining seamless deployment pipelines and compatibility across tools.
Theme 4. AI Safety, Censorship, and Licensing Issues
- Debates on Model Censorship and Uncensoring Techniques: Community members discuss the over-censorship of models like Phi-3.5, with efforts to uncensor models through tools and sharing of uncensored versions on platforms like Hugging Face.
- MetaAI's Licensing Restrictions in the EU: MetaAI faces licensing challenges in the EU, restricting access to multimodal models like Llama 3.2 and prompting discussions on compliance with regional laws.
- OpenAI's Corporate Shifts and Team Exodus: The resignation of Mira Murati and other key team members from OpenAI sparks speculation about organizational stability, corporate culture changes, and the potential impact on AI model development and safety protocols.
Theme 5. Hardware Infrastructure and GPU Optimization for AI
- Cost-Effective GPU Access with Lambda Labs: Members discuss utilizing Lambda Labs for GPU access at around $2/hour, highlighting its flexibility for running benchmarks and fine-tuning models without significant upfront costs.
- Troubleshooting CUDA Errors on Run Pod: Users encounter illegal CUDA memory access errors on platforms like Run Pod, with solutions including switching machines, updating drivers, and modifying CUDA code to prevent memory overflows.
- Deploying Multimodal Models on Edge Devices: Discussions on integrating Llama 3.2 models into edge platforms like GroqCloud, emphasizing the importance of optimized inference kernels and minimal latency for real-time AI applications.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Llama 3.2 Launches with New Features: Llama 3.2 has been launched, introducing new text models (1B and 3B) and vision models (11B and 90B), which support 128K context length and handle 9 trillion tokens.
- The release brings quantization format support including GGUF and BNB, enhancing its application in various scenarios.
- Cost Effectiveness of Model Usage Compared: Discussion emerged on whether smaller models save costs versus quality, with one member noting they created a dataset worth $15-20k despite expenses.
- Contradicting views spark debate on whether GPU costs might ultimately be more economical than subscribing to APIs, especially with heavy token consumption.
- Inquiry into Fine-tuning Llama Models: Members are interested in fine-tuning Llama 3.1 locally, suggesting Unsloth tools and scripts tailored for this process.
- There are rising expectations for support regarding Llama Vision models, indicating a roadmap for future enhancements.
- OpenAI's Feedback Process Under Scrutiny: Participants discussed OpenAI's approach to improvement through Reinforcement Learning from Human Feedback (RLHF), seeking clarity on implementation methods.
- Conversations highlighted the ambiguity around their feedback mechanism, pointing out the necessity for transparency in their processes.
- High Token Usage Raises Concerns: Intensive AI pipelines reportedly average 10-15M tokens per generation, stressing the complexities understood by seasoned developers.
- A member expressed frustration over misconceptions related to their hardware setup among peers.
HuggingFace Discord
- Hugging Face model releases better support: The recent announcements from Hugging Face include Mistral Small (22B) and updates on Qwen models, available for exploration, along with new Gradio 5 features for ML app development.
- Release of FinePersonas-v0.1 introduces 21 million personas for synthetic data generation, while Hugging Face's deeper integration with Google Cloud's Vertex AI enhances AI developer accessibility.
- Llama 3.2 offers multimodal capabilities: The newly released Llama 3.2 boasts multimodal support with models capable of handling text and image data and includes a substantial 128k token context length.
- Designed for mobile and edge device deployment, the models facilitate diverse application scenarios, potentially revolutionizing local inferencing performance.
- Challenges in training topic clusters: Members faced issues aggregating a sensible number of topics for training without excessive manual merging, leading to a focus on zero-shot systems as a solution.
- Discussions revolved around using flexible topic management techniques to streamline production processes.
- Insights into Diffusion Models: The effectiveness of Google Colab for running diffusion models sparked discussions, especially regarding model performance criteria when utilizing its free tier.
- Members discussed Flux as a robust open-source diffusion model, with alternatives like SDXL Lightning proposed for faster image generation without sacrificing too much quality.
- Exploring fine-tuning and optimization techniques: Techniques for fine-tuning token embeddings and other optimizations were core topics, with focus on maintaining pre-existing token functions while integrating newly added embeddings.
- Challenges with Setfit’s serialization due to memory constraints were also addressed, emphasizing strategies for better checkpoint management during training phases.
Nous Research AI Discord
- Hermes 3 Launches on HuggingChat: The latest release of Hermes 3 in 8B size is now available on HuggingChat, showcasing improved instruction adherence.
- Hermes 3 has significantly enhanced its ability to follow instructions, promising more accurate and contextually relevant responses than prior versions.
- Llama 3.2 Performance Insights: The release of Llama 3.2 with multiple sizes generated discussions about its performance, particularly when compared to smaller models like Llama 1B and 3B.
- Users noted specific capabilities and limitations, including improved code generation abilities, sparking much curiosity.
- Sample Packing Techniques Discussed: A discussion focused on sample packing for training small GPT-2 models raised concerns about potential performance degradation if not executed correctly.
- A participant emphasized that naive implementation could lead to suboptimal results, despite its theoretical benefits.
- MIMO Framework Revolutionizes Video Synthesis: The MIMO framework proposes a method for synthesizing realistic character videos with controllable attributes based on simple user inputs.
- MIMO aims to overcome limitations of existing 3D methods and enhances scalability and interactivity in video synthesis tasks.
- Seeking Research on Job Recommendation Systems: A member detailed their challenges in finding quality research related to building a resume ATS builder and job recommendation systems.
- Advice was sought to navigate the extensive landscape of existing literature effectively.
aider (Paul Gauthier) Discord
- Llama 3.2 Launch: Meta has announced the release of Llama 3.2, featuring small and medium-sized vision LLMs and lightweight models for edge and mobile devices, during Meta Connect.
- These models aim to enhance accessibility for developers with limited resources, as discussed in the context of their latest model advancements.
- Aider Faces Functionality Challenges: Users reported limitations in Aider, particularly the lack of built-in translation and insufficient documentation indexing, pushing discussions for potential enhancements.
- Ideas include incorporating voice feedback and automatic documentation searches to improve user experience.
- Switching LLMs for Better Performance: Reports indicate that users are switching from Claude Sonnet 3.5 to models like Gemini Pro 1.5 to improve code comprehension and performance.
- Engaging Aider's benchmark suite for model performance tracking is seen as essential to ensure accurate outcomes.
- Local Vector Databases Explored: A discussion centered on local vector databases revealed interest in Chroma, Qdrant, and PostgreSQL vector extensions for handling complex data efficiently.
- While SQLite can manage vector DB tasks, specialized databases are deemed more adept for heavy workloads.
- Introducing the par_scrape Tool: A member showcased the par_scrape tool on GitHub as an efficient web scraping solution, praised for its capabilities compared to alternatives.
- Its utilization could streamline scraping tasks significantly for the community.
OpenRouter (Alex Atallah) Discord
- OpenRouter's Database Upgrade Scheduled: A database upgrade is slated for Friday at 10am ET, leading to a brief downtime of 5-10 minutes. Users should prepare for potential service interruptions.
- The upgrade aims to enhance overall system performance, aligning with recent API changes.
- API Output Enhancements Announced: OpenRouter now includes the provider in the completion response for improved clarity in data retrieval.
- This change is designed to streamline information processing and enhance user experience.
- Gemini Models Routing Gets an Upgrade: Gemini-1.5-flash and Gemini-1.5-pro have been rerouted to utilize the latest 002 version for better performance.
- The community is encouraged to test these updated models to gauge their efficiency in various applications.
- Llama 3.2 Release Builds Anticipation: The upcoming Llama 3.2 release includes smaller models for easier integration in mobile and edge deployments.
- Inquiries on whether OpenRouter will host the new models sparked excitement among the developers.
- Local Server Support Faces Limits: Support for local servers remains a challenge as restricted external access hampers assistance capabilities.
- Future API support may expand if endpoints meet specific OpenAI-style schema requirements, opening doors for collaboration.
OpenAI Discord
- Advanced Voice Mode Distribution Frustrations: Members are frustrated over the limited rollout of the Advanced Voice mode, particularly in the EU, where access remains restricted despite announcements of full availability.
- They pointed out a trend of delayed features for EU users, referencing prior instances such as the memory functionality.
- Meta AI Faces Licensing Restrictions in the EU: It was clarified that Meta AI is not available for users in the EU and UK due to strict licensing rules on multimodal models, linked directly to Llama 3.2's licensing issues.
- Members noted that Llama 3.2 features improved multimodal capabilities but are still hindered by these licensing complications.
- Essay Grading Needs Tougher Feedback: Discussion focused on the challenge of providing honest feedback on essays, highlighting a tendency for models to offer lenient critiques.
- Members suggested using detailed rubrics and examples but noted the model's inherent inclination towards positive reinforcement complicates matters.
- Optimizing Minecraft API Prompts: Members proposed strategies to enhance prompts for the Minecraft API, aiming to reduce repetitive queries by varying topics and complexity levels.
- Concerns were raised about how to prompt the AI to enforce a structured response format and avoid duplicating questions.
- Struggles with Complex Task Handling: Users expressed frustration that GPT struggles with complex tasks, citing experiences of long waits for meager outputs, especially on book-writing requests.
- Some suggested alternative models like Claude and o1-preview, which they find more capable thanks to extended memory windows.
LM Studio Discord
- Llama 3.2 Launch Sparks Excitement: The recent release of Llama 3.2, including models like the 1B and 3B, has generated significant interest due to its performance across various hardware setups.
- Users are particularly eager for support for the 11B multimodal model, yet complications regarding its vision integration may delay availability.
- Integration Issues with SillyTavern: Users are encountering integration issues with SillyTavern while using LM Studio, largely related to server communication and response generation.
- Troubleshooting suggests that task inputs may need to be more specific rather than relying on freeform text prompts.
- Concerns Over Multimodal Model Capabilities: While Llama 3.2 includes a vision model, users demand true multimodal capabilities similar to GPT-4 for broader utility.
- It has been clarified that the 11B model is limited to vision tasks and currently lacks voice or video functionalities.
- Price Discrepancies Cause Frustration: Users shared their frustration over higher tech prices in the EU, which can be twice as much as those in the US.
- Many highlighted that VAT is a significant factor contributing to these discrepancies.
- Expectations for RTX 3090 TPS: Discussions on the RTX 3090 highlighted expected transactions per second (TPS) of around 60-70 TPS on a Q4 8B model.
- Clarified that this metric is primarily useful for inference training, rather than for simple query processing.
Eleuther Discord
- yt-dlp Emerges as a Must-Have Tool: A member highlighted yt-dlp, showcasing it as a robust audio/video downloader, raising concerns over malware but confirming the source's safety.
- This tool could simplify content downloading for developers, but review of its usage among engineers is essential due to potential security risks.
- PyTorch Training Attribute Bug Causes Frustration: A known bug in PyTorch was discussed where executing
.eval()or.train()fails to update the.trainingattribute oftorch.compile()modules, outlined in this GitHub issue.- Members expressed disappointment over the lack of transparency on this issue while brainstorming workarounds, such as altering
mod.compile().
- Members expressed disappointment over the lack of transparency on this issue while brainstorming workarounds, such as altering
- Local LLM Benchmarking Tools Needed: Request for recommendations on open-source benchmark suites for local LLM testing pointed towards established metrics like MMLU and GSM8K, with mentions of the lm-evaluation-harness for evaluating models.
- This search underscores the need for comprehensive evaluation frameworks in the AI community to validate local model performance.
- NAIV3 Technical Report on Crowd-Sourced Data: The NAIV3 Technical Report released contains a dataset of 6 million crowd-sourced images, focusing on tagging practices and image management.
- Discussions revolved around including humor in documentation, indicating a divergence in stylistic preferences for technical reports.
- BERT Masking Rates Show Performance Impact: Inquiring into high masking rates for BERT models revealed that rates exceeding 15%, notably up to 40%, can boost performance, suggesting a significant advantage in larger models.
- This suggests that training methodologies may need reevaluation to integrate findings from recent studies addressing masking strategies.
Perplexity AI Discord
- Perplexity AI struggles with context retention: Users have expressed frustration with Perplexity AI not retaining context for follow-up questions, a trend that has worsened recently. Some members noted a decline in the platform's performance, impacting its utility.
- Concerns were raised regarding potential financial issues affecting Perplexity's capabilities, prompting discussions about viable alternatives.
- Merlin.ai offers O1 with web access: Merlin.ai has been recommended as an alternative to Perplexity since it provides O1 capabilities with web access, allowing users to bypass daily message limits. Participants showed interest in exploring Merlin for its expanded functionalities.
- The discussion highlighted how users perceive Merlin to be more functional than Perplexity, potentially reshaping their tool choices.
- Wolfram Alpha integration with Perplexity API: A user inquired about the potential use of Wolfram Alpha with the Perplexity API similar to how it works on the web app, to which it was confirmed that integration is currently not possible. The independence of the API from the web interface was stressed.
- Further inquiries were made about whether the API could perform as efficiently as the web interface for math and science problem-solving, with no conclusive answers provided.
- Users weigh in on AI tools for education: Numerous users shared their perspectives on using various AI tools for academic tasks, with preferences varying between GPT-4o and Claude as alternatives. Feedback indicated that different AI tools offer varying levels of assistance for school-related needs.
- This exchange highlighted the significant role AI plays in educational settings, with an emphasis on user experience shaping these preferences.
- Evaluating Air Fryers: Worth It?: A user shared a link discussing whether air fryers are worth it, focusing on health benefits versus traditional frying methods and cooking efficiency. The dialogue included consumers' varied viewpoints about the gadget's practicality.
- Key takeaways from the discussion centered around both the positive cooking attributes of air fryers and the skepticism on their actual health benefits compared to conventional methods.
Interconnects (Nathan Lambert) Discord
- Anthropic Sets Sights on $1B Revenue: As reported by CNBC, Anthropic is projected to surpass $1B in revenue this year, achieving a jaw-dropping 1000% year-over-year growth.
- Revenue sources include 60-75% from third-party APIs and 15% from Claude subscriptions, marking a significant shift for the company.
- OpenAI Provides Training Data Access: In a notable shift, OpenAI announced it will allow access to its training data for review regarding copyrighted works used.
- This access is limited to a secured computer at OpenAI's San Francisco office, stirring varying reactions among the community.
- Molmo Model Surpasses Expectations: The Molmo model has generated excitement with claims that its pointing feature may be more significant than a higher AIME score, garnering positive comparisons to Llama 3.2 V 90B benchmarks.
- Comments noted Molmo outperformed on metrics like AI2D and ChatQA, demonstrating its strong performance relative to its competitors.
- Curriculum Learning Enhances RL Efficiency: Research shows that implementing curriculum learning can significantly boost Reinforcement Learning (RL) efficiency by using previous demonstration data for better exploration.
- This method includes a creative reverse and forward curriculum strategy, compared to DeepMind's similar Demostart, highlighting both gains and challenges in robotics.
- Llama 3.2 Launch Triggers Community Buzz: Llama 3.2 has officially launched with various model sizes including 1B, 3B, 11B, and 90B, aimed at enhancing text and multimodal capabilities.
- Initial reactions show a mix of excitement and skepticism about its readiness, with discussions fueled by hints of future improvements and updates.
GPU MODE Discord
- Exploring SAM2-fast with Diffusion Transformers: Members discussed using SAM2-fast within a Diffusion Transformer Policy to map camera sensor data to robotic arm positions, suggesting image/video segmentation for this use case.
- The conversation highlighted the potential of combining rapid sensor data processing with robotic control through advanced ML techniques.
- Torch Profiler's Size Issue: Torch profiler generated excessive file sizes (up to 7GB), leading to suggestions on profiling only essential items and exporting as .json.gz for compression.
- Members emphasized efficient profiling strategies to maintain manageable file sizes and usability for tracing performance.
- RoPE Cache Should Always Be FP32: A discussion arose on the RoPE cache in the Torchao Llama model, advocating for it to be consistently in FP32 format for accuracy.
- Members pointed to specific lines in the model repository for further clarity.
- Lambda Labs Cost-Effective GPU Access: Using Lambda Labs for GPU access at approximately $2/hour was highlighted as a flexible option for running benchmarks and fine-tuning.
- The user shared experiences regarding seamless SSH access and pay-per-use structure, making it attractive for many ML applications.
- Metal Atomics Require Atomic Load/Stores: To achieve message passing between workgroups, a member suggested employing an array of atomic bytes for operations in metal atomics.
- Efficient flag usage with atomic operations and non-atomic loads was emphasized for improved data handling.
OpenAccess AI Collective (axolotl) Discord
- Run Pod Issues Dismay Users: Users reported experiencing illegal CUDA errors on Run Pod, with some suggesting switching machines to resolve the issue.
- One user humorously advised against using Run Pod due to ongoing issues, emphasizing the frustration involved.
- Molmo 72B Takes Center Stage: The Molmo 72B, developed by the Allen Institute for AI, boasts state-of-the-art benchmarks and is built on the PixMo dataset of image-text pairs.
- Apache licensed, this model aims to compete with leading multimodal models, including GPT-4o.
- OpenAI's Leadership Shakeup Rocks Community: A standout moment occurred with the resignation of OpenAI's CTO, sparking speculation about the organization's future direction.
- Members discussed the potential implications for OpenAI's strategy, hinting at intriguing internal dynamics.
- Llama 3.2 Rollout Excites All: The introduction of Llama 3.2 features lightweight models for edge devices, generating buzz about sizes ranging from 1B to 90B.
- Multiple sources confirmed the phased rollout, with excitement about performance validation from the new models.
- Meta's EU Compliance Quagmire: Conversations revealed Meta's struggles with EU regulations, leading to restricted access for European users.
- Discussions alluded to a possible license change affecting model availability, igniting debate over company motivations.
Cohere Discord
- Cohere API Key Pricing Clarified: Members highlighted the rate-limited Trial-Key for free usage but stated that commercial applications require a Production-Key that incurs costs.
- This emphasizes careful consideration of intended usage when planning API key resources.
- Testing Recursive Iterative Models Hypotheses: A user posed the question if obtaining similar results across multiple LLMs implies their Recursive Iterative model is functioning correctly.
- Suggestions included further evaluations against benchmarks to ensure reliable outcomes.
- Launch of New RAG Course: An announcement was made about the new RAG course in production with Weights&Biases, covering evaluation and pipelines in under 2 hours.
- Participants earn Cohere credits and can ask questions to a Cohere team member during the course.
- Exciting Smart Telescope Project: A member shared their enthusiasm about a smart telescope mount project aiming to automatically locate 110 objects from the Messier catalog.
- Community support flowed in, encouraging collaboration and resource sharing for the project.
- Cohere Cookbook Now Available: The Cohere Cookbook has been highlighted as a resource containing guides for using Cohere’s generative AI platform effectively.
- Members were directed to explore sections specific to their AI project needs, including embedding and semantic search.
LlamaIndex Discord
- LlamaParse Fraud Alert: A warning was issued about a fraudulent site, llamaparse dot cloud, attempting to impersonate LlamaIndex products; the official LlamaParse can be accessed at cloud.llamaindex.ai.
- Stay vigilant against scams that pose risks to users by masquerading as legitimate services.
- Varied Exciting Presentations at AWS Gen AI Loft: LlamaIndex's developers will share insights on RAG and Agents at the AWS Gen AI Loft, coinciding with the ElasticON conference on March 21, 2024 (source).
- Attendees will understand how Fiber AI integrates Elasticsearch into high-performance B2B prospecting.
- Launch of Pixtral 12B Model: The Pixtral 12B model from @MistralAI is now integrated with LlamaIndex, excelling in multi-modal tasks involving chart and image comprehension (source).
- This model showcases impressive performance against similarly sized counterparts.
- Join LlamaIndex's Team!: LlamaIndex is actively hiring engineers for their San Francisco team; openings range from full-stack to specialized roles (link).
- The team seeks enthusiastic individuals eager to work with ML/AI technologies.
- Clarifications on VectorStoreIndex Usage: Users discussed how to properly access the underlying vector store using the
VectorStoreIndex, specifically throughindex.vector_store. Clarifications surfaced around the limitations of SimpleVectorStore, prompting discussions about alternative storage options.- The conversation highlighted technical aspects of callable methods and properties, contributing to a better grasp of Python decorators.
Latent Space Discord
- Gemini pricing solidifies competitive stance: The recent cut in Gemini Pro pricing aligns with a loglinear pricing curve based on its Elo score, refining its approach against other models.
- As prices adjust, OpenAI continues to dominate the high end, while Gemini Pro and Flash capture lower tiers in a vivid framework reminiscent of 'iPhone vs Android'.
- Anthropic hits a revenue milestone: Anthropic is on track to achieve $1B in revenue this year, reflecting a staggering 1000% year-over-year increase, based on a report from CNBC.
- The revenue breakdown indicates a heavy reliance on Third Party API sales, contributing 60-75% of their income, with API and chatbot subscriptions also playing key roles.
- Llama 3.2 models enhance edge capabilities: The launch of Llama 3.2 introduces lightweight models optimized for edge devices, with configurations like 1B, 3B, 11B, and 90B vision models.
- These new offerings emphasize multimodal capabilities, encouraging developers to explore enhanced functionalities through open-source access.
- Mira Murati bids farewell to OpenAI: In a community-shared farewell, Mira Murati's departure from OpenAI led to discussions reflecting on her significant contributions during her tenure.
- Sam Altman acknowledged the emotional journey she navigated, highlighting the support she provided to the team amid challenges.
- Meta's Orion glasses prototype stages debut: After nearly a decade of development, Meta has revealed their Orion AR glasses prototype, marking a significant advancement despite initial skepticism.
- Aimed for internal use to refine user experiences, these glasses are designed for a broad field of view and lightweight characteristics to prepare for eventual consumer release.
Stability.ai (Stable Diffusion) Discord
- Basicsr Installation Troubles Made Simple: To resolve issues with ComfyUI in Forge, users should navigate to the Forge folder and run
pip install basicsrafter activating their virtual environment.- There's a growing confusion about the installation, with several users hoping the extension appears as a tab post-install.
- Battle of the Interfaces: ComfyUI vs Forge: Members shared their preferences, with one stating that they find Invoke much easier to use compared to ComfyUI.
- Many prefer staying loyal to ComfyUI due to the outdated version and its compatibility issues within Forge.
- 3D Model Generators: What Works?: Inquiry about 3D model generators revealed issues with TripoSR, suggesting many open-source tools appear broken.
- Interest was shown in Luma Genie and Hyperhuman, though skepticism about their functionality remains high.
- Running Stable Diffusion Without a GPU: For those looking to run Stable Diffusion without a GPU, using Google Colab or Kaggle provides free access to GPU resources.
- There's a shared consensus that these platforms serve as great starting points for beginners engaging with Stable Diffusion.
- Getting Creative with ControlNet OpenPose: Members learned how to use the ControlNet OpenPose preprocessor for generating and editing preview images within the platform.
- There’s evident excitement about exploring this feature, allowing for detailed adjustments in generated outputs.
Torchtune Discord
- Llama 3.2 Launches with Multimodal Features: The release of Llama 3.2 introduces 1B and 3B text models with long-context support, allowing users to try with
enable_activation_offloading=Trueon long-context datasets.- Additionally, the 11B multimodal model supports The Cauldron datasets and custom multimodal datasets for enhanced generation.
- Desire for Green Card: A member humorously expressed desperation for a green card, suggesting they might make life harder for Europe due to their situation.
- 'I won't tell anyone in exchange for a green card' highlights their frustration and willingness to negotiate.
- Consider TF32 for FP32 users: Discussion arose around enabling TF32 as an option for users still utilizing FP32, as it accelerates matrix multiplication (matmul).
- The sentiment echoed that if one is already using FP16/BF16, TF32 may not offer added benefits, with one member humorously noting, ‘I wonder who would prefer it over FP16/BF16 directly’.
- RFC Proposal on KV-cache toggling: An RFC on KV-cache toggling has been proposed, aiming to improve how caches are handled during model forward passes.
- The proposal addresses the current limitation where caches are always updated unnecessarily, prompting further discussion on necessity and usability.
- Advice on handling Tensor sizing: A query was made regarding improving the handling of sizing for Tensors beyond using the Tensor item() method.
- One member acknowledged the need for better solutions and promised to think about it further.
Modular (Mojo 🔥) Discord
- MOToMGP Error Investigation: A user inquired about the error 'failed to run the MOToMGP pass manager', seeking reproduction cases to improve messaging around it.
- Community members were encouraged to share insights or experiences related to this specific issue.
- Sizing Linux Box for MAX Optimization: A member asked how to size a Linux box when running MAX with ollama3.1, opening discussions about optimal configurations.
- Members contributed tips on resource allocation to enhance performance.
- GitHub Discussions Shift: On September 26th, Mojo GitHub Discussions will disable new comments to focus community engagement on Discord due to low participation.
- The change aims to streamline discussions and reflect on the inefficacy of converting past discussions into issues.
- Mojo's Communication Speed with C: Participants wondered if Mojo's communication with C is faster than with Python, noting it likely depends on the specific implementation.
- There was agreement that Python's interaction with C can vary based on context.
- Evan Implements Associated Aliases: Evan is rolling out associated aliases in Mojo, allowing for traits and type aliases similar to provided examples which excites the community.
- Members see potential improvements in code organization and clarity with this feature.
OpenInterpreter Discord
- Excitement around o1 Preview and Mini API: Members express excitement over accessing the o1 Preview and Mini API, pondering its capabilities in Lite LLM and responses received through Open Interpreter.
- One member humorously mentioned their eagerness to test it despite lacking tier 5 access.
- Llama 3.2 Launches with Lightweight Edge Models: Meta's Llama 3.2 has launched, introducing 1B & 3B models for edge use, optimized for Arm, MediaTek, and Qualcomm.
- Developers can access the models through Meta and Hugging Face, with 11B & 90B vision models poised to compete against closed counterparts.
- Tool Use Episode Covers Open Source AI: The latest Tool Use episode features discussions on open source coding tools and the infrastructure around AI.
- The episode spotlights community-driven innovations, resonating with previously shared ideas within the channel.
- Llama 3.2 Now Available on GroqCloud: Groq announces a preview of Llama 3.2 in GroqCloud, enhancing accessibility for developers through their infrastructure.
- Members noted the positive response to Groq's speed with the remark that anything associated with Groq operates exceptionally fast.
- Logo Design Choices Spark Discussion: A member shares their logo design journey, noting that while they considered the GitHub logo, they feel their current choice is superior.
- Another member lightheartedly added commentary about the power of their design choice, infusing humor into the discussion.
LLM Agents (Berkeley MOOC) Discord
- Gemini 1.5 demonstrates strong benchmarks: Gemini 1.5 Flash achieved a score of 67.3% in September 2024, while Gemini 1.5 Pro scored even better at 85.4%, marking a significant performance upgrade.
- This improvement highlights ongoing enhancements in model capabilities across various datasets.
- Launch of MMLU-Pro dataset: The new MMLU-Pro dataset boasts questions from 57 subjects with increased difficulty, aiming to challenge model evaluation effectively.
- This updated dataset is critical for assessing models in complex areas such as STEM and humanities.
- Questioning Chain of Thought utility: A recent study with 300+ experiments indicates that Chain of Thought (CoT) is only beneficial for math and symbolic reasoning, performing similarly to direct answering for most tasks.
- The analysis suggests CoT is unnecessary for 95% of MMLU tasks, redirecting focus on its strengths in symbolic computation.
- AutoGen proves valuable in research: Research highlights the growing use of AutoGen, reflecting its relevance in the current AI landscape.
- This trend points to significant developments in automating model generation, impacting both performance and research progression.
- Quiz 3 details available: Inquiries about Quiz 3 led members to confirm it's available on the course website under the syllabus section.
- Regular checks for syllabus updates are emphasized for staying informed about assessment schedules.
DSPy Discord
- DSPy Launches Cool New Features!: New features specific to DSPy on Langtrace are rolling out this week, including a new project type and automatic experiment tracking inspired by MLFlow.
- These include automatic checkpoint state tracking, eval score trendlines, and support for litellm.
- Text Classification Targets Fraud Detection: Users are employing DSPy for classifying text into three types of fraud, seeking advice on the optimal Claude model.
- Highlighted was that Sonnet 3.5 is the leading model, with Haiku offering a cost-effective alternative.
- DSPy as an Orchestrator for User Queries: A member is exploring DSPy as a tool for routing user queries to sub-agents and assessing its direct interaction capabilities.
- The conversation covered the potential for integrating tools, questioning the effectiveness of memory versus standalone conversation history.
- Clarifying Complex Classes in Text Classification: Members discussed the need for precise definitions while classifying text into complex classes, specifically including US politics and International Politics.
- One member noted that these definitions significantly depend on the business context, highlighting the nuanced approach needed.
- Collaborative Tutorial on Classification Tasks: The ongoing discussions have coincided with a member writing a tutorial on classification tasks, aiming to enhance clarity.
- This signals an effort to improve understanding in the classification domain.
tinygrad (George Hotz) Discord
- Essential Resources for Tinygrad Contributions: A member shared a series of tutorials on tinygrad covering the internals to help new contributors grasp the framework.
- They highlighted the quickstart guide and abstraction guide as prime resources for onboarding.
- Training Loop Too Slow in Tinygrad: A user lamented the slow training in tinygrad version 0.9.2 while working on a character model, describing it as slow as balls.
- They rented a 4090 GPU to enhance performance but reported minimal improvements.
- Bug in Sampling Code Affects Output Quality: The user discovered a bug in their sampling code after initially attributing slow training to general performance issues.
- They clarified the problem stemmed specifically from the sampling implementation, not the training code, which impacted the quality of model inference.
- Efficient Learning Through Code: Members suggested reading code and allowing arising questions to guide learning within tinygrad.
- Using tools like ChatGPT can assist in troubleshooting and foster a productive feedback loop.
- Using DEBUG to Understand Tinygrad's Flow: A member recommended utilizing
DEBUG=4for simple operations to see generated code and understand the flow in tinygrad.- This technique provides practical insights into the internal workings of the framework.
LangChain AI Discord
- Open Source Chat UI Seeking: A member is on the hunt for an open source UI tailored for chat interfaces focusing on programming tasks, seeking insights from the community on available options.
- The discussion welcomes experiences in deploying similar systems to help refine choices.
- Thumbs Up/Down Feedback Mechanisms: Members are exploring the implementation of thumbs up/thumbs down review options for chatbots, with one sharing their custom front end approach ruling out Streamlit.
- This reveals a collective interest in enhancing user engagement through feedback systems.
- Azure Chat OpenAI Integration Details: A developer disclosed their integration of Azure Chat OpenAI for chatbot functionalities, highlighting it as a viable platform for similar projects.
- They encouraged others to exchange ideas and challenges around this integration.
- Experience Building an Agentic RAG Application: A user detailed their development of an agentic RAG application using LangGraph, Ollama, and Streamlit, aimed at retrieving pertinent research data.
- They successfully deployed their solution via Lightning Studios and shared insights on their process in a LinkedIn post.
- Experimentation with Lightning Studios: The developer utilized Lightning Studios for efficient application deployment and experimentation with their Streamlit app, optimizing the tech stack.
- This emphasizes the platform's capabilities in enhancing application performance across different tools.
LAION Discord
- GANs, CNNs, and ViTs as top image algorithms: Members noted that GANs, CNNs, and ViTs frequently trade off as the top algorithm for image tasks and requested a visual timeline to showcase this evolution.
- The interest in a timeline highlights a need for historical context in the algorithm landscape of image processing.
- MaskBit revolutionizes image generation: The paper on MaskBit presents an embedding-free model generating images from bit tokens with a state-of-the-art FID of 1.52 on ImageNet 256 × 256.
- This work also enhances the understanding of VQGANs, creating a model that improves accessibility and reveals new details.
- MonoFormer merges autoregression and diffusion: The MonoFormer paper proposes a unified transformer for autoregressive text and diffusion-based image generation, matching state-of-the-art performance.
- This is achieved by leveraging training similarities, differing mainly in the attention masks utilized.
- Sliding window attention still relies on positional encoding: Members discussed that while sliding window attention brings advantages, it still depends on a positional encoding mechanism.
- This discussion emphasizes the ongoing balance between model efficiency and retaining positional awareness.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (510 messages🔥🔥🔥):
Llama 3.2 ReleaseFine-tuning ModelsModel Performance ComparisonsVision ModelsModel Inference and Compatibility
- Llama 3.2 is Launched: Llama 3.2 has been released with new text models (1B, 3B) and vision models (11B, 90B), boasting features like 128K context length and 9 trillion tokens.
- It includes support for various quantization formats such as GGUF and BNB.
- Guidance on Fine-tuning Large Models: Beginners are advised to start with smaller models to familiarize themselves with the fine-tuning process before moving on to larger ones, like the Llama 70B model.
- Colab is suggested for smaller models, while larger ones require significant hardware resources.
- Model Performance and Comparisons: The performance of models trained on different datasets is discussed, with notes on the quality of data influencing model efficacy.
- Comparisons are made between Llama models and others, stressing the importance of data quality over sheer volume.
- Support for Vision Models: Questions arise regarding vision support in Llama 3.2, with clarifications provided about the capabilities and adaptation of models.
- Unsloth is mentioned as a potential solution to support vision models in the future.
- Running Llama on Different Systems: Users discuss their experiences with running Llama and its variants on various hardware configurations, particularly focusing on compatibility issues with Windows and ROCm versions.
- Llama.cpp is suggested as a resource for those using AMD GPUs in attempts to run the models.
- JSON Online Validator and Formatter - JSON Lint: no description found
- Tweet from Daniel Han (@danielhanchen): My analysis of Llama 3.2: 1. New 1B and 3B text only LLMs 9 trillion tokens 2. New 11B and 90B vision multimodal models 3. 128K context length 4. 1B and 3B used some distillation from 8B and 70B 5. VL...
- Paper page - PIPPA: A Partially Synthetic Conversational Dataset: no description found
- unsloth/Llama-3.2-1B-Instruct-GGUF · Hugging Face: no description found
- Tweet from Matthew Douglas (@mattkdouglas): Announcing bitsandbytes 0.44.0! We've implemented an 8-bit version of the AdEMAMix optimizer proposed by @Apple researchers @MatPagliardini, @GrangierDavid, and @PierreAblin.
- Tweet from Daniel Han (@danielhanchen): Llama 3.2 small models 1B and 3B text only LLM benchmarks - maybe standalone LLM as well? 1B MMLU 49.3 3B MMLU 63.4
- Reddit - Dive into anything: no description found
- Tweet from Daniel Han (@danielhanchen): Llama 3.2 Multimodal benchmarks MMMU for 11B 60.3 vs Claude Haiku 50.2 MMMU for 90B 60.3 vs GPT 4o mini 59.4 90B looks extremely powerful!
- Tweet from Daniel Han (@danielhanchen): Llama 3.2 multimodal is here! Model sizes from 1B, 3B to 11B and 90B!
- unsloth/Llama-3.2-3B-bnb-4bit · Hugging Face: no description found
- unsloth/Llama-3.2-1B-Instruct-bnb-4bit · Hugging Face: no description found
- llama32_3b_failwhale.py: GitHub Gist: instantly share code, notes, and snippets.
- Reddit - Dive into anything: no description found
- Llama 3.2 - a meta-llama Collection: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- meta-llama/Llama-3.2-90B-Vision-Instruct · Hugging Face: no description found
- FREE Fine Tune AI Models with Unsloth + Ollama in 5 Steps!: Are you ready to train your own Large Language Model (LLM) but think it’s too complicated? Think again! In this video, I’m going to show you how anyone can f...
- GitHub - unslothai/unsloth: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Support for Llama3.2 series of models by ashwinb · Pull Request #150 · meta-llama/llama-models: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (42 messages🔥):
Model Costs ComparisonAPI vs Local GPU UsageOpenAI's Corporate TransitionToken Usage in Generation
- Debate on Model Cost Effectiveness: There was a discussion on whether using a smaller model could save costs, but some insisted on prioritizing high quality over cheap solutions.
- One member highlighted that despite high costs, they see profits in creating a dataset worth $15-20k.
- API Usage vs Self-Hosted GPUs: The conversation shifted to whether using an API is cheaper than running 8 H100 GPUs, with one member claiming it would cost about $384 for 24 hours.
- A counterpoint was made that with heavy token use, the GPU costs might prove to be less expensive than using an API that could reach 2-5k.
- Token Overload Discussion: Members discussed the staggering token usage in their setups, with estimates ranging from 10-15M tokens per generation for intensive pipelines.
- One participant expressed frustration at others' assumptions who don't understand their complex setups.
- OpenAI's Shift to Corporate Culture: A member shared a link referring to a note from Mira Murati about recent changes at OpenAI, indicating a potential shift in their corporate culture.
- Concerns were raised about OpenAI becoming less of an exciting startup and possibly entering corporate mode, possibly due to management changes.
Link mentioned: Tweet from Mira Murati (@miramurati): I shared the following note with the OpenAI team today.
Unsloth AI (Daniel Han) ▷ #help (52 messages🔥):
KTO and ORPO methodsOpenAI's Feedback MechanismLlama fine-tuning inquiriesIssues with Llama modelSpider Dataset and SQL Assistants
- Discussion on KTO and ORPO methods for guiding models: A member sought advice on teaching models using past examples of mistakes, expressing frustration with KTO's binary true/false structure.
- They expressed interest in the different approaches to training models and how feedback is integrated into their performance enhancements.
- Curiosity about OpenAI's Feedback Process: Members discussed how OpenAI uses Reinforcement Learning from Human Feedback (RLHF) to improve their models, with some questioning the specifics of how this is implemented.
- An inquiry was made regarding the exact methods OpenAI employs to incorporate feedback, but conclusive details remain unspecified.
- Inquiries about fine-tuning Llama models: Several members questioned the possibility of fine-tuning the Llama 3.1 model locally, with suggestions directing them to install Unsloth and use provided scripts.
- Discussions also touched on the status of fine-tuning for Llama Vision models, with expectant timelines for future support mentioned.
- Issues experienced with Llama models: A member compared the performance of the Llama 3.1 8B model downloaded from Unsloth to one from ollama.ai, noting a discrepancy in output quality.
- They raised questions about potential differences in model capability, which led to discussions regarding the validity of the outputs from various sources.
- Utilizing Spider Dataset for Text-to-SQL Applications: A member detailed their intention to build a MySQL assistant leveraging the Spider text-to-SQL dataset, sharing their experiences with the existing models.
- They highlighted the positive results with Llama 3.1 but expressed a desire to further improve model performance through fine-tuning with specialized datasets.
- Hello! Spank: Morimura Aiko is a junior high school student who is short for her age. Her father went on a yacht ten years ago and his whereabouts remained in obscurity. Her mother, a designer for hats, left for Pa...
- phi3 playbook gguf: llama_model_load: error loading model: vocab size mismatch · Issue #418 · unslothai/unsloth: The llama.cpp integration within the playbook does not works, anyway i have manually created the gguf file but when i try to serve the model using the llama.cpp server i am getting the following er...
HuggingFace ▷ #announcements (1 messages):
New Model ReleasesGradio 5 LaunchFinePersonas Data SetHF Hub Google Cloud IntegrationWikimedia Dataset Release
- Mistral Small and New Qwen models announced: Mistral Small (22B) and the latest iteration of the Qwen Party of Models are now available for exploration on Hugging Face, along with CogVideoX-5b-I2V for video generation tasks.
- Explore the HF Collection and try out models in Hugging Chat.
- Gradio 5 simplifies ML app demos: The release of Gradio 5 promises to enhance the user experience in building and sharing machine learning applications with a fast and easy setup.
- With simple Python functions, users can create interfaces that run on any platform, making it ideal for collaboration and demonstration.
- Introducing FinePersonas for synthetic data: FinePersonas-v0.1 is launched, providing 21 million permissively licensed personas for generating diverse and controllable synthetic data for various applications.
- This dataset allows users to create realistic instructions, user queries, and domain-specific problems to improve LLM capabilities.
- HF Hub enhances integration with Google Cloud: The Hugging Face Hub has deepened its integration with Google Cloud’s Vertex AI Model Garden, improving accessibility for AI developers.
- This update brings potential seamless deployment of models and datasets within the Google Cloud ecosystem.
- Wikimedia releases structured Wikipedia dataset: Wikimedia has unveiled an early beta dataset for public use, sourced from the Snapshot API with a focus on English and French Wikipedia articles.
- The dataset aims to provide more machine-readable responses, enhancing usability for researchers and developers.
- Gradio: Build & Share Delightful Machine Learning Apps
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): Introducing FinePersonas-v0.1 - Permissively licensed 21 Million Personas for generating massive scale (diverse & controllable) synthetic data! 🔥 Produced with @AIatMeta Llama 3.1 70B Instruct, @arg...
- Tweet from Matthew Douglas (@mattkdouglas): Announcing bitsandbytes 0.44.0! We've implemented an 8-bit version of the AdEMAMix optimizer proposed by @Apple researchers @MatPagliardini, @GrangierDavid, and @PierreAblin.
- Tweet from Miquel Farré (@micuelll): Curious about how FineVideo was built? 🍿 We open sourced the whole scraping and processing scripts to convert ~2M YouTube videos into a rich, annotated dataset for training video foundation models. R...
- Tweet from tomaarsen (@tomaarsen): I've just shipped the Sentence Transformers v3.1.1 patch release, fixing the hard negatives mining utility for some models. This utility is extremely useful to get more performance out of your emb...
- Tweet from David Berenstein (@davidberenstei): Why is it important to look at your synthetic data, even when using synthetic data? DataCraft UX update. Data may contain quirks, like repeated prompts, too difficult phrasing and markdown formats,...
- Tweet from Gabriel Martín Blázquez (@gabrielmbmb_): Curious about what you can do with the 21M personas in FinePersonas? One use case is creating completely novel datasets—like I just did! FinePersonas Synthetic Email Conversations ✉️ Using distilab...
- Tweet from Gradio (@Gradio): 🔥 Diffusers fast Inpaint by @OzzyGT Draw the mask over the subject you want to erase or change and write what you want to Inpaint it with. Create interesting art pieces with Diffusers and Gradio 😎
- Wikipedia Dataset on Hugging Face: Structured Content for AI/ML: Wikimedia Enterprise releasing Wikipedia dataset on Hugging Face, featuring Structured Contents beta from Snapshot API for AI and machine learning applications
- Tweet from Quentin Lhoest 🤗 (@qlhoest): FinePersonas is the richest personas dataset And now you can ReWrite it to adapt the personas to your needs (works on any dataset on HF!)
HuggingFace ▷ #general (432 messages🔥🔥🔥):
Llama 3.2 releasevLLM memory managementQuantization techniquesHugging Face librariesMachine learning optimization
- Llama 3.2 introduces new models: Llama 3.2 has been released, featuring multimodal support and tiny models for local deployment, with significant capabilities for text and image processing.
- These updates include a 128k token context length and models specifically designed for deployment on mobile and edge devices.
- Memory challenges with vLLM on Tesla T4: Users reported difficulties running vLLM with Llama 3.1 on a Tesla T4 GPU due to VRAM limitations, primarily when loading multiple models simultaneously.
- One user successfully executed the model separately but encountered issues with VRAM exhaustion when attempting to run additional models together.
- Exploring quantization for model efficiency: Quantization techniques, such as converting models to 4-bit or 8-bit representations, are discussed as essential for making large models operable within limited VRAM capacities.
- Hugging Face documentation provides guidance on applying these quantization strategies to optimize model performance and reduce memory load.
- Difference in code execution: A comparison between two code snippets indicated that one successfully loaded models without memory issues while the other did not, leading to discussions on code optimization.
- It was noted that the second code snippet processes models one after another, which may explain its successful execution compared to the first snippet.
- Learning from AI interactions: Users emphasized their desire to learn about AI through active inquiry, utilizing tools like ChatGPT and Claude to enhance their understanding.
- While recognizing their coding limitations, they expressed optimism in using available resources to grasp AI concepts and practices more effectively.
- Tweet from seshu bonam (@seshubon): 3 powerful nodes added to workflow builder today: 📽️Text to Video 🏄Realism LoRA or bring any LoRA url ✍️Edit images with natural language input. You can try these from the homepage and check...
- Tweet from Philipp Schmid (@_philschmid): Llama can now see and run on your phone!👀🖼️ Llama 3.2 released with Multimodal support in Llama Vision and tiny llamas for on-device usage. 10 new llama released by @AIatMeta from 1B text only to 90...
- Hug GIF - Hug - Discover & Share GIFs: Click to view the GIF
- graphic : AI-Powered Workflow Automation: no description found
- Wink Wink Agnes GIF - Wink Wink Agnes Agatha Harkness - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- no title found: no description found
- The Simpsons Moe Syzlak GIF - The simpsons Moe syzlak Get a load of this guy - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- Future Computers Will Be Radically Different (Analog Computing): Visit https://brilliant.org/Veritasium/ to get started learning STEM for free, and the first 200 people will get 20% off their annual premium subscription. D...
- The Tax Breaks (Twilight) [15.ai]: Ponyville has faced many great threats over the years, but how will they fare against a visit from the dreaded tax pony?AI tools:15.ai - https://15.ai/Adapte...
- Tweet from Sam Altman (@sama): openai now generates about 100 billion words per day. all people on earth generate about 100 trillion words per day.
- Optimizing LLMs for Speed and Memory: no description found
- Quantization: no description found
- GitHub - DigitalPhonetics/IMS-Toucan: Multilingual and Controllable Text-to-Speech Toolkit of the Speech and Language Technologies Group at the University of Stuttgart.: Multilingual and Controllable Text-to-Speech Toolkit of the Speech and Language Technologies Group at the University of Stuttgart. - DigitalPhonetics/IMS-Toucan
- GitHub - ai-graphic/Graphic-so: Graphic.so is a Multi Modal Ai Playground to build your AI apps and automations 10x faster with Natural Language interface: Graphic.so is a Multi Modal Ai Playground to build your AI apps and automations 10x faster with Natural Language interface - ai-graphic/Graphic-so
HuggingFace ▷ #today-im-learning (7 messages):
Fine-tuning LLMsStable Diffusion ModelsDiffusion Models from ScratchOptimizing Embeddings with PCA
- Fine-tuning LLMs using another LLM: A member clarified that it's possible to create inputs associated with outputs for fine-tuning a LLM using another LLM instead of relying solely on human input.
- This approach may provide more efficient data generation for training purposes.
- Running a Stable Diffusion model: A user shared their experience of working through a Stable Diffusion model as part of the Hugging Face course.
- They noted that their activities were quite basic and aimed at newbies in the field.
- Building Diffusion Models from Scratch: A member reported on their progress in developing diffusion models from scratch, focusing on implementing convolutional neural networks using Rust and WGSL.
- Their initial milestone included successfully getting Gaussian blur kernels operational for testing.
- Optimizing Embeddings with PCA: A user is learning about optimizing embeddings using Principal Component Analysis (PCA) with sklearn.
- This topic suggests an emphasis on dimensionality reduction techniques for more efficient data processing.
HuggingFace ▷ #cool-finds (12 messages🔥):
Comic Sans FLUX ModelNeural Network Learning ConstraintsDigital Processing of Postal CodesDHL Manual SortingDeutsche Post Operations
- Comic Sans FLUX Model helps with Text Generation: The release of the Comic Sans FLUX model is set to enhance the Text-Tacular Showdown Contest by allowing users to generate text-laden images in the iconic font.
- Fun Fact: Googling 'comic sans' provides results entirely rendered in Comic Sans font.
- Learning Networks Enhanced by Domain Constraints: A referenced paper highlights how adding task domain constraints significantly improves the generalization ability of learning networks, particularly for recognizing handwritten digits.
- This approach showcases a unified method for recognizing zip code digits in postal services, demonstrating efficiency in processing.
- Comparison of Postal Services Among Countries: Discussion arose regarding how Germany was an early adopter of digital processing for zip codes, while questions lingered about its performance compared to other countries.
- A member noted the continued reliance on manual sorting in postal services, leading to discussions about operational efficiency.
- DHL’s Sorting Practices Highlighted: Responses to a video revealed that despite advancements, DHL still engages in significant manual sorting for packages, as noted in a YouTube video.
- Concerns were raised regarding whether this reflected a broader issue in postal services where automation has not fully replaced manual methods.
- Inside Deutsche Post Operations: A video shared by a member provides insights into operations at Deutsche Post, showcasing that a substantial volume of mail is processed automatically, handling around a million items daily.
- However, observations indicated that plenty of handsorting still occurs, emphasizing a mix of automated and manual processes.
- Backpropagation applied to handwritten zip code recognition: Y LeCun, B Boser, JS Denker, D Henderson, RE Howard, W Hubbard, LD Jackel, Neural computation, 1989 - Cited by 17,411
- AirTags Expose Dodgy Postal Industry (DHL Responds): Thanks Brilliant for sponsoring this video! Try Brilliant for free at: https://brilliant.org/MegaLagAirTagAlex's Video: https://www.youtube.com/watch?v=tRIdo...
- BRIEFZENTRUM BERLIN: Hier geht mit täglich einer Million Sendungen mächtig die Post ab! | Magazin: Bei der Deutschen Post könnte sich bald einiges ändern und das hätte Auswirkungen auf ihren Geldbeutel. Würdet ihr mehr Porto bezahlen für mehr Tempo bei der...
- Comic Sans Font for Flux - V1 | Stable Diffusion LoRA | Civitai: Just in time for the Text-Tacular Showdown Contest , get an edge on the competition by generating text-laden images using this FLUX model to accura...
HuggingFace ▷ #i-made-this (125 messages🔥🔥):
Google Gemini demoZeromagic API platformTranscription toolsPCA optimization projectGame development and quantum programming
- Google Gemini demo showcases bounding box functionality: A member created a demo using Google Gemini that can provide coordinates for bounding boxes from images, which sparked discussions about its performance.
- Qtjack praised the demo, while others discussed alternative approaches like YOLO as a benchmark.
- Zeromagic accelerates API building: A member introduced Zeromagic, an AI-powered low-code platform that speeds up the creation of REST and GraphQL APIs significantly.
- They shared links to the project and encouragement for feedback, emphasizing the benefits for small and medium enterprises.
- Transcription tool development trends: A member discussed plans for developing a tool that extracts audio from YouTube videos, transcribes it, and aligns it for blog posts and social media.
- Feedback suggested adding a censor checkbox and improving usability, particularly for educational content.
- Innovative PCA optimization project launched: A member detailed their new PCA optimization Python package aimed at reducing the dimensionality of data while maintaining relationships among embeddings.
- Discussion included plans for a future PyPI listing, highlighting the relevance of PCA in machine learning and data science.
- Game development and learning ethos: A member shared experiences from their game development venture, discussing projects like a 3D Tetris game and their efforts in quantum programming.
- They noted the importance of continuous learning, applying the 80/20 Pareto principle to balancing work and play.
- p3nGu1nZz/Kyle-b0a · Hugging Face: no description found
- FreeTranscriptMaker - a Hugging Face Space by qamarsidd: no description found
- BatCountryEnt: no description found
- Gemini Object Detection - a Hugging Face Space by saq1b: no description found
- Tau/MLAgentsProject/Scripts/optimizer.py at dev-pca-optimization-script · p3nGu1nZz/Tau: Tau LLM made with Unity 6 ML Agents. Contribute to p3nGu1nZz/Tau development by creating an account on GitHub.
- oproof/oproof/main.py at main · p3nGu1nZz/oproof: Validate prompt-response pairs using Ollama and Python. - p3nGu1nZz/oproof
- GitHub - ytdl-org/youtube-dl: Command-line program to download videos from YouTube.com and other video sites: Command-line program to download videos from YouTube.com and other video sites - ytdl-org/youtube-dl
- ZeroMagic - Build, Deploy, and Scale Your Application Faster: Zeromagic is an AI-powered low code SAAS platform helps developers and enterprises to build Rest & GraphQL APIs 10x times faster with instant deployment, everything minutes.
- Zeromagic Documentation: no description found
- Zeromagic Documentation: no description found
HuggingFace ▷ #computer-vision (3 messages):
Molmo modelsMultimodal comparisonGraphs and resources
- Excitement for Multimodal Molmo Models: A member expressed interest in sharing insights about the new multimodal Molmo models, highlighting this blogpost that contains many graphs and comparisons.
- Yes! Here's the blogpost if anyone's interested, notes another member, indicating a wealth of information provided.
- Request for More Context: A member requested others to share resources and context related to the discussion, opening the floor for additional insights.
- Share with resources/context became the call for collaborative learning among members.
Link mentioned: no title found: no description found
HuggingFace ▷ #NLP (12 messages🔥):
Training Topic ClustersSetfit Serialization IssuevLLM Deployment for NERFine-tuning Token Embeddings
- Training Topic Clusters Challenges: A member expressed difficulty in obtaining a sensible number of topics without extensive manual merging, finding it unfeasible for production.
- In response, another member shared their experience deploying zero-shot systems and suggested flexible handling of new topics.
- Setfit Serialization Parameter Inquiry: One member inquired about a parameter in Setfit that prevents the saving of serialized safetensors due to memory constraints on a cluster.
- Others mentioned that the 'save_strategy' might help to manage checkpoint saving during training.
- Optimizing NER with vLLM: A member discussed deploying LLMs with vLLM and explored improving performance for the bert-base-NER model for Named Entity Recognition.
- They inquired about combining pipelines with vLLM for NER tasks and sought simpler packaging alternatives after successful setup on Triton.
- Fine-tuning New Token Embeddings: A member asked how to finetune only the embeddings of newly added tokens in a model while preserving the existing tokens' embeddings.
- This question indicates ongoing discussions on managing model updates without disrupting established token functionalities.
Link mentioned: dslim/bert-base-NER · Hugging Face: no description found
HuggingFace ▷ #diffusion-discussions (4 messages):
Google ColabDiffusion ModelsFlux ModelSDXL LightningWürstchen Model
- Google Colab free tier supports various models: Members discussed the feasibility of running diffusion models on the Google Colab free tier, noting that most models can be utilized effectively.
- One member emphasized the need for specificity in defining 'relatively performant' models when seeking recommendations.
- Flux Model shines as an open-source contender: A member recommended using the Flux model, stating it's the best open-source diffusion model and can be run in Colab without issues.
- However, they cautioned that generating images might take a considerable amount of time with this model.
- SDXL Lightning for quicker image generation: For faster image generation, members suggested SDXL Lightning type models as a solid alternative to Flux, offering decent quality images.
- This option was noted as particularly favorable for users prioritizing speed over high fidelity.
Nous Research AI ▷ #announcements (1 messages):
Hermes 3Llama-3.1 8BHuggingChat
- Hermes 3 Launches on HuggingChat: The latest release of Hermes 3 in 8B size is now available on HuggingChat, showcasing improved instruction adherence.
- This model is part of the Nous Research offerings, designed to enhance user interaction.
- Instruction Following Enhanced: Hermes 3 has significantly improved its ability to follow instructions, enabling better performance in chat interactions.
- Users can expect more accurate and contextually relevant responses compared to previous versions.
Link mentioned: HuggingChat: Making the community's best AI chat models available to everyone.
Nous Research AI ▷ #general (214 messages🔥🔥):
Llama 3.2 Model ReleaseQuantization vs. DistillationNew Innovations in AI TrainingHermes 3 UpdateLocalization of Models
- Llama 3.2 model performance insights: Llama 3.2 has been released with multiple sizes, generating discussions about its performance, particularly in comparison to smaller models like Llama 1B and 3B.
- Users noted specific capabilities and limitations of these models, with some praising their ability to generate functional code.
- Debate on quantization vs. distillation: The conversation highlighted that while Meta favors distillation for model compression, quantization remains relevant due to its complementary benefits and efficiency on various hardware.
- Participants pointed out the importance of both techniques in addressing memory and computational needs for different applications.
- Training Innovations and Improvements: Questions arose regarding advancements in AI training techniques post-DPO, focusing on the effectiveness of model distillation.
- The community expressed curiosity about continual innovations in optimizing model training.
- Hermes 3 on HuggingChat: The release of Hermes 3 on HuggingChat was noted, featuring Llama 3.1 in an 8B configuration aimed at closely following instructions.
- This update reflects ongoing developments in the application of advanced language models.
- Localization challenges for AI models: Concerns were raised about the constraints on using low-precision models like Llama 3.2 for complex tasks, especially in various languages.
- The discourse emphasized that while smaller models can generate English, they struggle with more nuanced tasks like coding and foreign language generation.
- Tweet from Daniel Han (@danielhanchen): Llama 3.2 multimodal is here! Model sizes from 1B, 3B to 11B and 90B!
- no title found: no description found
- Tweet from AI at Meta (@AIatMeta): 📣 Introducing Llama 3.2: Lightweight models for edge devices, vision models and more! What’s new? • Llama 3.2 1B & 3B models deliver state-of-the-art capabilities for their class for several on-devi...
- Llama 3.2 Re-upload - a alpindale Collection: no description found
- HuggingChat: Making the community's best AI chat models available to everyone.
- bartowski/Llama-3.2-3B-Instruct-GGUF · Hugging Face: no description found
- Llama 3.2 3B Instruct - a Hugging Face Space by huggingface-projects: no description found
- bartowski/Llama-3.2-1B-Instruct-GGUF · Hugging Face: no description found
- Meta Connect 2024 Full Event Livestream. Meta Quest 3S & More: Meta Connect 2024 livestream full event reveals the meta Quest 3S and more. This is the yearly meta connect where we finally got the announcement of the Meta...
- Layla Lite APK for Android Download: no description found
- hugging-quants/Llama-3.2-1B-Instruct-Q8_0-GGUF · Hugging Face: no description found
- Llama 3.2 1B & 3B Benchmarks: Posted in r/LocalLLaMA by u/TKGaming_11 • 67 points and 5 comments
- Molmo Models Outperform Llama 3.2 in Most Vision Benchmarks 🌟: Posted in r/LocalLLaMA by u/shrewdeenger • 55 points and 7 comments
- GitHub - kyutai-labs/moshi: Contribute to kyutai-labs/moshi development by creating an account on GitHub.
- no title found: no description found
- Qwen2.5-LLM: Extending the boundary of LLMs: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD Introduction In this blog, we delve into the details of our latest Qwen2.5 series language models. We have developed a range of decoder-only dense models, w...
- Llama 3.2: The open source AI model you can fine-tune, distill and deploy anywhere. Our latest models are available in 8B, 70B, and 405B variants.
Nous Research AI ▷ #ask-about-llms (25 messages🔥):
Sample Packing TechniquesTokenizers in Model TrainingLLaMA 3.2 Vision Encoder
- Innovative Sample Packing Raises Performance Questions: A discussion arose around the implementation of sample packing when training a small GPT-2 model, with members highlighting potential degradation of performance if done naively.
- One participant suggested that using the proposed method could lead to suboptimal results despite the possibility of zeroing out attention scores.
- The Role of Special Tokens in Sentence Contexts: It was suggested that adding special tokens like 'endoftext' could help clarify sentence boundaries in training, though some considered it not strictly necessary.
- Another member mentioned that most off-the-shelf tokenizers automatically include special tokens if specified in their configuration.
- Success with Tokenizer Swaps Remains Uncertain: The potential for successful tokenizer swaps across models sparked inquiry, particularly about Huggingface tokenizers managing special tokens.
- The conversation revealed uncertainty about the custom tokenizers' capability in this regard compared to existing ones.
- LLaMA 3.2 Vision Encoder's Impressive Size: A member shared insights about the LLaMA 3.2 Vision Encoder, noting its vast sizes of 18B and 3B for different model variants.
- Discussion highlighted that the text decoder remains consistent with previous versions (L3.1), leading to curiosity about the implications of the encoder's size.
Nous Research AI ▷ #research-papers (2 messages):
Character Video SynthesisResume ATS BuilderJob Recommendation Systems
- MIMO Framework Revolutionizes Character Video Synthesis: A novel framework called MIMO proposes a solution for realistic character video synthesis by generating videos with controllable attributes like character, motion, and scene through simple user inputs.
- It aims to overcome limitations of 3D methods requiring multi-view captures and enhances pose generality and scene interaction using advanced scalability to arbitrary characters.
- Advice Needed for Resume ATS and Job Recommendations: One member shared their experience working on a resume ATS builder and a job matching and recommendation system, feeling lost in their search for quality research papers.
- They seek guidance from others on how to efficiently approach their research efforts in this area.
Link mentioned: Paper page - MIMO: Controllable Character Video Synthesis with Spatial Decomposed Modeling: no description found
Nous Research AI ▷ #interesting-links (2 messages):
Opus Insight updatesSonnet 3.5 review processThinkLab explorationO1-preview functionality
- Opus Insight introduces O1mini: The latest update of Opus Insight incorporates O1mini, enhancing its multi-model template with comprehensive model adjustments and ranking reviews.
- In this process, Sonnet 3.5 handles the initial review before O1mini conducts the final review and model ranking.
- ThinkLab powered by Sonar Huge 405b: ThinkLab utilizes the Sonar Huge 405b model for web searches, emphasizing its utility for scratchpad usage and follow-up searches to broaden exploration.
- This approach aims to streamline the exploration process and enhance user interaction with the content.
- Rate limits of O1-preview feature: O1-preview is available as an option in the Wordware app, but it is rate limited, which can cause stalls if it doesn't return data.
- This feature is added to the app but disabled by default; users can enable it by clicking 'create my own version' to test the dedicated O1-preview flow.
- OPUS Insight : Latest Model Ranking - o1mini: This prompt processes a question using the latest models,and provides a comprehensive review and ranking. Update: 9/25/2024 - added: o1mini, Gemini 1.5 Flash, Command R+ . Note: o1-preview is part...
- _Think-Lab Revised - o1mini: (version 1.10) Use the power of ScratchPad-Think for every day web searches. Export refined search queries in JSON format. The scratchpad is a powerful tool that helps you maintain coherence and accur...
Nous Research AI ▷ #research-papers (2 messages):
Character video synthesisResume ATS builderJob recommendation systems
- MIMO Framework for Character Video Synthesis: The MIMO framework proposes a method for synthesizing realistic character videos with controllable attributes like character, motion, and scene, all from simple user inputs.
- It aims to address limitations of traditional 3D methods and existing 2D approaches by achieving scalability, generality, and interactivity in a unified framework.
- Searching for Quality Research in Resume Systems: A member expressed feeling lost while searching for research papers to assist in building a resume ATS builder and job recommendation system.
- Advice was sought on how to effectively approach this search in the vast amount of available research.
Link mentioned: Paper page - MIMO: Controllable Character Video Synthesis with Spatial Decomposed Modeling: no description found
aider (Paul Gauthier) ▷ #general (95 messages🔥🔥):
Llama 3.2 ReleaseAider FunctionalityVector DatabasesMeta ConnectSonnet 3.5 Errors
- Llama 3.2 Launch: Meta has announced the release of Llama 3.2, including small and medium-sized vision LLMs and lightweight models suitable for edge and mobile devices.
- These new models aim to provide more accessible AI capabilities for developers without extensive resources, as highlighted during Meta Connect.
- Aider's Potential Expansions: Users discussed the limitations of Aider without built-in translation features and emphasized the need for better documentation indexing.
- There is interest in adding functionalities like voice feedback and automatic documentation searches to enhance user experience.
- Vector Database Options: Members shared their thoughts on local vector databases, with mentions of Chroma, Qdrant, and the potential of PostgreSQL with vector extensions.
- While SQLite and PostgreSQL can perform vector DB tasks, dedicated vector databases are seen as more efficient for heavy workloads.
- Ongoing Sonnet 3.5 Issues: An incident regarding Sonnet 3.5 led to elevated errors for users, which has been reported and resolved on the Anthropic status page.
- This incident indicates the ongoing fluctuations in availability and performance of Anthropic's models, impacting user workflows.
- Engagement During Meta Connect: Members were actively engaged in discussions about Meta Connect, sharing insights about the new models being announced, such as Llama 3.2.
- Discussion included thoughts on how these announcements might affect usage and development considerations moving forward.
- Scale | SEAL Leaderboard: Coding Evaluation: Scale’s SEAL Coding Leaderboard evaluates and ranks top LLMs on programming languages, disciplines, and tasks.
- Repository map: Aider uses a map of your git repository to provide code context to LLMs.
- 22M views · 33K comments | Meta Connect 2024 | Join Mark Zuckerberg as he shares Meta’s vision for AI and the metaverse, including Meta’s newest product announcements. Then stay with us for the... | By Meta for DevelopersFacebook: Join Mark Zuckerberg as he shares Meta’s vision for AI and the metaverse, including Meta’s newest product announcements. Then stay with us for the...
- /llms.txt—a proposal to provide information to help LLMs use websites – Answer.AI: We propose that those interested in providing LLM-friendly content add a /llms.txt file to their site. This is a markdown file that provides brief background information and guidance, along with links...
- no title found: no description found
- Reddit - Dive into anything: no description found
- Elevated Errors on Claude 3.5 Sonnet: no description found
- GitHub - mendableai/firecrawl: 🔥 Turn entire websites into LLM-ready markdown or structured data. Scrape, crawl and extract with a single API.: 🔥 Turn entire websites into LLM-ready markdown or structured data. Scrape, crawl and extract with a single API. - mendableai/firecrawl
aider (Paul Gauthier) ▷ #questions-and-tips (104 messages🔥🔥):
Aider Model IssuesUsing Aider with PDFsTesting Aider with Various ModelsAider's Token UsageIntegrating External Libraries and Analyzers
- Concerns about Claude Sonnet's Performance: Users have reported issues with Claude Sonnet 3.5 exhibiting decreased performance and comprehension of codebases, leading to errors and incorrect assumptions.
- Some users, however, managed to improve results by switching to models like Gemini Pro 1.5 for specific prompts and then reverting back to Sonnet.
- Aider's Functionality with PDF Files: Discussion highlighted that PDF files are binary formats that LLMs cannot read, and users should convert them to text formats for better comprehension.
- Using tools like Jina Reader was suggested as a method to convert URLs to text, but concerns were raised about the parsing of equations in LaTeX.
- Switching Aider Models for Better Outputs: Several users have noted varying degrees of success with different models, which led some to explore switching to other LLMs to achieve better coding results.
- The general consensus is to monitor and report on model performance using Aider's benchmark suite to ensure accurate assessments.
- Understanding Aider's Token Management: Users frequently checked their token usage with the
/tokenscommand to manage their context and avoid excessive memory errors.- Maintaining a lean context was crucial for effective performance, as larger token usage often led to misunderstanding or incomplete comprehension of code.
- Integrating External Libraries in Aider: A user expressed concern about Aider's ability to handle specific Rust libraries and other external analyzers, which could hinder its effectiveness in generating correct code.
- The integration of these resources was framed as essential for improving the LLM’s performance in accurately coding with complex language rules.
- Model warnings: aider is AI pair programming in your terminal
- File editing problems: aider is AI pair programming in your terminal
- Reader API: Read URLs or search the web, get better grounding for LLMs.
- Tutorial videos: Intro and tutorial videos made by aider users.
- In-chat commands: Control aider with in-chat commands like /add, /model, etc.
- How to forward option-enter (alt-enter) to terminal? · zed-industries/zed · Discussion #18149: i'm having trouble sending option-enter keypresses to the terminal, i've read this https://zed.dev/docs/key-bindings#forward-keys-to-terminal and in my keymap i've tried the following: [ {...
aider (Paul Gauthier) ▷ #links (4 messages):
par_scrape toolshot-scraper utilityLlama 3.2 Multimodalo1-preview bug fixing
- Discover the par_scrape tool: A member shared an interesting tool on GitHub called par_scrape, aimed at simplifying web scraping tasks.
- It's noted that this tool could be more efficient compared to alternatives.
- Shot-scraper beats expectations: Another member highlighted the shot-scraper utility as a good alternative, stating it’s easier for some tasks than par_scrape.
- Dang, this is a good tool emphasizes its capabilities as a command-line utility for automated website screenshots.
- Llama 3.2 Multimodal in the spotlight: A link to a Reddit post titled 'Llama 3.2 Multimodal' was shared, awaiting moderator approval for further discussion.
- It stimulates interest in the latest advancements surrounding the Llama model.
- Fixing LLM bugs with o1-preview: A post discussed solving a bug with o1-preview, noting a new feature added to DJP for plugin metadata positioning.
- The author shared their experience addressing a test failure using files-to-prompt combined with OpenAI’s LLM.
- Solving a bug with o1-preview, files-to-prompt and LLM: I added [a new feature](https://github.com/simonw/djp/issues/10) to DJP this morning: you can now have plugins specify their metadata in terms of how it should be positioned relative to other metadata...
- Reddit - Dive into anything: no description found
- GitHub - paulrobello/par_scrape: Contribute to paulrobello/par_scrape development by creating an account on GitHub.
- shot-scraper: no description found
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
Database UpgradeAPI Completion Response ChangesGemini Model UpdatesNew Vision Language ModelsCohere Models Discount
- Scheduled Database Upgrade to Cause Downtime: A database upgrade is set for Friday at 10am ET, expected to result in 5-10 minutes of downtime.
- Users are advised to prepare accordingly for potential service interruptions.
- API Enhancements in Response Outputs: The provider used to serve requests is now included directly in the completion response.
- This update aims to streamline the amount of information returned to users.
- Gemini Models Routing Updated: Gemini-1.5-flash and Gemini-1.5-pro are now routed to the newest 002 version.
- This change is part of ongoing improvements to the Gemini model lineup.
- Exciting New Vision Language Models Launched: OpenRouter now features a collection of new open-source vision language models, ready for interaction.
- Models include Mistral Pixtral 12B and Qwen2-VL series, with users encouraged to engage them in the chatroom.
- 5% Discount on All Cohere Models: A 5% discount has been launched on all Cohere models, exclusively on OpenRouter.
- Users can explore the flagship model with 128k context at the provided link.
- Command R+ - API, Providers, Stats: Command R+ is a new, 104B-parameter LLM from Cohere. It's useful for roleplay, general consumer usecases, and Retrieval Augmented Generation (RAG). Run Command R+ with API
- Pixtral 12B - API, Providers, Stats: The first image to text model from Mistral AI. Its weight was launched via torrent per their tradition: https://x. Run Pixtral 12B with API
- Qwen2-VL 7B Instruct - API, Providers, Stats: Qwen2 VL 7B is a multimodal LLM from the Qwen Team with the following key enhancements: - SoTA understanding of images of various resolution & ratio: Qwen2-VL achieves state-of-the-art performanc...
- Qwen2-VL 72B Instruct - API, Providers, Stats: Qwen2 VL 72B is a multimodal LLM from the Qwen Team with the following key enhancements: - SoTA understanding of images of various resolution & ratio: Qwen2-VL achieves state-of-the-art performan...
OpenRouter (Alex Atallah) ▷ #general (169 messages🔥🔥):
GPTs Agents PerformanceOpenRouter Model AvailabilityMistral Image Recognition IssuesLlama 3.2 ReleaseOpenRouter API Rate Limits
- GPT4o Mini vs Gemini 1.5 Flash: Members tested GPT4o Mini and Gemini 1.5 Flash, noting GPT4o Mini performed but didn't adhere strictly to constraints while Flash was faster but gave unreliable outputs.
- Concerns were raised about the speed and adherence to requirements, especially in relation to the context size.
- Mistral's Pixtral Model Performance: A member reported that mistralai/pixtral-12b is producing hallucinations and poor output, while other models perform well with image recognition.
- It was suggested that although Pixer is not the best, Gemini Flash models are more cost-effective for similar tasks.
- Excitement for Llama 3.2 Release: Announcement of the upcoming Llama 3.2 included smaller models aimed at easier deployment for development on mobile and edge devices.
- The community showed interest in whether Llama 3.2 would be available on OpenRouter soon.
- Rate Limiting on OpenRouter API: Discussion indicated that users were encountering rate limits after sending consecutive requests to the OpenRouter API.
- Clarifications were provided regarding the rate limit being tied to the usage of credits and request frequency.
- Translation Model Suggestions: A user inquired about the best model for translation, leading to discussions about the trade-offs between size, accuracy, and language commonality.
- Recommendations included testing different models based on the specific use case and requirements.
- Chatroom | OpenRouter: LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Llama 3.2 Acceptable Use Policy: Llama 3.2 Acceptable Use Policy
- Activity | OpenRouter: See how you've been using models on OpenRouter.
- Transforms | OpenRouter: Transform data for model consumption
- no title found: no description found
- Limits | OpenRouter: Set limits on model usage
- phind-codellama: Code generation model based on Code Llama.
- Gemini Flash 8B 1.5 Experimental - API, Providers, Stats: Gemini 1.5 Flash 8B Experimental is an experimental, 8B parameter version of the [Gemini 1. Run Gemini Flash 8B 1.5 Experimental with API
- Elevated Errors on Claude 3.5 Sonnet: no description found
- no title found: no description found
OpenRouter (Alex Atallah) ▷ #beta-feedback (2 messages):
Local Server SupportAPI Access Conditions
- Challenges of Supporting Local Servers: It was noted that running services locally without external access makes support difficult, indicating limited assistance in the near future.
- If you're running it locally, support may not be feasible.
- Potential for Future API Support: Support might become available for endpoints accessible via HTTPS that adhere to an OpenAI-style schema with an API key.
- This opens the door for potential collaborations down the line, should these criteria be met.
OpenAI ▷ #ai-discussions (110 messages🔥🔥):
Advanced Voice Mode AvailabilityMeta AI RestrictionsLlama 3.2 LicensingGame Development with AIAI Character Interactions
- Advanced Voice Mode Distribution Debate: Members expressed frustration over the limited rollout of the Advanced Voice mode, with many in the EU still lacking access despite claims of availability for all users.
- Comments highlighted the disparity in features for different regions, particularly pointing out that previous features like memory were similarly delayed for EU users.
- Meta AI's EU Conflict: Discussion clarified that Meta AI is not available for users in the EU, UK, and other countries due to licensing restrictions on multimodal models.
- Members noted that Llama 3.2's license is explicitly incompatible with EU regulations, limiting its access to developers in those regions.
- Llama 3.2 Model Features: The introduction of Llama 3.2 was announced, focusing on multimodal capabilities with improved models but with tight licensing restrictions for EU users.
- Details shared included the model's launch on Hugging Face and its technical specifications, highlighting it as a leap forward in the model lineup despite licensing hurdles.
- AI IDE Tools for Game Development: A user sought recommendations for the best AI IDE options for game development, looking for tools that can write and execute code for auditing.
- Suggestions included paid cloud services like Cursor and community-driven tools, with some users leveraging ChatGPT for file system modifications.
- The Future of AI and Parcel Delivery: A thought-provoking idea emerged about using brain interfaces and encrypted mailing addresses to streamline parcel delivery without traditional address systems.
- While ideation sparked interest, participants noted the importance of moving beyond ideas to actual implementation.
- Reddit - Dive into anything: no description found
- Llama can now see and run on your device - welcome Llama 3.2: no description found
OpenAI ▷ #gpt-4-discussions (8 messages🔥):
Voice Functionality with GPTComplex Tasks Handling by GPTComparative Efficiency of AI Models
- GPT cannot make calls: A member clarified that ChatGPT currently cannot call other GPTs and that users have to perform actions themselves.
- A suggestion has been submitted to allow such functionality in the future.
- Complex tasks cause delays: A user reported frustration with GPT's inability to complete a complex book-writing task on time, receiving feedback like 'I am working on it.'
- After several days of waiting, the user is concerned that GPT's responses aren't producing satisfactory results, delivering only two pages of work when prompted.
- Skepticism on GPT's capabilities: One member expressed doubt about GPT's capability to handle complex tasks without constant prompting and adjustments.
- Another suggested that while GPT may struggle, using models like o1-preview and Claude could yield better results.
- Preference for alternative AI models: A user mentioned that they find Claude and o1-preview models more suitable for complex tasks due to longer memory windows.
- They shared their extensive use of paid models, indicating interest in comparative feedback.
OpenAI ▷ #prompt-engineering (24 messages🔥):
Minecraft API promptingFeedback mechanisms in AIEssay grading challengesModel output variabilityPrompt engineering best practices
- Refining Minecraft API Prompts: Members discussed optimizing prompts for the Minecraft API to reduce repetitive questions and improve variety by specifying different related topics and complexity levels in the queries.
- Suggestions included guiding the AI to avoid repeating earlier questions and to enforce a structured JSON output format.
- Challenges in Grading Essays: A member sought ways to fine-tune the model for providing brutally honest feedback on essays with specific scoring metrics, citing leniency in responses as a major concern.
- Advice was given on providing detailed rubrics and samples while noting that the model's inherent design encourages positive reinforcement, which may clash with the need for harsh critiques.
- Prompts and Model Guidance Effectiveness: Discussion highlighted how precise and positive language when communicating with the AI can yield better results, especially when defining expectations like 'brutally honest feedback'.
- Members noted the importance of clarity in prompts and the potential mismatch between what users expect versus what the model understands as helpful.
OpenAI ▷ #api-discussions (24 messages🔥):
Prompt Engineering for Minecraft QuestionsChallenges with Feedback ModelsFine-Tuning Models for Essay Feedback
- Improving Minecraft Question Prompts: Members discussed ways to enhance prompts for generating unique and engaging Minecraft-related questions, suggesting more specific question topics like mechanics and mobs.
- One member expressed frustration with repetition in output, seeking advice on how to modify the prompt to ensure variety and consistency.
- Struggles with AI Feedback Systems: A discussion arose about the AI's tendency to provide overly lenient feedback on essays, with suggestions to encourage more brutally honest critiques.
- One member noted that the model is designed to be supportive, which may clash with expectations for harsher evaluations of writing.
- Fine-Tuning for Honest Essay Feedback: There was a conversation on whether fine-tuning a model could yield brutally honest feedback on essays, with members debating the effectiveness of various prompting techniques.
- Tips included providing example essays with score metrics to guide the AI's feedback, emphasizing that the model's goal is often to be constructive even when striving for honesty.
LM Studio ▷ #general (145 messages🔥🔥):
Llama 3.2 ModelsSillyTavern IntegrationMultimodal CapabilitiesModel Performance BenchmarksSupport for New Models
- Llama 3.2 Launch Sparks Excitement: The recent release of Llama 3.2, including models like the 1B and 3B, has generated significant interest, particularly for its speed on various hardware setups.
- Users are eager for support for the 11B multimodal model, but it is noted that support may take time due to its vision model nature.
- Integration Issues with SillyTavern: Users are experiencing integration issues with SillyTavern when using LM Studio, mainly related to server communication and response generation.
- Troubleshooting suggests that SillyTavern may require specific task inputs rather than freeform text prompts.
- Concerns Over Multimodal Model Capabilities: Discussions highlighted that while Llama 3.2 includes a vision model, users were seeking true multimodal capabilities akin to GPT-4.
- Clarifications indicated that **Llama 3.2's 11B model is only for vision tasks and does not include voice or video functions yet.
- Benchmarking Model Performance: Benchmark results for Llama 3.2 have shown varied performance with the 1B and 3B achieving scores of 49.3% and 63.4%, respectively.
- Comparisons with Qwen2.5 models reveal similar performance, indicating competitive capabilities among different language models.
- Future Support and Development Plans: Expectations are set for additional support for new models, with ongoing discussions about the feasibility of implementing various quantization levels.
- As advancements continue, users express optimism regarding the integration of NPU capabilities and faster inference speeds for future releases.
- program.pinokio: Pinokio Programming Manual
- no title found: no description found
- Llama 3.2 3B & 1B GGUF Quants - a hugging-quants Collection: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Qwen2.5 (self-reported) now on official MMLU-Pro leaderboard, beats Gemini 1.5 Pro and Claude 3 Opus: https://huggingface.co/spaces/TIGER-Lab/MMLU-Pro
- NEW Flux in Forge. How to guide. Flux Img2Img + Inpainting: Flux Forge tutorial guide https://www.patreon.com/posts/110007661Chat with me in our community discord: https://discord.gg/dFB7zuXyFYStable Diffusion for Beg...
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- GitHub - THUDM/LongWriter: LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs: LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs - THUDM/LongWriter
- GitHub - chigkim/Ollama-MMLU-Pro: Contribute to chigkim/Ollama-MMLU-Pro development by creating an account on GitHub.
- llama.cpp/gguf-py/scripts/gguf_new_metadata.py at master · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- image processing for llama3.2 by pdevine · Pull Request #6963 · ollama/ollama: Image processing routines for being able to run llama3.2. This will need to be refactored at some point to support other multimodal models as well.
- Google Colab: no description found
- Tweet from elvis (@omarsar0): The prompting guide for Gemma 7B Instruct is live! I started to document a few examples of how to prompt Gemma. Based on a few tests, it feels like a fun and very capable model. The chain-of-though...
LM Studio ▷ #hardware-discussion (17 messages🔥):
Price Discrepancies in TechDual GPU Setup in LM StudioPerformance of RTX 3090Vulkan and Mixed GPU Types
- Price Discrepancies Cause Frustration: Users expressed frustration over the higher tech prices in the EU, noting they can be twice as much compared to the US.
- Not fair! said one member, while another pointed out that VAT plays a significant role in this difference.
- LM Studio Supports Dual GPU Setup: A member inquired about using an RTX 4070ti and RTX 3080 together, to which it was confirmed that LM Studio supports dual GPU setups if they are the same type.
- Others debated the potential of using varying GPU types with Vulkan, suggesting it could be a good experiment.
- Expectations for RTX 3090 TPS: Discussion on the transactions per second (TPS) for the RTX 3090 revealed expected performance of about 60-70 TPS on a Q4 8B model.
- Clarifications were made that this performance is more suitable for inference training rather than simple queries.
- Experimenting with Mixed GPUs in Vulkan: A user shared their experience using an RTX 2070 and RX 7800 together with Vulkan, achieving a total of 24GB VRAM for loading LLMs.
- They noted that the performance of different LLMs varies, with some running slower and others faster when loaded on both GPUs.
- Income Taxes GIF - Income Tax Tax Taxes - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
Eleuther ▷ #general (19 messages🔥):
yt-dlp toolPyTorch training attribute issueLocal LLM benchmark suiteFoundation model engineer hiringControlling diffusion models
- Introducing yt-dlp for Audio/Video Downloading: A member shared a GitHub link to yt-dlp, a feature-rich command-line audio/video downloader, suggesting its utility as a preexisting tool.
- Concerns were raised about malware, but it's noted that the source repository appears clean.
- PyTorch Training Attribute Bug: A known issue was discussed regarding PyTorch where calling either
.eval()or.train()does not change the.trainingattribute of thetorch.compile()module, as detailed in this GitHub issue.- Members shared frustrations about the lack of visibility of such issues and discussed potential workarounds like modifying
mod.compile().
- Members shared frustrations about the lack of visibility of such issues and discussed potential workarounds like modifying
- Seeking Local LLM Benchmark Suite: A member requested recommendations for open-source benchmark suites for local LLM testing, mentioning specific benchmarks like MMLU and GSM8K.
- Another member provided a link to the lm-evaluation-harness, which serves as a framework for few-shot evaluation of language models.
- Hiring Foundation Model Engineers: A member is promoting job openings for foundation model engineers and shared social media links to boost engagement.
- The member encouraged resharing or liking their posts on LinkedIn and X to enhance visibility.
- Challenges in Controlling Diffusion Models: Discussion centered around the difficulties in controlling latent diffusion models for image generation, citing a tweet from Advex about the fidelity vs faithfulness tradeoff.
- They mentioned existing models like DALLE-3 and ControlNet that struggle with this balance and highlighted Advex's research aims.
- Tweet from Qasim Wani (@qasim31wani): Controlling LDMs (latent diffusion model) is hard. 😓 Being able to control exact image you want to generate is holy grail of image generation. Numerous papers have studied this problem from differe...
- `training` property of complied models is always `True`: I noticed that I can’t set the training property to False for modules that I have compiled, regardless of the state of the property when the module was compiled. Is this expected behaviour? A demo: ...
- `.eval()` and `.train()` don't set value of `.training` properly on `torch.compile()` module · Issue #132986 · pytorch/pytorch: 🐛 Describe the bug Calling either .eval() or .train() doesn't change .training value of torch.compile() module, it only changes that value for the underlying module. Reproduction code: import tor...
- GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models.: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- GitHub - yt-dlp/yt-dlp: A feature-rich command-line audio/video downloader: A feature-rich command-line audio/video downloader - yt-dlp/yt-dlp
Eleuther ▷ #research (70 messages🔥🔥):
NAIV3 Technical ReportBERT Masking RatesModel Training TechniquesCrowd-Sourced DatasetsSUNDAE Model Insights
- NAIV3 Technical Report Released: The NAIV3 Technical Report discusses a dataset of 6 million images from crowd-sourced platforms, raising visibility on specifics like image tagging methods.
- Discussions included whether to include humorous elements like a crown image, based on prior projects' documents.
- Exploring Higher BERT Masking Rates: A member queried if anyone has trained BERT-like models with over 15% masking, leading to insights about higher rates improving performance, particularly in larger models.
- Another entry linked to a study indicating that 40% masking outperformed 15%, and noted that extremely high rates maintain fine-tuning performance.
- Training Techniques in the Open Source Community: Members expressed dissatisfaction with the perceived simplicity of the current project work, hinting that complexity is undervalued in community feedback.
- Comments implied that the expectation for 'novel insights' could undercut the project's recognition, with fears that minor improvements may not satisfy reviewers.
- Insights on Crowd-Sourced Data Usage: The conversation highlighted how utilizing data from platforms like Danbooru needs careful framing to avoid aggravating potential critics.
- Mentioning a standardization of practices for training on specific image formats added a layer of professional development in scholarly discourse.
- Follow-up on SUNDAE Training Methodology: Discussion on the SUNDAE model revealed its use of randomized masking across a range from 0 to 1, though its primary focus was machine translation.
- There were inquiries about any follow-ups to SUNDAE, noting a lack of current developments as the interest shifted towards text diffusion techniques.
- Tweet from Lexin Zhou (@lexin_zhou): 1/ New paper @Nature! Discrepancy between human expectations of task difficulty and LLM errors harms reliability. In 2022, Ilya Sutskever @ilyasut predicted: "perhaps over time that discrepancy w...
- Improvements to SDXL in NovelAI Diffusion V3: In this technical report, we document the changes we made to SDXL in the process of training NovelAI Diffusion V3, our state of the art anime image generation model.
- Should You Mask 15% in Masked Language Modeling?: Masked language models (MLMs) conventionally mask 15% of tokens due to the belief that more masking would leave insufficient context to learn good representations; this masking rate has been widely us...
Eleuther ▷ #scaling-laws (9 messages🔥):
Decomposing modelsScaling laws datapointsBroken neural scaling laws datasetGoogle research findings
- Decomposing models using Strassen-inspired methods: A member suggested that models could potentially be decomposed in a Strassen-inspired manner to reduce the number of addition and subtraction operations.
- This method may allow the model to approximate results similar to a full model without full complexity.
- Seeking Data Points for Scaling Laws: A request was made for sources of datapoints regarding scaling laws, specifically for architecture trained with different parameters and dataset sizes.
- The inquiry aimed to test if including a missing lower-order term in Chinchilla's scaling laws would affect compute-optimal choices.
- Using the Broken Neural Scaling Laws Dataset: A member recommended using the broken neural scaling laws dataset, stating that it is comprehensive but lacks architecture details.
- Without architecture specifics, it becomes challenging to train new models and gather data points tailored to personal needs.
- Google Research Paper References: A discussion referenced a google research paper that provides results on GitHub related to neural scaling laws, but primarily contains raw datapoints.
- Members noted that despite these data points being what was requested, there is no easy method to replicate or extend the results.
Link mentioned: google-research/revisiting_neural_scaling_laws/README.md at master · google-research/google-research: Google Research. Contribute to google-research/google-research development by creating an account on GitHub.
Eleuther ▷ #interpretability-general (1 messages):
Chain-of-thought responsesFiller tokens efficacyHuman-like task decompositionTransformers and algorithmic tasks
- Chain-of-thought responses boost performance: Recent research reveals that chain-of-thought responses from language models significantly enhance performance across most benchmarks, as outlined in the paper Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.
- However, the study questions whether performance gains stem from human-like task decomposition or merely the increased computation from additional tokens.
- Filler tokens can replace thought chains: The experiment showed that transformers could utilize meaningless filler tokens (e.g., '......') to tackle complex algorithmic tasks that they otherwise couldn't solve without intermediate tokens.
- Yet, the research emphasizes that teaching models to use these filler tokens demands specific, dense supervision to achieve effective learning.
- Filler tokens and quantifier depth: The Paper provides a theoretical framework identifying a class of problems where filler tokens are advantageous, linking their efficacy to the quantifier depth of first-order formulas.
- Within this framework, it is shown that for certain problems, chain-of-thought tokens need not convey information about intermediate computations.
- Hidden thinking embedding remains debatable: A query was raised about the existence of a 'hidden thinking embedding' behind the token text, indicating uncertainty around its establishment.
- This highlights an ongoing discussion in the community regarding the mechanisms underlying model responses and the validity of task decomposition.
Link mentioned: Let's Think Dot by Dot: Hidden Computation in Transformer Language Models: Chain-of-thought responses from language models improve performance across most benchmarks. However, it remains unclear to what extent these performance gains can be attributed to human-like task deco...
Eleuther ▷ #lm-thunderdome (40 messages🔥):
Pile model formatting issueslm_eval usage with OpenAI APIAexams task evaluationExact match metricsDebugging sequence length errors
- Reference for Pile model formatting issues: A member asked for references regarding the 'Pile model sucks at formatting', leading to the suggestion of citing the paper Lessons from the Trenches for relevant data.
- Another member confirmed that the same results could also be observed for the ARC-Challenge in the paper's current table.
- Using lm_eval with OpenAI API for plaintext tests: A user inquired about running tests without pre-tokenization in lm_eval against the OpenAI API, and another member confirmed that the
openai-chat-completionswon't tokenize when using--apply_chat_template.- For
openai-completions, addingtokenized_requests=Falseto--model_argswas suggested as a solution.
- For
- Evaluating issues with the aexams task: A member expressed concern over the empty Groups table when running evaluations on the aexams task with Claude 3.5 Sonnet, despite seeing results for subtasks.
- Another member advised that the
_aexams.yamlconfiguration should be updated to useexact_matchaggregation instead ofacc.
- Another member advised that the
- Debugging sequence length errors in generate_until: A member encountered a sequence length error exceeding
self.max_lengthwhile debugging thegenerate_untilfunction in the harness.- They suspect the issue may stem from overriding
tok_batch_encode, which could lead to unintended context encoding results.
- They suspect the issue may stem from overriding
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- [BUG] Eval recipe not using max_seq_length · Issue #1644 · pytorch/torchtune: 2024-09-21:20:19:56,843 INFO [_logging.py:101] Running EleutherEvalRecipe with resolved config: batch_size: 1 checkpointer: _component_: torchtune.training.FullModelHFCheckpointer checkpoint_dir: ....
- lm-evaluation-harness/lm_eval/models/huggingface.py at bc50a9aa6d6149f6702889b4ef341b83d0304f85 · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/models/huggingface.py at bc50a9aa6d6149f6702889b4ef341b83d0304f85 · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #multimodal-general (1 messages):
Non-casual maskingAR masks and positional information
- AR Masks Aid Positional Learning: A member clarified that the assertion only applies to non-casual masking; using an AR mask enables the model to acquire positional information.
- This distinction is crucial for understanding how masks influence model training and input processing.
- Understanding Masking Effects: Another member discussed the general effects of various masking techniques on models, emphasizing the need for clear definitions.
- They noted that confusion often arises when comparing casual and non-casual masking strategies.
Perplexity AI ▷ #general (123 messages🔥🔥):
Perplexity AI updatesChatGPT voice mode capabilitiesO1 preview accessIssues with context retentionUsage of AI tools for school
- Perplexity AI struggles with context retention: Users have expressed frustration with Perplexity not retaining context for follow-up questions, noting that this issue has become more frequent recently.
- Several members discussed their experiences, suggesting that the platform's performance may have declined, impacting its usefulness.
- Merlin.ai offers O1 with web access: Merlin.ai has been recommended as an alternative since it offers O1 capabilities with web access, without a daily message limit, just a rate limit.
- Users have shown interest in exploring Merlin for its extended functionalities compared to Perplexity.
- Users weigh in on AI tools for education: Several users discussed their reliance on AI tools for school-related tasks, with some favoring GPT-4o and others considering Claude as alternatives.
- Feedback included acknowledgment of various AI tools providing different levels of assistance, especially with academic needs.
- Concerns over Perplexity's performance decline: Users noted a perceived decline in Perplexity's performance, with fewer detailed responses compared to previous experiences.
- Concerns were raised regarding potential financial issues impacting the platform's capabilities, with users sharing their thoughts on alternatives.
- Llama 3.2 release news: The announcement of the Llama 3.2 model has generated excitement among users, with mentions of its availability and capabilities.
- However, some users noted the absence of Llama 3.2's information on Perplexity, indicating a possible gap in available resources.
- Sir Sir Sir GIF - Sir Sir Sir Give Me That - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- Perplexity Full Tutorial: WILD Ai Research Tool! (A-Z Guide): ⚡Join Ai Foundations: https://swiy.co/aif-0In today's video I'm going to be teaching you everything you need to know about Perplexity. This ai tool brings th...
Perplexity AI ▷ #sharing (6 messages):
Air Fryers Worth It4-Day Workout PlanJony Ive's OpenAI ProjectAntarctica's Ozone HoleFashion Industry Research
- Evaluating Air Fryers: A user shared a link discussing whether air fryers are worth it, focusing on their benefits and drawbacks.
- Key points include health benefits versus traditional frying methods and efficiency in cooking.
- 4-Day Workout Plan for Beginners: A member provided a link to a 4-day workout plan for beginners aimed at those new to fitness.
- The program focuses on building a solid routine while being manageable for newcomers.
- Jony Ive's OpenAI Project Discussion: A fascinating YouTube video titled YouTube covers Jony Ive's OpenAI Project, detailing innovative intersections of design and AI.
- The video also touches on notable topics like Antarctica's ozone hole and an ancient cosmic signal.
- Investigating Fashion Industry Trends: A user sought information on the fashion industry, prompting discussions on current trends and sustainability.
- Key discussions centered around the industry's environmental impact and its evolving practices.
- Soldered RAM Obsolescence Explained: Discussion arose around the obsolescence of soldered RAM, analyzing impacts on system upgrades.
- Participants expressed concerns about future-proofing devices as RAM becomes increasingly non-upgradable.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (9 messages🔥):
Wolfram Alpha integrationPerplexity API capabilitiesWebhook Zap structureScripting web interface usageExternal models availability
- Wolfram Alpha integration with Perplexity API: A user inquired if it's possible to utilize Wolfram Alpha with the Perplexity API like its functionality on the web app.
- Another member confirmed that currently it is not possible, highlighting the independence of the API and web interface.
- API vs Web Interface for Math and Science: There was a question about whether the API is as capable as the web interface when solving math and science problems.
- No conclusive answers were provided in the discussions surrounding this capability.
- Clarification on Webhook Zap Structure: A user using Perplexity inside a Zapier webhook sought clarification on its structure, specifically regarding system and user content.
- They proposed that system content is instructions for the AI, while user content is the input given to the AI.
- Availability of External Models: A user noted that external models seem to be accessible only through the web interface, not the API.
- They inquired about scripting the usage of the web interface in a manner supported by Perplexity, but no responses were given.
Interconnects (Nathan Lambert) ▷ #news (32 messages🔥):
Anthropic FinancialsOpenAI Training Data AccessMolmo Model PerformanceMolmo Model CapabilitiesMolmo License Changes
- Anthropic Expected to Surpass $1B Revenue: According to CNBC, Anthropic is on track to achieve $1B in revenue this year, marking an astounding 1000% year-over-year growth.
- The revenue breakdown reveals 60-75% from third-party APIs, 10-25% from direct APIs, 15% from Claude subscriptions, and a small 2% from professional services.
- OpenAI Offers Access to Training Data: For the first time, OpenAI will provide access to its training data for review regarding any copyrighted works used, as shared by a member.
- Access will be offered on a secured computer at OpenAI's San Francisco office without internet or network access, prompting mixed reactions in the community.
- Excitement Over Molmo Model Capabilities: The new Molmo model has generated buzz with a member commenting that its pointing feature is one of the most exciting AI capabilities they've seen in a while, claiming it's more impactful than a higher AIME score.
- The model's performance, as noted during various comparisons, shows it's truly impressive, and feedback suggests it 'passes the vibe check'.
- Discussion of Molmo Model Benchmarks: Comparing the largest Molmo model (72B) to Llama 3.2 V 90B, members shared specific benchmark results indicating Molmo's superiority in several areas like AI2D and ChatQA.
- Overall, discussions pointed to favorable metrics, with one member humorously expressing surprise at the model's good performance despite their modest role in its development.
- Concerns Regarding Changes in Molmo License: A member raised questions about significant differences in the 3.2 license compared to 3.1, prompting others to analyze the changes.
- They shared a diff checker link for deeper examination of the licensing text.
- Tweet from Mira Murati (@miramurati): I shared the following note with the OpenAI team today.
- Tweet from Colin Fraser (@colin_fraser): I've never been more vindicated Quoting Colin Fraser (@colin_fraser) What if it actually looks like this?
- Tweet from Omar Sanseviero (@osanseviero): Molmo by @allenai - a SOTA multimodal model 🤗Open models and partially open data 🤏7B and 72B model sizes (+7B MoE with 1B active params) 🤯Benchmarks above GPT-4V, Flash, etc 🗣️Human Preference of...
- Tweet from Tanay Jaipuria (@tanayj): Per CNBC, Anthropic is expected to hit $1B in revenue this year, roughly a ~1000% increase y/y. Breakdown of revenue is: • Third Party API (via Amazon, etc): 60-75% • Direct API: 10-25% • Claude chat...
- Tweet from Ben (e/treats) (@andersonbcdefg): i havent felt as excited about a new AI model ability in a while as i do about the Molmo pointing feature. for someone trying to build a product (not a god) i would argue this might be more impactful ...
- Tweet from morgan — (@morqon): “for the first time, openai will provide access to its training data for review of whether copyrighted works were used”
- Tweet from morgan — (@morqon): “the training datasets will be made available at openai’s san francisco office on a secured computer without internet or network access”
- Tweet from Nathan Lambert (@natolambert): Comparing the biggest Molmo model (72B) to Llama 3.2 V 90B MMMU, Llama is higher by 6 pTS MathVista, Molmo up 1 pt ChatQA Molmo up 2 AI2D Molmo up 4 DocVQA up 3 VQAv2 about the same or molmo better ...
- llama 3.2 vs 3.1 - Diffchecker: llama 3.2 vs 3.1 - LLAMA 3.1 COMMUNITY LICENSE AGREEMENT Llama 3.1 Version Release Date: July 23, 2024 “Agreement” mea
Interconnects (Nathan Lambert) ▷ #ml-questions (15 messages🔥):
Twitter and BloggingOpenAI's Recent AnnouncementsHugging Face CollectionsLate Fusion in Visual Language ModelsPlaying with GPT-4
- Twitter and Blogging Acknowledgement: A member recognized their Twitter and blog presented in an unironical manner, highlighting their use of these platforms.
- They also hinted at a personal contribution to organizing a lecture without further details.
- OpenAI's Voice Announcements Spark Discussion: A member noted that OpenAI's recent voice announcements prompted a reflection on potential model releases beyond just updates, referencing more complex systems.
- They suggested potential connections between Interconnects Artifacts, Models, datasets, and the systems mentioned.
- Overview of Hugging Face Collections: Details were shared about the organization's Hugging Face collections, specifically regarding the 2024 Interconnects Artifacts.
- The collection includes models such as argilla/notux-8x7b-v1, updated as recently as March 4.
- Investigating Late Fusion Visual LMs: Questions were raised about the performance of late fusion visual language models on text benchmarks and their potential gains compared to Tulu recipes.
- The member expressed curiosity about possible degradations in model performance with visual inputs.
- Playing with GPT-4's Image Input: A member shared their experimentation with GPT-4, testing it with and without image input to analyze its performance.
- They observed that the model routes to a different model when presented with images and pondered its comparative intelligence.
- [18 April 2024] Aligning open language models: Aligning open language models Nathan Lambert || Allen Institute for AI || @natolambert Stanford CS25: Transformers United V4
- 2024 Interconnects Artifacts - a natolambert Collection: no description found
Interconnects (Nathan Lambert) ▷ #ml-drama (24 messages🔥):
OpenAI Team ChangesDrama in AI CompaniesAnthropic's PositionInvestor ConfidenceLatest OpenAI News
- OpenAI's exodus raises eyebrows: Members pointed out that almost all of the original OpenAI team has left, besides Sam Altman, prompting discussions about the implications of this mass departure.
- One member asserted that it can't be a stronger signal than this, suggesting a sense of instability within the organization.
- Concerns about leadership fit: A member questioned whether the recent departure of a prominent leader was a negative signal, suggesting that she may not have fit the role well.
- Another noted that while her exit is concerning, OpenAI still leads in model development and investor support.
- Drama fuels speculation: The continual drama surrounding OpenAI seems to have taken center stage, with discussions hinting that the company orchestrates events to overshadow competitors like Molmo.
- One member remarked how sketchy everything feels, reflecting widespread concern over the state of affairs at OpenAI.
- Possibility of moves to Anthropic: Speculation arose about whether a former OpenAI leader moving to Anthropic could further shift the industry landscape, with one saying it would signify a major disruption.
- Another member contrasted Anthropic's seriousness with OpenAI's drama, suggesting they operate with a clearer mandate.
- Greg's challenges amid turbulence: The atmosphere surrounding OpenAI is described as brutal for Greg, likely indicating challenges faced by its leadership amidst the upheaval.
- This sentiment was echoed by multiple members, who expressed doubts about the current trajectory of the company.
- Tweet from undefined: no description found
- Tweet from Mira Murati (@miramurati): I shared the following note with the OpenAI team today.
Interconnects (Nathan Lambert) ▷ #random (22 messages🔥):
UV Python Tool EnhancementFTC AI Crackdown AnnouncementData Dependencies in ScriptsDocker Integration with UVLLaMA Stack Discussion
- UV Python Tool Enhances Package Management: A user recommended starting to use
uv pip install XYfor insane speedups, particularly advising use ofpyproject.tomlfor managing dependencies and usinguv run myfile.pyfor script execution.- "This is a literal gamechanger" with newly supported inline script dependencies enhances usability significantly.
- FTC Cracks Down on AI Scams: The FTC has announced an AI-related crackdown that has raised eyebrows due to its vague standards about what constitutes real AI Inside.
- As one commentator noted, "What even is AI? IDK but FCC will tell you after suing!"
- Docker Integration Tips for UV: For using UV in Docker, a user referred to the documentation and mentioned a GitHub example showing best practices.
- The available Docker images, including distroless and alpine variants, simplify command execution by running
docker run ghcr.io/astral-sh/uv --help.
- The available Docker images, including distroless and alpine variants, simplify command execution by running
- Discussion on LLaMA Stack Importance: A user inquired about the significance of the 'LLaMA Stack' in relation to recent updates, speculating it might be just tool integrations.
- Another member agreed, saying they felt it was "just integrations imo. Not important" based on their findings.
- User Sentiment on PyCharm's UV Integration: Concerns were raised about UV's functionality with PyCharm due to its handling of virtual environments, prompting a user to share a GitHub repository as a potential workaround.
- The experience was summarized with the sentiment that even “the UX of
uvis amazing” despite some integration clunkiness.
- The experience was summarized with the sentiment that even “the UX of
- Tweet from OpenAI (@OpenAI): Advanced Voice is not yet available in the EU, the UK, Switzerland, Iceland, Norway, and Liechtenstein.
- Running scripts | uv: no description found
- Tweet from Colin Fraser (@colin_fraser): I've never been more vindicated Quoting Colin Fraser (@colin_fraser) What if it actually looks like this?
- Docker | uv: no description found
- Tweet from Charlie Dolan (@cdolan92): FTC announced AI related crackdowns Hot Take: Good! There's a lot of scams On further reading: WTF!? Example: what in the world does this mean? "...our technologists can figure out [if your...
- Tweet from Han (@HanchungLee): o1-preview reasoning ability 1. accuracy converges to ~85% on 9.11 vs 9.8. 2. not 100% instruction following 3. reasoning outputs at ~10 TPS 4. empty response when max_completion_token < reason...
Interconnects (Nathan Lambert) ▷ #memes (8 messages🔥):
Artificial General Intelligence (AGI)Social Media ImpactsXeophon QuotesTransformative OpportunitiesPublic Reactions
- AGI Predictions by Leopold Aschenbrenner: Leopold Aschenbrenner's SITUATIONAL AWARENESS predicts that we are on course for Artificial General Intelligence (AGI) by 2027, followed by superintelligence soon after, presenting significant opportunities and risks. This was highlighted in a tweet shared by Ivanka Trump.
- The message emphasized the importance of understanding these potential shifts in technological capabilities.
- Debate on Tweets and Followers: There was a humorous conversation about whether to pursue tweets and followers related to the interconnects topic, with one member questioning if it's really wanted. Xeophon responded with skepticism, asking, 'Do you really want those tweets and followers?'.
- The lighthearted back-and-forth raised doubts about the value of social media engagement.
- Tweet from Ivanka Trump (@IvankaTrump): Leopold Aschenbrenner’s SITUATIONAL AWARENESS predicts we are on course for Artificial General Intelligence (AGI) by 2027, followed by superintelligence shortly thereafter, posing transformative oppor...
- Tweet from Crypto Unc (@UncCrypto): Quoting Xeophon (@TheXeophon) It actually is so over
Interconnects (Nathan Lambert) ▷ #rl (2 messages):
Reinforcement LearningCurriculum LearningDemonstration DataSimulation in Robotics
- Enhancing RL with Curriculum Learning: Recent research proposes using curriculum learning to improve Reinforcement Learning (RL) efficiency by leveraging offline demonstration data from previous tasks, which can ease exploration problems in complex environments. Their approach consists of a reverse curriculum followed by a forward curriculum, resulting in effective policies trained on narrow state distributions.
- These methods were compared with similar efforts by DeepMind's Demostart methodology, emphasizing the challenge of acquiring high-quality demonstration data, particularly in robotics.
- Niche Applications of Curriculum Learning: The efficiency of curriculum learning is attributed to its ability to leverage demonstration data and reset environments to previously seen states, optimizing training processes. However, the reliance on simulation means that real-world applications are limited, which can deter participation from some researchers.
- This niche requirement underscores both the innovation in reinforcement learning strategies and the inherent challenges that come with the necessity for simulated environments.
Link mentioned: Reverse Forward Curriculum Learning for Extreme Sample and Demonstration Efficiency in Reinforcement Learning: Reinforcement learning (RL) presents a promising framework to learn policies through environment interaction, but often requires an infeasible amount of interaction data to solve complex tasks from sp...
Interconnects (Nathan Lambert) ▷ #posts (25 messages🔥):
Llama 3.2 ReleaseMultimodal ModelsMolmo Model PerformanceMeta's Edge Device IntegrationCommunity Reactions
- Llama 3.2 officially launched: Llama 3.2 has been released with several model sizes, including 1B, 3B, 11B, and 90B, aimed at enhancing both text and multimodal capabilities.
- Initial reactions suggested it might be a bit rough around the edges, but availability is better now than later during busier hours.
- Multimodal models disrupt the landscape: Members noted that Molmo, a new multimodal model, is reportedly outperforming Llama 3.2 90B on certain benchmarks, highlighting competitive advancements.
- Commentary suggested congratulations were in order for both the Llama and Molmo teams for their impressive offerings.
- Meta integrates Llama for edge devices: Meta introduced Llama 3.2 as suitable for edge devices with support from major partners like Arm and Qualcomm, showcasing its on-device capabilities.
- The announcement emphasizes the intent to expand open-source AI usage across various platforms and partnerships.
- Community buzz on Llama's readiness: Discussion revealed mixed feelings about Llama 3.2’s immediate deployment, with some speculating on its timing tactics while eagerly anticipating official updates.
- A member remarked on having 3.5 hours of meetings, jokingly balancing the hectic schedule with the excitement of the new release.
- Hints and deleted tweets fuel speculation: Hugging Face members hinted at potential updates regarding Llama, specifically by Julien Chaumond, whose tweet was subsequently deleted, adding to the intrigue.
- Members actively refreshed Llama's website in hopes of obtaining new information, showcasing a dedicated and engaged community.
- Tweet from Daniel Han (@danielhanchen): They seem to have deleted their pre-release 😅 - it was uploaded to https://www.llama.com/ and https://ai.meta.com/ a few minutes ago (kept refreshing lol)
- Tweet from Daniel Han (@danielhanchen): Llama 3.2 multimodal is here! Model sizes from 1B, 3B to 11B and 90B!
- Tweet from AI at Meta (@AIatMeta): 📣 Introducing Llama 3.2: Lightweight models for edge devices, vision models and more! What’s new? • Llama 3.2 1B & 3B models deliver state-of-the-art capabilities for their class for several on-devi...
- Tweet from xjdr (@_xjdr): Interesting context. Wow, congrats llama and molmo teams
- Tweet from Andrew Curran (@AndrewCurran_): This little 1B is strong. Mr Z said on stage they are embedding a local model on the new glasses, I guess this might be it.
- Tweet from Alex Volkov (Thursd/AI) (@altryne): What have we here? Just in time for MultiModal models to be disrupted by Meta (reporting soon!), the great folks at @allen_ai releasing a multimodal MOLMO! 2 SOTA vision models in 1 day?? > With...
GPU MODE ▷ #torch (22 messages🔥):
Diffusion Transformer Policy for Imitation LearningTorch Profiler File Size IssuesPytorch Kernel Performance ImprovementUnderstanding torch.float8_e4m3fnEmbedding Data Loading from GPU
- Exploring SAM2-fast with Diffusion Transformers: Discussion centered on using SAM2-fast as input to a Diffusion Transformer Policy for imitation learning, specifically for mapping camera sensor data to robotic arm joint positions.
- Image/video segmentation annotation was suggested as a potential requirement for this approach.
- Torch Profiler Generates Massive Files: Torch profiler is producing excessively large files (up to 7GB) which can't be loaded in Chrome Tracer, prompting discussions about making files smaller.
- Suggestions included profiling for only essential items and exporting traces as .json.gz to compress the output.
- Improving Pytorch Kernel Performance: A user sought advice on improving kernel performance in PyTorch without writing a kernel in CUDA, sharing a relevant discussion link.
- Members offered general strategies for boosting performance, although specifics weren't extensively detailed.
- Clarifying torch.float8_e4m3fn Terminology: Questions arose about the meaning of
fnin torch.float8_e4m3fn and the reasoning behindtorch.finfo(torch.float8_e4m3fn).maxbeing 448.- The conversation clarified that
0 1111 111represents NaN, thus explaining the limit on maximum values.
- The conversation clarified that
- Resource for Understanding float8 in GPUs: A user shared a link to a GitHub resource that provides detailed information about float8 representation and usage in machine learning ops.
- This serves as a go-to reference for those seeking clarity on the topic, particularly regarding fp8 and its specifications.
- Improving Pytorch kernel performance: My code (for a somewhat degenerate matmul) looks like this: def opt_foo(out, i1, i2, j1, j2, idx): out[i1*512:i2*512].view(i2-i1, 512).add_(torch.mm(A[idx:idx+(i2-i1)*(j2-j1)].view(j2-j1,i2-i1).t...
- `training` property of complied models is always `True`: I noticed that I can’t set the training property to False for modules that I have compiled, regardless of the state of the property when the module was compiled. Is this expected behaviour? A demo: ...
- stablehlo/rfcs/20230321-fp8_fnuz.md at main · openxla/stablehlo: Backward compatible ML compute opset inspired by HLO/MHLO - openxla/stablehlo
GPU MODE ▷ #cool-links (17 messages🔥):
New Course ReleasePranav Marla's O1 AlternativeNVIDIA ASR Model OptimizationLlama 3.2 AnnouncementLocal AI Model Performance
- New Course Just Launched!: It’s good; I built it—members confirmed the newly released course is a success, coming out today.
- One member expressed interest in checking it out after hearing positive feedback.
- Pranav Marla's O1 Alternative Shines: Check out Pranav Marla's O1 alternative, which is transparent, self-healing, and performs shockingly well on reasoning problems.
- This model is designed with features like infinite recursion and a Python interpreter, making it promising for various applications.
- Optimizing ASR Models with NVIDIA: An interesting blog post discusses NVIDIA's ASR models that have set benchmarks in speed and accuracy.
- One key takeaway is about automatic mixed precision not performing as expected during inference, which caught attention among ML researchers.
- Llama 3.2 Models Unveiled by Meta: Meta announced the arrival of Llama 3.2, featuring smaller vision and text models designed for edge and mobile devices.
- These models include 11B and 90B vision LLMs and 1B and 3B text models, aiming to expand accessibility for developers.
- Discussing Local AI Models: It was suggested that having models like Phi locally could be more practical, especially with specific fine-tuning approaches.
- There was a discussion on using distilled versions of models, highlighting potential for improved local AI performance.
- Tweet from trees of thought (@pranavmarla): I built an o1 alternative, that is: 1) Fully transparent, visually trackable 2) Infinitely recursive 3) Self-healing, with tests at every step 4) Capable of using a Python interpreter It performs sh...
- no title found: no description found
- Accelerating Leaderboard-Topping ASR Models 10x with NVIDIA NeMo | NVIDIA Technical Blog: NVIDIA NeMo has consistently developed automatic speech recognition (ASR) models that set the benchmark in the industry, particularly those topping the Hugging Face Open ASR Leaderboard.
GPU MODE ▷ #jobs (2 messages):
Luma Engineering RolesMeta Community Projects
- Luma seeks top engineers for optimization: Luma is looking for strong engineers to work on performance optimization for their Dream Machine and other multimodal foundation models, offering visa sponsorship for in-person candidates.
- They require experience in large-scale distributed training, low-level kernels, and optimizing distributed inference workloads, emphasizing fast shipping and minimal bureaucracy.
- Join Meta for exciting community projects: Meta invites applications to work on community projects related to PyTorch, including GPU MODE and the NeurIPS LLM efficiency competition, highlighting the role's freedom and flexibility.
- Interested candidates can apply through the Meta careers page and are encouraged to ask any questions regarding the position.
Link mentioned: Software Engineer, Systems ML - PyTorch Performance and Engagement: Meta's mission is to give people the power to build community and bring the world closer together. Together, we can help people build stronger communities - join us.
GPU MODE ▷ #beginner (12 messages🔥):
CUDA code in PythonCustom Ops in PyTorchBeginner Projects
- Porting CUDA Code Made Easy: To wrap standalone CUDA code in Python, members suggested using load_inline from PyTorch, as discussed in lecture 1.
- Another member mentioned that while it is straightforward, custom ops would be the best practice solution for integration.
- Custom Ops Without Graph Break: Discussion revealed that you can integrate custom kernels in PyTorch without a graph break, simplifying development.
- However, members acknowledged the packaging process can be a bit annoying, hoping the provided resources make it easier.
- Request for Beginner Project Ideas: A member expressed a desire for a list of beginner-friendly projects, seeking options beyond the algorithms presented in video lectures.
- They noted that the projects in working groups appear daunting for newcomers.
- Regular Events Scheduled: A member updated that there are Friday events scheduled, stating speakers are being lined up currently.
- The Events tab will be updated as new sessions are arranged, making it easier for members to keep track.
- Channel for Article Discussion: A member communicated that a new channel was created for article discussions to keep other channels focused on conversation.
- Another member expressed gratitude and agreed to repost their content in the appropriate channel.
Link mentioned: ao/torchao/csrc at main · pytorch/ao: PyTorch native quantization and sparsity for training and inference - pytorch/ao
GPU MODE ▷ #torchao (1 messages):
RoPE cache in FP32Torchao Llama
- RoPE Cache Should Always Be FP32: A member raised a question regarding the RoPE cache in the Torchao Llama model, suggesting that it should always be in FP32 format.
- They referred to the specific lines of code in the repository that might clarify the reasoning.
- Discussion on Code Behavior for Torchao Llama: The conversation included details about the behavior of Torchao Llama's code, particularly the implementation of the RoPE cache.
- Participants expressed concerns over the handling of precision in the caching mechanism, emphasizing its significance for performance.
Link mentioned: ao/torchao/_models/llama/model.py at 7dff17a0e6880cdbeed1a14f92846fac33717b75 · pytorch/ao: PyTorch native quantization and sparsity for training and inference - pytorch/ao
GPU MODE ▷ #off-topic (16 messages🔥):
GPU Mode Name IdeasLambda Labs CreditsMascot Suggestions
- Creative Names for GPU Mode: A discussion emerged on potential names for GPU mode, with ideas like Accelerator Mode and Accel Mode being floated, alongside appreciation for the name GPU mode.
- Goku was suggested as a mascot example, highlighting a fun community spirit.
- Questions on Lambda Labs Credits: One member inquired about the status of the $300 credits from Lambda Labs for IRL attendees, noting a lack of visibility in their accounts.
- Others noted that the Lambda credits were a one-off, but mentioned that services like Prime Intellect and Modal should still show credit activity.
- Feedback on Lambda and Prime Intellect Usability: Members shared their experiences with Lambda Labs, where one noted it was the easiest to use, especially while transitioning from a 3070.
- It was pointed out that Prime Intellect runs on Lambda, making it a seamless transition option.
GPU MODE ▷ #triton-puzzles (3 messages):
CUDA puzzlesMachine Learning in PMP book
- Searching for CUDA Puzzles: Locknit3 inquired if there are any platforms similar to Triton Puzzles specifically for raw CUDA.
- A suggestion for a resource was shared: GPU Puzzles, which offers puzzles to help learn CUDA.
- Lack of Machine Learning Content in PMP Book: Locknit3 expressed disappointment, stating that the PMP book does not include any references to machine learning.
- This indicates a possible gap in integrating AI topics within traditional project management literature.
Link mentioned: GitHub - srush/GPU-Puzzles: Solve puzzles. Learn CUDA.: Solve puzzles. Learn CUDA. Contribute to srush/GPU-Puzzles development by creating an account on GitHub.
GPU MODE ▷ #llmdotc (13 messages🔥):
RoPE implementationFused RMSNorm integrationLlama 3.1 and 3.2 supportCUDA kernel development
- RoPE Implementation Doesn't Match 3.1 Scaling: A member pointed out that the current RoPE implementation does not support the RoPE scaling introduced in version 3.1.
- Another member shared their efforts, stating they've added RoPE code that adjusts PyTorch for real-valued calculations and prepares for CUDA implementation.
- Fused RMSNorm Reference Found: A member shared a GitHub pull request as a reference for fused RMSNorm, signaling ongoing development efforts.
- The suggested reference outlined a mathematical property relevant to the RoPE implementation.
- Successful RoPE Forward Integration: The same member confirmed that the RoPE forward functionality has been added and tested successfully.
- They also mentioned the next step involves integrating fused RMSNorm after completing the RoPE updates.
- Fused RMSNorm Integrated Successfully: The integration of fused RMSNorm forward was successfully completed, with plans for the next implementation of SwiGLU.
- This integration received a thumbs up, indicating progress in the overall development.
- Excitement for Llama 3.2: A member expressed enthusiasm for the new Llama 3.2 model, specifically mentioning the 1B variant, showcasing excitement in the community.
- This adds an element of anticipation and interest in future capabilities of the model.
- Fused rmsnorm reference by gordicaleksa · Pull Request #769 · karpathy/llm.c: fyi @karpathy
- add llama 3 support to llm.c by karpathy · Pull Request #754 · karpathy/llm.c: This branch starts with a copy paste of train_gpt2.cu and test_gpt2.cu, but these two files (and other files) will change to incorporate Llama 3.1 support, before merging back to master.
GPU MODE ▷ #rocm (6 messages):
MI250xGroupedGemm examplesAMD Instinct™ GPU TrainingArchitecture Development
- MI250x targets: The hardware being targeted in the discussion includes the MI250x GPU, as mentioned by a participant.
- This highlights a focus on AMD's advanced GPU offerings in computing tasks.
- AMD Instinct™ GPU Training Details: Information about the AMD Instinct™ GPU Training provided by HLRS was shared, including a link to materials for the upcoming course.
- The course covers various topics, such as programming models and OpenMP offloading strategies on AMD GPUs.
- Clarification on Examples for GroupedGemm: A user expressed uncertainty about choosing among multiple GroupedGemm examples, needing guidance to select an appropriate one.
- This indicates challenges in navigating example implementations, particularly for those new to the subject.
- Architecture Building for MI250x: The discussion included suggestions to potentially build a small architecture to start experimenting with the MI250x.
- This implies a strategic approach to initial experimentation and development on the hardware.
- Confidence in Example Runs: Participants agreed that if an example runs successfully, it confirms readiness for further use on the MI250x.
- This reflects the collaborative nature of troubleshooting and knowledge sharing in hardware utilization.
Link mentioned: AMD Instinct™ GPU Training: no description found
GPU MODE ▷ #bitnet (2 messages):
TorchAO PR for BitNetOptimized Inference KernelModel Training Plans
- TorchAO Pull Request for BitNet b1.58 Ready: A member announced that the TorchAO PR #930 is ready, adding training code for BitNet b1.58 with ternary weights and implemented as a tensor subclass.
- This version is a notable upgrade from the previous binary weights implementation, integrating smoothly with the quantization framework.
- Call for Optimized Inference Kernel Development: Members discussed the importance of someone working on an optimized inference kernel, suggesting a baseline similar to gemlite A8W2.
- This is positioned as a necessary enhancement to complement the newly implemented training code.
- Plans for Toy Model Training: A member expressed intentions to train a toy model to handle between 10B-100B tokens, leaning towards the lower end of that range.
- They encouraged contributions from others for additional computing resources to support this effort.
Link mentioned: BitNet b1.58 training by gau-nernst · Pull Request #930 · pytorch/ao: This PR adds training code for BitNet b1.58 (ternary weights - 1.58 bit. The first version of BitNet is binary weights). This is implemented as tensor subclass and integrate nicely with the quantiz...
GPU MODE ▷ #arm (4 messages):
iPhone 16 performanceSME on A18 chipMetal benchmarks on GitHub
- Curiosity Surrounds iPhone 16 SME Performance: A member inquired if anyone has experimented with the SME on iPhone 16, noting claims it can handle 14 or 16 int8 operations. This sparked interest in the capabilities of the new A18 chip as well.
- Another user clarified the performance context, linking it to the M4 chip while prompting a deeper discussion on benchmarks.
- A New iPhone 16 Pro User Steps Up: One member announced they just got an iPhone 16 Pro and offered to test the SME performance. They shared a link to metal-benchmarks for further exploration of Apple GPU microarchitecture.
- This link provides resources for anyone interested in understanding the capabilities of Apple's GPU advancements in more detail.
Link mentioned: GitHub - philipturner/metal-benchmarks: Apple GPU microarchitecture: Apple GPU microarchitecture. Contribute to philipturner/metal-benchmarks development by creating an account on GitHub.
GPU MODE ▷ #webgpu (1 messages):
Compute Pass Pipeline BehaviorWorkgroup Dispatch Visibility
- Compute Pass Behavior with Pipe Switching: A user inquired whether all writes from pipe1 dispatch would be visible in the subsequent pipe2 dispatch when set in the same compute pass sequence.
- This parallels behavior seen in CUDA streams, where operations are often serialized and visibility is maintained across different pipelines.
- Seeking Clarity on Pipeline Writes: A member raised a question about the visibility of writes when switching pipelines within a compute pass, specifically if the output of one can be seen in the next.
- This relates to how CUDA streams function, where writes from one operation can be explicitly managed to ensure visibility in subsequent operations.
GPU MODE ▷ #liger-kernel (23 messages🔥):
Jensen-Shannon Divergence BenchmarkLambda Labs UsageSyncBatchNorm Implementation
- JSD Kernel Pull Request Discussed: A member shared a link to the JSD kernel pull request on GitHub which resolves issue #252, emphasizing distributions in log-space.
- The details indicate the use of Jenson-Shannon Divergence for comparing two distributions.
- Cost-Effective GPU Access via Lambda Labs: A member mentioned using Lambda Labs for GPU access at approximately $2/hour, making it a budget-friendly option for running benchmarks and final fine-tuning.
- They emphasized the ease of use with SSH access and pay-per-use flexibility, suitable for various projects.
- Graph Visualizations Available Post-Benchmark: One member confirmed that after running an individual benchmark, the results would be saved to a CSV and graphs would be accessible in the visualizations folder.
- This provides an easy way to visualize and analyze benchmark results.
- SyncBatchNorm Implementation Efforts: A member announced plans to implement SyncBatchNorm, referring to the official PyTorch documentation for guidance.
- They highlighted its role in applying batch normalization over N-dimensional inputs and its core functionality as described in the original batch normalization paper.
- Virtual environments and Docker containers | Lambda Docs: no description found
- SyncBatchNorm — PyTorch 2.4 documentation: no description found
- Add JSD kernel by Tcc0403 · Pull Request #264 · linkedin/Liger-Kernel: Summary Resolve #252 Details JSD We expect input $X$ and target $Y$ are distributions in log-space, i.e., $X = log Q$ and $Y = log P$. Jenson-Shannon Divergence between two distributions $P$ and $Q...
GPU MODE ▷ #metal (2 messages):
Metal AtomicsMemory Barrier SemanticsWorkgroup Scheduling
- Metal Atomics Limit Decoupled Messaging: Understanding the metal atomics and memory barrier semantics suggests that achieving decoupled look-back or message passing between workgroups requires constructing an array of atomic bytes with atomic load/stores for all operations.
- Ideally, only the flag would use atomics, allowing for fast non-atomic loads to read data.
- Random Workgroup Scheduling Observed: In practice, blocks appear to be scheduled in an essentially random manner, which diminishes the likelihood of features for message passing being added soon.
- This scheduling behavior raises concerns about the practicality of implementing more efficient communication between workgroups.
GPU MODE ▷ #self-promotion (1 messages):
GPU Performance OptimizationDeep Learning Applications with GPUsNVIDIA NsightGPU Programming Languages
- Blog Post Launch: Optimize GPU Performance: A new blog post discusses how to enhance GPU performance in deep learning, focusing on GPU architecture and performance monitoring tools like NVIDIA Nsight.
- The article emphasizes that experimentation and benchmarking are key to improving hardware utilization in deep learning applications.
- GPUs Driving Deep Learning Innovations: The discussion highlights how GPU computing facilitates advancements in diverse fields like autonomous vehicles and robotics, thanks to high-speed parallel processing.
- It’s essential to understand optimizing GPU performance to prioritize faster and more cost-effective training and inference of neural networks.
Link mentioned: An Introduction to GPU Performance Optimization for Deep Learning | DigitalOcean: no description found
OpenAccess AI Collective (axolotl) ▷ #general (82 messages🔥🔥):
Run Pod IssuesMolmo 72B AnnouncementOpenAI's Recent DevelopmentsLlama 3.2 ReleaseMeta and EU Controversy
- Run Pod Issues Persist: Users reported experiencing illegal CUDA errors on Run Pod, with some suggesting switching machines to resolve the issue.
- One user humorously advised against using Run Pod due to ongoing issues, highlighting the frustration it causes.
- Molmo 72B: A New Multimodal Contender: The Molmo 72B, developed by the Allen Institute for AI, boasts state-of-the-art benchmarks and is built on the PixMo dataset of image-text pairs.
- It is highlighted as Apache licensed and supports various modalities, aiming to compete with leading multimodal models like GPT-4o.
- OpenAI Faces Organizational Changes: A bombshell moment occurred with the resignation of OpenAI's CTO, prompting speculation about the company's marketing and future direction.
- Members discussed the potential implications for OpenAI, musing about the internal dynamics potentially leading to a Netflix mini-series.
- Llama 3.2 Rollout Sparks Interest: Llama 3.2's introduction features lightweight models for edge devices, sparking discussions about its various model sizes ranging from 1B to 90B.
- Multiple sources confirmed the phased rollout, with some users expressing excitement and curiosity about the performance of the new models.
- Meta's Compliance Issues in the EU: Conversations revealed Meta's concerns about complying with EU laws, leading to restricted access for users in Europe.
- The discussions alluded to a license change that may have impacted the availability of models, igniting a deeper exploration of the company's motivations.
- Tweet from AI at Meta (@AIatMeta): 📣 Introducing Llama 3.2: Lightweight models for edge devices, vision models and more! What’s new? • Llama 3.2 1B & 3B models deliver state-of-the-art capabilities for their class for several on-devi...
- Tweet from Daniel Han (@danielhanchen): Llama 3.2 multimodal is here! Model sizes from 1B, 3B to 11B and 90B!
- no title found: no description found
- axolotl/src/axolotl/utils/chat_templates.py at main · axolotl-ai-cloud/axolotl: Go ahead and axolotl questions. Contribute to axolotl-ai-cloud/axolotl development by creating an account on GitHub.
- allenai/Molmo-72B-0924 · Hugging Face: no description found
- Llama 3.2: The open source AI model you can fine-tune, distill and deploy anywhere. Our latest models are available in 8B, 70B, and 405B variants.
- Fixing/Adding Mistral Templates by pandora-s-git · Pull Request #1927 · axolotl-ai-cloud/axolotl: Description This PR has come objective fixing the templates and making them match as closesly as possible the ground truth (Mistral Common), a document delves into details this issue here. Motivat...
- Fine-tuning | How-to guides: Full parameter fine-tuning is a method that fine-tunes all the parameters of all the layers of the pre-trained model.
- PurpleLlama/Llama-Guard3/1B/MODEL_CARD.md at main · meta-llama/PurpleLlama: Set of tools to assess and improve LLM security. Contribute to meta-llama/PurpleLlama development by creating an account on GitHub.
- Tweet from Mira Murati (@miramurati): I shared the following note with the OpenAI team today.
OpenAccess AI Collective (axolotl) ▷ #general-help (9 messages🔥):
Axolotl with MetaflowUsing rope_thetaTool calling for fine-tuning
- Axolotl struggles in Metaflow pipelines: A member attempted running Axolotl in a Metaflow pipeline but faced issues loading the step with the Axolotl docker image, while a more generic python image worked fine.
- They suspect that MetaFlow constructs a custom docker entrypoint that is incompatible with the Axolotl image and noted that the system setup blocked pulling other public repositories.
- Discussion on tool alternatives: A member suggested that the current consensus for a tool is to use rope_theta but admitted they haven't had the time to read about its setup.
- Another asked if they had tried other images to verify whether the issue was with Axolotl specifically.
- Fine-tuning for tool calling considerations: A member sought advice on how to fine-tune for tool calling and wondered if using Alpaca for this purpose would be beneficial.
- They later shared a configuration example involving activating or deactivating a night mode feature.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (5 messages):
Illegal CUDA Memory AccessCUDA Version CompatibilityNVIDIA Driver UpdatesCompute Sanitizer UsageError Checking in CUDA
- Steps to Fix Illegal CUDA Memory Access: To fix an illegal CUDA memory access error, users should check CUDA version compatibility with libraries like PyTorch using
nvcc --version.- Updating NVIDIA drivers and the CUDA toolkit can often resolve these types of compatibility issues.
- Use Environment Variables for Debugging: Setting
CUDA_LAUNCH_BLOCKING=1allows CUDA operations to run synchronously, aiding in identifying the exact line causing errors.- Users can run their scripts with this environment variable for clearer error detection.
- Monitor GPU Memory Usage: Tools like
nvidia-smican help track GPU memory usage to avoid illegal accesses due to overstepping available memory limits.- Adjusting batch sizes and model sizes based on observed memory can prevent illegal memory access.
- Validate Memory Operations in CUDA: Ensure that all CUDA memory operations are valid and avoid uninitialized or freed memory to prevent errors.
- Adding error checking around CUDA API calls can help catch issues early in the code.
- Review Custom CUDA Kernels: Users should carefully check array indexing in custom CUDA kernels to prevent out-of-bounds memory accesses.
- Using Compute Sanitizer can help identify memory access issues more effectively during debugging.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Cohere ▷ #discussions (52 messages🔥):
Recursive Iterative ModelsMulti-step Tool ApplicationsRAG ModelsCohere Course on RAGUsing Cohere Models in Projects
- Testing Hypotheses on LLMs: A user questioned if testing a hypothesis across multiple large language models yielding similar results indicates that their Recursive Iterative model works.
- Suggestions were made to evaluate it further against benchmarks and evaluation harnesses to ensure accuracy.
- Exploring Multi-step Tools: A member expressed interest in others' favorite applications of multi-step tools, highlighting a previous winning application in the agent build day competition.
- Another member shared a GitHub link with multiple examples of multi-step use cases, prompting discussions on favorite applications.
- New Cohere RAG Course Launch: An announcement was made regarding a new course on RAG in production with Weights&Biases, covering various important aspects like evaluation and pipelines.
- The course is shorter than 2 hours and offers Cohere credits for participants, with a Cohere team member available for questions.
- Integrating Cohere Models: A user sought interest in adding or testing Cohere models on a GitHub project, leading to discussions on more mature frameworks and the benefits of adaptable proxies.
- Members debated the inherent goals of their projects and the flexibility required to integrate tools efficiently.
- Welcoming New Members to Cohere: New users expressed their eagerness to learn about AI and Cohere applications, receiving welcoming responses from the community.
- Members encouraged questions and reminded them of resources available within the Cohere Discord for assistance.
- GitHub - codelion/optillm: Optimizing inference proxy for LLMs: Optimizing inference proxy for LLMs. Contribute to codelion/optillm development by creating an account on GitHub.
- GitHub - MadcowD/ell: A language model programming library.: A language model programming library. Contribute to MadcowD/ell development by creating an account on GitHub.
- GitHub - cohere-ai/notebooks: Code examples and jupyter notebooks for the Cohere Platform: Code examples and jupyter notebooks for the Cohere Platform - cohere-ai/notebooks
- Advanced RAG course : Practical RAG techniques for engineers: learn production-ready solutions from industry experts to optimize performance, cut costs, and enhance the accuracy and relevance of your applications.
- GitHub - ack-sec/toyberry: Toy implementation of Strawberry: Toy implementation of Strawberry . Contribute to ack-sec/toyberry development by creating an account on GitHub.
Cohere ▷ #questions (6 messages):
Cohere API Key PricingCitations for Unstructured Text DataRerank Fine-tuning Expectations
- Cohere API Key Pricing Clarified: A member explained that one can use a rate-limited Trial-Key for free, but for commercial applications, switching to a Production-Key is required, which comes at a cost.
- This insight emphasizes the need to consider the intended usage of the API key when planning resources.
- Best Practices for Citations Shared: Another member directed to the LLM University RAG module for best practices on obtaining citations for unstructured text data, available at cohere.com.
- Additional documentation was also mentioned, highlighting their resources about utilizing citations effectively in models.
- Concerns About Rerank Fine-tuning Duration: One member expressed concern about their Rerank fine-tuning job running for over 2 hours on a dataset of only 1711 queries with minimal positives and negatives per query.
- They noted they did not supply a validation set, and were unsure if this length of time was typical for their setup.
- Getting Started with Retrieval-Augmented Generation: Part 1 of the LLM University module on Retrieval-Augmented Generation.
- Chat — Cohere: Generates a text response to a user message. To learn how to use the Chat API and RAG follow our Text Generation guides .
Cohere ▷ #api-discussions (15 messages🔥):
NotFoundError with multilingual Embed404 error on documentation linkSwitching to newer Embed modelResponse from Cohere Support
- Encountering NotFoundError with multilingual Embed: A team reported a
cohere.errors.not_found_error.NotFoundErrorfor the model 'packed-embed-multilingual-v2.0', suggesting it might not be accessible with the current API keys.- Another member mentioned they switched to embed-multilingual-v3.0, which resolved their issue, prompting others to consider the same solution.
- 404 error on documentation link: A user raised concern over a previously working link to the Cohere documentation (https://docs.cohere.com/docs/structure-of-the-course) now returning a 404 error.
- Cohere support acknowledged the issue and promised to investigate further.
- Potential changes in Embed model hosting: Members discussed if there were any changes in the hosting of the multilingual Embed models that could be causing these errors.
- They shared experiences with using Chat successfully while facing issues with the Embed model under the same API key.
Cohere ▷ #projects (11 messages🔥):
Cohere in Embedded SystemsSmart Telescope Mount/TrackerCohere CookbookEmbedding Use CasesGitHub Notebooks
- Exploring Cohere applications in Embedded Systems: A user inquired about examples of Cohere being used in embedded systems, expressing interest in integrating it into a smart telescope mount for their capstone project.
- Discussion ensued about the potential of finding celestial objects using embeddings from the Messier catalog.
- Smart Telescope Project Excites Community: The user shared excitement about their project aimed at automatically locating 110 objects from the Messier catalog, with plans for further expansion beyond that.
- Community members enthusiastically supported the idea, encouraging collaboration and offering resources.
- Cohere Cookbook as a Resource: Members highlighted the availability of the Cohere Cookbook on their website, providing ready-made guides for using Cohere’s generative AI platform.
- These guides cover a range of use cases, such as building powerful agents and integrating with open source software.
- Use Cases for Cohere: The discussion mentioned multiple categories in the Cohere Cookbook, including embedding and semantic search, vital for AI projects.
- Members were encouraged to explore specific sections relevant to their project needs.
- Code Examples on GitHub: A user shared a link to GitHub notebooks containing code examples and Jupyter notebooks for exploring Cohere’s platform.
- This resource aims to assist users in practical implementations and experimentation with Cohere’s capabilities.
- Cookbooks — Cohere: Explore a range of AI guides and get started with Cohere's generative platform, ready-made and best-practice optimized.
- GitHub - cohere-ai/notebooks: Code examples and jupyter notebooks for the Cohere Platform: Code examples and jupyter notebooks for the Cohere Platform - cohere-ai/notebooks
LlamaIndex ▷ #announcements (1 messages):
LlamaParse Fraud AlertLlamaIndex Product Clarification
- Beware of fraudulent LlamaParse site: A warning was issued about a site masquerading as a LlamaIndex product: llamaparse dot cloud (we're not linking to it!).
- Users are advised to ignore it as the real LlamaParse can be found at cloud.llamaindex.ai.
- Clarification on LlamaParse legitimacy: The community was informed that the legitimate LlamaParse service is hosted at cloud.llamaindex.ai, ensuring users access the correct product.
- This clarification is crucial to prevent confusion and potential misuse of the fraudulent site.
LlamaIndex ▷ #blog (5 messages):
LlamaParse Scam WarningAWS Gen AI Loft EventAdvanced RAG over ExcelPixtral 12B Model LaunchLlamaIndex Hiring Announcement
- Beware of LlamaParse Imposter!: A warning was issued about llamaparse dot cloud, a fraudulent site impersonating LlamaIndex products; the authentic LlamaParse is located at this link.
- Stay vigilant against scams masquerading as reputable services.
- Exciting Talks at AWS Gen AI Loft: Our own @seldo will present on RAG and Agents at the AWS Gen AI Loft, leading up to the ElasticON conference with @elastic on March 21, 2024 (source).
- Attendees will learn how Fiber AI harnesses Elasticsearch for high-performance B2B prospecting.
- Releasing Guide for RAG on Multi-Sheet Excel: A new guide is coming out detailing how to perform advanced RAG analysis using the OpenAI o1 model over Excel files with multiple sheets (link).
- The guide addresses complexities associated with multi-sheet Excel files for a better analytical approach.
- Introducing Pixtral 12B: The Multi-Modal Marvel: The Pixtral 12B model from @MistralAI is now compatible with LlamaIndex, boasting impressive capabilities in chart and image understanding (source).
- Pixtral's performance shines when compared to similarly sized models in multi-modal tasks.
- Join Our Growing Team at LlamaIndex!: LlamaIndex is on the lookout for passionate engineers in San Francisco to expand our dynamic team (link).
- Roles vary from full-stack to specialized positions, targeting enthusiastic individuals eager to dive into ML/AI technologies.
Link mentioned: LlamaCloud: no description found
LlamaIndex ▷ #general (74 messages🔥🔥):
Using LlamaIndex with OllamaAccessing VectorStoreIndexHandling LlamaTrace Project ErrorsError Resolution in NotebooksPassing Messages to ReAct Agent
- Issues with Llama Index Notebooks: Users reported encountering errors in the LlamaIndex Notebook (link). Confirmation of similar issues led to ongoing troubleshooting discussions within the channel.
- Understanding VectorStoreIndex: Clarifications emerged regarding the
VectorStoreIndex, specifically how to access the underlying vector store throughindex.vector_store. Users discussed the storage limitations ofSimpleVectorStore, prompting considerations for alternative vector stores. - Resolving LlamaTrace Project Error: A user expressed frustration over encountering an error after logging into their LlamaTrace project. Eventually, they noted that clearing cookies could resolve the issue, and considered setting up a personal instance to avoid future complications.
- Accessing ReAct Agent Features: Participants explored how to effectively pass multiple examples as input to the
ReActAgentand retrieve structured output usingPydanticOutputParser. They discussed the need for proper formatting and handling of user and system messages. - Technical Confusions Around Functions: During discussions, participants highlighted confusions regarding callable methods and properties in
VectorStoreIndex, exemplifying Python's use of decorators. Misunderstandings were clarified, leading to a better understanding of class properties and their functions.
- Introduction to PandasAI - PandasAI: no description found
- Groq - LlamaIndex: no description found
- Ollama - Llama 3.1 - LlamaIndex: no description found
- ReAct Agent - A Simple Intro with Calculator Tools - LlamaIndex: no description found
- Hugging Face LLMs - LlamaIndex: no description found
- Email Data Extraction - LlamaIndex: no description found
- Function Calling NVIDIA Agent - LlamaIndex: no description found
- React - LlamaIndex: no description found
- React - LlamaIndex: no description found
- Function Calling NVIDIA Agent - LlamaIndex: no description found
- Pydantic - LlamaIndex: no description found
- LLM Pydantic Program - LlamaIndex: no description found
Latent Space ▷ #ai-general-chat (76 messages🔥🔥):
Gemini Pricing StrategiesAnthropic Revenue BreakdownLlama 3.2 LaunchMira Murati DepartureMeta's Orion Glasses
- Gemini Pricing Lines Up with Predictions: Today's cut in Gemini Pro pricing aligns perfectly with the loglinear pricing curve based on its Elo score, suggesting an effective strategy in the competitive landscape.
- OpenAI models dominate the higher pricing tier, while Gemini Pro and Flash capture the lower end, resembling a tech rivalry akin to 'iPhone vs Android'.
- Anthropic's Revenue Projection Surges: Per CNBC, Anthropic expects to reach $1B in revenue this year, reflecting a significant 1000% increase year-over-year.
- The revenue breakdown shows heavy reliance on Third Party API at 60-75%, with direct API sales and chatbot subscriptions contributing notably.
- Llama 3.2 Models Introduced: Llama 3.2 has launched with lightweight models for edge devices, offering 1B, 3B, 11B, and 90B vision models, promising competitive performance.
- Notably, the new models support multimodal use cases, and developers have free access to test the latest capabilities, facilitating open-source AI developments.
- Mira Murati Exits OpenAI: Mira Murati shared a heartfelt farewell note as she departs OpenAI, which has sparked significant discussion within the community.
- Sam Altman expressed gratitude for her contributions, recognizing the scrutiny she faced during her tenure and reflecting on the emotional support she provided during challenging times.
- Meta's Orion Glasses Prototype Unveiled: Meta revealed their Orion AR glasses prototype, marking a significant milestone after nearly a decade in development with initially low expectations of success.
- These glasses aim for a wide field of view and lightweight design, and will be used internally to develop user experiences for their future consumer launch.
- Tweet from Yuchen Jin (@Yuchenj_UW): How it started vs how it’s goin. Quoting Sam Altman (@sama) I replied with this. Mira, thank you for everything. It’s hard to overstate how much Mira has meant to OpenAI, our mission, and to us al...
- Tweet from Mira Murati (@miramurati): I shared the following note with the OpenAI team today.
- Tweet from Tanay Jaipuria (@tanayj): Per CNBC, Anthropic is expected to hit $1B in revenue this year, roughly a ~1000% increase y/y. Breakdown of revenue is: • Third Party API (via Amazon, etc): 60-75% • Direct API: 10-25% • Claude chat...
- Tweet from Boz (@boztank): We just unveiled Orion, our full AR glasses prototype that we’ve been working on for nearly a decade. When we started on this journey, our teams predicted that we had a 10% chance (at best) of success...
- Tweet from AI at Meta (@AIatMeta): 📣 Introducing Llama 3.2: Lightweight models for edge devices, vision models and more! What’s new? • Llama 3.2 1B & 3B models deliver state-of-the-art capabilities for their class for several on-devi...
- Tweet from Ai2 (@allen_ai): Meet Molmo: a family of open, state-of-the-art multimodal AI models. Our best model outperforms proprietary systems, using 1000x less data. Molmo doesn't just understand multimodal data—it acts ...
- Tweet from AI News by Smol AI (@Smol_AI): it's notable how predictive the Lmsys Elo vs $ pricing curve is, and how the strategy is panning out. Today's Gemini Pro price cut brings it exactly in line with where a loglinear pricing curv...
- Tweet from Luca Soldaini 🎀 (@soldni): Green is my favorite color
- Llama 3.2 Vision and Molmo: Foundations for the multimodal open-source ecosystem : Open models, tools, examples, limits, and the state of training multimodal models.
- Tweet from Hassan (@nutlope): Announcing http://napkins.dev! An open source wireframe to app tool powered by Llama 3.2 vision. Upload a screenshot of a simple site/design & get code. 100% free and open source.
- Tweet from Georgi Gerganov (@ggerganov): Try the 4-bit model easily on your Mac (even in EU): Quoting Georgi Gerganov (@ggerganov) Llama 3.2 3B & 1B GGUF https://huggingface.co/collections/hugging-quants/llama-32-3b-and-1b-gguf-quants-66...
- Tweet from Daniel Han (@danielhanchen): My analysis of Llama 3.2: 1. New 1B and 3B text only LLMs 9 trillion tokens 2. New 11B and 90B vision multimodal models 3. 128K context length 4. 1B and 3B used some distillation from 8B and 70B 5. VL...
- Tweet from Shishir Patil (@shishirpatil_): 💥 LLAMA Models: 1B IS THE NEW 8B 💥 📢 Thrilled to open-source LLAMA-1B and LLAMA-3B models today. Trained on up to 9T tokens, we break many new benchmarks with the new-family of LLAMA models. Jumpi...
- James Cameron, Academy Award-Winning Filmmaker, Joins Stability AI Board of Directors — Stability AI: Today we announced that legendary filmmaker, technology innovator, and visual effects pioneer James Cameron has joined our Board of Directors.
- Tweet from Andrew Curran (@AndrewCurran_): Wow.
- Tweet from Together AI (@togethercompute): 🚀 Big news! We’re thrilled to announce the launch of Llama 3.2 Vision Models & Llama Stack on Together AI. 🎉 Free access to Llama 3.2 Vision Model for developers to build and innovate with open sou...
- Tweet from Nathan Lambert (@natolambert): Comparing the biggest Molmo model (72B) to Llama 3.2 V 90B MMMU, Llama is higher by 6 pTS MathVista, Molmo up 1 pt ChatQA Molmo up 2 AI2D Molmo up 4 DocVQA up 3 VQAv2 about the same or molmo better ...
- Tweet from vik (@vikhyatk): molmo > gemini 1.5 flash (at counting)
- Tweet from Rihard Jarc (@RihardJarc): $META's iPhone moment
- Reddit - Dive into anything: no description found
- napkins/app/api at f6c89c76b07b234c7ec690195df278db355f18fc · Nutlope/napkins: napkins.dev – from screenshot to app. Contribute to Nutlope/napkins development by creating an account on GitHub.
- Director James Cameron explains why he is joining Stability AI's board of directors: James Cameron, Oscar Winning Filmmaker and Prem Akkaraju, Stability AI CEO, join 'Closing Bell Overtime' and CNBC's Julia Boorstin to talk the impact of AI o...
- [Paper Club] 🍓 On Reasoning: Q-STaR and Friends!: Following the Strawberry launch, we'll survey a few related papers rumored to be relevant:STaR: Boostrapping Reasoning with Reasoning (https://arxiv.org/abs...
- llama 3.2 vs 3.1 - Diffchecker: llama 3.2 vs 3.1 - LLAMA 3.1 COMMUNITY LICENSE AGREEMENT Llama 3.1 Version Release Date: July 23, 2024 “Agreement” mea
- Llama 3.2: The open source AI model you can fine-tune, distill and deploy anywhere. Our latest models are available in 8B, 70B, and 405B variants.
- napkins/app/api/generateCode/route.ts at f6c89c76b07b234c7ec690195df278db355f18fc · Nutlope/napkins: napkins.dev – from screenshot to app. Contribute to Nutlope/napkins development by creating an account on GitHub.
Latent Space ▷ #ai-announcements (1 messages):
swyxio: new meetup in <@&1284244976024424630> led by <@656968717883670570> ! https://lu.ma/i8ulstlw
Stability.ai (Stable Diffusion) ▷ #general-chat (66 messages🔥🔥):
Installing BasicsrComfyUI vs Forge3D Model GeneratorsStable Diffusion UsageControlNet OpenPose
- Troubleshooting Basicsr Installation: To fix issues with ComfyUI in Forge, @cs1o suggests navigating to the Forge folder and running
pip install basicsrin the command prompt after activating the virtual environment.- Users expressed confusion and plan to try again, hoping the extension will show up as a tab after installation.
- ComfyUI versus Forge Preferences: Members discussed their preferences between ComfyUI and Forge, with @emperatorzacksweden mentioning they find Invoke much easier to use.
- Some users advocate for sticking to ComfyUI rather than using the extension in Forge due to its old version and compatibility issues.
- Interest in 3D Model Generators: @placebo_yue inquired about 3D generators running locally, mentioning issues with TripoSR and that open-source options seem broken.
- There was an interest in tools like Luma Genie and Hyperhuman, but skepticism regarding their functionality was expressed.
- Learning Stable Diffusion Without a GPU: A user seeking advice on using Stable Diffusion without a GPU was directed to use Google Colab or Kaggle for free access to GPU resources.
- There was a consensus that using these platforms for running scripts is acceptable for beginners learning Stable Diffusion.
- Using ControlNet OpenPose Editor: @cs1o explained how to utilize the ControlNet OpenPose preprocessor to generate and edit preview images within the platform.
- Users were interested in exploring this feature, with indications it allows for more detailed adjustments in their generated outputs.
Torchtune ▷ #announcements (1 messages):
Llama 3.2 ReleaseMultimodal SupportLong-context ModelsFinetuning Options
- Llama 3.2 Launches with Multimodal Features: The release of Llama 3.2 introduces 1B and 3B text models with long-context support, allowing users to try with
enable_activation_offloading=Trueon long-context datasets.- Additionally, the 11B multimodal model supports The Cauldron datasets and custom multimodal datasets for enhanced generation.
- Flexible Finetuning Options Available: Llama 3.2 offers multiple finetuning methods including full finetuning, LoRA, and QLoRA, with DoRA finetuning support coming soon.
- Stay tuned for more updates in the next few days regarding configuration details.
Torchtune ▷ #general (29 messages🔥):
Green Card ConcernsPen and Paper ReturnLlama 3.2 AccessMetaAI RestrictionsLegal Department Reactions
- Desire for Green Card: A member humorously expressed desperation for a green card, suggesting they might make life harder for Europe due to their situation.
- 'I won't tell anyone in exchange for a green card' highlights their frustration and willingness to negotiate.
- Throwback to Pen and Paper: In a humorous tone, a member indicated a return to drawing surgical reports on paper like in the 80s, sharing nostalgia for traditional methods.
- This reflects a dissatisfaction with modern processes amid current frustrations.
- Confusion Over Llama 3.2 Access: There was confusion regarding the inability to download Llama 3.2 directly, with speculation that services using it may still be accessible.
- One member noted, 'Maybe it's like if a US company builds a service with llama 3.2 I can still use the service.'
- Restrictions on MetaAI: Discussion arose around MetaAI, with some members confirming they are unable to access the platform due to geo-restrictions that prevent EU users from logging in.
- One remarked, 'I don't think we get access to MetaAI over here,' illustrating how access barriers affect users.
- Uncertainty About Llama 3.2 Release: Members questioned the release status of Llama 3.2 405B, expressing confusion over whether it is open-sourced or not.
- One member admitted, 'Yeah I can't find it on hugging face lol,' showcasing frustration in trying to locate the model.
Torchtune ▷ #dev (9 messages🔥):
TF32 usage in PyTorchKV-cache toggling RFCHandling Tensor sizing
- Consider TF32 for FP32 users: Discussion arose around enabling TF32 as an option for users still utilizing FP32, as it accelerates matrix multiplication (matmul). The sentiment echoed that if one is already using FP16/BF16, TF32 may not offer added benefits.
- ‘I wonder who would prefer it over FP16/BF16 directly’ was humorously noted.
- RFC Proposal on KV-cache toggling: An RFC on KV-cache toggling has been proposed, aiming to improve how caches are handled during model forward passes. The proposal addresses the current limitation where caches are always updated unnecessarily.
- Concerns were raised about the necessity and usability of this caching mechanism within specific model setups, prompting further discussion.
- Merging compile support in a PR: A member asked if they should merge a related pull request that fixes recompiles in KV-cache and adds compile support. This led to a suggestion to incorporate compile support into the PR for better integration.
- The dialogue indicates a collaborative effort to refine the code and improve performance across the project.
- Advice on handling Tensor sizing: A query was made regarding improving the handling of sizing for Tensors beyond using the Tensor item() method. There was a request for insights or alternatives from other members.
- One member acknowledged the need for better solutions and promised to think about it further.
- [RFC] Supporting KV-cache toggling · Issue #1675 · pytorch/torchtune: Problem Currently, when we use model.setup_caches(), KV-caches are always updated for every subsequent forward pass on the model. We have valid use cases for using model.setup_caches(), but then no...
- CUDA semantics — PyTorch 2.4 documentation: no description found
- torch.compile, the missing manual: torch.compile, the missing manual You are here because you want to use torch.compile to make your PyTorch model run faster. torch.compile is a complex and relatively new piece of software, and so you ...
- Fixing recompiles in KV-cache + compile by SalmanMohammadi · Pull Request #1663 · pytorch/torchtune: Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) Unbeknownst to me, when #1449 landed it broke compatibil...
Modular (Mojo 🔥) ▷ #general (4 messages):
MOToMGP errorLinux box sizing for MAXMojo birthday celebrations
- MOToMGP Error Investigation: A user inquired about the error 'failed to run the MOToMGP pass manager' and sought any reproduction cases to prevent or better message it.
- Community members were encouraged to share experiences or insights regarding this specific issue.
- Sizing Linux Box for MAX and Ollama 3.1: A member asked for advice on how to size a Linux box when running MAX with ollama3.1.
- This question opens up discussion on optimal configurations for resource allocation to ensure performance.
- Happy Birthday to Mojo!: A celebration message was shared in honor of Mojo's birthday, humorously noting that the AI almost counted the right number of candles.
- The cheerful announcement brought a festive spirit to the chat, highlighting community camaraderie.
Modular (Mojo 🔥) ▷ #announcements (1 messages):
Mojo GitHub DiscussionsCommunity Q&A on Magic
- Mojo GitHub Discussions changes announced: Starting September 26th, the Mojo GitHub Discussions tab will remain accessible but new Discussions and comments will be disabled to focus the community's conversations in Discord.
- This decision follows the realization that there's little value in converting historically important Discussions into Issues, leading to a shutdown of GitHub Discussions on the MAX repo due to low volume.
- Community meeting planned for Magic Q&A: A community meeting will be held on September 30th, where questions about Magic 🪄 will be addressed by Zac, and participants are encouraged to submit their questions via the linked Google form.
- The recording of this session will be uploaded to YouTube for those unable to attend live.
Link mentioned: Community Magic Questions: Please share your questions related to Magic! Zac will answer them during the Magic Q&A in our community meeting on September 30th. As always, the recording will be posted to YouTube.
Modular (Mojo 🔥) ▷ #mojo (21 messages🔥):
Mojo and C communication speedImplementation of associated aliasesPotential for chainable iterables in MojoOwnership mechanisms in MojoUnsafeMaybeUninitialized wrapper
- Mojo's communication with C vs Python: A participant questioned if the communication between Mojo and C (via DLHandle) is faster than with Python, suggesting it may depend on whether Python calls into C.
- Another member chimed in, agreeing that the answer could vary based on the specific implementation.
- Associated aliases implementation by Evan: Evan is implementing associated aliases in Mojo, which can be defined similarly to the given code snippet with traits and type aliases.
- Members expressed excitement over this development and its potential impact on code organization and clarity.
- Interest in Mojo for chainable iterables: A member expressed interest in creating chainable iterables in Mojo, referencing a transformation pipeline similar to torchdata.
- They speculated that associated aliases might enable a proper iterable trait for lists, sets, and dictionaries.
- Mojo's ownership initialization mechanisms: Discussion arose around whether Mojo has a way to indicate a variable is initialized or uninitialized, referencing
lit.ownership.mark_destroyedandlit.ownership.mark_initialized.- While this was confirmed, it was noted that documentation is lacking, and users should review the standard library for examples.
- Wraps ownership ops in Mojo: The term UnsafeMaybeUninitialized was discussed, with a member describing it as a wrapper around the ownership operations in Mojo.
- There was a call for more features like associated aliases as Mojo stabilizes, to ease coding and debugging efforts.
Link mentioned: [stdlib] Use ownership ops in Uninit to remove pointer indirection. by helehex · Pull Request #3453 · modularml/mojo: The ownership ops provide a more clear implementation than pop.array, and allows the pointer indirection to be removed. This makes the inner field of UnsafeMaybeUninitialized just a ElementType ins...
OpenInterpreter ▷ #general (12 messages🔥):
o1 Preview and Mini API accessLlama 3.2 experiment resultsDesign choices for logosBroken Open Interpreter
- Excitement around o1 Preview and Mini API: Members are discussing accessing the o1 Preview and Mini API, with one expressing curiosity about its support in Lite LLM as they get responses from Open Interpreter.
- Another member humorously mentioned preparing to test it but has no access to tier 5.
- Experiments with Llama 3.2: Discussions arose about the upcoming experiments with Llama 3.2, prompting questions about what tests people plan to conduct.
- One member shared they attempted to ask Llama 3.2 to count files on their desktop, resulting in a failure.
- Logo Design Choices: One member shared their progress with design by stating they initially tried the GitHub logo but found their current choice to be better.
- Another chimed in, playfully questioning the power of their design decision, adding a light-hearted tone to the discussion.
- Broken Open Interpreter Issues: A member shared a lighthearted personal issue with Open Interpreter, stating they broke their setup but are getting back on track.
- The conversation included offers to share access for troubleshooting as the community rallied to support.
OpenInterpreter ▷ #ai-content (5 messages):
Llama 3.2 ReleaseTool Use YouTube EpisodeGroqCloud Availability
- Llama 3.2 Launches with Lightweight Edge Models: Meta introduced Llama 3.2, featuring 1B & 3B models for on-device use cases with support for Arm, MediaTek, and Qualcomm on day one. The announcement highlights competitive performance of new 11B & 90B vision models against leading closed models.
- Developers can access the models directly from Meta and Hugging Face as they roll out across 25+ partners including AWS, Google Cloud, and NVIDIA.
- Tool Use Episode Covers Open Source AI: Watch the latest Tool Use episode featuring AJ (@techfren) discussing open source coding tools and infrastructure projects. The episode emphasizes the importance of community-driven open source innovations in AI.
- The discussion underlines a growing trend in leveraging open source tools, aligning with sentiments shared in the channel.
- Llama 3.2 Now Available on GroqCloud: Groq announced a preview of Llama 3.2 available in GroqCloud, showcasing its integration into their infrastructure. This launch aligns with efforts to enhance the accessibility of Llama models for developers and enterprises.
- Mikebirdtech noted an enthusiastic response, remarking that everything associated with Groq is fast, reinforcing the speed of deployment.
- Tweet from Groq Inc (@GroqInc): 💥 Llama 3.2 preview available in GroqCloud.
- Tweet from AI at Meta (@AIatMeta): 📣 Introducing Llama 3.2: Lightweight models for edge devices, vision models and more! What’s new? • Llama 3.2 1B & 3B models deliver state-of-the-art capabilities for their class for several on-devi...
- What Are Techfren's Favourite AI Tools? - Ep 6 - Tool Use: We're joined by AJ, also known as @techfren in the tech world. We discuss open source coding tools and demo some open source infrastructure projects with th...
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
Quiz 3 Information
- Quiz 3 waiting inquiry: A member asked about the status of Quiz 3, indicating they were waiting for information.
- Another member promptly responded that it's available on the course website under the syllabus section.
- Course website resources: A member directed the original inquirer to check the course website for details on scheduled assessments.
- This highlights the importance of frequently checking syllabus updates for timely exam information.
LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (13 messages🔥):
Gemini 1.5 Flash performanceNew MMLU-Pro datasetChain of Thought effectivenessAutoGen usage in research
- Gemini 1.5 Flash shows impressive benchmarks: The Gemini 1.5 Flash model is reported to achieve a score of 67.3% as of September 2024 and offers improvements across various datasets.
- It was noted that Gemini 1.5 Pro achieves even better scores, reaching 85.4%, showcasing notable advancements in model performance.
- Introduction of MMLU-Pro dataset: A new Enhanced version of the MMLU dataset, known as MMLU-Pro, includes questions across 57 subjects with a higher difficulty level.
- This dataset aims to provide a better challenge for evaluating model capabilities, particularly in areas like STEM and humanities.
- Chain of Thought's effectiveness questioned: A new study discusses when Chain of Thought (CoT) is beneficial, indicating that direct answering performs similarly except for math and symbolic reasoning tasks.
- The analysis involved 300+ experiments and suggests that CoT is unnecessary for 95% of MMLU tasks; its main utility lies in symbolic computation.
- Research highlights AutoGen usage: Another research project has notably utilized AutoGen, showing its relevance in current AI developments.
- This points to ongoing trends in leveraging automated model generation techniques for enhancing performance and research outputs.
- Discussion on Flash Model: Members engaged in discussions surrounding the Flash model, which was recently updated and shows performance parity with previous pro-level models.
- It was highlighted that its pricing justifies its designation as a leader in the affordable category for model performance.
- Tweet from Zayne Sprague (@ZayneSprague): To CoT or not to CoT?🤔 300+ experiments with 14 LLMs & systematic meta-analysis of 100+ recent papers 🤯Direct answering is as good as CoT except for math and symbolic reasoning 🤯You don’t need Co...
- Thread by @ZayneSprague on Thread Reader App: @ZayneSprague: To CoT or not to CoT?🤔 300+ experiments with 14 LLMs & systematic meta-analysis of 100+ recent papers 🤯Direct answering is as good as CoT except for math and symbolic reasoning 🤯...
- To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning: Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra ``thinking'' reall...
- Gemini Flash: Our lightweight model, optimized for when speed and efficiency matter most, with a context window of up to one million tokens.
DSPy ▷ #show-and-tell (2 messages):
Langtrace UpdatesDSPy FeaturesAutomatic Experiment TrackingCheckpoint State Tracking
- Exciting DSPy Features Launching!: New features specific to DSPy on Langtrace are launching this week, including a new project type and automatic experiment tracking inspired by MLFlow.
- Automatic checkpoint state tracking, eval score trendlines, and span graphs will also be included, alongside support for litellm.
- Typescript Version Ax to Support New Features: These new DSPy features will soon be available for the Typescript version Ax of Langtrace.
- This is expected to enhance the usability and functionality for users leveraging DSPy.
Link mentioned: Tweet from Karthik Kalyanaraman (@karthikkalyan90): Some DSPy specific native features on @langtrace_ai launching this week. - New project type - DSPy - Automatic experiment tracking (inspired from MLFlow) - Automatic checkpoint state tracking - Eval ...
DSPy ▷ #general (5 messages):
DSPy text classificationClaude modelsDSPy for conversational agentsOrchestrating user queriesDSPy memory and conversation history
- DSPy excels in text classification for fraud detection: A user is employing DSPy for classifying text into three types of fraud based on semantics and context and is seeking advice on the best Claude model for this task.
- Another member noted that Sonnet 3.5 is currently the top anthropic model, with Haiku being the more cost-effective choice.
- DSPy as a conversational agent orchestration tool: A member is exploring DSPy as an orchestrator for routing user queries to sub-agents and is inquiring about its capabilities for handling direct conversations with users.
- They discussed the potential of providing tools for it to call and mentioned the concept of memory, questioning its effectiveness compared to using a standalone conversation history with summarization.
DSPy ▷ #examples (3 messages):
Text ClassificationComplex Classes in ClassificationTutorial on Classification Tasks
- Exploring Complex Classes in Text Classification: Members discussed the concept of 'text classification into complex classes', emphasizing the need for precise definitions.
- One member noted the differentiation between US politics, International Politics, vague queries, and out of scope queries, highlighting how their definitions depend on the business context.
- Timing for a Classification Tutorial: A member pointed out that the ongoing discussion is timely as they are currently writing a tutorial on classification tasks.
- This indicates a collaborative effort to enhance understanding and clarity in the classification domain.
tinygrad (George Hotz) ▷ #general (9 messages🔥):
tinygrad resourcesdebugging tinygradcontributing to tinygrad
- Essential Resources for Tinygrad Contributions: A member shared a series of tutorials on tinygrad that cover the internals and will help new contributors understand the framework.
- They highlighted the quickstart guide and abstraction guide as great resources.
- Efficient Learning Through Code: To grasp the various concepts of tinygrad, a member advised reading code and letting questions that arise guide further learning.
- Using search engines or tools like ChatGPT can help answer queries and enhance understanding, creating a productive feedback loop.
- Tracking Discussions for Insight: Following pull requests and discussions in the Discord channel is suggested as a way to keep up with what contributors are working on in tinygrad.
- This provides contextual knowledge and insight into ongoing projects within the community.
- Using DEBUG to Understand Tinygrad's Flow: Another member mentioned that using
DEBUG=4on simple operations reveals the generated code, aiding in understanding the flow from front end to back end.- This approach serves as a practical method to dissect and comprehend how tinygrad operates internally.
- Need for Persistence in Learning: A light-hearted comment highlighted that getting comfortable with tinygrad might feel like slamming your head against a wall due to its complexity.
- It reflects the challenging nature of diving into intricate systems but encourages perseverance.
Link mentioned: Tutorials on Tinygrad: Tutorials on tinygrad
tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
Training speed issuesSampling code bugModel output quality
- Training loop too slow in tinygrad: A user expressed frustration with the slow training in tinygrad (version 0.9.2) when training a character model, referring to the process as slow as balls.
- They mentioned they rented a 4090 GPU to improve performance but did not see significant gains.
- Bug in sampling code affects output quality: After initially suspected slow training, the user identified a bug in their sampling code that was causing poor output quality during inference.
- They clarified that the issue was not with the training code but specifically with the sampling implementation.
LangChain AI ▷ #general (8 messages🔥):
Open Source Chat UI for Programming TasksThumbs Up/Down Review Options for ChatbotsAzure Chat OpenAI Integration
- Seeking Open Source Chat UI for Coding: A member inquired about any available open source UI specifically designed for chat interfaces aimed at programming tasks.
- They expressed that the question is quite general and welcomed input from anyone with experience in this area.
- Looking for Chatbot Feedback Features: Another member asked if anyone had implemented a thumbs up/thumbs down review option for their chatbot.
- They shared that they have created a custom front end and ruled out using Streamlit as an option.
- Discussion Threads on Chatbot Enhancements: A discussion thread emerged focused on the thumbs up/thumbs down review option, prompting further engagement.
- This indicates a community interest in enhancing user feedback mechanisms in chatbot designs.
- Integration with Azure Chat OpenAI: A member revealed they are utilizing Azure Chat OpenAI for their chatbot development efforts.
- This mention highlights the choice of platform that others might consider for similar use cases.
- Need for Ideas on Chatbot Implementation: The developer using Azure Chat OpenAI solicited ideas and suggestions from the community regarding their project.
- This underscores a collaborative effort among members to support each other's development challenges.
LangChain AI ▷ #share-your-work (1 messages):
Agentic RAG applicationLangGraphLightning StudiosStreamlitResearch Assistant
- Building an Agentic RAG Application: A user shared their experience building an agentic RAG application using LangGraph, Ollama, and Streamlit to act as a researcher retrieving valuable information from papers and web searches.
- They successfully deployed the app via Lightning Studios and documented their journey in a LinkedIn post.
- Utilizing Lightning Studios for Experiments: The user utilized Lightning Studios to run experiments and deploy the Streamlit app for their research application.
- Through this platform, they optimized their application setup, combining different technologies for enhanced functionality.
Link mentioned: LangGraph-AgenticRAG with Streamlit - a Lightning Studio by maxidiazbattan: This studio provides a guide on integrating and utilizing an Agentic-RAG, with Langgraph, Ollama and Streamlit.
LAION ▷ #general (1 messages):
GANsCNNsViTsImage tasksAlgorithm comparison
- GANs, CNNs, and ViTs as top image algorithms: A member expressed that GANs, CNNs, and ViTs frequently trade off as the top algorithm for image tasks.
- They sought confirmation and ideally a visual timeline showcasing this evolution.
- Request for timeline visual: A member requested a visual timeline to illustrate the changing dominance of GANs, CNNs, and ViTs.
- This request highlights interest in understanding the historical context of these algorithms in image processing.
LAION ▷ #research (7 messages):
MaskBit image generationMonoFormer multimodal transformerSliding window attentionVQGAN modernizationEmbedding-free generation
- MaskBit revolutionizes image generation: The paper on MaskBit presents an embedding-free image generation model that operates on bit tokens, achieving a state-of-the-art FID of 1.52 on the ImageNet 256 × 256 benchmark.
- It also provides an insightful examination of VQGANs, resulting in a high-performing model that enhances accessibility while revealing previously unknown details.
- MonoFormer merges autoregression and diffusion: The MonoFormer paper proposes a unified transformer architecture for both autoregressive text generation and diffusion-based image generation, achieving comparable performance to state-of-the-art models.
- This is made possible by leveraging the similarities in training for both methods, differing only in the attention masks used during training.
- Sliding window attention still relies on positional encoding: A member noted that while sliding window attention (similar to Longformer) provides benefits, it still incorporates a positional encoding mechanism.
- This raises further discussion about the balance between efficiency and the need to maintain positional awareness in model architecture.