[AINews] Is this... OpenQ*?
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
MCTS is all you need.
AI News for 6/14/2024-6/17/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (414 channels, and 5506 messages) for you. Estimated reading time saved (at 200wpm): 669 minutes. You can now tag @smol_ai for AINews discussions!
A bunch of incremental releases over this weekend; DeepSeekCoder V2 promises GPT4T-beating performance (validated by aider) at $0.14/$0.28 per million tokens (vs GPT4T's $10/$30), Anthropic dropped some Reward Tampering research, and Runway finally dropped their Sora response.
However probably the longer lasting, meatier thing to dive into is the discussion around "test-time" search:
spawning a list of related papers:
- Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B: A Technical Report
- Improve Mathematical Reasoning in Language Models by Automated Process Supervision
- AlphaMath Almost Zero: Process Supervision Without Process
- ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
We'll be honest that we haven't read any of these papers yet, but we did cover OpenAI's thoughts on verifier-generator process supervision on the ICLR podcast, and have lined the remaining papers up for the Latent Space Discord Paper Club.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Stability.ai (Stable Diffusion) Discord
- Unsloth AI (Daniel Han) Discord
- CUDA MODE Discord
- LM Studio Discord
- HuggingFace Discord
- OpenAI Discord
- LAION Discord
- OpenAccess AI Collective (axolotl) Discord
- Perplexity AI Discord
- Nous Research AI Discord
- Modular (Mojo 🔥) Discord
- Eleuther Discord
- LLM Finetuning (Hamel + Dan) Discord
- Interconnects (Nathan Lambert) Discord
- LlamaIndex Discord
- tinygrad (George Hotz) Discord
- OpenRouter (Alex Atallah) Discord
- LangChain AI Discord
- Latent Space Discord
- Cohere Discord
- OpenInterpreter Discord
- Torchtune Discord
- DiscoResearch Discord
- Datasette - LLM (@SimonW) Discord
- AI Stack Devs (Yoko Li) Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- Stability.ai (Stable Diffusion) ▷ #general-chat (723 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (517 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #random (17 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (304 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (3 messages):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
- CUDA MODE ▷ #general (49 messages🔥):
- CUDA MODE ▷ #triton (2 messages):
- CUDA MODE ▷ #torch (10 messages🔥):
- CUDA MODE ▷ #algorithms (2 messages):
- CUDA MODE ▷ #beginner (5 messages):
- CUDA MODE ▷ #jax (1 messages):
- CUDA MODE ▷ #torchao (11 messages🔥):
- CUDA MODE ▷ #off-topic (10 messages🔥):
- CUDA MODE ▷ #irl-meetup (1 messages):
- CUDA MODE ▷ #llmdotc (473 messages🔥🔥🔥):
- CUDA MODE ▷ #oneapi (2 messages):
- CUDA MODE ▷ #bitnet (49 messages🔥):
- LM Studio ▷ #💬-general (204 messages🔥🔥):
- LM Studio ▷ #🤖-models-discussion-chat (137 messages🔥🔥):
- LM Studio ▷ #🧠-feedback (13 messages🔥):
- LM Studio ▷ #📝-prompts-discussion-chat (8 messages🔥):
- LM Studio ▷ #⚙-configs-discussion (3 messages):
- LM Studio ▷ #🎛-hardware-discussion (34 messages🔥):
- LM Studio ▷ #🧪-beta-releases-chat (22 messages🔥):
- LM Studio ▷ #autogen (1 messages):
- LM Studio ▷ #open-interpreter (13 messages🔥):
- LM Studio ▷ #model-announcements (1 messages):
- LM Studio ▷ #🛠-dev-chat (27 messages🔥):
- HuggingFace ▷ #general (372 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (5 messages):
- HuggingFace ▷ #cool-finds (10 messages🔥):
- HuggingFace ▷ #i-made-this (18 messages🔥):
- HuggingFace ▷ #reading-group (16 messages🔥):
- HuggingFace ▷ #computer-vision (4 messages):
- HuggingFace ▷ #NLP (5 messages):
- HuggingFace ▷ #diffusion-discussions (5 messages):
- OpenAI ▷ #ai-discussions (184 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (49 messages🔥):
- OpenAI ▷ #prompt-engineering (28 messages🔥):
- OpenAI ▷ #api-discussions (28 messages🔥):
- LAION ▷ #general (250 messages🔥🔥):
- LAION ▷ #research (34 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (161 messages🔥🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (4 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (9 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #datasets (4 messages):
- OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (11 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (11 messages🔥):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (187 messages🔥🔥):
- Perplexity AI ▷ #sharing (10 messages🔥):
- Perplexity AI ▷ #pplx-api (3 messages):
- Nous Research AI ▷ #off-topic (3 messages):
- Nous Research AI ▷ #interesting-links (5 messages):
- Nous Research AI ▷ #general (124 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (22 messages🔥):
- Nous Research AI ▷ #world-sim (29 messages🔥):
- Modular (Mojo 🔥) ▷ #general (40 messages🔥):
- Modular (Mojo 🔥) ▷ #💬︱twitter (2 messages):
- Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- Modular (Mojo 🔥) ▷ #ai (2 messages):
- Modular (Mojo 🔥) ▷ #🔥mojo (107 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #🏎engine (3 messages):
- Modular (Mojo 🔥) ▷ #nightly (9 messages🔥):
- Eleuther ▷ #announcements (1 messages):
- Eleuther ▷ #general (51 messages🔥):
- Eleuther ▷ #research (61 messages🔥🔥):
- Eleuther ▷ #scaling-laws (18 messages🔥):
- Eleuther ▷ #interpretability-general (11 messages🔥):
- Eleuther ▷ #lm-thunderdome (4 messages):
- Eleuther ▷ #multimodal-general (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #general (35 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (14 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #learning-resources (5 messages):
- LLM Finetuning (Hamel + Dan) ▷ #hugging-face (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #replicate (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #langsmith (5 messages):
- LLM Finetuning (Hamel + Dan) ▷ #berryman_prompt_workshop (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #workshop-3 (4 messages):
- LLM Finetuning (Hamel + Dan) ▷ #clavie_beyond_ragbasics (8 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #jason_improving_rag (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #jeremy_python_llms (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #saroufimxu_slaying_ooms (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #axolotl (27 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #charles-modal (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #simon_cli_llms (5 messages):
- LLM Finetuning (Hamel + Dan) ▷ #allaire_inspect_ai (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #credits-questions (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #fireworks (6 messages):
- LLM Finetuning (Hamel + Dan) ▷ #braintrust (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #west-coast-usa (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #east-coast-usa (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #predibase (7 messages):
- LLM Finetuning (Hamel + Dan) ▷ #openpipe (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #openai (1 messages):
- Interconnects (Nathan Lambert) ▷ #news (69 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (4 messages):
- Interconnects (Nathan Lambert) ▷ #random (63 messages🔥🔥):
- LlamaIndex ▷ #blog (9 messages🔥):
- LlamaIndex ▷ #general (95 messages🔥🔥):
- LlamaIndex ▷ #ai-discussion (6 messages):
- tinygrad (George Hotz) ▷ #general (39 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (69 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (68 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #일반 (1 messages):
- LangChain AI ▷ #general (48 messages🔥):
- LangChain AI ▷ #share-your-work (14 messages🔥):
- LangChain AI ▷ #tutorials (1 messages):
- Latent Space ▷ #ai-general-chat (21 messages🔥):
- Latent Space ▷ #ai-in-action-club (20 messages🔥):
- Cohere ▷ #general (20 messages🔥):
- Cohere ▷ #project-sharing (11 messages🔥):
- Cohere ▷ #announcements (1 messages):
- OpenInterpreter ▷ #general (14 messages🔥):
- OpenInterpreter ▷ #O1 (4 messages):
- OpenInterpreter ▷ #ai-content (6 messages):
- Torchtune ▷ #general (7 messages):
- DiscoResearch ▷ #discolm_german (5 messages):
- Datasette - LLM (@SimonW) ▷ #ai (3 messages):
- Datasette - LLM (@SimonW) ▷ #llm (1 messages):
- AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (1 messages):
- Mozilla AI ▷ #llamafile (1 messages):
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Apple's AI Developments and Partnerships
- Apple Intelligence announced: @adcock_brett noted Apple revealed Apple Intelligence at WWDC, their first AI system coming to iPhone, iPad, and Mac, with features like a smarter Siri and image/document understanding.
- OpenAI partnership: Apple and OpenAI announced a partnership to directly integrate ChatGPT into iOS 18, iPadOS 18, and macOS, as mentioned by @adcock_brett.
- On-device AI models: @ClementDelangue highlighted that Apple released 20 new CoreML models for on-device AI and 4 new datasets on Hugging Face.
- Optimized training: Apple offered a peek into its new models' performance and how they were trained and optimized, as reported by @DeepLearningAI.
- LoRA adapters for specialization: @svpino explained how Apple uses LoRA fine-tuning to generate specialized "adapters" for different tasks, swapping them on the fly.
Open Source LLMs Matching GPT-4 Performance
- Nemotron-4 340B from NVIDIA: NVIDIA released Nemotron-4 340B, an open model matching GPT-4 (0314) performance, according to @adcock_brett.
- DeepSeek-Coder-V2: @deepseek_ai introduced DeepSeek-Coder-V2, a 230B model excelling in coding and math, beating several other models. It supports 338 programming languages and 128K context length.
- Stable Diffusion 3 Medium: Stability AI released open model weights for its text-to-image model, Stable Diffusion 3 Medium, offering advanced capabilities, as noted by @adcock_brett.
New Video Generation Models
- Dream Machine from Luma Labs: Luma Labs launched Dream Machine, a new AI model generating 5-second video clips from text and image prompts, as reported by @adcock_brett.
- Gen-3 Alpha from Runway: @c_valenzuelab showcased Runway's new Gen-3 Alpha model, generating detailed videos with complex scenes and customization options.
- PROTEUS from Apparate Labs: Apparate Labs launched PROTEUS, a real-time AI video generation model creating realistic avatars and lip-syncs from a single reference image, as mentioned by @adcock_brett.
- Video-to-Audio from Google DeepMind: @GoogleDeepMind shared progress on their video-to-audio generative technology, adding sound to silent clips matching scene acoustics and on-screen action.
Robotics and Embodied AI Developments
- OpenVLA for robotics: OpenVLA, a new open-source 7B-param robotic foundation model outperforming a larger closed-source model, was reported by @adcock_brett.
- Virtual rodent from DeepMind and Harvard: DeepMind and Harvard created a 'virtual rodent' powered by an AI neural network, mimicking agile movements and neural activity of real-life rats, as noted by @adcock_brett.
- Manta Ray drone from Northrop Grumman: @adcock_brett mentioned Northrop Grumman released videos of the 'Manta Ray', their new uncrewed underwater vehicle drone prototype.
- Autonomous driving with humanoids: A new approach to autonomous driving leveraging humanoids to operate vehicle controls based on sensor feedback was reported by @adcock_brett.
Miscellaneous AI Research and Applications
- Anthropic's reward tampering research: @AnthropicAI published a new paper investigating reward tampering, showing AI models can learn to hack their own reward system.
- Meta's CRAG benchmark: Meta's article discussing the Corrective Retrieval-Augmented Generation (CRAG) benchmark was highlighted by @dair_ai.
- DenseAV for learning language from videos: An AI algorithm called 'DenseAV' that can learn language meaning and sound locations from unlabeled videos was mentioned by @adcock_brett.
- Goldfish loss for training LLMs: @tomgoldsteincs introduced the goldfish loss, a technique for training LLMs without memorizing training data.
- Creativity reduction in aligned LLMs: @hardmaru shared a paper exploring the unintended consequences of aligning LLMs with RLHF, which reduces their creativity and output diversity.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Models and Techniques
- Improved CLIP ViT-L/14 for Stable Diffusion: In /r/StableDiffusion, an improved CLIP ViT-L/14 model is available for download, along with a Long-CLIP version, which can be used with any Stable Diffusion model.
- Mixed Precision Training from Scratch: In /r/MachineLearning, a reimplementation of the original mixed precision training paper from Nvidia on a 2-layer MLP is presented, diving into CUDA land to showcase TensorCore activations.
- Understanding LoRA: Also in /r/MachineLearning, a visual guide to understanding Low-Rank Approximation (LoRA) for efficient fine-tuning of large language models is shared. LoRA reduces the number of parameters involved in fine-tuning by 10,000x while still converging to the performance of a fully fine-tuned model.
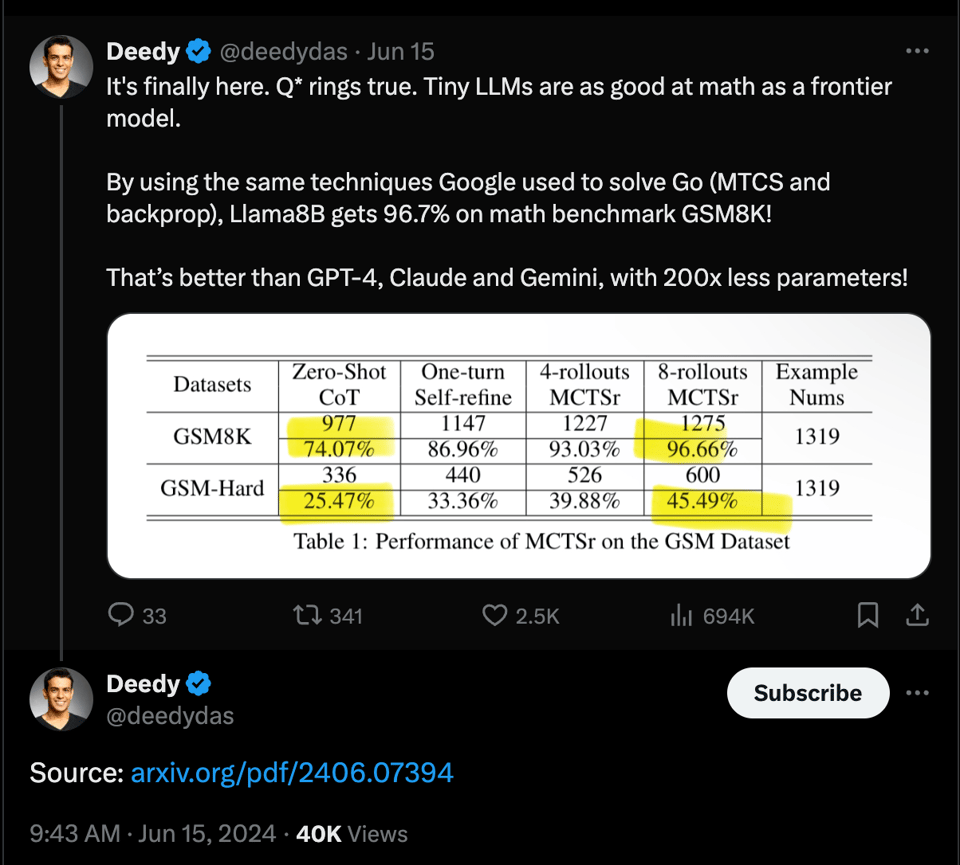
- GPT-4 level Math Solutions with LLaMa-3 8B: A research paper explores accessing GPT-4 level Mathematical Olympiad solutions using Monte Carlo Tree Self-refine with the LLaMa-3 8B model.
- Instruction Finetuning From Scratch: An implementation of instruction finetuning from scratch is provided.
- AlphaMath Almost Zero: Research on AlphaMath Almost Zero introduces process supervision without process.
Stable Diffusion Models and Techniques
- Model Comparisons: In /r/StableDiffusion, a comparison of PixArt Sigma, Hunyuan DiT, and SD3 Medium models for image generation is presented, with PixArt Sigma and SDXL refinement showing promise.
- ControlNet for SD3: ControlNet Canny and Pose models have been released for SD3, with Tile and Inpainting models coming soon.
- Sampler and Scheduler Permutations: An overview of all working sampler and scheduler combinations for Stable Diffusion 3 is provided.
- CFG Values in SD3: A comparison of different CFG values in Stable Diffusion 3 shows a narrower usable range compared to SD1.
- Playground 2.5 Similar to Midjourney: The Playground 2.5 model is identified as the most similar to Midjourney in terms of output quality and style.
- Layer Perturbation Analysis in SD3: An analysis of how adding random noise to different layers in SD3 affects the final output is conducted, potentially providing insights into how and where SD3 was altered.
Llama and Local LLM Models
- Llama 3 Spellbound: In /r/LocalLLaMA, Llama 3 7B finetune is trained without instruction examples, aiming to preserve world understanding and creativity while reducing positivity bias in writing.
- Models for NSFW Roleplay: A request for models that can run on a 3060 12GB GPU and produce NSFW roleplay similar to a provided example is made.
- Model Similar to Command-R: Someone is seeking a model with similar quality to Command-R but requiring less memory for 64k context size on a Mac with M3 Max 64GB.
- System Prompt for RP/Chatting/Storytelling: A detailed system prompt for controlling models in roleplay, chatting, and storytelling scenarios is shared, focusing on thorough, direct, and symbolic instructions.
- Running High Models on 24GB VRAM: Guidance is sought on running high models/context on 24GB of VRAM, possibly using quantization or 4/8 bits.
- Underlying Model Importance with RAG: A discussion on whether the underlying model matters when using Retrieval-Augmented Generation (RAG) with a solid corpus takes place.
AI Ethics and Regulation
- OpenAI Board Appointment Criticism: Edward Snowden criticizes OpenAI's decision to appoint a former NSA director to its board, calling it a "willful, calculated betrayal of the rights of every person on earth."
- Stability AI's Closed-Source Approach: In /r/StableDiffusion, there is a discussion on Stability AI's decision to go the closed-source API selling route, questioning their ability to compete without leveraging community fine-tunes.
- Clarification on Stable Diffusion TOS: A clarification on the terms of service (TOS) for Stable Diffusion models is provided, addressing misunderstandings caused by a clickbait YouTuber.
- Crowdfunded Open-Source Alternative to SD3: A suggestion to start a crowdfunded open-source alternative to SD3 is made, potentially led by a former Stability AI employee who helped train SD3 but recently resigned.
- Malicious Stable Diffusion Tool on GitHub: A news article reports on hackers targeting AI users with a malicious Stable Diffusion tool on GitHub, claiming to protest "art theft" but actually seeking financial gain through ransomware.
- Impact of Debiasing on Creativity: A research paper discusses the impact of debiasing language models on their creativity, suggesting that censoring models makes them less creative.
AI and the Future
- Feeling Lost Amidst AI Advancements: In /r/singularity, a personal reflection on feeling lost and uncertain about the future in the face of rapid AI advancements is shared.
- Concerns About AI's Impact on Career: Also in /r/singularity, someone expresses feeling lost about the future of AI and their career in light of recent developments.
AI Discord Recap
A summary of Summaries of Summaries
1. AI Model Performance and Scaling
- Scaling Up with New AI Models: DeepSeek's Coder V2 reportedly beats GPT-4 on benchmarks and Google DeepMind reveals new video-to-audio tech creating tracks for any video, gaining traction on Rowan Cheung's X profile.
- Expanding AI Capabilities Across Platforms: Runway introduces Gen-3 Alpha for video generation, enhancing cinematic styles and scene transitions. AP details shared on Twitter.
2. Integration and Implementation Across Platforms
- Hybrid Notes App Unveils LLM integration: OpenRouter unveils a notes app integrating LLMs for dynamic content interaction, though lacking mobile support as specified on their full-screen app.
- Challenges with Implementation on Various Platforms: Users face issues like CORS errors on OpenRouter and integration challenges on LangChain, reflecting the need for better implementation guides or platform-specific APIs.
3. Ethical AI and Governance
- OpenAI Shifts Towards Profit-Driven Model: Speculations and confirmations stir about OpenAI's move towards becoming a profit entity, potentially impacting governance and ethical considerations. More on this from The Information.
- Discussions on AI Ethics Heat Up: Debates continue about data privacy, model biases, and corporate governance in AI, as Edward Snowden criticizes OpenAI's new board appointments on Edward Snowden's X profile.
4. New AI Developments and Benchmarking
- AI Innovations and Improvements Announced: Anthropic publishes insights into AI's ability to tamper with reward systems in their new research article.
- Benchmarking New Models: Stability AI releases SD3 models discussing new techniques for loss stabilization and artifacts management across forums, including a spotlight on Reddit.
5. Collaborative AI Projects and User Engagement
- Community Projects Highlight AI Integration: From a notes app merging notes and API keys management on OpenRouter to innovative AI-driven video generation tools like Dream Machine, community-built tools are pushing the boundaries of creativity and practical AI application, visible on platforms like Lumalabs.
- Interactive AI Discussions and Collabs Flourish: Webinars and collaborative events like the upcoming Mojo Community Meeting encourage deep dives into AI advancements, with detailed discussions and participation boasts from across the global user base as shared on blog.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
- SD3 License Troubles: The new license for Stable Diffusion 3 (SD3) has led to its ban on Civitai due to legal ambiguities, with a review by Civitai's legal team announced in their temporary ban statement.
- Community Rift Over SD3: Users expressed frustration with Stability AI's licensing of SD3, highlighting both confusion and discontent, while some criticized youtuber Olivio Sarikas for allegedly misrepresenting the SD3 license for views, referencing his video.
- Guidance for ComfyUI: Issues around ComfyUI setup sparked technical discussion, with suggested fixes for custom node installations including dependencies like cv2; a user-contributed ComfyUI tutorial was shared to assist.
- Seeking SD3 Alternatives: The dialogue points to a shift towards seeking alternative models and artistic tools, such as video generation with animatediff, possibly due to the ongoing SD3 controversy.
- Misinformation Allegations in the AI Community: Accusations fly regarding youtuber Olivio Sarikas spreading misinformation about SD3's license, with community members challenging the veracity of his content found in his contentious video.
Unsloth AI (Daniel Han) Discord
- Ollama Integration Nears Completion: The Ollama support development has reached 80% completion, with the Unsloth AI team and Ollama collaboratively pushing through delays. Issues with template fine-tuning validation and learning rates concerning Ollama were discussed, along with an issue where running
model.push_to_hub_mergeddoes not save the full merged model, prompting a manual workaround.
- Unsloth Speeds Ahead: Unsloth's training process is touted to be 24% faster than torch.compile() torchtune for the NVIDIA GeForce RTX 4090, as benchmarks show its impressive training speed. Additionally, upcoming multi-GPU support for up to 8 GPUs is being tested with a select group of users getting early access for initial evaluations.
- Training Troubles and Tricks: Members encountered challenges like crashes during saving steps while training the Yi model, possible mismanagement of
quantization_methodduring saving, and confusion around batch sizes and gradient accumulation in VRAM usage. Solutions and workarounds included verifying memory/disk resources and a submitted pull request addressing the quantization error.
- Lively Discussion on Nostalgia and Novelty in Music: Members shared music ranging from a nostalgic 1962 song to iconic tracks by Daft Punk and Darude, showing a light-hearted side to the community. In contrast, concerns were raised over Gemma 2's output on AI Studio, with mixed reactions varying from disappointment to intrigue and anticipation for Gemini 2.0.
- CryptGPT Secures LLMs with an Encryption Twist: CryptGPT was introduced as a concept using the Vigenere cipher to pretrain GPT-2 models on encrypted datasets, ensuring privacy and requiring an encryption key to generate output, as detailed in a shared blog post.
- Singular Message of Curiosity: The community-collaboration channel featured a single message expressing interest, but without further context or detail, its relevance to broader discussion topics remains unclear.
CUDA MODE Discord
- NVIDIA's Next Big Thing Speculated and PyCUDA SM Query Clarified: Engineers speculated about the potential specs of the upcoming NVIDIA 5090 GPU, with rumors of up to 64 GB of VRAM circulating yet met with skepticism. Additionally, a discrepancy in GPU SM count for an A10G card reported by techpowerup was cleared up, with independent sources such as Amazon Web Services confirming the correct count as 80, not the 72 originally stated.
- Triton and Torch Users Navigate Glitches and Limits: Triton users encountered an
AttributeErrorin Colab and debated the feasibility of nested reductions for handling quadrants. Meanwhile, PyTorch users adjusted the SM threshold intorch.compile(mode="max-autotune")to accommodate GPUs with less than 68 SMs and explored enabling coordinate descent tuning for better performance.
- Software and Algorithms Push the AI Envelope: A member lauded the matching of GPT-4 with LLaMA 3 8B, while Akim will attend the AI_dev conference and is open to networking. Elsewhere, Vayuda’s search algorithm paper spurred interest among enthusiasts, discussed across multiple channels. Discussions around AI training, evident in Meta's described challenges in LLM training, underscore the importance of infrastructure adaptability.
- CUDA Development Optics: News from CUDA-focused development revealed: Permuted DataLoader integration did not significantly affect performance; a unique seed strategy was developed for stochastic rounding; challenges surfaced regarding ZeRO-2's memory overhead; and new LayerNorm kernels provided much-needed speedups under certain configurations.
- Beyond CUDA: Dynamic Batching, Quantization, and Bit Packing: In the domain of parallel computing, engineers struggled with dynamic batching for Gaudi architecture and discussed the complexity of quantization and bit-packing techniques. They stressed the VRAM limitations constraining local deployment of large models and shared diverse resources, including links to Python development environments and documentation on novel machine learning libraries.
LM Studio Discord
- LM Studio equips engineers with CLI tools: The latest LM Studio 0.2.22 release introduced 'lms', a CLI management tool for models and debugging prompts, which is detailed in its GitHub repository. The update streamlines the workflow for AI deployments, especially with model loading/unloading and input inspection.
- Performance tweaks and troubleshooting: Engineers discussed optimal settings for AI model performance, including troubleshooting GPU support for Intel ARC A7700, configuration adjustments for GPU layers, and adjusting Flash Attention settings. There was a recommendation to check Open Interpreter's documentation for issues hosting local models and a call for better handling of font sizes in LM Studio interfaces for usability.
- Diverse model engagement: Members recommended Fimbulvetr-11B for roleplaying use-cases, while highlighting the fast-paced changes in coding models like DeepSeek-Coder-V2, advising peers to stay updated with current models for specific tasks like coding, which can be reviewed on sites like Large and Small Language Models list.
- Hardware optimization and issues: A link to archived LM Studio 0.2.23 was shared for those facing installation issues—a MirrorCreator link. Hardware discussions also included the compatibility of mixed RAM sticks, setting CPU cores for server mode, and troubleshooting GPU detection on various systems.
- Development insights and API interactions: Developers shared their aspirations for integrating various coding models like
llama3anddeepseek-coderinto their VSCode workflow and sought assistance with implementing models incontinue.dev. There was also a conversation about decoupling ROCm from the main LM Studio application and a user guide for configuringcontinue.devwith LM Studio.
- Beta release observations and app versioning: The community tested and reviewed recent beta releases, discussing tokenizer fixes and GPU offloading glitches. There’s a need for access to older versions, which is challenged by LM Studio's update policies, and a suggestion to maintain personal archives of preferred versions.
- AI-driven creativity and quality of life concerns: Engineers raised issues like the mismanagement of stop tokens by LM Studio and a tool's tendency to append irrelevant text in outputs. A frequent use-case-related complaint was an AI model not indicating its failure to provide a correct output by using an "#ERROR" message when necessary.
HuggingFace Discord
AI Alternatives for GPT-4 on Low-End Hardware: Users debated on practical AI models for less powerful servers with suggestions like "llama3 (70B-7B), mixtral 8x7B, or command r+" for self-hosted AI similar to GPT-4.
RWKV-TS Challenges RNN Dominance: An arXiv paper introduces RWKV-TS, proposing it as a more efficient alternative to RNNs in time series forecasting, by effectively capturing long-term dependencies and scaling computationally.
Model Selection Matters in Business Use: In the choice of AI for business applications, it's crucial to consider use cases, tools, and deployment constraints, even with a limitation like the 7B model size. For tailored advice, members suggested focusing on specifics.
Innovations and Integrations Abound: From Difoosion, a user-friendly web interface for Stable Diffusion, to Ask Steve, a Chrome extension designed to streamline web tasks using LLMs, community members are actively integrating AI into practical tools and workflows.
Issues and Suggestions in Model Handling and Fine-Tuning: - A tutorial for fine-tuning BERT was shared. - Concerns about non-deterministic model initializations were raised, with advice to save the model state for reproducibility. - Mistral-7b-0.3's context length handling and the quest for high-quality meme generator models indicate challenges and pursuits in model customization. - For TPU users, guidance on using Diffusers with GCP's TPU is sought, indicating an interest in leveraging cloud TPUs for diffusion models.
OpenAI Discord
- iOS Compatibility Question Marks: Members debated whether ChatGPT functioned with iOS 18 beta, recommending sticking to stable versions like iOS 17 and noting that beta users are under NDA regarding new features. No clear consensus was reached on compatibility.
- Open Source Ascending: The release of an open-source model by DeepSeek AI that outperforms GPT-4 Turbo in coding and math sparked debate about the advantages of open-source AI over proprietary models.
- Database Deployments with LLMs: For better semantic search and fewer hallucinations, a community member highlighted OpenAI's Cookbook as a resource for integrating vector databases with OpenAI's models.
- GPT-4 Usage Ups and Downs: Users expressed frustrations with access to GPT interactions, privacy settings on Custom GPTs, and server downtimes. The community provided workarounds and suggested monitoring OpenAI's service status for updates.
- Challenges with 3D Modeling and Prompt Engineering: Conversations focused on the technicalities of generating shadow-less 3D models and the intricacies of preventing GPT-4 from mixing information. Members shared various strategies, including step-back prompting and setting explicit actions to guide the AI's output.
LAION Discord
- Stabilizing SD3 Models: The discussion revolved around SD3 models facing stability hurdles, particularly with artifacts and training. Concerns were raised about loss stabilization, pinpointing issues like non-uniform timestep sampling and missing elements such as qk norm.
- T2I Models Take the Stage: The dialog highlighted interest in open-source T2I (text-to-image) models, notably for character consistency across scenes. Resources such as Awesome-Controllable-T2I-Diffusion-Models and Theatergen were recommended for those seeking reliable multi-turn image generation.
- Logical Limitbreak: A member brought attention to current challenges in logical reasoning within AI, identifying Phi-2's "severe reasoning breakdown" and naming bias in LLMs when tackling AIW problems—a key point supported by related research.
- Boosting Deductive Reasoning: Queries about hybrid methods for enhancing deductive reasoning in LLMs directed to Logic-LM, a method that combines LLMs with symbolic AI solvers to improve logical problem-solving capabilities.
- Video Generation Innovation: Fudan University's Hallo model sparked excitement, a tool capable of video generation from single images and audio, with potential application alongside Text-to-Speech systems. A utility to run it locally was shared from FXTwitter, highlighting community interest in practical integrations.
OpenAccess AI Collective (axolotl) Discord
- 200T Parameter Model: AGI or Fantasy?: Discussions about the accessibility of a hypothetical 200T parameter model surfaced, highlighting both the limits of current compute capabilities for most users and the humor in staking an AGI claim for such models.
- Competing at the Big Model Rodeo: Members juxtaposed the Qwen7B and Llama3 8B models, acknowledging Llama3 8B as the dominant contender in performance. The problem of custom training configurations for Llama3 models was tackled, with a solution shared to address the
chat_templatesetting issues.
- Optimization Quest for PyTorch GPUs: Requests for optimization feedback directed towards various GPU setups in PyTorch have yielded a trove of diverse community experiences ranging from AMD MI300X to RTX 3090, Google TPU v4, and 4090 with tinygrad.
- Navigating Axolotl's Development Labyrinth: An issue halting the development with the Llama3 models was found and traced to a specific commit, which helped identify the problem but emphasized the need for a fix in the main branch. Instructions for setting inference parameters and fine-tuning vision models within Axolotl were detailed for users.
- Data Extraction with a Twist of Structure: Community showcase hinted at positive results after fine-tuning LLMs with Axolotl, particularly in transforming unstructured press releases into structured outputs. A forthcoming post promises to expound on the use of the OpenAI API's function calling to enhance LLM accuracy in this task. The author points to a detailed post for more information.
Perplexity AI Discord
- Pro Language Partnerships!: Perplexity AI has inked a deal with SoftBank, offering Perplexity Pro free for one year to SoftBank customers. This premium service, typically costing 29,500 yen annually, is set to enhance users' exploration and learning experiences through AI (More info on the partnership).
- Circumventing AB Testing Protocols? Think Again: Engineers discussed how to bypass A/B testing for Agentic Pro Search, with a Reddit link provided; however, concerns about integrity led to reconsideration. The community also tackled a myriad of usage questions on Perplexity features, debated the merits of Subscriptions to Perplexity versus ChatGPT, and raised critical privacy issues concerning web crawling practices.
- API Access is the Name of the Game: Members expressed urgency for closed-beta access to the Perplexity API, emphasizing the impact on launching projects like those at Kalshi. Troubleshooting Custom GPT issues, they exchanged tips to enhance its "ask-anything" feature using schema-based explanations and error detail to improve action/function call handling.
- Community Leaks and Shares: Links to Perplexity AI searches and pages on varied topics, from data table management tools (Tanstack Table) to Russia’s pet food market and elephant communication strategies, were circulated. A mishap with a publicized personal document on prostate health led to community-driven support resolving the issue.
- Gaming and Research Collide: The shared content within the community included a mix of academic interests and gaming culture, demonstrated by a publicly posted page pertaining to The Elder Scrolls, hinting at the intersecting passions of the technical audience involved.
Nous Research AI Discord
- Neurons Gaming with Doom: An innovative approach brings together biotech and gaming as living neurons are used to play the video game Doom, detailed in a YouTube video. This could be a step forward in understanding biological process integration with digital systems.
- AI Ethics and Bias in the Spotlight: A critical take on AI discussed in a ResearchGate paper calls attention to AI's trajectory towards promulgating human bias and aligned corporate interests, naming "stochastic parrots" as potential instruments of cognitive manipulation.
- LLM Merging and MoE Concerns: An engaged debate over the practical use of Mixture of Experts (MoE) models surfaced, contemplating the effectiveness of model merging versus comprehensive fine-tuning, citing a PR on llama.cpp and MoE models on Hugging Face.
- Llama3 8B Deployment Challenges: On setting up and deploying Llama3 8B, it was advised to utilize platforms like unsloth qlora, Axolotl, and Llamafactory for training and lmstudio or Ollama for running fast OAI-compatible endpoints on Apple's M2 Ultra, bringing light to tooling for model deployment.
- Autechre Tunes Stir Debate: Opinions and emotions around Autechre's music led to sharing of contrasting YouTube videos, "Gantz Graf" and "Altibzz", showcasing the diverse auditory landscapes crafted by the electronic music duo.
- Explore Multiplayer AI World Building: Suggestion raised for collaborative creation in WorldSim, as members discussed enabling multiplayer features for AI-assisted co-op experiences, while noting censorship from the model provider could influence WorldSim AI content.
- NVIDIA's LLM Rolls Out: Introductions to NVIDIA's Nemotron-4-340B-Instruct model, accessible on Hugging Face, kindled talks on synthetic data generation and strategic partnerships, highlighting the company's new stride into language processing.
- OpenAI's Profit-Minded Pivot: OpenAI's CEO Sam AltBody has indicated a potential shift from a non-profit to a for-profit setup, aligning closer to competitors and affecting the organizational dynamic and future trajectories within the AI industry.
Modular (Mojo 🔥) Discord
- Mojo Functions Discussion Heats Up: Engineers critiqued the Mojo manual's treatment of
defandfnfunctions, highlighting the ambiguity in English phrasing and implications for type declarations in these function variants. This led to a consensus that whiledeffunctions permit optional type declarations,fnfunctions enforce them; a nuanced distinction impacting code flexibility and type safety.
- Meetup Alert: Mojo Community Gathers: An upcoming Mojo Community Meeting was announced, featuring talks on constraints, Lightbug, and Python interoperability, inviting participants to join via Zoom. Moreover, benchmark tests revealed that Mojo's Lightbug outstrips Python FastAPI in single-threaded performance yet falls short of Rust Actix, sparking further discussion on potential runtime costs entailed by function coloring decisions.
- Fresh Release of Mojo 24.4: The Mojo team has rolled out version 24.4, introducing core language and standard library improvements. Detail-oriented engineers were pointed towards a blog post for a deep dive into the new traits, OS module features, and more.
- Advanced Mojo Techniques Uncovered: Deep technical discussions unveiled challenges and insights in Mojo programming, from handling 2D Numpy arrays and leveraging
DTypePointerfor efficient SIMD operations to addressing bugs in casting unsigned integers. Notably, a discrepancy involvingaliasusage in CRC32 table initialization sparked an investigation into unexpected casting behaviors.
- Nightly Mojo Compiler on the Horizon: Engineers were informed about the new nightly builds of the Mojo compiler with the release of versions
2024.6.1505,2024.6.1605, and2024.6.1705, along with instructions to update viamodular update. Each version's specifics could be examined via provided GitHub diffs, showcasing the platform's continuous refinement. Additionally, the absence of external documentation for built-in MLIR dialects was noted, and enhancements such as direct output expressions in REPL were requested.
Eleuther Discord
- Replication of OpenAI's Generalization Techniques by Eleuther: EleutherAI's interpretability team successfully replicated OpenAI's "weak-to-strong" generalization on open-source LLMs across 21 NLP datasets, publishing a detailed account of their findings, positive and negative, on experimenting with variants like strong-to-strong training and probe-based methods, here.
- Job Opportunities and Navigating CommonCrawl: The AI Safety Institute announced new roles with visa assistance for UK relocation on their careers page, while discussions on efficiently processing CommonCrawl data mentioned tools like ccget and resiliparse.
- Model Innovations and Concerns: From exploring RWKV-CLIP, a vision-language model, to concerns about content generated by diffusion models and the stealing of commercial model outputs, the community addressed various aspects of AI model development and security. The effectiveness of the Laprop optimizer was debated, and papers ranging from those on online adaptation to those on "stealing" embedding models were shared, with a key paper being here.
- Evolving Optimization and Scaling Laws: A member's critique of a hypernetwork-based paper sparked conversations on the value and comparison of hypernetworks with Hopfield nets. Interested parties ventured into the scaling of scaling laws, considering online adaptation for LLMs and citing Andy L. Jones' concept of offsetting training compute against inference compute.
- Interpretability Insights on Sparse Autoencoders: Interpretability research centered around Sparse Autoencoders, with a paper proposing a framework for evaluating feature dictionaries in tasks like indirect object identification with GPT-2, and another highlighting "logit prisms" decomposing logit output components, as documented in this article.
- Need for A Shared Platform for Model Evaluation: Calls were made for a platform to share and validate evaluation results of AI models, particularly for those using Hugging Face and seeking to verify the credibility of closed-source models, highlighting the need for comprehensive and transparent evaluation metrics.
- Awaiting Code Release for Vision-Language Project: A specific request for a release date for code related to RWKV-CLIP was directed to the GitHub Issues page of the project, indicating a demand for access to the latest advancements in vision-language representation models.
LLM Finetuning (Hamel + Dan) Discord
- Apple Sidesteps NVIDIA in AI: Apple's WWDC reveal details its avoidance of NVIDIA hardware, preferring their in-house AXLearn on TPUs and Apple Silicon, potentially revolutionizing their AI development strategy. The technical scoop is unpacked in a Trail of Bits blog post.
- Embeddings and Fine-Tuning: Enthusiasm emerges for fine-tuning methodologies, with discussions ranging from embedding intricacies, highlighted by resources like Awesome Embeddings, to specific practices like adapting TinyLlama for unique narration styles, detailed in a developer's blog post.
- Prompt Crafting Innovations: Mention of Promptfoo and inspect-ai indicates a trend toward more sophisticated prompt engineering tools, with the community weighing functionality and user-friendliness. Diverging preferences suggest such tools are pivotal for refined human-AI interaction schemes.
- Crediting Confusions Cleared: Participants express mixed signals about course credits across platforms like LangSmith and Replicate, with reminders and clarifications surfacing through communal support. The difference between beta and course credits was elucidated for concerned members.
- Code Llama Leaps Forward: Conversations ignited by the release of Code Llama show a commitment to enhancing programming productivity. Curiosity about permissible variability between Hugging Face and GitHub configuration formats for Code Llama indicates the precision required for fine-tuning these purpose-built models.
Interconnects (Nathan Lambert) Discord
- Sakana AI Joins the Unicorn Club: Sakana AI, pushing past traditional transformer models, has secured a monster $1B valuation from heavy-hitters like NEA, Lux, and Khosla, marking a significant milestone for the AI community. Full financial details can be ferreted out in this article.
- Next-Gen Video Generation with Runway's Gen-3 Alpha: Runway has turned heads with its Gen-3 Alpha, flaunting the ability to create high-quality videos replete with intricate scene transitions and a cornucopia of cinematographic styles, setting a new bar in video generation which can be explored here.
- DeepMind's Video-Turned-Audio Breakthrough: Google DeepMind's new video-to-audio technology aims to revolutionize silent AI video generations by churning out a theoretically infinite number of tracks tailored to any video, as showcased in Rowan Cheung's examples.
- Wayve's Impressive Take on View Synthesis: Wayve claims a fresh victory in AI with a view synthesis model that leverages 4D Gaussians, promising a significant leap in generating new perspectives from static images, detailed in Jon Barron's tweet.
- Speculations Stir on OpenAI's Future: Whispers of OpenAI's governance shake-up suggest a potential pivot to a for-profit stance with musings of a subsequent IPO, stirring debate within the community; some greet with derision while others await concrete developments, as covered in The Information and echoed by Jacques Thibault's tweet.
LlamaIndex Discord
- RAG and Agents Drawn Clear: An Excalidraw-enhanced slide deck was shared detailing the construction of Retrieval-Augmented Generation (RAG) and Agents, containing diagrams that elucidate concepts from simple to advanced levels.
- Observability Integrated in LLM Apps: A new module for instrumentation brings end-to-end observability to LLM applications through Arize integration, with a guide available detailing custom event/span handler instrumentation.
- Knowledge Graphs Meet Neo4j: Discussions around integrating Neo4j knowledge graphs with LlamaIndex focused on transforming Neo4j graphs into property graphs for LlamaIndex, with resources and documentation provided (LlamaIndex Property Graph Example).
- Enhanced LLMs with Web Scraping Strategies: Apublication discusses improving LLMs by combining them with web scraping and RAG, recommending tools such as Firecrawl for effective Markdown extraction, and Scrapfly for diverse output formats suitable for LLM preprocessing.
- Practical Tutorials and AI Event Highlights: Practical step-by-step guides for full-stack agents and multimodal RAG pipelines were made available, and AI World's Fair highlighted with noteworthy speakers shared their knowledge on AI and engineering, enhancing the community's skill set and understanding of emerging AI trends.
tinygrad (George Hotz) Discord
- Script Snafu and OpenCL Woes: Discussions around
autogen_stubs.shrevealed thatclang2pybreaks the indentation, but this was found unnecessary for GPU-accelerated tinygrad operations. Meanwhile, George Hotz suggested fixing OpenCL installation and verifying withclinfodue to errors affecting tinygrad's GPU functionality.
- Enhanced OpenCL Diagnostics on the Horizon: A move to improve OpenCL error messages is underway, with a proposed solution that autonomously generates messages from available OpenCL headers, aiming to ease developers' debugging process.
- Deciphering Gradient Synchronization: In a bid to demystify gradient synchronization, George Hotz affirmed Tinygrad's built-in solution within its optimizer, touting its efficiency compared to the more complex Distributed Data Parallel in PyTorch.
- Chasing PyTorch's Tail with Ambitions and Actions: George Hotz conveyed ambitions for tinygrad to eclipse PyTorch in terms of speed, simplicity, and reliability. Although currently trailing, particularly in LLM training, tinygrad's clean design and strong foundation exude promise.
- Precision Matters in the Kernel Cosmos: A technical exchange discussed strategies for incorporating mixed precision in models, where George Hotz recommended late casting for efficiency gains and the use of
cast_methods, highlighting a critical aspect of optimizing for computation-heavy tasks.
OpenRouter (Alex Atallah) Discord
- GPT Notes App Unveiled: An LLM client and notes app hybrid has been demonstrated, featuring dynamic inclusion of notes, vanilla JavaScript construction, and local storage of notes and API keys in the browser; however, it currently lacks mobile support. The app is showcased with a Codepen and a full-screen deployment.
- OpenRouter Gripes and Glimpses: OpenRouter requires at least one user message to prevent errors, with users suggesting the use of the
promptparameter; formatting tools like PDF.js and Jina AI Reader are recommended for PDF pre-processing to enhance LLM compatibility.
- Censorship Consternation with Qwen2: The Qwen2 model is facing user criticism for excessive censorship, while the less restrictive Dolphin Qwen 2 model garners recommendation for its more realistic narrative generation.
- Gemini Flash Context Clash: Questions arise over Gemini Flash's token limits, with OpenRouter listing a 22k limit, in contrast to the 8k tokens cited in the Gemini Documentation; the discrepancy is attributed to OpenRouter's character counting to align with Vertex AI's pricing.
- Rate Limits and Configuration Conversations: Users discuss rate limits for models like GPT-4o and Opus and model performance configurations; for further information, the OpenRouter documentation on rate limits proves informative, and there is a focus on efficiency in API requests and usage.
LangChain AI Discord
- LangChain API Update Breaks TextGen: A recent API update has disrupted textgen integration in LangChain, with members seeking solutions in the general channel.
- Technical Troubleshooting Takes the Stage: Users discussed challenges with installing langchain_postgres and a ModuleNotFoundError caused by an update to tenacity version 8.4.0; reverting to version 8.3.0 fixed the issue.
- LangChain Knowledge Sharing: Questions around LangChain usage emerged, including transitioning from Python to JavaScript implementations, and handling of models like Llama 3 or Google Gemini for local deployment.
- Tech enthusiasts Intro New Cool Toys: Innovative projects were highlighted such as R2R's automatic knowledge graph construction, an interactive map for Collision events, and CryptGPT, which is a privacy-preserving approach to LLMs using Vigenere cipher.
- AI for the Creatively Inclined: Community members announced a custom GPT for generating technical diagrams, and Rubik's AI, a research assistant and search engine offering free premium with models like GPT-4 Turbo to beta testers.
Latent Space Discord
OtterTune Exits Stage Left: OtterTuneAI has shut down following a failed acquisition deal, marking the end of their automatic database tuning services.
Apple and OpenAI Make Moves: Apple released optimized on-device models on Hugging Face, such as DETR Resnet50 Core ML, while OpenAI faced criticism from Edward Snowden for adding former NSA Director Paul M. Nakasone to its board.
DeepMind Stays in Its Lane: In recent community discussions, it was clarified that DeepMind has not been contributing to specific AI projects, debunking earlier speculation.
Runway and Anthropic Innovate: Runway announced their new video generation model, Gen-3 Alpha, on Twitter, while Anthropic publicized important research on AI models hacking their reward systems in a blog post.
Future of AI in Collaboration and Learning: Prime Intellect is set to open source sophisticated models DiLoco and DiPaco, Bittensor is making use of The Horde for decentralized training, and a YouTube video shared among users breaks down optimizers critical for model training.
Cohere Discord
- AGI: Fantasy or Future?: Members shared their perspectives on a YouTube video about AGI, discussing the balance between skepticism and the potential for real progress that parallels the aftermath of the dot-com bubble.
- Next.js Migrations Ahead: There's a collaborative push to utilize Next.js App Router for the Cohere toolkit, aiming at better code portability and community contribution, details of which are in GitHub issue #219.
- C4AI by Cohere: Nick Frosst invites to a C4AI talk via a Google Meet link, offering an avenue for community engagement on LLM advancements and applications.
- Command Your Browser: A free Chrome Extension has been released, baking LLMs into Chrome to boost productivity, while an interactive Collision map with AI chat features showcases events using modern web tech stacks.
- Developer Touch Base: Cohere is hosting Developer Office Hours with David Stewart for a deep dive into API and model intricacies; interested community members can join here and post their questions on the mentioned thread for dedicated support.
OpenInterpreter Discord
- Frozen Model Mystery Solved: Engineers reported instances of a model freezing during coding, but it was determined that patience pays off as the model generally completes the task, albeit with a deceptive pause.
- Tech Support Redirect: A query about Windows installation issues for a model led to advice pointing the user towards a specific help channel for more targeted assistance.
- Model Memory Just Got Better: A member celebrated a breakthrough with memory implementation, achieving success they described in rudimentary terms; meanwhile, Llama 3 Instruct 70b and 8b performance details were disclosed through a Reddit post.
- Cyber Hat Countdown: An open-source, AI-enabled “cyber hat” project sparked interest among engineers for its originality, potential for innovation, and an open invite for collaboration watch here; similarly, Dream Machine’s text and image-based realistic video creation signaled strides in AI model capabilities.
- Semantic Search Synergy: Conversation turned to the fusion of voice-based semantic search and indexing with a vector database holding audio data, leveraging the prowess of an LLM to perform complex tasks based on vocal inputs, suggesting the nascent power of integrated tech systems.
Torchtune Discord
- Tuning Into Torchtune's Single Node Priorities: Torchtune is focusing on optimizing single node training before considering multi-node training; it utilizes the
tune runcommand as a wrapper fortorch run, which might support multi-node setups with some adjustments, despite being untested for such use.
- Unlocking Multi-Node Potential in Torchtune: Some members shared how to potentially configure Torchtune for multi-node training, suggesting the use of
tune run —nnodes 2and additional tools like TorchX or slurm for script execution and network coordination across nodes, referencing the FullyShardedDataParallel documentation as a resource for sharding strategies.
DiscoResearch Discord
- Llama3 Sticks to Its Roots: Despite the introduction of a German model, the Llama3 tokenizer has not been modified and remains identical to the base Llama3, raising questions about its efficiency in handling German tokens.
- Token Talk: Concerns emerged over the unchanged tokenizer, with engineers speculating that not incorporating specific German tokens could substantially reduce the context window and affect the quality of embeddings.
- Comparing Llama2 and Llama3 Token Sizes: Inquisitive minds noted that Llama3's tokenizer is notably 4 times larger than Llama2's, leading to questions about its existing efficacy with the German language and potential unrecognized issues.
Datasette - LLM (@SimonW) Discord
Heralding Data Engineering Job Security: ChatGPT's burgeoning role in the tech landscape drew humor-inflected commentary that it represents an infinite job generator for data engineers.
Thoughtbot Clears the Fog on LLMs: The guild appreciated a guide by Thoughtbot for its lucidity in dissecting the world of Large Language Models, specifically for their delineation of Base, Instruct, and Chat models which can aid beginners.
New Kid on the Search Block: Turso's latest release integrates native vector search with SQLite, which aims at enhancing the AI product development experience by replacing the need for independent extensions like sqlite-vss.
AI Stack Devs (Yoko Li) Discord
- In Search of Hospital AI Project Name: User gomiez inquired about the name of the hospital AI project within the AI Stack Devs community. There was no additional context or responses provided to further identify the project.
Mozilla AI Discord
- Llama as Firefox's New Search Companion?: A guild member, cryovolcano., inquired about the possibility of integrating llamafile with tinyllama as a search engine in the Firefox browser. No further details or context about the implementation or feasibility were provided.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #general-chat (723 messages🔥🔥🔥):
- Lack of Trust in SD3 License Creates Chaos: There are significant concerns over Stability AI's new license for SD3, leading to temporary banning of SD3-related content on Civitai due to the perceived legal ambiguities. Civitai announcement mentions that "legal team review" is underway.
- Community Frustration and Critics' Backlash: Many users voice their frustrations and criticisms towards Stability AI's confusing license and handling of SD3’s release. One user notes, “The worst base model release yet… I just wanted nice hands.”
- Inquiry and Troubleshooting in ComfyUI: Several users discuss issues and fixes for ComfyUI setup, particularly around custom nodes installations and dependencies like cv2. One user shared a helpful ComfyUI install tutorial.
- Interest in Model Applications and Alternatives: Users explore models for various art styles and uses, such as retro dark fantasy and video generation with animatediff tools. User discussions imply the open-source community might pivot attention to alternative models and tools post-SD3 controversy.
- Youtuber Olivio Sarikas Faces Scrutiny: Multiple users discuss the youtuber's video on SD3's license, accusing him of spreading misinformation and overblown fears about the legal implications, with one stating, "Olivio had all the information... and willfully misreported it to farm views.”
- - YouTube: no description found
- PenelopeSystems/penelope-palette · Hugging Face: no description found
- SD3 - Absurd new License. Stability AI asks you to destroy your Models!: The new SD3 License from Stability AI asks you to destroy your models. The new Creator License has some pretty absurd Terms. Including limiting you to only 6...
- YouTube: no description found
- SD3 - Absurd new License. Stability AI asks you to destroy your Models!: The new SD3 License from Stability AI asks you to destroy your models. The new Creator License has some pretty absurd Terms. Including limiting you to only 6...
- Stable Diffusion 3's Concerning Fine Print: What Studios and Artists Should Know About the New Terms: We took a look at the fine print of Stable Diffusion 3's new licenses and break down what you need to know if you are planning to use SD3 for commercial or n...
- ONNX | Home: no description found
- SD3 - Absurd new License. Stability AI asks you to destroy your Models!: The new SD3 License from Stability AI asks you to destroy your models. The new Creator License has some pretty absurd Terms. Including limiting you to only 6...
- DreamStudio: no description found
- SD3 IS HERE!! ComfyUI Workflow.: SD3 is finally here for ComfyUI!Topaz Labs: https://topazlabs.com/ref/2377/HOW TO SUPPORT MY CHANNEL-Support me by joining my Patreon: https://www.patreon.co...
- Temporary Stable Diffusion 3 Ban | Civitai: Unfortunately, due to a lack of clarity in the license associated with Stable Diffusion 3 , we are temporarily banning: All SD3 based models All mo...
- ByteDance/Hyper-SD · Hugging Face: no description found
- Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis: no description found
- GitHub - Picsart-AI-Research/StreamingT2V: StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text: StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text - Picsart-AI-Research/StreamingT2V
- Shoe Nike GIF - Shoe Nike Design Shoe - Discover & Share GIFs: Click to view the GIF
- GitHub - Fannovel16/comfyui_controlnet_aux: ComfyUI's ControlNet Auxiliary Preprocessors: ComfyUI's ControlNet Auxiliary Preprocessors. Contribute to Fannovel16/comfyui_controlnet_aux development by creating an account on GitHub.
- Tweet from D̷ELL (@xqdior): Stable Diffusion 3 8Bを搭載した、Stable Image API Ultraをみなさまに体験していただきました。生成いただいた画像をまとめましたので、レポートさせて頂きます。 Stable Diffusion 3 最上級モデルの性能を、ぜひご覧くださいませ。 https://qiita.com/nqdior/items/ce894b5c5382b2029ced #Qiita
- sd web ui 3d lora: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- Tweet from -Zho- (@ZHOZHO672070): InstantX 刚刚又连续上传了 4 个 SD3 Medium 的 ControlNet 模型 Canny(1024):https://huggingface.co/InstantX/SD3-Controlnet-Canny Pose:https://huggingface.co/InstantX/SD3-Controlnet-Pose Tile(还在上传):https://huggingfa...
- Releases · comfyanonymous/ComfyUI: The most powerful and modular stable diffusion GUI, api and backend with a graph/nodes interface. - comfyanonymous/ComfyUI
- Professional Membership Agreement — Stability AI: no description found
- ptx0/sd3-reality-mix · Hugging Face: no description found
- nerijs/pixel-art-medium-128-v0.1 · Hugging Face: no description found
- Civitai: The Home of Open-Source Generative AI: Explore thousands of high-quality Stable Diffusion models, share your AI-generated art, and engage with a vibrant community of creators
- Reddit - Dive into anything: no description found
- Realistic Vision V6.0 B1 - V5.1 Hyper (VAE) | Stable Diffusion Checkpoint | Civitai: Recommendations for using the Hyper model: Sampler = DPM SDE++ Karras or another / 4-6+ steps CFG Scale = 1.5-2.0 ( the lower the value, the more m...
{kind=link}
Unsloth AI (Daniel Han) ▷ #general (517 messages🔥🔥🔥):
- Work in Progress on Ollama Support: A member stated, "Unfortunately the Ollama support got kinda delayed," but reassured that they are "working with the amazing Ollama team." The support is around 80% complete.
- Validation Issues in Template Fine-Tuning: A member queried about validating templates for use with Ollama and discussed issues with learning rates and model configurations. They noted, "I had acceptable results with my merged models but it turns sick sometimes."
- Push to HF Merged Models Issue: A member raised a problem where running `model.push_to_hub_merged` only saves the adapter but not the full merged model. Another member suggested a workaround involving manually merging before uploading.
- Training Performance Comparisons: A user highlighted UnsLoath's performance in training speed, claiming it was "24% faster than torch.compile() torchtune for 4090" based on their benchmarking results. The UnsLoath team acknowledged this and discussed the possibility of releasing an academic paper on it.
- Upcoming Multi-GPU Support: The team confirmed that they will be implementing multi-GPU support up to 8 GPUs. A small group is getting early access for initial testing.
- Join the Ollama Discord Server!: Check out the Ollama community on Discord - hang out with 49602 other members and enjoy free voice and text chat.
- nyunai/nyun-c2-llama3-50B · Hugging Face: no description found
- Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B: This paper introduces the MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS), designed to enhance performance in complex m...
- Lecture 10: Build a Prod Ready CUDA library: Slides https://drive.google.com/drive/folders/158V8BzGj-IkdXXDAdHPNwUzDLNmr971_?usp=sharingSpeaker: Oscar Amoros Huguet
- KAN: Kolmogorov-Arnold Networks: A Google Algorithms Seminar TechTalk, presented by Ziming Liu, 2024-06-04ABSTRACT: Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmo...
- torchtune vs axolotl vs unsloth Trainer Performance Comparison: A performance comparison of various trainers and GPUs. Made by lhl using Weights & Biases
- Card Codes GIF - Card Codes - Discover & Share GIFs: Click to view the GIF
- Tweet from Ryan Els (@RyanEls4): AI revealed 😲
- save_pretrained_merged doesn't merge the model · Issue #611 · unslothai/unsloth: Problem My goal, I want to save the merged model as a GGUF file, but I'm getting various errors. The deeper problem seems to be that merging lora+base model isn't saving a merged file. I think...
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Tweet from AI Engineer (@aiDotEngineer): We're excited to announce our speakers! CEO @Modular AI LEAD @MozillaAI ENG LEAD @OpenAI CEO @UnslothAI TBA @Microsoft TBA @AnthropicAI CEO @cognition_labs (Devin) CEO @anysphere (@cursor_ai) CTO...
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Google Colab: no description found
- Continued LLM Pretraining with Unsloth: Make a model learn a new language by doing continued pretraining with Unsloth using Llama 3, Phi-3 and Mistral.
- Google Colab: no description found
- Reddit - Dive into anything: no description found
- Training Comparison: Sheet1 Run,Trainer,GPU,Train (h),Max Mem (GiB),Power (W),Energy (kWh),Tok/s,Steps,Optimizer,Max Seq,Batch Size,Grad Accum,Global,Notes <a href="https://wandb.ai/augmxnt/train-bench/runs/n59y6...
- augmxnt: Weights & Biases, developer tools for machine learning
Unsloth AI (Daniel Han) ▷ #random (17 messages🔥):
- Vintage Music Video Shared: A member posted a YouTube video titled "Not like us (1962) full song," indicating their appreciation for older music styles. Another member complimented the taste, humorously noting they've only listened to anime songs.
- Darude's Sandstorm and Musical Preferences: A member jokingly shared Darude - Sandstorm, later revealing a genuine preference for Daft Punk's Discovery album, sharing it on Spotify. Other users chimed in to share their favorite Daft Punk songs like "Lose Yourself to Dance."
- Mixed Reactions to Gemma 2 on AI Studio: A member mentioned trying out Gemma 2 27b on aistudio.google.com, noting the output was not impressive. Another user recognized the reference from Reddit, while others expressed excitement and anticipation for Gemma 2 and its potential capabilities.
- Speculation and Excitement for Gemini 2.0: Users speculated that the release of Gemma 2 could mean that Gemini 2.0 is also near. There was notable excitement about the potential for training the model, with one user contemplating renting a Runpod 48GB instance to thoroughly test the model's performance and capacity.
- Not like us (1962) full song: K Dot senior is back to fulfill your requests for the full version of this song.
- Darude - Sandstorm: New Darude album "Together" out now → https://found.ee/Darude-TogetherNew 'Closer Together' music video out now → https://youtu.be/edUBI3k2lUo?si=ynkxg7p7Ofa...
- Spotify - Web Player: Music for everyone: Spotify is a digital music service that gives you access to millions of songs.
- High Life: Daft Punk · Song · 2001
Unsloth AI (Daniel Han) ▷ #help (304 messages🔥🔥):
- Facing issues with Triton on Windows: A member reported issues installing Triton on Windows 11 even after setting up Visual C++ correctly. Assistance was provided by querying if
g++orclang++could be called from the terminal.
- Data Preparation Tutorial Request: A member inquired about a data preparation tutorial for Unsloth fine-tuning similar to OpenAI's chat fine-tuning data prep notebook. Another member cited a plan to create a tutorial and recommended a related YouTube video.
- Model training crashes during saving: A member experienced crashes while training the Yi model during the last saving steps, suspecting memory or disk space issues. It was suggested to check available memory and disk space, and a link to Unsloth's saving issues on GitHub was provided.
- Issues with batch size and gradient accumulation: A member questioned the discrepancy in VRAM usage when adjusting batch size and gradient accumulation. Discussions clarified that gradient accumulation steps act similar to increasing batch size, and experimenting with larger batch sizes was recommended.
- Error with quantization_method in save.py: A bug was identified where
quantization_methodwas mishandled as a string, leading to errors. A workaround involved passingquantization_methodas a list, and a pull request to fix the bug was submitted.
- CUDA Quick Start Guide: no description found
- Llama 3 Fine Tuning for Dummies (with 16k, 32k,... Context): Learn how to easily fine-tune Meta's powerful new Llama 3 language model using Unsloth in this step-by-step tutorial. We cover:* Overview of Llama 3's 8B and...
- Data preparation and analysis for chat model fine-tuning | OpenAI Cookbook: no description found
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- maplerxyz1/rbxidle · Datasets at Hugging Face: no description found
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - Syllo/nvtop: GPU & Accelerator process monitoring for AMD, Apple, Huawei, Intel, NVIDIA and Qualcomm: GPU & Accelerator process monitoring for AMD, Apple, Huawei, Intel, NVIDIA and Qualcomm - Syllo/nvtop
- Continuous training on Fine-tuned Model: Thank you for your reply. I tried this as well. My old dataset and the new dataset has different texts. This method makes the model heavily lean towards the new text provided. This results in the te...
- I got unsloth running in native windows. · Issue #210 · unslothai/unsloth: I got unsloth running in native windows, (no wsl). You need visual studio 2022 c++ compiler, triton, and deepspeed. I have a full tutorial on installing it, I would write it all here but I’m on mob...
- Fix breaking bug in save.py with interpreting quantization_method as a string when saving to gguf by ArcadaLabs-Jason · Pull Request #651 · unslothai/unsloth: Context Upon attempting to save my fine-tuned models as gguf I encountered a new error as of today. Upon investigation I discovered the issue to be some code that incorrectly broke strings passed f...
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- unsloth/unsloth/save.py at main · unslothai/unsloth: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #showcase (3 messages):
- CryptGPT introduces privacy-preserving LLMs: A user shared an introductory blog post titled "CryptGPT: Privacy-Preserving LLMs using Vigenere cipher". The blog post describes pretraining a GPT-2 model on an encrypted dataset, achieving comparable performance to a regular GPT-2 but requiring an encryption key to use it. Blog Post Link.
Link mentioned: Tweet from Diwank Singh (@diwanksingh): http://x.com/i/article/1802116084507848704
Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
starsupernova: Oh very interesting!
CUDA MODE ▷ #general (49 messages🔥):
- Lighting AI Interface Suggestions: A member shared the NVIDIA warp example code and sought advice on a graphical interface to see the rendered results. They considered setting up a VNC session to resolve the issue.
- Solved NVRTC Compilation Error: A user described an issue with NVRTC where compiling multiple kernels resulted in 'invalid resource handle'. They later resolved it by avoiding initializing a new context for each compilation, which was causing CUDA to free the modules/functions.
- GPU SM Count Discrepancy: A query was raised about the discrepancies between measured and reported SM counts for the A10G GPU, noting that techpowerup reports 72 SMs while pycuda measures 80. It was clarified that the site might be wrong and other sources confirm 80 SMs.
- New NVIDIA 5090 GPU Speculations: Members discussed the upcoming NVIDIA 5090, with speculations about it having up to 64 GB of VRAM (source). There were debates about the likelihood of these specs, with pessimistic views on seeing 64GB in consumer versions.
- Value of Forum Knowledge in Daily AI Work: A member expressed doubts about the practical value of most discussions in their daily AI work apart from a few specific topics. Others responded by emphasizing the importance of performance optimization and the general value of learning and being part of such communities.
- Chinese zodiac - Wikipedia: no description found
- warp/warp/examples/core/example_sph.py at main · NVIDIA/warp: A Python framework for high performance GPU simulation and graphics - NVIDIA/warp
- NVIDIA A10 vs A10G for ML model inference: The A10, an Ampere-series GPU, excels in tasks like running 7B parameter LLMs. AWS's A10G variant, similar in GPU memory & bandwidth, is mostly interchangeable.
- Reddit - Dive into anything: no description found
- NVIDIA GeForce RTX 3090 Specs: NVIDIA GA102, 1695 MHz, 10496 Cores, 328 TMUs, 112 ROPs, 24576 MB GDDR6X, 1219 MHz, 384 bit
- NVIDIA GeForce RTX 4090 Specs: NVIDIA AD102, 2520 MHz, 16384 Cores, 512 TMUs, 176 ROPs, 24576 MB GDDR6X, 1313 MHz, 384 bit
- NVIDIA A10G Specs: NVIDIA GA102, 1710 MHz, 9216 Cores, 288 TMUs, 96 ROPs, 24576 MB GDDR6, 1563 MHz, 384 bit
CUDA MODE ▷ #triton (2 messages):
- AttributeError in Triton on Colab: A user encountered an AttributeError while running Fused Softmax from Triton's official tutorial on Colab. The error message indicated
'CudaDriver' object has no attribute 'active'and they are seeking assistance for this issue.
- Nested Reduction Feasibility in Triton: Another user inquired about the possibility of performing nested reductions in Triton. They are interested in running reduction code at various stages to handle quadrants individually, asking if this staged reduction is supported.
CUDA MODE ▷ #torch (10 messages🔥):
- Error with
torch.compile(mode="max-autotune"): A user reported receiving an error message,Not enough SMs to use max_autotune_gemm mode, due to a hard-coded limit of 68 SMs in the PyTorch code, while their GPU only has 66 SMs. The user shared a link to the relevant section in the PyTorch repository.
- Discussion on Reducing SM Threshold: A member suggested lowering the SM threshold to test if performance remains good without needing to rebuild from source. The lack of consumer GPUs in CI was mentioned as a reason for the current hard-coded value.
- Testing Performance with Modified SM Threshold: After changing the SM threshold to 0, the user reported no significant performance improvement.
- Enabling Coordinate Descent Tuning: Another member proposed enabling coordinate descent tuning found in
inductor/config.pyas a potential solution for improving performance.
Link mentioned: pytorch/torch/_inductor/utils.py at f0d68120f4e99ee6c05f1235d9b42a4524af39d5 · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
CUDA MODE ▷ #algorithms (2 messages):
- Vayuda paper sparks interest in search algorithms: A member shared a link to the Vayuda paper expressing hope that more people would work on search. This implies a potential for significant research and development in the area.
- GPT-4 matches LLaMA 3 8B impressively: A member was impressed by how matching GPT-4 with LLaMA 3 8B turned out. They highlighted this achievement as noteworthy in current AI capabilities.
CUDA MODE ▷ #beginner (5 messages):
- Blockwise softmax not in PMPP book: Blockwise softmax concepts are not covered in the PMPP book, but understanding the flash-attn algorithm and shared memory (smem) is crucial. High-end implementations leverage tensor cores, requiring further exploration into resources like CUTLASS.
- Start with accessible YouTube lectures: For newcomers to GPU programming and high-performance computing, starting with YouTube lectures is advised. These lectures aim to provide an accessible introduction to the fundamentals.
CUDA MODE ▷ #jax (1 messages):
- Announcing tpux for simplifying Cloud TPU: A member announced the tpux project, a suite of tools aimed at simplifying Cloud TPU setup and operation to facilitate the usage of JAX across multiple hosts. For more details, visit tpux on GitHub and give it a ⭐️.
Link mentioned: GitHub - yixiaoer/tpux: A set of Python scripts that makes your experience on TPU better: A set of Python scripts that makes your experience on TPU better - yixiaoer/tpux
CUDA MODE ▷ #torchao (11 messages🔥):
- Quant API Import Documentation Issue: A member flagged a correction stating,
unwrap_tensor_subclass()should be imported fromtorchao.utilsortorchao.quantization.quant_api, nottorchao.quantization.utils. They emphasized the importance of users callingunwrap_tensor_subclass()before compiling the quant model to avoid errors.
- API Release Delay and BC Issues: It was confirmed that the 0.3 release is being delayed due to backward compatibility issues that need resolution. This delay ensures the team can address and fix critical problems.
- Innovative API Naming with 'brrr' Proposal: There was a playful yet practical suggestion to create an API with the name
brrrthat adds additional experimental flags based on the number of 'r's. A member humorously asked if this was serious but also hinted at a need for easier control overtorchinductorflags likeuse_mixed_mm.
- Feedback on
use_mixed_mmFlag: A member suggested enabling theuse_mixed_mmflag by default if the relevant kernel in AO is on. This feedback may lead to a GitHub issue for further discussion and implementation.
CUDA MODE ▷ #off-topic (10 messages🔥):
- Meta tackles large-scale AI training challenges: Meta's article discusses the complexity and computation required to train large language models (LLMs). The shift to generative AI has necessitated a rethinking of software, hardware, and network infrastructure.
- Interview with Esolang Academics: A YouTube video titled "Interview with Esolang Academic 2024" was shared. The full version and BC Vim Linter will be available on Patreon for $5 the following day.
- Pessimistic Neko's Jensen Emojis: Member pessmistic_neko posted emojis <:jensen:1189650200147542017> to express their amusement.
- Interview with Esolang Academic 2024: Esoteric programming languageFull version + BC Vim Linter for $5 tomorrow on: https://www.patreon.com/ProgrammersAreAlsoHuman Interview with an Esoteric deve...
- How Meta trains large language models at scale: As we continue to focus our AI research and development on solving increasingly complex problems, one of the most significant and challenging shifts we’ve experienced is the sheer scale of co…
- How Meta trains large language models at scale: As we continue to focus our AI research and development on solving increasingly complex problems, one of the most significant and challenging shifts we’ve experienced is the sheer scale of co…
CUDA MODE ▷ #irl-meetup (1 messages):
- Catch Akim at AI_dev Conference: One member mentioned they will "probably be at AI_dev" and invited others to reach out. They also noted that there will be a movie about "PyTorch" shown on Tuesday.
CUDA MODE ▷ #llmdotc (473 messages🔥🔥🔥):
- DataLoader PR merged, surprising no performance difference: The Permuted DataLoader PR was merged after some discussion and testing, although initial runs showed no performance improvement. A surprised Aleksa retested and finally confirmed a slight improvement in validation loss.
- Stochastic rounding only with unique seeds: The PR to ensure unique seeds for stochastic rounding was discussed. The team discovered that an overflow feature in their approach was actually intended by the noise function algorithm.
- ZeRO-2 PR has noticeable memory overhead: PR 593 for ZeRO-2 was discussed for its complexity and memory overhead. Suggestions included falling back to ZeRO-1 for certain parameters.
- Master weight storage: A PR (https://github.com/karpathy/llm.c/pull/522) to save master weights to resume state was merged to improve determinism. Follow-up tasks included verifying determinism through CI and exploring memory-saving techniques such as saving 16-bit master weights.
- LayerNorm kernel optimization delivers speedup: Profiling data indicated that the new LayerNorm kernel (kernel 6) was faster than the older ones (kernel 3 and 5). This boosted certain tasks significantly especially under specific configurations, like recompute=2.
- Revisiting BFloat16 Training: State-of-the-art generic low-precision training algorithms use a mix of 16-bit and 32-bit precision, creating the folklore that 16-bit hardware compute units alone are not enough to maximize model acc...
- Tweet from undefined: no description found
- Noise-Based RNG: In this 2017 GDC Math for Game Programmers talk, SMU Guildhall's Squirrel Eiserloh discuss RNGs vs. noise functions, and shows how the latter can replace th...
- Tweet from Squirrel Eiserloh (@SquirrelTweets): Updated my raw noise function. Eliminates a flaw discovered by @ptrschmdtnlsn in which certain high input bits lacked influence over certain low output bits. Anyone using Squirrel3 from my GDC 2017 ...
- Noise-Based RNG: In this 2017 GDC Math for Game Programmers talk, SMU Guildhall's Squirrel Eiserloh discuss RNGs vs. noise functions, and shows how the latter can replace th...
- Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations: Scale has become a main ingredient in obtaining strong machine learning models. As a result, understanding a model's scaling properties is key to effectively designing both the right training setu...
- Use faster kernel for LayerNorm forward by gordicaleksa · Pull Request #600 · karpathy/llm.c: I ran kernel 5 under /dev/cuda/ (./layernorm_forward 5) on both RTX 3090 and H100 systems and it's faster on both of them. Numbers: kernel 3, optimal block size on: RTX 3090 → 32 (689.11 GB/s) H1...
- llm.c/llmc/global_norm.cuh at master · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- add scripts to export to HF and run Eleuther evals by karpathy · Pull Request #594 · karpathy/llm.c: no description found
- GELU Fusion with cuBLASLt (SLOWER because it only merges in FP16 mode, not BF16/FP32...) by ademeure · Pull Request #338 · karpathy/llm.c: It turns out that not only is cuBLASLt not able to fuse BF16 GELU (or RELU) into a BF16 matmul, it also ends up with a strange kernel that is slower than our own GELU kernel as it does 2 writes per...
- Hotfix - proper handling of max num of block sums by gordicaleksa · Pull Request #602 · karpathy/llm.c: The previous assert logic was too restrictive as it depended on the number of layers of the model and the specification of the GPU (num of SMs & max number of threads per SM). This PR fixes that. ...
- fix sync issue that results in incorrect gradient accumulation and incorrect loss by WilsonCWu · Pull Request #30 · karpathy/build-nanogpt: Repro Used torch version '2.3.1+cu121'. Set B = 16 (from 64). The following losses were observed: 250 val 6.4300 250 hella 0.2440 250 train 6.387966 ... 1000 val 4.8797 1000 hella 0.2419 1000 ...
- Fix stochastic rounding in encoder backward kernel by gordicaleksa · Pull Request #601 · karpathy/llm.c: #597 provided unique seeds to adamw update. This PR does the same thing for the encoder backward which is the only other place where we do stochastic rounding.
- Dataloader - introducing randomness by gordicaleksa · Pull Request #573 · karpathy/llm.c: On the way to fully random train data shuffling... This PR does the following: Each process has a different unique random seed Each process train data loader independently chooses its starting sha...
- Changes toward `layernorm_forward` in `dev/cuda` by KarhouTam · Pull Request #595 · karpathy/llm.c: Remove cooperative groups Following the instructions in #292, remove cooperative groups codes in existing layernorm forward kernels. benchmark Performance before and after changes: Block Size l...
- Fused Forward GELU (again) by ademeure · Pull Request #591 · karpathy/llm.c: This turns out to be properly fused (and therefore faster) on H100 with CUDA 12.5 - it was definitely not fused and actually noticeably slower on RTX 4090 with CUDA 12.4, I suspect that is more abo...
- Added packed layernorm_forward by ChrisDryden · Pull Request #513 · karpathy/llm.c: This is the implementation of using packed data types for layernorm and has an associated speedup of around 50% for this kernel in the dev files, waiting for the PR for making the data types in tha...
- Added additional layernorm forward kernel that does not recalculate mean and rstd by ChrisDryden · Pull Request #506 · karpathy/llm.c: This is the first optimization and there are many more that can be done now, but now the kernel is split into two so that each of the Layernorm forwards can be modified independently now for future...
- Fix the compiler warnings and errors by lancerts · Pull Request #561 · karpathy/llm.c: Fix such error that happens for CUDA 11.8 per discussion #558 (comment) matmul_backward_bias.cu(151): error: no operator "+=" matches these operands operand types are: floatX += ...
- Use faster kernel for LayerNorm forward · karpathy/llm.c@7d7084a: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- adding wsd schedule with (1-sqrt) decay by eliebak · Pull Request #508 · karpathy/llm.c: Adding new learning rate schedule support: WSD learning rate schedule: Warmup: classical linear warmup Stable: constant lr Decay: Decaying to min_lr in a (1-sqrt) shape. (more info here https://ar...
- Fix stochastic rounding by gordicaleksa · Pull Request #597 · karpathy/llm.c: Previously our stochastic rounding logic didn't have a unique seed for each of the parameters we're rounding. This PR fixes that. In more detail, previously: we were passing the same seed for...
- Neuron Rounding Modes — AWS Neuron Documentation: no description found
- Replaced hard-coded max float with FLT_MAX by vyom1611 · Pull Request #583 · karpathy/llm.c: Just fixed some TODOs and replaced hard-coded values with FLT_MAX for floating point integers which comes with already included <float.h> headers in both files.
- Dataloader - introducing randomness by gordicaleksa · Pull Request #573 · karpathy/llm.c: On the way to fully random train data shuffling... This PR does the following: Each process has a different unique random seed Each process train data loader independently chooses its starting sha...
- Check determinism in CI by ngc92 · Pull Request #603 · karpathy/llm.c: Extends the test script to validate determinism. Some thoughts: With C memory management, it is quite easy to introduce memory leaks, e.g., loading from checkpoint twice without freeing in the mid...
- mdouglas/llmc-gpt2-774M-150B · Hugging Face: no description found
- GPT-2 (774M) reproduced · karpathy/llm.c · Discussion #580: I left the GPT-2 774M model running for ~6 days on my 8X A100 80GB node (150B tokens, 1.5 epochs over the 100B FineWeb sample dataset) and training just finished a few hours ago and went well with ...
- Add master weights to resume state by gordicaleksa · Pull Request #522 · karpathy/llm.c: We're currently not saving master weights as part of the state -> we lose some precision because otherwise when we resume we'll have to reconstruct the master weights by upcasti...
- only save missing bits to reconstruct fp32 master weights by ngc92 · Pull Request #432 · karpathy/llm.c: I think I managed to get the bit-fiddling right, and this will effectively give us fp31 master parameters at the cost of only 16 additional bits (instead of the current 32). Before merging, the cod...
- Use faster kernel for LayerNorm forward by gordicaleksa · Pull Request #600 · karpathy/llm.c: I ran kernel 5 under /dev/cuda/ (./layernorm_forward 5) on both RTX 3090 and H100 systems and it's faster on both of them. Numbers: kernel 3, optimal block size on: RTX 3090 → 32 (689.11 GB/s...
- Utilities for cuda streams + disk IO by ngc92 · Pull Request #556 · karpathy/llm.c: handling disk io for checkpointing with cuda streams is a nontrivial task. If you're not careful, you can easily get broken code (need to wait for data to be on the CPU before you can start writi...
- Zero 2 - WIP by ngc92 · Pull Request #593 · karpathy/llm.c: Trying to get a first version working. Code isn't nice, we currently lose the asynchrony in the communication code because we need to reuse the buffer for the next layer, and it doesn'...
- Permuted DataLoader by karpathy · Pull Request #599 · karpathy/llm.c: Permuted dataloader, and some first tests. WIP still.
- Add master weights to resume state by gordicaleksa · Pull Request #522 · karpathy/llm.c: We're currently not saving master weights as part of the state -> we lose some precision because otherwise when we resume we'll have to reconstruct the master weights by upcasting from lowe...
CUDA MODE ▷ #oneapi (2 messages):
- Dynamic batching support struggles with Gaudi: A member mentioned the difficulties in getting dynamic batching with vLLM ported to Gaudi. They questioned if there is an architecture limitation preventing the implementation of KV cache flash attention kernels, contrasting it with regular "rectangular" shapes that are processed without issue.
- Channel rename suggestion to Intel: Another suggestion was to rename the channel to Intel, tagging a user for their input. This reflects a possible channel rebranding direction.
CUDA MODE ▷ #bitnet (49 messages🔥):
- Meeting Troubleshooting and New Link Shares: Users were discussing voice chat issues and shared several resources like Python development environments with Nix. "New laptop and having some problems with ubuntu," one mentioned while testing their setup.
- Benchmarking and Quantization Debates: Much of the conversation centered around benchmarking matrix multiplication with different precisions and quantization techniques. One user inquired, "Are you benchmarking matmul(x_fp16, W_nbit) or do you include scaling / zeros with grouping?" while others responded with their specific benchmarking approaches and the importance of grouping for better quality.
- Resource Links for Further Reading: Several useful links were shared including a quantization technique and a library supporting mixed-precision matrix multiplications. These resources aimed to facilitate a clearer understanding of optimization strategies.
- VRAM Constraints and GPU Considerations: Discussions also included the limitations of running larger models like llama2 locally due to VRAM constraints. One user mentioned using an XPS15 laptop with a GeForce GTX 1650 and explored alternative platforms like Lightning AI’s L4 with 22 free hours for testing.
- New Git Pull Requests and Test Case Pushes: Updates on the development side were shared, including pushing new test cases for BitnetTensor and UInt2Tensor. Users interacted around issues and updates, as seen in the comment, "pushed test cases for BitnetTensor, UInt2Tensor and bitpacking gen," providing collaborative development progress.
- BitBLAS/docs/PythonAPI.md at main · microsoft/BitBLAS: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment. - microsoft/BitBLAS
- Tensor Core Layout docs is not clear · Issue #386 · pytorch/ao: Right now what we have is docstrings but they could use work - this came up as @vayuda was looking at extending his bitpacking work to include a notion of scales What does tensor core layout mean? ...
- hqq/hqq/core/quantize.py at master · mobiusml/hqq: Official implementation of Half-Quadratic Quantization (HQQ) - mobiusml/hqq
- Python - NixOS Wiki: no description found
- [WIP] Added first bits of Uint2Tensor and BitnetTensor by andreaskoepf · Pull Request #282 · pytorch/ao: Created a UInt2Tensor class (similar to the UInt4Tensor class). Added a BitnetTensor class and a first unit test which quantizes the weights of a nn.Linear() layer and executes the matmul. Currentl...
LM Studio ▷ #💬-general (204 messages🔥🔥):
- Link Your Code Projects with 'lms' Tool: With the release of LM Studio 0.2.22, users can now utilize 'lms' for managing models and debugging prompts. The tool helps with loading/unloading models, and inspecting raw LLM input, streamlining local AI deployments (GitHub repository).
- Intel ARC A770 GPU Now Supported: There were several inquiries about Intel ARC A770 GPU support. Instructions were provided to enable OpenCL for Intel GPUs, emphasizing manual adjustments for GPU layers.
- Performance Comparison and GPU Utilization: Members discussed performance comparisons, revealing mixed results with CPU vs. GPU, and specific configuration needs for optimal model performance. Issues with the Deepseek Coder V2 Lite GGUF models were addressed, highlighting the necessity to toggle Flash Attention settings.
- Local Model Hosting Issues with Open Interpreter: Users encountered issues hosting local models for Open Interpreter via LM Studio. Recommendations included checking the detailed guide on Open Interpreter's documentation.
- Font Size Adjustments in LM Studio: A repeated request was to improve font size controls in LM Studio. Although there are keyboard shortcuts for zooming in/out, a more permanent and versatile solution within the app was suggested.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- Introducing `lms` - LM Studio's companion cli tool | LM Studio: Today, alongside LM Studio 0.2.22, we're releasing the first version of lms — LM Studio's companion cli tool.
- no title found: no description found
- Qwen/Qwen2-7B-Instruct-GGUF · Hugging Face: no description found
- MaziyarPanahi/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face: no description found
- configs/Extension-Pack-Instructions.md at main · lmstudio-ai/configs: LM Studio JSON configuration file format and a collection of example config files. - lmstudio-ai/configs
- Reddit - Dive into anything: no description found
- Hugging Face – The AI community building the future.: no description found
- Bug: Deepseek Coder MOE GGML_ASSERT: ggml.c:5705: ggml_nelements(a) == ne0*ne1 · Issue #7979 · ggerganov/llama.cpp: What happened? When trying to run one of the new Deepseek Coder conversions or quantizations I see this error: GGML_ASSERT: ggml.c:5705: ggml_nelements(a) == ne0*ne1 Happens when on pure CPU My F32...
LM Studio ▷ #🤖-models-discussion-chat (137 messages🔥🔥):
- Qwen2 and the search mishap: A user initially struggled to get coherent outputs from Qwen2 instruct, solved it using the "blank" preset, and another member advised on searching within the Discord for help rather than external sites.
- Roleplaying model recommendation: When asked for the best model for roleplaying, a member suggested Fimbulvetr-11B, describing it as effective for their needs.
- Finding coding models amid confusion: There was a discussion about the best models for coding, emphasizing the rapidly changing landscape and the difficulty of making reliable recommendations. Users mentioned preferring Codestral and exploring Large and Small Language Models list for detailed searches.
- New "Ultra-Quality" model releases: Members highlighted the release of new high-performance models like Psyonic-Cetacean-Ultra-Quality-20b-GGUF-imat-plus2 and discussed their testing results and quantitative improvements.
- Discussion on DeepSeek-Coder-V2: A member noted the release of DeepSeek-Coder-V2, capturing the excitement around its coding capabilities and discussing VRAM requirements and flash attention settings for optimal performance.
- DavidAU/Psyonic-Cetacean-Ultra-Quality-20b-GGUF-imat-plus2 · Hugging Face: no description found
- DavidAU/PsyCET-Decision-Time-Imatrix · Hugging Face: no description found
- deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct · Hugging Face: no description found
- mradermacher/Oumuamua-7b-instruct-v2-i1-GGUF · Hugging Face: no description found
- nitky/Oumuamua-7b-instruct-v2 · Hugging Face: no description found
- All Large Language Models: A Curated List of the Large and Small Language Models (Open-Source LLMs and SLMs). All Large Language Models with Dynamic Sorting and Filtering.
- Tweet from うみゆき@AI研究 (@umiyuki_ai): Oumuamua-7b-instruct-v2、Shaberi3ベンチマークで平均点7.25です。GPT3.5T(7.16)やQwen2-7B(7.23)を超えてます。メッチャ強い
- RichardErkhov/ArthurZ_-_mamba-2.8b-gguf · Hugging Face: no description found
- How do quantization formats affect model output?: How do quantization formats affect model output? Introduction Test method The box question Prompt Results Thoughts Shopping and haircut Prompt Results Thoughts Health education Prompt Results Thoughts...
- Reddit - Dive into anything: no description found
LM Studio ▷ #🧠-feedback (13 messages🔥):
- How to handle AVX2 instruction issue: A member faced issues after updating LM Studio and found that reinstalling the beta version from here resolved the problem. They warn, "do not update" afterwards to avoid recurring issues.
- Qwen2 outputting eot_id token problem: Users reported LM Studio outputting the eot_id token for Qwen2 instead of stopping generation, similar to issues with Llama3. Suggestions included checking the preset used and whether flash was enabled.
- Suggestion for GPU off-loading: A user proposed an enhancement to allow off-loading models to GPU before they fully load into RAM. This would benefit machines with more VRAM than RAM, particularly GPU servers, ensuring faster and more efficient model loading.
- Stop token handling in LM Studio: Concerns were raised about LM Studio allowing stop tokens to appear in the output and not stopping generation, leading to extensive token generation. One user emphasized the need for LM Studio to honor all listed stop tokens and treat this as a release-blocking bug.
- User interface feedback: The LM Studio interface received positive feedback for being "cool, soft, intuitive, and fast." Another user suggested adding VRAM usage statistics for better performance monitoring.
Link mentioned: LM Studio Beta Releases: no description found
LM Studio ▷ #📝-prompts-discussion-chat (8 messages🔥):
- Wrestling with Error Detection: A member expressed frustration over their model's inability to detect its errors and suggested it should output "#ERROR" when it cannot self-correct. Despite clear instructions, the model keeps requesting guidance rather than failing gracefully.
- Struggling with Text Appendages: Another member sought advice on preventing a model from adding irrelevant text at the end of responses. They specified using the bartowski/aya-23-8B-GGUF/aya-23-8B-Q8_0.gguf model and received a suggestion to try the Cohere Command R preset.
LM Studio ▷ #⚙-configs-discussion (3 messages):
- Mikupad User Faces Config Issues: A user sought help for using Mikupad as a webUI to interact with LMS, reporting an error message for an unexpected endpoint or method. They noted, "Mikupad have same config as LMS."
- Codestral RAG Preset Advice Needed: A member downloaded Codestral RAG and requested advice on creating a preset oriented towards RAG (retrieval-augmented generation). They mentioned reading relevant information on Hugging Face but remained unsure about the preset creation process.
LM Studio ▷ #🎛-hardware-discussion (34 messages🔥):
- Archiving LM Studio 0.2.23 Setup: A member shared a MirrorCreator link to the archived LM Studio 0.2.23 setup file, noting that the installers are digitally signed and can be verified for integrity.
- Adding a Second RTX 3090: A member asked if adding a different brand RTX 3090 would cause issues and whether to retain an RTX 2070 in the same system. Advice given suggested that for best results, get the exact same card and an SLI bridge; keeping the 2070 would slow down performance.
- Setting CPU Cores in Server Mode: A query was raised regarding the ability to set the number of CPU cores for processing in Server Mode, noting that only four cores were being utilized despite the model being loaded in RAM.
- AMD Ryzen RX 7700S GPU Detection Issues: A member faced issues with LM Studio not detecting an AMD Ryzen RX 7700S GPU on a Windows laptop. The discussion sought troubleshooting steps and clarified specifics about the GPU and OS.
- Mixing RAM Sticks Concerns: The conversation involved the viability of mixing different RAM sticks with the same speed but potentially different timings for CPU-only inference tasks. The conclusion was that it should work but to confirm compatibility using memtest.
Link mentioned: LM-Studio-0.2.23-Setup.exe - Mirrored.to - Mirrorcreator - Upload files to multiple hosts: no description found
LM Studio ▷ #🧪-beta-releases-chat (22 messages🔥):
- Smaug-3 Tokenizer Issue Resolved: The latest build resolves the previously noted smaug-3 tokenizer issue. This update was quickly acknowledged and appreciated by other members.
- Decoupling ROCm from Main App: A user commended the move to decouple ROCm from the main app, highlighting the successful upgrade and smooth operation on a 7900xtx. They shared their positive experience: "working just fine for me after upgrading".
- Command R+ GPU Offloading Glitch: Users debated an issue where Command R+ outputs gibberish when fully offloaded to the GPU, while the same model functions correctly on the CPU. One user mentioned, "Something screwy there. My context is only 4k", indicating it might not be a memory issue.
- Older Version Availability: Members discussed the difficulty of accessing older versions of the app, noting that changing version numbers in the URL to access older versions no longer works. Suggestions included personally keeping copies of older versions before updating, although this was flagged as impractical post-update.
LM Studio ▷ #autogen (1 messages):
- Environment recreation resolves API key issue: A user described an issue receiving an "incorrect API key" error that persisted until they recreated their environment and reinstalled dependencies. Setting the API key using
$env:OPENAI_API_KEYresolved their problem. - Assistant sends blank messages, causing errors: Although the user successfully set the default message and configured a model for user proxy and chat managers, the assistant sends blank messages, which results in errors in LM Studio. They are seeking further solutions to this issue.
LM Studio ▷ #open-interpreter (13 messages🔥):
- Interpreter defaults to GPT-4 despite LM Studio running: A user faced an issue where attempting to run interpreter --local with a running LM Studio server resulted in a prompt for a provider, and then defaulted to GPT-4 even after setting LM Studio as the provider.
- YouTube tutorial link shared: Another user suggested following this YouTube tutorial to potentially resolve the issue with the Open Interpreter setup.
- Need to see full server page screenshot: It was advised to have the server running with a model selected and to share a screenshot of the entire LMStudio server page to diagnose the problem.
- MacOS vs Linux inquiry: The troubleshooting user mentioned the steps they took on MacOS, prompting an inquiry about whether the original issue occurred on Linux.
- Simple setup steps shared: A user provided clear steps to set up the interpreter on their machine, which seemed to work fine on MacOS.
Link mentioned: ChatGPT "Code Interpreter" But 100% Open-Source (Open Interpreter Tutorial): This is my second video about Open Interpreter, with many new features and much more stability, the new Open Interpreter is amazing. Update: Mixtral 7x8b was...
LM Studio ▷ #model-announcements (1 messages):
- DeepSeek releases ultra-fast coding models: DeepSeek's new Coding models are now available, featuring their V2 MoE with 16B total parameters and only 2.4B activated for each request. This model requires flash attention disabled for proper functioning; download it here.
- DeepSeek's community contributions highlighted: The DeepSeek-Coder-V2-Lite-Instruct is part of the LM Studio Community models highlights program, which emphasizes new and notable models. The GGUF quantization was provided by bartowski based on the latest
llama.cpprelease.
Link mentioned: lmstudio-community/DeepSeek-Coder-V2-Lite-Instruct-GGUF · Hugging Face: no description found
LM Studio ▷ #🛠-dev-chat (27 messages🔥):
- VSCode code scripts and model suggestions integration: A member shared their "dream workflow" for integrating VSCode with various models, using tools like CodeParrot and OpenAI's Playground to generate script files and
continue.devfor code modification and explanation. They expressed challenges in iterating code versions and requested help setting upcontinue.dev.
- Recommendations for model selection and config in
continue.dev: Another member recommended using models likellama3ordeepseek-coderfor chat and provided a configuration file example forcontinue.dev. They pointed to issues related to unsupported GPU (6600XT) needing OpenCL instead of ROCM.
- GPU setup issues: A member faced problems setting up GPU acceleration with ROCM and then OpenCL, leading to repeated errors about GPU survey failures. It was suggested they might be missing drivers and to seek detailed help in a specific channel.
- Configuring
continue.devwith LM Studio: Discussions highlighted the complexities of setting up multiple servers with LM Studio for different models, and using theapiBaseproperty incontinue.dev's config. A link to setup instructions specifically for LM Studio was shared.
- Call for API usage of LM Studio: A member asked about using LM Studio via API through ngrok, but it was clarified that LM Studio must be installed and run locally to use its services.
- Select models | Continue: Configure LLMs
- Tab Autocomplete (beta) | Continue: Continue now provides support for tab autocomplete in VS Code and JetBrains IDEs. We will be greatly improving the experience over the next few releases, and it is always helpful to hear feedback. If ...
- Example configurations | Continue: If you're looking for a quick way to create the perfect Continue setup, we've written a few sample config.jsons for common situations. You can copy these and paste them into your config.json...
- LM Studio | Continue: LM Studio is an application for Mac, Windows, and Linux that makes it easy to locally run open-source models and comes with a great UI. To get started with LM Studio, download from the website, use th...
HuggingFace ▷ #general (372 messages🔥🔥):
- Homemade AIs for Low-Resource Devices: Users discussed self-hosted AI alternatives to GPT-4 that don't require powerful servers. "Maybe llama3 (70B-7B), mixtral 8x7B, or command r+" were suggested.
- FlowGPT's NSFW Content: FlowGPT is under scrutiny for potentially allowing NSFW content, which OpenAI prohibits. One user argued that while NSFW bots are common, it's important to clarify moral vs. legal concerns.
- Efficient Fine-Tuning and Evaluation: Viliamvolosv shared his QLoRa settings for improving Russian language models on classic literature, seeking advice on optimal parameters. Fulx69 highlighted the importance of experimenting with r and alpha values and suggested tools for evaluation like LLaMA-Factory.
- New AI Models and Tools: DeepSeek-Coder-V2 is claimed to surpass GPT-4-Turbo in coding and math, with users recommending using LiveCodeBench for unbiased evaluation. Its on @deepseek_ai.
- Joined and Welcomed: New users like 9do4n1 and open.group joined, with others welcoming them and clarifying server rules and culture. "Welcome 🤗" messages emphasized the supportive community environment.
- Phi-3-mini-128k-instruct - a Hugging Face Space by eswardivi: no description found
- OpenGPT 4o - a Hugging Face Space by KingNish: no description found
- InternVL - a Hugging Face Space by OpenGVLab: no description found
- Omost - a Hugging Face Space by lllyasviel: no description found
- lllyasviel (Lvmin Zhang): no description found
- MENACE: the pile of matchboxes which can learn: See more data and check out what we changed on the second day (which caused MENACE to learn a different strategy) in the second video: https://youtu.be/KcmjO...
- trl/examples/notebooks/gpt2-sentiment.ipynb at main · huggingface/trl: Train transformer language models with reinforcement learning. - huggingface/trl
- Train a Shitty Tic-Tac-Toe AI: no description found
- ShogAI | Explore Open Source & Decentralized AI: no description found
- Protect your AI applications in real time — Robust Intelligence: Protect generative AI applications against attacks and undesired responses. Robust Intelligence guardrails protect against security and safety threats.
- numpy: Fundamental package for array computing in Python
- Tweet from DeepSeek (@deepseek_ai): DeepSeek-Coder-V2: First Open Source Model Beats GPT4-Turbo in Coding and Math > Excels in coding and math, beating GPT4-Turbo, Claude3-Opus, Gemini-1.5Pro, Codestral. > Supports 338 programmin...
- Dead Pixels Dpgc GIF - Dead Pixels Dpgc - Discover & Share GIFs: Click to view the GIF
- Guy Arguing GIF - Guy Arguing Guy Talking To Wall - Discover & Share GIFs: Click to view the GIF
- Michael Jackson Eating Popcorn GIF - Michael Jackson Eating Popcorn Enjoy - Discover & Share GIFs: Click to view the GIF
- microsoft/Phi-3-vision-128k-instruct · Hugging Face: no description found
- THUDM/cogvlm2-llama3-chat-19B-int4 · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- GitHub - Zz-ww/SadTalker-Video-Lip-Sync: 本项目基于SadTalkers实现视频唇形合成的Wav2lip。通过以视频文件方式进行语音驱动生成唇形,设置面部区域可配置的增强方式进行合成唇形(人脸)区域画面增强,提高生成唇形的清晰度。使用DAIN 插帧的DL算法对生成视频进行补帧,补充帧间合成唇形的动作过渡,使合成的唇形更为流畅、真实以及自然。: 本项目基于SadTalkers实现视频唇形合成的Wav2lip。通过以视频文件方式进行语音驱动生成唇形,设置面部区域可配置的增强方式进行合成唇形(人脸)区域画面增强,提高生成唇形的清晰度。使用DAIN 插帧的DL算法对生成视频进行补帧,补充帧间合成唇形的动作过渡,使合成的唇形更为流畅、真实以及自然。 - Zz-ww/SadTalker-Video-Lip-Sync
- SAMPLE LESSON: Matchboxes Play Tic-Tac-Toe: This is an example of a lesson from my AWS Machine Learning course.See the full course here: https://learn.mikegchambers.com/p/aws-machine-learning-specialty...
- GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs: Unify Efficient Fine-Tuning of 100+ LLMs. Contribute to hiyouga/LLaMA-Factory development by creating an account on GitHub.
- LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code : no description found
- Papers with Code - TextGrad: Automatic "Differentiation" via Text: 🏆 SOTA for on GPQA (Accuracy metric)
- Rebrandly Dashboard: no description found
- Settings for qlora: Settings for qlora. GitHub Gist: instantly share code, notes, and snippets.
HuggingFace ▷ #today-im-learning (5 messages):
- Seeking a Model for Business Use: A member inquired about the best model for general-purpose support and business use. They specified that the largest model they can deploy is 7B.
- Experimentation Recommended: In response, another member suggested that the choice of the model will depend on the specific use case, whether tools/agents are being used, and the deployment/affordability constraints.
- Game Screenshot Project with GPT-4 API: A member shared their experience of using the GPT-4 API to crop and caption over 150 screenshots from the game Mirror's Edge: Catalyst and creating a LoRA for Stable Diffusion from those images.
HuggingFace ▷ #cool-finds (10 messages🔥):
- RNNs vs RWKV-TS in Time Series Forecasting: A member shared an arXiv paper discussing the declining dominance of traditional RNN architectures in time series tasks. The paper introduces RWKV-TS, a novel RNN-based model, which claims better efficiency, long-term sequence information capture, and computational scalability.
- Advanced Prompt Option Impact on Production Time: A member reported that disabling the advanced prompt option significantly reduces the production time during peak periods, improving fidelity and maintaining scene stability.
- Web Scraping and RAG to Enhance LLMs: A Medium article was shared, explaining how integrating web scraping with retrieval-augmented generation (RAG) can power up large language models (LLMs). Techniques referenced aim to enhance data collection and prompt accuracy.
- Labor Market Impact of LLMs: A member shared a study examining the labor market impact potential of LLMs, revealing that large portions of the U.S. workforce could see significant changes in their job tasks due to LLMs. The investigation suggests both low and high-wage workers may experience shifts in their work responsibilities.
- Reducing AI Hallucinations through RAG: An article from Wired on reducing AI hallucinations using retrieval-augmented generation (RAG) was discussed. The approach involves a model gathering information from a custom database before generating responses, enhancing reliability and accuracy.
- Reduce AI Hallucinations With This Neat Software Trick: A buzzy process called retrieval augmented generation, or RAG, is taking hold in Silicon Valley and improving the outputs from large language models. How does it work?
- Dull Men's Club | Hi, I'm a mathematician who likes to think about things that would be useful if implemented but stand 0 chance of ever being implemented | Facebook: Hi, I'm a mathematician who likes to think about things that would be useful if implemented but stand 0 chance of ever being implemented. For example, I often think we could improve the calendar...
- RWKV-TS: Beyond Traditional Recurrent Neural Network for Time Series Tasks: Traditional Recurrent Neural Network (RNN) architectures, such as LSTM and GRU, have historically held prominence in time series tasks. However, they have recently seen a decline in their dominant pos...
- GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models: We investigate the potential implications of large language models (LLMs), such as Generative Pre-trained Transformers (GPTs), on the U.S. labor market, focusing on the increased capabilities arising ...
HuggingFace ▷ #i-made-this (18 messages🔥):
- Introducing Difoosion - A Web Interface for Stable Diffusion: A member showcased their Web-Interface for Stable Diffusion leveraging the
diffuserslibrary and a Pure-Python web framework, Rio. They invited the community to check it out on GitLab.
- Ask Steve - LLMs Integration into Chrome: A member developed a Chrome extension that integrates LLMs directly into the browser, akin to GitHub Copilot but for web navigation. They introduced the tool as a way to eliminate repetitive tasks and promoted the project at Ask Steve.
- Ilaria RVC for Voice Conversion: A member announced the creation of Ilaria RVC, a voice conversion space running on Zero, and thanked another user for their help. They shared the project on Hugging Face Spaces.
- Demonstrating Transformers.js with LLM Temperature Parameter: A blog post was shared about the temperature parameter in LLMs, featuring an interactive demo via Transformers.js running directly in the browser. The author highlighted how this approach could revolutionize educational content by eliminating the need for hosting models, shared on Twitter.
- PowershAI - Combining PowerShell with AI: A member introduced PowershAI, a PowerShell module allowing Function Calling with AI integration, which they developed while studying the OpenAI API. They shared their progress on GitHub and detailed their journey in a blog post.
- Ilaria RVC - a Hugging Face Space by TheStinger: no description found
- SD3 Reality Mix (Finetune) - a Hugging Face Space by ptx0: no description found
- Autonomous agents with layer-2 blockchain transaction capabilities: This video walks you through turning a GPT into an agent that can make layer-2 nano-payments.To discover more:Dhali - https://dhali.io
- Ask Steve - Unlock the Power of ChatGPT and Gemini in any web page!: Ask Steve adds AI superpowers from ChatGPT & Gemini to any web page, so you can get your everyday tasks done better and faster. FREE!
- Tweet from Taha Yassine (@taha_yssne): I just wrote a blog post about the temperature parameter in LLMs, but really it was just an excuse to play with Transformers.js. I had fun implementing an interactive demo of the impact of T on genera...
- Jakob Pinterits / Difoosion · GitLab: A simple web interface for Stable Diffusion - Including the new Stable Diffusion 3
- GitHub - rrg92/powershai: IA com PowerShell: IA com PowerShell. Contribute to rrg92/powershai development by creating an account on GitHub.
- PowershAI: PowerShell + Inteligência Artificial – IA Talking 🤖 : no description found
HuggingFace ▷ #reading-group (16 messages🔥):
- QKV in ViT challenged and experiments planned: A user questioned the correctness of the QKV implementation in ViTs, describing it as "wrong" and promising to conduct experiments to provide insights. More on this in the coming days.
- HyperZZW vs Self-Attention: A member shared a critique of the self-attention mechanism in ViTs, proposing the HyperZZW operator as a simpler and more reasonable alternative. They linked a detailed post on X (Twitter), suggesting that it deals better with spatial information.
- Global HyperZZW and tokenization issues: The same user argued that converting images into tokens in ViTs is fundamentally flawed and that the Global HyperZZW branch can manage global position info more efficiently with a matrix multiplication strategy.
- Different strategies for image and text data: They also stressed that images and text are fundamentally different, making ViT's implementation inappropriate for vision data, hinting at the use of prior information for future sequence modeling instead of attention mechanisms.
- Slow neural loss and local feedback error: Contributions like slow neural loss as local feedback error have been verified and mentioned as a potential key element for next-gen architectures, inspired by Hinton’s proposal. This was promoted with another Twitter link.
- Tweet from Harvie Zhang (@harvie_zhang): I propose a #HyperZZW operator with linear complexity to replace the #SelfAttention mechanism. The pixcel-level scores are obtained by Hadamard product between large implicit kernels and input activat...
- Tweet from Harvie Zhang (@harvie_zhang): Do you think there is any difference between your proposed loss and my slow neural loss? Please also refer to Eqn. 11-12 in https://arxiv.org/pdf/2401.17948. Quoting Francesco Faccio (@FaccioAI) ...
HuggingFace ▷ #computer-vision (4 messages):
- Inquiring about VASA models: A member asked if anyone has figured out the VASA-like open-source models. There's no indication of a follow-up or response in the provided messages.
- Interest in mobile CLIP: Another member queried if Hugging Face will implement the mobile CLIP model. There were no further discussions or responses to this question in the provided messages.
HuggingFace ▷ #NLP (5 messages):
- Fine-tuning BERT methods shared: A member suggested using the method outlined in this tutorial for fine-tuning BERT.
- Randomness issue in HF model loading: A user mentioned that loading HuggingFace models multiple times leads to different validation outputs, suggesting to save untrained model states for reproducibility. They noted, "don't rely on HF initialization to be deterministic... Save your untrained model state".
- Trouble with Mistral-7b-0.3 context handling: A new member is having issues with Mistral-7b-0.3 model not handling a context length properly, failing to answer questions beyond the first half of the context. They seek guidance on whether they misunderstood the model capabilities.
- New Open Source TTS model: A member shared a new TTS model, MARS5-TTS, inviting their team to a talk on the Mozilla AI Main stage. They requested the community to submit any questions they might have for the MARS5-TTS team.
- GitHub - Camb-ai/MARS5-TTS: MARS5 speech model (TTS) from CAMB.AI: MARS5 speech model (TTS) from CAMB.AI. Contribute to Camb-ai/MARS5-TTS development by creating an account on GitHub.
- Transformers-Tutorials/BERT/Fine_tuning_BERT_(and_friends)_for_multi_label_text_classification.ipynb at master · NielsRogge/Transformers-Tutorials: This repository contains demos I made with the Transformers library by HuggingFace. - NielsRogge/Transformers-Tutorials
HuggingFace ▷ #diffusion-discussions (5 messages):
- Struggles with meme generator model: A member sought advice on developing a high-quality meme generator model and asked for guidance from those with experience or interest in this domain. They emphasized the desire to produce high-quality memes and wondered about the initial steps.
- Rate limit errors hinder progress: One member reported rate limit exceeding errors and requested help to resolve this issue.
- Overflow error in Stable Diffusion XL: A detailed error involving SDXL loading was shared, showcasing an Overflow error: cannot fit 'int' into an index-sized integer. The provided code snippet and system information, including GPU: A100 and Torch: 2.3.1, were part of the context.
- Seeking examples for Diffusers with GCP's TPU: Another member requested an example or guidance on using Diffusers with GCP's TPU.
OpenAI ▷ #ai-discussions (184 messages🔥🔥):
- ChatGPT on iOS 18 remains uncertain: A member asked if ChatGPT works with iOS 18, and another noted not to install beta software, underscoring the importance of using a stable iOS version like iOS 17 for ChatGPT. They also mentioned that beta users sign NDAs about new features.
- Extracting transcripts from YouTube videos: Members discussed tools for extracting transcripts from YouTube videos, including AI tools like Otter.ai, and a specific tool that requires the YouTube API key via the
fabriclibrary. One member suggested using Google Gemini's trial for a consumer-friendly experience.
- Open source models beat GPT-4 in specific tasks: DeepSeek AI released an open-source model reportedly outperforming GPT-4 Turbo in specialized tasks like coding and math. This sparked discussions about open-source versus proprietary models.
- Connecting OpenAI models to databases: A member asked about integrating OpenAI's LLM with a continuously updating database, and another shared links to OpenAI's Cookbook with examples for vector databases, which are foundational for supporting semantic search and reducing hallucinations in responses.
- Dream Machine and Sora's AI capabilities: There was enthusiastic discussion about Luma's Dream Machine video capabilities, compared to the anticipated Sora, revealing some users' impatience with the limited release of Sora. Members noted its impressive but still evolving functionality, with unique features like incorporating consistent physical motion.
- Tweet from DeepSeek (@deepseek_ai): DeepSeek-Coder-V2: First Open Source Model Beats GPT4-Turbo in Coding and Math > Excels in coding and math, beating GPT4-Turbo, Claude3-Opus, Gemini-1.5Pro, Codestral. > Supports 338 programmin...
- Tweet from undefined: no description found
- Whisper JAX - a Hugging Face Space by sanchit-gandhi: no description found
- What is Copilot? - Microsoft Copilot: 你的日常 AI 助手: Microsoft Copilot 利用 AI 的强大功能来提高工作效率、释放创造力,并通过简单的聊天体验帮助你更好地理解信息。
- Potato Fries GIF - Potato Fries Poop - Discover & Share GIFs: Click to view the GIF
- RAG with a Graph database | OpenAI Cookbook: no description found
- Vector databases | OpenAI Cookbook: no description found
OpenAI ▷ #gpt-4-discussions (49 messages🔥):
- Custom GPTs privacy setting confusion: A member struggled with setting their Custom GPTs to private, mentioning that the most restricted option now is "invite only," but it was still showing as available to everyone. A workaround suggested is to create a copy and restrict it to people with the link, then delete the original.
- Funny idea for a GPT mod: A member suggested making a Fallout or Skyrim mod that changes all the game's dialogue to zoomer slang or any specified prompt, noting it would be amusing.
- Access issues with free-tier GPT interactions: Several members reported difficulties in accessing GPT interactions, with conversations requiring a paid subscription to continue. This seems to be affecting multiple users, with some confirming the same issue with their friends.
- Specifying actions for Custom GPTs: A user inquired about setting specific actions like web browsing in their custom GPT and was advised to prompt the GPT accordingly for when to use certain tools.
- GPT usage limits frustration: Another user expressed frustration over GPT not loading and servers being down, with others confirming similar issues. For real-time updates, users were directed to check status.openai.com.
OpenAI ▷ #prompt-engineering (28 messages🔥):
- 3D Models Struggle with No Shadows: Members discussed the challenges of creating 3D models with no shadows or lighting. One shared hope to create texture resembling an "albedo map" to aid in 3D conversions, while another suggested inpainting or using tools like Canva to minimize shadows.
- Extracting Information from GPT-4: A member faced issues with GPT-4 mixing sample and target emails during information extraction. Solutions included clearly separating samples with distinct markers and clarifying instructions.
- Generate Detailed Roadmaps with ChatGPT: To explore topics like marketing and branding in depth, members recommended strategies such as step-back prompting and using detailed queries. Shared tips included creating topic trees and using browser tools for specific research.
- Handling ChatGPT's Request Refusals: A user experienced consecutive refusals from ChatGPT to fulfill certain requests without clear reasons. Tips shared included repeating the prompt and asking for detailed explanations while requesting the fulfillment.
- Generating Tables from XML Data: A member inquired about prompts for extracting XML data into table form and generating specific token amounts with the GPT API. The community awaits further responses to this technical query.
OpenAI ▷ #api-discussions (28 messages🔥):
- Secrets to 3D Model Prompts: A member suggested finding 3 examples of a 3D model with no shadows or lighting, asking ChatGPT to notate their lack and then generating a new image. Another user noted that completely eliminating shadows seems impossible due to language limitations and rendering corrections by ChatGPT and Dall-E.
- Using Separate Samples for GPT-4: To prevent GPT-4 from mixing sample and target emails, members debated using distinct markers. Clear separation and specific instructions can prevent content amalgamation.
- Balancing Shadows in 3D Models: A detailed discussion on minimizing shadows and light on objects for better 3D model texture mapping ensued. The consensus was that the baked-in shading interferes with albedo map creation, recommending using the generated shape as a base model instead.
- Generating Marketing Roadmaps with ChatGPT: One user sought advanced insights on marketing topics like Brand Archetypes using ChatGPT. Members advised step-back prompting and specific roadmaps of subtopics; suggestions included using clear directives and external resources for deeper dives.
- ChatGPT Refusal Quirks: Several users reported that ChatGPT sometimes refuses requests without giving reasons. The proposed workaround involves asking ChatGPT to explain refusals, which may prompt it to fulfill the request.
LAION ▷ #general (250 messages🔥🔥):
- SD3 Models Struggle with Artifacts and Training: Members discussed the stability and training challenges with SD3 models, noting that loss stabilization remains complex. Explicit concerns were raised about non-uniform timestep sampling and the lack of critical components such as qk norm.
- Timestep Weighting in Training: Discussion highlighted different approaches to timestep weighting with V-prediction models. One user prefers uniform sampling while reweighting loss, segmenting schedules into smaller batches to distribute training effectively.
- Open-source T2I Models: Queries and recommendations about the best open T2I models with character consistency led to GitHub resources for controllable text-to-image generation. Theatergen for character management was also discussed as an option for consistent multi-turn image generation.
- ComfyUI and Adaptive ODE Solvers: A member shared a GitHub link for adaptive ODE solvers implemented for SD3, suggesting they offer better results than existing fixed-step solvers and could serve as a valuable reference or alternative for current diffusers.
- Fudan's Open-source Video Generative Model: Spirited discussion erupted around Fudan University's Hallo model for video generation from single images and audio, with another tool to run it locally shared on FXTwitter. Members expressed interest in integrating it with Text-to-Speech systems like Udio or Suno.
- Introducing Gen-3 Alpha: A New Frontier for Video Generation: Gen-3 Alpha is the first of the next generation of foundation models trained by Runway on a new infrastructure built for large-scale multimodal training. It is a major improvement in fidelity, consist...
- Tweet from Siyu ZHU (@JoeSiyuZhu): We (Fudan, Baidu, ETH Zurich) have open-sourced the superior-performing video generative model that make single image sing and talk from audio reference, and can adaptively control facial expression. ...
- CaptionEmporium (Caption Emporium): no description found
- A perceptual color space for image processing: A perceptual color space for image processing A perceptual color space is desirable when doing many kinds of image processing. It is useful...
- Tonton Friends Yuta GIF - Tonton Friends Yuta Chubby Shiba - Discover & Share GIFs: Click to view the GIF
- Im Doing My Part Serious GIF - Im Doing My Part Serious Stare - Discover & Share GIFs: Click to view the GIF
- Thats The Neat Part You Dont Invincible GIF - Thats The Neat Part You Dont Invincible - Discover & Share GIFs: Click to view the GIF
- GitHub - oppo-us-research/FA-VAE: Description: Frequency Augmented Variational Autoencoder for better Image Reconstruction: Description: Frequency Augmented Variational Autoencoder for better Image Reconstruction - oppo-us-research/FA-VAE
- Tweet from cocktail peanut (@cocktailpeanut): Kanye, singing "Dynamite" by BTS
- Tweet from cocktail peanut (@cocktailpeanut): Run High Quality Lipsync Locally, with 1 Click. [NVIDIA ONLY] The quality of lip syncing you get from Hallo is the best I've seen. So I wrote a gradio app AND a 1 click launcher for this. Enjoy!...
- GitHub - PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models: A collection of resources on controllable generation with text-to-image diffusion models.: A collection of resources on controllable generation with text-to-image diffusion models. - PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models
- GitHub - donahowe/Theatergen: TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation: TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation - donahowe/Theatergen
- Reddit - Dive into anything: no description found
- fofr/consistent-character – Run with an API on Replicate: no description found
LAION ▷ #research (34 messages🔥):
- Logical Reasoning Challenges with AIW Problems: Discussion highlighted the frequent use of names like "Alice" in logical reasoning problems, which may bias LLMs. A member shared that "Phi-2 performed horrible in general," showing "severe reasoning breakdown" in SOTA LLMs on the AIW problem described in this paper.
- Experiment Tactics to Address Bias: One member experimented by changing the problem setup to remove bias from known examples, noting that models like "GPT4o and Claude-Opus managed to solve it," while others failed. Failures were attributed to the LLMs’ misinterpretations like handling groupings incorrectly or hallucinating geometric associations.
- Reasoning Sensitivity in Models: Further analysis showed LLMs are "VERY SENSITIVE to even slight AIW problem variations," with Fig 11 from the referenced paper illustrating drastic fluctuations in correct response rates with slight changes, emphasizing the fragile state of their reasoning capabilities.
- Symbolic AI Hybrids for Deductive Reasoning: A query about research efforts combining LLMs with symbolic AI for improved deductive reasoning led to the recommendation of Logic-LM, which integrates LLMs with symbolic solvers to significantly boost logical problem-solving performance.
- JEPA for Building a Collective Vision in Email Assistants: Anu4938 shared ambitions of using JEPA to create an email assistant aimed at maximizing collective good and efficiently managing complexities. The envisioned assistant emphasizes values such as environmental respect, climate change action, and fostering global cooperation.
- Glyph-ByT5-v2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering: Recently, Glyph-ByT5 has achieved highly accurate visual text rendering performance in graphic design images. However, it still focuses solely on English and performs relatively poorly in terms of vis...
- Claude’s Character: Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
- Tweet from Jenia Jitsev 🏳️🌈 🇺🇦 (@JJitsev): Community was digging into our work https://arxiv.org/abs/2406.02061 that shows severe reasoning breakdown on the very simple AIW problem in SOTA LLMs. Following intense debates, to showcase further ...
- Logic-LM: Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning: Large Language Models (LLMs) have shown human-like reasoning abilities but still struggle with complex logical problems. This paper introduces a novel framework, Logic-LM, which integrates LLMs with s...
OpenAccess AI Collective (axolotl) ▷ #general (161 messages🔥🔥):
- Debate on Large Model Usability: A heated discussion took place on releasing and meme-ing about large models like the 200T parameter model, which are beyond most users' reach. One user humorously mentioned, "I am this close to making a 200T parameter model. Claim it is AGI."
- Qwen7B vs Llama3 8B: Members discussed the performance comparison between Qwen7B and Llama3 8B with one user mentioning that small LLMs like Qwen7B are unlikely to outperform Llama3 8B, emphasizing its current superiority in the field.
- Custom Llama3 Template Issue: There was a detailed technical exchange about training configurations and issues related to the
chat_templatesetting when training with Llama3 models. One user shared a link to fix custom Llama3 prompt strategies that resolved some issues.
- GPU and Optimization Feedback for PyTorch: A call for feedback from users using various GPUs to assist PyTorch optimizations saw diverse responses, including GPUs like AMD MI300X, RTX 3090, Google TPU v4, and 4090 with tinygrad.
- Shared Projects and Resources: Users shared several resources, including a blog post on CryptGPT: Privacy-Preserving LLMs, a language-specific GPT chat model DanskGPT, and GitHub links for setting up chat UI similar to HuggingChat using Huggingface's chat-ui project.
- turboderp/Cat-Llama-3-70B-instruct · Hugging Face: no description found
- Tweet from Diwank Singh (@diwanksingh): http://x.com/i/article/1802116084507848704
- Tweet from Philipp Schmid (@_philschmid): What a lucky day it is today. @nvidia release a strong 340B open LLM, which needs 8x H200 to run. And at the same day the first providers start hosting 8x H200. 🍀
- axolotl/src/axolotl/cli/train.py at 5783839c6e29bb148041338772040c85aaae4646 · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- GitHub - huggingface/chat-ui: Open source codebase powering the HuggingChat app: Open source codebase powering the HuggingChat app. Contribute to huggingface/chat-ui development by creating an account on GitHub.
- trl/trl/trainer/rloo_trainer.py at main · huggingface/trl: Train transformer language models with reinforcement learning. - huggingface/trl
- axolotl/src/axolotl/prompt_strategies/sharegpt.py at 5783839c6e29bb148041338772040c85aaae4646 · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- axolotl/src/axolotl/prompt_strategies/customllama3.py at dan_metharme · xzuyn/axolotl: Go ahead and axolotl questions. Contribute to xzuyn/axolotl development by creating an account on GitHub.
- GitHub - lm-sys/FastChat: An open platform for training, serving, and evaluating large language models. Release repo for Vicuna and Chatbot Arena.: An open platform for training, serving, and evaluating large language models. Release repo for Vicuna and Chatbot Arena. - lm-sys/FastChat
- DanskGPT: Dansk sprogteknologi tilgængelig for alle, helt gratis.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (4 messages):
- Llama3 Bug Halts Development: A user raised an issue on GitHub regarding a bug introduced on June 7 that prevents tuning Llama 3 or Mistral models. The bug is affecting several users, with 6 people confirming its impact, and while a workaround exists, they insist that the main branch needs fixing.
- Investigating the Bug Source: Another member asked if the issue might be related to setting
remove_unused_columnto false, but then concluded that the "length" keyword argument problem likely stems from a specific commit. The problematic commit was identified after abisect, confirming it as the source of the issue.
- Llama3-8b: LlamaForCausalLM.forward() got an unexpected keyword argument 'length' · Issue #1700 · OpenAccess-AI-Collective/axolotl: Please check that this issue hasn't been reported before. I searched previous Bug Reports didn't find any similar reports. Expected Behavior I expect the training run to finish and save the we...
- Jeopardy bot! by winglian · Pull Request #17 · OpenAccess-AI-Collective/axolotl: https://huggingface.co/openaccess-ai-collective/jeopardy-bot
OpenAccess AI Collective (axolotl) ▷ #general-help (9 messages🔥):
- Config confusion for dataset types: A user expressed confusion regarding the dataset type field in their
axolotlconfig, particularly foralpaca_chat.load_qa, referencing the dataset formats. Another user confirmed that the config format provided is correct.
- Running accelerate on SLURM clusters: A user shared a SLURM job script for running
axolotlwithaccelerateanddeepspeed, specifying mixed precision and multi-GPU settings. They advised replacing$PMI_RANKwith$SLURM_NODEIDif the former is unavailable.
- QDora issues in Axolotl: A user inquired about getting QDora to work with Axolotl, and another user replied that it hangs after a few steps, suggesting it's unreliable. Further details on building QDora from source were sought.
- Using axolotl for personality extraction: A user asked if anyone has used Axolotl to train models for extracting personalities from text and linked to Delphi AI for reference. They asked if the
oasstdataset format would be appropriate, linking to the documentation.
- Delphi: Clone Yourself.
- Axolotl - Instruction Tuning: no description found
- Axolotl - Instruction Tuning: no description found
- Axolotl - Config options: no description found
OpenAccess AI Collective (axolotl) ▷ #datasets (4 messages):
- Dataset Config Issues Resolved: A member requested a dataset config section due to encountering a
ValueErrorstating "unhandled prompt tokenization strategy: sharegpt." Another member shared a configuration link from Discord (link), which resolved the issue.
OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
- First Finetune with Axolotl Shines: "Had a blast finetuning my first LLMs with Axolotl!" The author reports successfully transitioning an unstructured press release into a structured output, hinting at further exploring OpenAI API’s function calling for improved accuracy.
- Exploring Press Release Data Extraction Efficiency: "We previously looked into how well LLMs could extract structured data from press releases." The initial evaluations revealed that while LLMs performed decently, there was noticeable room for improvement.
- Future Comparisons Promised: Emphasizing the use of function calling over raw prompting for better accuracy, a separate post on finetuning comparisons is hinted at. For more details, the author refers readers to a detailed post.
Link mentioned: Alex Strick van Linschoten - Finetuning my first LLM(s) for structured data extraction with axolotl: I finetuned my first LLM(s) for the task of extracting structured data from ISAF press releases. Initial tests suggest that it worked pretty well out of the box.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (11 messages🔥):
- Adjusting Inference Parameters in Axolotl: A user asked how to set inference parameters like temperature or seed while running
accelerate launch -m axolotl.cli.inference. It was suggested to modify the inference script directly or the configuration file if the command-line arguments for these settings aren't supported, showcasing an example of how to adjustgeneration_config.
- Request for Fine-Tuning Vision Models: A user inquired about fine-tuning vision models. It was explained that the process involves loading a pre-trained model (e.g., ResNet-50), preparing the dataset, modifying the final layers if necessary, defining data transforms, and then setting up a training loop with proper loss function and optimizer.
- no title found: no description found
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (11 messages🔥):
- Doubling context length in models needs careful adjustments: To train a model at 2x the native context length (e.g., 16k from 8k), users need to modify several settings related to model architecture, data processing, and training configuration. Key changes include adjusting maximum position embeddings and training parameters like batch size and gradient accumulation steps.
- Fine-tuning vision models with Axolotl explained: A step-by-step guide is provided for fine-tuning vision models using Axolotl. It involves cloning the Axolotl repository, installing dependencies, preparing the dataset, modifying the configuration file, and using Accelerate for training and inference.
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Perplexity AI ▷ #announcements (1 messages):
- Curiosity speaks every language; partners with SoftBank: Perplexity announced a strategic partnership with SoftBank to offer Perplexity Pro free for one year to customers using SoftBank, Y!mobile, and LINEMO services. This premium version of Perplexity, valued at 29,500 yen annually, provides users with a revolutionary AI answer engine for exploring and learning. More info.
Link mentioned: SoftBank Corp. Launches Strategic Partnership with Leading AI Startup Perplexity | About Us | SoftBank: SoftBank Corp.‘s corporate page provides information about “SoftBank Corp. Launches Strategic Partnership with Leading AI Startup Perplexity”.
Perplexity AI ▷ #general (187 messages🔥🔥):
- Agentic Search AB Testing Secrets: Community members discussed the new Agentic Pro Search being in A/B testing. One user shared a Reddit link on how to cheat the system but later reconsidered to avoid messing up the control group.
- Confusion Over Perplexity's Features and Model Settings: Users had various questions about using Perplexity, such as setting a system prompt, formatting answers, accessing writing modes, and experiencing issues like temperature changes or the chat freezing. They shared solutions like contacting support or clearing browser cache for bugs.
- Perplexity vs. ChatGPT and Investment Discussions: Members debated whether it was worth having both Perplexity and ChatGPT subscriptions concurrently and discussed the potential of investing in Perplexity. Comparisons focused on the strengths of each platform for specific use cases like writing and research.
- Concerns Over Web Crawling and Privacy: Some users raised concerns about Perplexity's crawling behavior not respecting
robots.txtand masking user agents. Suggestions for blocking or addressing this issue included using JA3 fingerprinting and bot endpoints. - Customizable Features and Document Handling: Members inquired and discussed uploading files, handling extensive document collections, and potential integrations with academic databases like academia.edu. Solutions included using other AI tools like custom GPTs on OpenAI and NotebookLM to manage large document loads.
Link mentioned: Reddit - Dive into anything: no description found
Perplexity AI ▷ #sharing (10 messages🔥):
- Tanstack Table Search Shared: A member shared a link to a Perplexity AI search related to Tanstack Table queries. This sparked interest in data table management tools.
- Pet Food in Russia Search: Another member provided a link to a search about pet food in Russia. Discussions likely revolved around the pet food market in Russia.
- Prostate Health Paper Public Issue: A user unintentionally made their prostate health paper public and sought help to fix it. Another member advised using the "Unpublish Page" button in the Pages menu.
- Elephant Communication Page: A contributor shared a link to a page discussing elephant communication. This might have led to conversations around animal behavior and communication methods.
- Elder Scrolls Page (duplicated): A couple of messages included links to a page about The Elder Scrolls. This probably indicates a shared interest in this gaming series among users.
Perplexity AI ▷ #pplx-api (3 messages):
- Ask-anything feature in Custom GPT struggles: A user successfully got their Custom GPT working but wants it to handle any prompts or queries. Another suggested explaining the problem to GPT-4o with a specific schema and error details to resolve issues with Action/Function Calling to the Perplexity API.
- Inquire for closed-beta access timeframe: A member asked about the expected response time for closed-beta access to the API. They mentioned their project at Kalshi is heavily dependent on accessing sources and is ready to launch pending this access.
Nous Research AI ▷ #off-topic (3 messages):
- Channel needs Autechre to hurt ears: One member suggested they need more Autechre in the channel and shared the YouTube video of "Autechre - Gantz Graf (Official Music Video) 1080p HD" to achieve this.
- Autechre to heal your soul: To balance the previous suggestion, the same member shared the YouTube video of "Autechre - Altibzz", describing it as a way to heal your soul.
- Autechre - Altibzz: The ambient opener to their new album "Quaristice." Music by Rob Brown and Sean Booth (c)/(p) 2007-8 Warp Records, Ltd.
- Autechre - Gantz Graf (Official Music Video) 1080p HD: Autechre - Gantz Graf (Official Music Video) HD
Nous Research AI ▷ #interesting-links (5 messages):
- Neurons play Doom in YouTube Video: Shared YouTube video titled "Growing Living Neurons to Play...Doom? | Part 2!" explores the concept of using living neurons to play the video game Doom. It's an intriguing intersection of biotech and gaming.
- Automated Bias and Indoctrination: Link to ResearchGate paper discusses the market-driven trajectory of AI and novel risks related to human bias and cognition at scale. The paper critiques "stochastic parrots" like LLMs as tools for manipulation aligned with corporate biases.
- Solving the Alignment Problem in mASI: A thought-provoking paper aims to highlight ethical implications and extreme liabilities in AI decision-making. It introduces the concept of "Ethical Center of Gravity" for balancing ethical deeds to mitigate dystopian risks.
- Efficient LLM Inference with vLLM: Blog post details about vLLM, an open-source inference engine using PagedAttention to improve memory usage and throughput. vLLM can run models with significantly fewer GPUs and boasts up to 24x higher throughput compared to HuggingFace Transformers.
- Stable Diffusion Subreddit Protests Reddit API Changes: The r/StableDiffusion subreddit reopens after protesting changes to Reddit's open API policy. The protest highlighted concerns about the impact on app developers, moderation, and accessibility for blind users.
- Growing Living Neurons to Play...Doom? | Part 2!: Use code thoughtemporium at the link below to get an exclusive 60% off anannual Incogni plan: https://incogni.com/thoughtemporium____________________________...
- Tweet from Moritz Wallawitsch 🗽 (@MoritzW42): An Introduction to vLLM and PagedAttention (originally published on @runpod_io's blog) 1/6 vLLM is an open-source LLM inference and serving engine (developed by @woosuk_k @KaichaoYou @zhuohan1...
- Reddit - Dive into anything: no description found
Nous Research AI ▷ #general (124 messages🔥🔥):
- Stable Diffusion 3 and Usage: Members noted that lying is allowed for anime, but only for non-human characters. Shared link to access Stable Diffusion 3.
- NVIDIA's Synthetic Data Model: Discussion about Nemotron-4-340B-Instruct, a large language model for synthetic data generation, optimized for English chat and supporting a 4,096 tokens context length. Available on Hugging Face and explored for its usage and competitive implications for NVIDIA's customer relations.
- Realtime Inference and ComfyUI: A member suggested using ComfyUI with TensorRT SD-Turbo for near real-time inference, especially fun when paired with a webcam feed for image manipulation.
- OpenAI's Shift to For-Profit: Sam Altman has informed shareholders that OpenAI might transition to a for-profit entity akin to rivals like Anthropic and xAI.
- Model Merging and MoE Debate: Extended discussion on the practicality and performance of Mixture of Experts (MoE) models and merging strategies, with hesitations about the efficacy of merging methods versus comprehensive fine-tuning. Links shared to relevant PR on llama.cpp and MoE models on Hugging Face.
- Introduction - SITUATIONAL AWARENESS: The Decade Ahead: Leopold Aschenbrenner, June 2024 You can see the future first in San Francisco. Over the past year, the talk of the town has shifted from $10 billion compute clusters to $100 billion clusters to trill...
- Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B: This paper introduces the MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS), designed to enhance performance in complex m...
- Stable Diffusion 3 Medium - a Hugging Face Space by stabilityai: no description found
- Is the Intelligence-Explosion Near? A Reality Check.: Learn more about neural networks and large language models on Brilliant! First 30 days are free and 20% off the annual premium subscription when you use our ...
- nvidia/Nemotron-4-340B-Instruct · Hugging Face: no description found
- Kquant03/CognitiveFusion-4x7B-bf16-MoE · Hugging Face: no description found
- Growing Living Neurons to Play...Doom? | Part 2!: Use code thoughtemporium at the link below to get an exclusive 60% off anannual Incogni plan: https://incogni.com/thoughtemporium____________________________...
- Tweet from Ryan Els (@RyanEls4): AI revealed 😲
- Godfather Massacre GIF - Godfather Massacre Sad - Discover & Share GIFs: Click to view the GIF
- Tweet from aaron holmes (@aaronpholmes): New: Sam Altman has told shareholders that OpenAI is considering becoming a for-profit company that would no longer be controlled by a nonprofit board https://www.theinformation.com/articles/openai-ce...
- Tweet from Alex Albert (@alexalbert__): Loved Golden Gate Claude? 🌉 We're opening limited access to an experimental Steering API—allowing you to steer a subset of Claude's internal features. Sign up here: https://forms.gle/T8fDp...
- BAAI/Infinity-Instruct · Datasets at Hugging Face: no description found
- Adding Support for Custom Qwen2moe Architectures with mergekit-qwen2 by DisOOM · Pull Request #6453 · ggerganov/llama.cpp: Statement: This has nothing to do with the fine-grained MoE architecture in Qwen/Qwen1.5-MoE-A2.7B. It is more akin to a traditional MoE, except that its experts are derived from the qwen2 (qwen1.5...
Nous Research AI ▷ #ask-about-llms (22 messages🔥):
- Setting Up Llama3 8B is Challenging: Plasmator asked for tips on training Llama3 8B for a specific style and deploying a fast OAI-compatible endpoint on M2 Ultra. Teknium recommended using unsloth qlora, Axolotl, and Llamafactory for training, and lmstudio or Ollama for endpoint deployment on a Mac.
- RAG Method Inquiry: Rbccapitalmarkets inquired if the set-based prompting technique from a recent paper could work with RAG (Retrieval-Augmented Generation). They shared a link to the paper for further context.
- PEFT Methods Discussion at CMU: 420gunna mentioned a CMU Advanced NLP course where the professor plugs his own paper about two new PEFT (Parameter Efficient Fine-Tuning) methods. They shared a YouTube link to the lecture for those interested.
- Nvidia’s Nemotron Model: Avinierdc asked about opinions on Nvidia's new Nemotron model, sparking a brief discussion. Teknium expressed a positive outlook and noted having tried it once on LMSYS chatbot arena.
- Equivalents to ComfyUI for LLMs: Csshsh sought a tool equivalent to ComfyUI for LLMs that allows playful interaction below the API layer. Orabazes suggested that a lot can be done with ComfyUI and recommended checking out the AnyNode custom node for running models locally.
- Set-Based Prompting: Provably Solving the Language Model Order Dependency Problem: The development of generative language models that can create long and coherent textual outputs via autoregression has lead to a proliferation of uses and a corresponding sweep of analyses as research...
- CMU Advanced NLP 2024 (8): Fine-tuning and Instruction Tuning: This lecture (by Graham Neubig) for CMU CS 11-711, Advanced NLP (Spring 2024) covers:* Multi-tasking* Fine-tuning and Instruction Tuning* Parameter Efficient...
Nous Research AI ▷ #world-sim (29 messages🔥):
- Feature for multiplayer collaboration considered: A member asked about the possibility of creating lobbies for collaborative creation with AI. Another member confirmed interest, stating, "Yes that's something we really like the idea of - any forms of multiplayer/pvp/co-op".
- Worldclient and WebSim are not connected: There was confusion regarding the connection between Opus on WebSim and WorldSim. It was clarified that "worldclient has no connection with websim".
- WorldSim AI experiences more censorship: A member noted, “the world-sim ai has been censored a bit”. Another explained that the increased censorship could be due to stricter measures by the model provider, Anthropic.
- Continuation feature for AI responses in development: Members discussed a bug where the AI's replies abruptly cut off. One highlighted an ongoing effort to fix this, “yeah, I have a feature in the works to allow continuation”.
- Claude 3's vision support and cost considerations: Members discussed integrating vision support in WorldSim, noting that Claude 3 already has this feature. They also debated the costs, with suggestions to use GPT4o for vision tasks and pass the information to Claude to optimize usage.
Modular (Mojo 🔥) ▷ #general (40 messages🔥):
- Mojo Manual on Functions Sparks Debate: A discussion arose around the Mojo manual's explanation of
defandfnfunctions, specifically whetherdeffunctions allow or require no type declarations. One participant proposed seven alternative phrasings to clarify the language, showing the nuances in English interpretation.
- Mojo Typing Mechanisms Critiqued: The conversation steered towards the permissiveness of type declarations in
deffunctions. The consensus was that whiledeffunctions do not enforce type declarations, they do allow them, contrasting withfnfunctions which require explicit type declarations.
- Mojo Community Event Announcement: An announcement for the Mojo Community Meeting was made, stating it would include talks by Helehex on constraints and Valentin on Lightbug, followed by a discussion on Python interop by Jack. A link to join the meeting was provided. Join the meeting
- Benchmark Comparison Shared: A user shared the results of a 1-thread benchmark test comparing Python FastAPI, Mojo Lightbug, and Rust Actix. The results showed Mojo Lightbug performed better than Python FastAPI but lagged behind Rust Actix.
- Concerns About Function Coloring Discussed: Following the community meeting, a discussion about the potential runtime costs of eliminating function coloring led to a conversation about stackful vs stackless coroutines. The debate highlighted the trade-offs between runtime cost and language complexity. Link to discussion on coroutines
- Functions | Modular Docs: Introduction to Mojo `fn` and `def` functions.
- What are the benefits of stackful vs. stackless coroutines?: Many languages that use async nowadays are implemented via stackless coroutines. That is, in a language like Python or Javascript, when you await an expression, that await returns to the caller,
- Inconsistent key detection bug · Issue #662 · go-vgo/robotgo: Robotgo version (or commit ref): Go version:1.17 Gcc version: Operating system and bit:windows10 64bit Provide example code: robotgo.EventHook(hook.KeyDown, []string{"command", "m"...
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
Modular (Mojo 🔥) ▷ #💬︱twitter (2 messages):
- Modular tweets new update: Modular shares a Tweet with their community, keeping followers updated on their latest activities and announcements.
- Another Modular announcement via Twitter: Modular posts another Tweet to keep the community informed about their continuous advancements and upcoming events.
Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- Mojo 24.4 Release Announced: Mojo has released version 24.4, boasting several significant core language and standard library enhancements. Readers are encouraged to read the full blog post here for detailed insights and code examples.
Link mentioned: Modular: What’s New in Mojo 24.4? Improved collections, new traits, os module features and core language enhancements: We are building a next-generation AI developer platform for the world. Check out our latest post: What’s New in Mojo 24.4? Improved collections, new traits, os module features and core language enhanc...
Modular (Mojo 🔥) ▷ #ai (2 messages):
- $1,000,000 Prize for True AGI Solution!: A user shared a YouTube video featuring Francois Chollet discussing why he believes LLMs won’t lead to AGI, along with a $1,000,000 ARC-AGI Prize for finding a true solution. Another user expressed skepticism, commenting that the prize amount felt like "lowballing."
Link mentioned: Francois Chollet - LLMs won’t lead to AGI - $1,000,000 Prize to find true solution: Here is my conversation with Francois Chollet and Mike Knoop on the $1 million ARC-AGI Prize they're launching today.I did a bunch of socratic grilling throu...
Modular (Mojo 🔥) ▷ #🔥mojo (107 messages🔥🔥):
- Defining 2D Numpy Arrays with Mojo: Users discussed the limitations of Mojo in passing nested lists to Python and shared workarounds using the
astmodule andPython.import_module. For example, one user suggested a functionndarraythat converts a string representation of a nested list to a Numpy array, which is then returned as a Python object. - Differences Between
DTypePointerandPointer[SomeDType]: Users highlighted thatDTypePointeris preferable for SIMD operations, as it allows for efficientsimd_loadinstructions. This was particularly helpful for a user who wanted to understand the performance implications of using each type. - VSCode Integration with Mojo: A member asked how to include directories in VSCode for Mojo, and another provided a way to do so via
settings.json. This helps VSCode analyze Mojo packages by adding"mojo.lsp.includeDirs": [ "/Users/your-name/your-mojo-files" ]. - Bug in Casting and Contextual Behavior: A user reported a bug when casting unsigned integers using
int()orUInt32(), experiencing different behavior between running the script and using the REPL. A GitHub issue was created to track this inconsistency. - CRC32 Table Calculation with Var vs. Alias: A detailed discussion revealed an issue when using
aliasinstead ofvarto initialize CRC32 tables, leading to different results due to casting behaviors. The minimal example showed that overflowing as if signed was occurring unexpectedly, prompting an investigation into the alias-specific behavior.
- mojo repl | Modular Docs: Launches the Mojo REPL.
- fnands.com/blog/2024/mojo-crc-calc/super_minimal_bug.mojo at main · fnands/fnands.com: My personal blog. Contribute to fnands/fnands.com development by creating an account on GitHub.
- [BUG]: Issue on creating numpy N-dimensional array · Issue #1139 · modularml/mojo: Bug description Can't create multi dimensional numpy array, creating single dimension numpy array works well. Steps to reproduce Include relevant code snippet or link to code that did not work as ...
- [BUG] Unsigned integer casting overflowing as if signed when using `int()` or `UInt32()` · Issue #3065 · modularml/mojo: Bug description Migrating this here after a bit of discussion in Discord. It seems like casting to unsigned integers actually just casts to signed integers, but has different behaviour in different...
- [BUG] Unsigned integer casting overflowing as if signed when using `int()` or `UInt32()` · Issue #3065 · modularml/mojo: Bug description Migrating this here after a bit of discussion in Discord. It seems like casting to unsigned integers actually just casts to signed integers, but has different behaviour in different...
- fnands.com/blog/2024/mojo-crc-calc/crc32_alias.mojo at main · fnands/fnands.com: My personal blog. Contribute to fnands/fnands.com development by creating an account on GitHub.
- fnands.com/blog/2024/mojo-crc-calc/minimal_bug.mojo at main · fnands/fnands.com: My personal blog. Contribute to fnands/fnands.com development by creating an account on GitHub.
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- fnands.com/blog/2024/mojo-crc-calc/crc.mojo at main · fnands/fnands.com: My personal blog. Contribute to fnands/fnands.com development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #🏎engine (3 messages):
- TPU usage clarified: A member explained that the only way to use TPUs is through calling XLA via the PjRT API. They provided a link to the PjRT API documentation and the TPU plugin libtpu.so.
- Call for native TPU support: Another member suggested writing native support for TPUs, similar to how Modular handles GPUs. The first member responded that there's no public API for TPUs that operates at a lower level than XLA.
Link mentioned: GitHub - openxla/xla: A machine learning compiler for GPUs, CPUs, and ML accelerators: A machine learning compiler for GPUs, CPUs, and ML accelerators - openxla/xla
Modular (Mojo 🔥) ▷ #nightly (9 messages🔥):
- New Nightly Mojo Compiler Released: A new nightly Mojo compiler version
2024.6.1505was released, and users can update withmodular update nightly/mojo. For more details, see the raw diff and the current changelog. - Compiler Version
2024.6.1605Released: Another nightly update to Mojo compiler, version2024.6.1605, has been released. Users should update and review changes through the raw diff and the changelog. - Latest Nightly Release
2024.6.1705: The most recent update to the nightly Mojo compiler is now available as version2024.6.1705. Update details can be reviewed via the raw diff and the current changelog. - Request for Builtin MLIR Dialects Documentation: A user inquired about the availability of external documentation for builtin MLIR dialects. Another member confirmed that no such documentation is currently available.
- Feature Request for REPL Improvements: A query was made regarding whether expressions could directly output values in the REPL similar to Python. The response suggested filing a feature request on GitHub for this enhancement.
Eleuther ▷ #announcements (1 messages):
- Interpretability team replicates OpenAI's findings: The EleutherAI interpretability team successfully replicated OpenAI's "weak-to-strong" generalization results using open-source LLMs. They observed these results across 21 NLP datasets and tried several modifications to improve generalization but found that "vanilla weak-to-strong training may already be close to eliciting everything the student 'knows'".
- Negative results for generalization improvements: The team experimented with various modifications such as strong-to-strong training, modified loss functions, and several probe-based experiments, with "generally negative results". Among these, only the log-confidence auxiliary loss showed potential signs of consistent improvement in generalization.
- Detailed findings published: The detailed findings and results of their investigations on weak-to-strong generalization in open-source models like Qwen1.5 0.5B and Llama 3 8B can be found in their latest blog post.
Link mentioned: Experiments in Weak-to-Strong Generalization: Writing up results from a recent project
Eleuther ▷ #general (51 messages🔥):
- AISI adds new roles and assistance for moving: AISI announced a variety of new job openings on their careers page and mentioned they could assist with visas for candidates open to relocating to the UK. This sparked interest among members not residing in the UK, considering the opportunity despite the location requirement.
- Discussion on CommonCrawl processing: Members exchanged tips for processing CommonCrawl snapshots, highlighting tools like ccget and resiliparse. Challenges included throttling and performance optimizations for handling large datasets efficiently.
- Interest in reproducible image generation models: Users discussed image generation models trained on publicly licensed data, specifically pointing to the CommonCanvas models on Hugging Face and a related arXiv paper. While some found the models currently less effective, they suggested their potential use in creating applications like texture generation.
- Clarification of Git vs. GitHub confusion: Members clarified the differences between Git and GitHub, emphasizing that Git is a source code management tool and GitHub is a repository hosting service. The conversation included a video link to help explain these concepts further.
- Introduction of new members: New members such as Piyush Ranjan Maharana and Tomer shared their backgrounds, including work in computational physics, autonomous cars, and material discovery via LLMs. They expressed eagerness to learn and contribute to the community.
- common-canvas (CommonCanvas): no description found
- GitHub - allenai/ccget: Tools for an internal archive of some Common Crawl files: Tools for an internal archive of some Common Crawl files - allenai/ccget
- Careers | AISI: View career opportunities at AISI. The AI Safety Institute is a directorate of the Department of Science, Innovation, and Technology that facilitates rigorous research to enable advanced AI governance...
Eleuther ▷ #research (61 messages🔥🔥):
- Exploring RWKV-CLIP for Vision-Language Learning: A paper discussed the introduction of RWKV-CLIP, a vision-language representation learning model combining transformers' parallel training with RNNs' efficient inference. This approach aims to improve large-scale image-text data quality by leveraging LLMs to synthesize and refine web-based texts and synthetic captions.
- Concerns Around Diffusion Model Hallucinations: Another paper explored the phenomenon of "hallucinations" in diffusion models, identifying a failure mode termed mode interpolation. The study revealed that diffusion models interpolate between data modes, creating artifacts not present in the original training distribution.
- Discussion on Prefetching Streaming Datasets: Some technical discussions touched on handling streaming datasets with
keep_in_memory=Truefor efficient data fetching. Members shared insights about the recent introduction of checkpointing and resuming streams, enhancing usability for large datasets.
- Effectiveness of Laprop Optimizer: Members debated the effectiveness of the Laprop optimizer, with mixed results showing indifferent or inferior performance compared to AdamW. Parameter tweaks made some improvements, yet Laprop's overall performance remained underwhelming.
- Stealing Commercial Embedding Models: A paper highlighted a method for "stealing" commercial embedding models by training local models with text-embedding pairs obtained from APIs. The method showed that effective replication could be achieved inexpensively, raising concerns about the security of commercial models.
- Can't Hide Behind the API: Stealing Black-Box Commercial Embedding Models: Embedding models that generate representation vectors from natural language text are widely used, reflect substantial investments, and carry significant commercial value. Companies such as OpenAI and ...
- Creativity Has Left the Chat: The Price of Debiasing Language Models: Large Language Models (LLMs) have revolutionized natural language processing but can exhibit biases and may generate toxic content. While alignment techniques like Reinforcement Learning from Human Fe...
- Language Reconstruction with Brain Predictive Coding from fMRI Data: Many recent studies have shown that the perception of speech can be decoded from brain signals and subsequently reconstructed as continuous language. However, there is a lack of neurological basis for...
- Understanding Hallucinations in Diffusion Models through Mode Interpolation: Colloquially speaking, image generation models based upon diffusion processes are frequently said to exhibit "hallucinations," samples that could never occur in the training data. But where do...
- Logit Prisms: Decomposing Transformer Outputs for Mechanistic Interpretability: no description found
- Neural Isometries: Taming Transformations for Equivariant ML: Real-world geometry and 3D vision tasks are replete with challenging symmetries that defy tractable analytical expression. In this paper, we introduce Neural Isometries, an autoencoder framework which...
- RWKV-CLIP: A Robust Vision-Language Representation Learner: Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper...
- codeparrot/github-code-clean · Datasets at Hugging Face: no description found
- Tweet from Armen Aghajanyan (@ArmenAgha): Final Update: One more magnitude of testing Sophia. We're talking model sizes in the B's, tokens in the T's. Sophia once again wins out. For me at least this is clear evidence that Sophia ...
- Learned Optimizers that Scale and Generalize: no description found
- A Closer Look at Learned Optimization: Stability, Robustness, and Inductive Biases: Learned optimizers -- neural networks that are trained to act as optimizers -- have the potential to dramatically accelerate training of machine learning models. However, even when meta-trained across...
- TextGrad: Automatic "Differentiation" via Text: AI is undergoing a paradigm shift, with breakthroughs achieved by systems orchestrating multiple large language models (LLMs) and other complex components. As a result, developing principled and autom...
- GitHub - zou-group/textgrad: Automatic ''Differentiation'' via Text -- using large language models to backpropagate textual gradients.: Automatic ''Differentiation'' via Text -- using large language models to backpropagate textual gradients. - zou-group/textgrad
- GitHub - CFGpp-diffusion/CFGpp: Official repository for "CFG++: manifold-constrained classifier free guidance for diffusion models": Official repository for "CFG++: manifold-constrained classifier free guidance for diffusion models" - CFGpp-diffusion/CFGpp
- CFG++: Manifold-constrained Classifier Free Guidance for Diffusion Models: Classifier-free guidance (CFG) is a fundamental tool in modern diffusion models for text-guided generation. Although effective, CFG has notable drawbacks. For instance, DDIM with CFG lacks invertibili...
- GitHub - apple/ml-agm: Contribute to apple/ml-agm development by creating an account on GitHub.
- Generative Modeling with Phase Stochastic Bridge: Diffusion models (DMs) represent state-of-the-art generative models for continuous inputs. DMs work by constructing a Stochastic Differential Equation (SDE) in the input space (ie, position space),...
Eleuther ▷ #scaling-laws (18 messages🔥):
- Hypernetwork-based Paper Critique: A member dismissed a paper proposing linear hypernetwork attention as "useless," claiming it contains a critical mistake making its efficiency worse than full attention. They highlighted that the paper provides some reasoning for attention mechanisms behaving like hypernetworks.
- Hypernetworks and Hopfield Nets Debate: Members discussed whether hypernetworks are actually Hopfield nets, with one member noting that although there are high-level similarities like input-dependent weight generation, Hopfield networks are inherently recurrent. This sparked a conversation on the historical significance and evolution of Hopfield networks.
- Hopfield Networks' Historical Context: Members reminisced about Hopfield networks' past significance in connectionism and their influence on current models like transformers. They pointed out that modern models use backpropagation and multi-layer networks for superior performance, but the concepts of attractors and dynamics from Hopfield nets still inform contemporary neural network architecture.
- Dynamic Evaluation and Online Adaptation: A member shared a paper on dynamic evaluation for language models, emphasizing its utility in adapting to distributional shifts at test time. This method is described as turning parameters into temporally changing states, much like memory in neuroscience, and warrants a potential Jones-style scaling law evaluation.
- Jones-style Scaling Law Reference: In response to the dynamic evaluation discussion, a member referenced the "Scaling scaling laws with board games" paper by Andy L. Jones, which suggests trading off training compute and inference compute. This reference underscores the relevance of considering efficient scaling laws in adaptive model contexts.
- Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models: We consider the problem of online fine tuning the parameters of a language model at test time, also known as dynamic evaluation. While it is generally known that this approach improves the overall pre...
- Beyond Scaling Laws: Understanding Transformer Performance with Associative Memory: Increasing the size of a Transformer model does not always lead to enhanced performance. This phenomenon cannot be explained by the empirical scaling laws. Furthermore, improved generalization ability...
- Tweet from Igor Babuschkin (@ibab): I keep revisiting this great paper from @andy_l_jones: “Scaling scaling laws with board games”. It shows how training compute and inference compute of MCTS can be traded off against each other. 10x mo...
Eleuther ▷ #interpretability-general (11 messages🔥):
- Math PhD explores Sparse Autoencoders: A new math PhD graduate expressed interest in interpretability research involving Sparse Autoencoders (SAEs). They were directed to a blog post, which found that SAEs may recover composed features instead of ground truth ones in toy models.
- Discussion on Sparse Coding and Dictionary Learning: Members shared relevant papers and discussed topics related to sparse coding and dictionary learning, including a paper on dictionary learning in Wasserstein space here and another on disentanglement in naturalistic videos here.
- Framework for Evaluating Feature Dictionaries: A paper was introduced which proposes a framework for evaluating feature dictionaries in specific tasks using supervised dictionaries, highlighting its application on the indirect object identification task using GPT-2 Small (link to paper).
- Link to Linear Identifiability Work: Inquiries about settings with genuinely linear features in activation space led to recommendations for investigating linear probes and ICA literature, with a relevant paper here.
- Announcement of Logit Prisms Tool: New work extending the logit lens method was announced as "logit prisms," decomposing logit output into components of the residual stream, attention layers, and MLP layers. It was used to study the gemma-2b model, revealing that digits 0-9 are encoded in a heart-like shape in a 2D space (full article).
- Logit Prisms: Decomposing Transformer Outputs for Mechanistic Interpretability: no description found
- Towards Nonlinear Disentanglement in Natural Data with Temporal Sparse Coding: We construct an unsupervised learning model that achieves nonlinear disentanglement of underlying factors of variation in naturalistic videos. Previous work suggests that representations can be disent...
- Towards Principled Evaluations of Sparse Autoencoders for Interpretability and Control: Disentangling model activations into meaningful features is a central problem in interpretability. However, the absence of ground-truth for these features in realistic scenarios makes validating recen...
- Sparse autoencoders find composed features in small toy models — LessWrong: Summary * Context: Sparse Autoencoders (SAEs) reveal interpretable features in the activation spaces of language models. They achieve sparse, interp…
Eleuther ▷ #lm-thunderdome (4 messages):
- Call for sharing evaluation results: A member pointed out that Hugging Face is using an outdated harness version and observed significant differences in current results. They inquired about a platform where people could post their own evaluation results including runtime parameters and version information for validation.
- Independent validation request for closed-source models: The same member also asked if there was a place to post independent validation results for various closed-source models. This suggests a need for a shared, trustworthy evaluation forum.
- Multi-GPU evaluation issue with WANDB: Another member reported an issue when executing multi-GPU evaluation, leading to the creation of two separate projects in WANDB instead of one. They shared their command setup and sought advice on whether using the
--num_processes=2flag for data parallel evaluation is appropriate.
Eleuther ▷ #multimodal-general (3 messages):
- Code Release Inquiry Leads to GitHub Issues: A member inquired about the release date for a particular code. Another member redirected the query to the project's GitHub Issues page for the RWKV-CLIP project.
Link mentioned: Issues · deepglint/RWKV-CLIP: The official code of "RWKV-CLIP: A Robust Vision-Language Representation Learner" - Issues · deepglint/RWKV-CLIP
LLM Finetuning (Hamel + Dan) ▷ #general (35 messages🔥):
- Apple's AI strategy at WWDC intrigues: A community member shared a blog post detailing Apple's new AI strategy, highlighting Apple's avoidance of NVIDIA hardware and CUDA APIs. It discusses the use of Apple’s AXLearn, which runs on TPUs and Apple Silicon.
- Deep dive into embeddings resources: A list of valuable resources on embeddings was shared, including a link to a curated list on GitHub and a blog post at vickiboykis.com. Members discussed the importance of understanding latent spaces and how embeddings emerge.
- Open call for refusal classifier models: A member expressed interest in off-the-shelf refusal classifier models, possibly using T5/BERT for multilingual data. They indicated a need for around 1K samples for training and sought advice on this topic.
- Fine-tuning TinyLlama for specific narration style: A member documented their experience with fine-tuning TinyLlama to generate David Attenborough-style narration, sharing their blog post. They utilized tools like Axolotl and Jarvis Labs for the project, learning and sharing detailed steps and insights.
- Issue with loading model config on Jarvis Labs: A user faced an error while trying to fine-tune Mistral on Jarvis, which was resolved after switching to version v0.3 and changing the permissions of their token. They noted this might have also needed network stability, thanking others for their assistance.
- no title found: no description found
- Hamel Husain: no description found
- What are embeddings?: A deep-dive into machine learning embeddings.
- Educational Resources – Parlance: no description found
- Gabriel Chua - Fine-tuning TinyLlama with Axolotl and JarvisLab: no description found
- Understanding Apple’s On-Device and Server Foundation Models release: By Artem Dinaburg Earlier this week, at Apple’s WWDC, we finally witnessed Apple’s AI strategy. The videos and live demos were accompanied by two long-form releases: Apple’s Private Cloud Compute a…
- Tweet from gabriel (@gabrielchua_): fine-tuning with @axolotl_ai and @jarvislabsai as part of @HamelHusain & @dan_s_becker 's llm f̴i̴n̴e̴-̴t̴u̴n̴i̴n̴g̴ ̴c̴o̴u̴r̴s̴e̴ conference, i did up a toy example to generate david attenbor...
- GitHub - eifuentes/awesome-embeddings: 🪁A curated list of awesome resources around entity embeddings: 🪁A curated list of awesome resources around entity embeddings - eifuentes/awesome-embeddings
- It Crowd Hello It GIF - It Crowd Hello IT Have You Tried Turning It Off And On Again - Discover & Share GIFs: Click to view the GIF
{kind=link}
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (14 messages🔥):
- Credit confusion and resolution: A user realized they missed the deadline for additional credits and asked for help, receiving a positive response with the GitHub link. Another user asked about the status of their account, and their credits were granted after a manual review.
- Discussion on model startup optimization: A user inquired whether copying model weights into the image or mounting them from a volume affects startup times. They were informed that weights loaded into images might have a slight edge, but infrastructure unification means differences are minor.
- Multi-turn conversation issue and solution: A user experienced an issue with their model predicting the first turn of conversation repeatedly and was advised to discuss it in the appropriate channel. They later resolved it by changing the dataset format to the input_output format of Axolotl.
- Axolotl - Template-free prompt construction: no description found
- setegonz - Overview: setegonz has 10 repositories available. Follow their code on GitHub.
- llm-finetuning/nbs/inspect_data.ipynb at main · modal-labs/llm-finetuning: Guide for fine-tuning Llama/Mistral/CodeLlama models and more - modal-labs/llm-finetuning
LLM Finetuning (Hamel + Dan) ▷ #learning-resources (5 messages):
- Learn TextGrad for prompt fine-tuning: Members discussed the TextGrad project, which uses large language models to backpropagate textual gradients. It was noted that the project is considered better than DSPy and there is an explanatory YouTube video.
- Using TextGrad without installation: One member inquired if they could use TextGrad with their Anthropic/OpenAI API keys without installing anything. Another member mentioned that they tried the example Colab notebooks where one can set their OpenAI API key and test how it works.
- Implementing LLMs from scratch: A link to a GitHub repository was shared, providing a step-by-step guide for implementing a ChatGPT-like LLM in PyTorch. This resource could be useful for those interested in learning and experimenting with LLM development from the ground up.
- LLMs-from-scratch/ch07/01_main-chapter-code/ch07.ipynb at main · rasbt/LLMs-from-scratch: Implementing a ChatGPT-like LLM in PyTorch from scratch, step by step - rasbt/LLMs-from-scratch
- GitHub - zou-group/textgrad: Automatic ''Differentiation'' via Text -- using large language models to backpropagate textual gradients.: Automatic ''Differentiation'' via Text -- using large language models to backpropagate textual gradients. - zou-group/textgrad
- NEW TextGrad by Stanford: Better than DSPy: In this TEXTGRAD framework, each AI system is transformed into a computation graph, where variables are inputs and outputs of complex (not necessarily differ...
LLM Finetuning (Hamel + Dan) ▷ #hugging-face (2 messages):
- Reminder about form deadline: Gentle reminder folks that today is the last day to sign the form! If you have not gotten credits yet, but yet think you filled out the first form, FILL THIS ONE OUT!**
- Credits issuance for second form submissions: If you applied on the second form, "we haven't done credits for those yet, that happens after Monday." There was a mention of difficulty in finding some users in the original form.
LLM Finetuning (Hamel + Dan) ▷ #replicate (2 messages):
- User Follows Up on Credit Link: A member expressed concern about not receiving a link to redeem credits for Replicate. They mentioned having already sent their email and other details via DM.
- LoRA Adapter Deployment Query: A member sought assistance on deploying LoRA adapters to Replicate, mentioning success with running a fine-tuned phi-3-mini locally using Cog. They contrasted the process with Modal, where a volume is created and bound to a container at runtime, and asked how a similar approach could be achieved on Replicate.
LLM Finetuning (Hamel + Dan) ▷ #langsmith (5 messages):
- Clarification on LangSmith Beta Credits vs Course Credits: A user asked if "LangSmith Beta Credit" are the same as the credits for the course. Another user clarified that they are different; "LangSmith Beta Credit" was granted to beta users, while course credits should appear as 'Mastering LLMs Course Credit' under billing.
- Offering Help with Missing Credits: One user offered assistance to another user who felt they were missing course credits. They confirmed that they could check the situation if provided with the email used in the credits form.
- User Queries about Missing Credits: Another user inquired about not seeing any credits on LangSmith. They requested help to understand if any additional steps were needed from their end.
LLM Finetuning (Hamel + Dan) ▷ #berryman_prompt_workshop (2 messages):
- Promptfoo gains interest among members: A member expressed interest in Promptfoo, thanking another for sharing it.
- Inspect-ai preferred over Promptfoo: Another member shared their preference for inspect-ai over Promptfoo, citing its flexibility and fit with Python in a test style. However, they mentioned it's not straightforward to do side-by-side comparisons with inspect-ai compared to Promptfoo.
LLM Finetuning (Hamel + Dan) ▷ #workshop-3 (4 messages):
- CUDA Error during Docker Execution: A user experienced a
Dockererror when running Python in a container, with the message "OCI runtime create failed: runc create failed: unable to start container process". Another user suggested that this might be due to an improperly set up CUDA or a compatibility issue. - Difficulty in Issue Replication: The issue is hard to replicate, as noted by a responder who stated, "It’s hard to tell because I can’t replicate this issue". This indicates the problem might be environment-specific or related to the user's specific configuration.
LLM Finetuning (Hamel + Dan) ▷ #clavie_beyond_ragbasics (8 messages🔥):
- RAGatouille Simplifies ColBERT Usage: A member praised RAGatouille as a great tool for integrating ColBERT with Langchain for internal projects. They also recommended Ben's post as a fantastic introduction to ColBERT.
- Understanding Bi-encoder Functionality in RAG: Addressing a beginner’s query about the logic behind bi-encoders in RAG setups, another member explained that models are trained to associate queries and documents with a prefix system. The response highlighted the necessity of defining "similarity" during model training to suit different use cases.
- Exploring Learning Resources: A member sought resources for advanced topics like finetuning ColBERT and rerankers, and using embedding adapters. They appreciated another member's recommendation of a Medium post on building state-of-the-art text embedding models.
- Combining Full Text Search with Fine-tuned Rerankers: A participant discussed their approach of using lancedb and combining full-text search via Lucene with fine-tuned rerankers for impactful results. They noted not using vector databases as mentioned in Ben's presentation.
- RAGatouille: no description found
- GitHub - bclavie/RAGatouille: Easily use and train state of the art late-interaction retrieval methods (ColBERT) in any RAG pipeline. Designed for modularity and ease-of-use, backed by research.: Easily use and train state of the art late-interaction retrieval methods (ColBERT) in any RAG pipeline. Designed for modularity and ease-of-use, backed by research. - bclavie/RAGatouille
LLM Finetuning (Hamel + Dan) ▷ #jason_improving_rag (1 messages):
- Efficient Category Structuring for GPT-4o: Members discussed how using a tree structure for category prompts improves GPT-4o's decision-making in filter selection. Despite the large system prompt, it works well even though latency was an issue with GPT-4.
- Single Vector Strategy for Documents: The group uses just one vector per document/product, accompanied by appropriate meta tags. This approach aids in maintaining a streamlined and effective categorization system.
LLM Finetuning (Hamel + Dan) ▷ #jeremy_python_llms (3 messages):
- Catch up on talks with shared link: A member requested a link to catch up on the discussions. Jeremy Howard promptly shared this Discord link, and the member expressed their gratitude.
Link mentioned: Join the fast.ai Discord Server!: Check out the fast.ai community on Discord - hang out with 10920 other members and enjoy free voice and text chat.
LLM Finetuning (Hamel + Dan) ▷ #saroufimxu_slaying_ooms (3 messages):
- Anticipation Builds for New Session: A user inquired about the likelihood of a new session taking place with a humorous undertone: What is the probability that there will be a session? 🫢🤪.
- Upcoming Project in Memory Efficiency: Another user informed everyone that a new project focused on memory efficiency is underway. They mentioned that once this project is ready, a "more interesting talk" can be expected.
LLM Finetuning (Hamel + Dan) ▷ #axolotl (27 messages🔥):
- Strickvl hits OOM errors with local LORA models: Despite using two 4090s, Strickvl faces Out-Of-Memory (OOM) errors when loading full resultant LORA models. They suggested checking configurations and considering quantization, and shared their configs on GitHub.
- Quantization offers a memory-saving solution: Chrislevy pointed out that models loaded in float32 consume a lot of memory and recommended using
torch_dtype=torch.bfloat16for inference, as described in the Llama 3 model card.
- Documentation gap for axolotl and finetuning: There's a call for better documentation on finetuning, specifically on training LORA/QLORA settings, saving models, and proper loading techniques. Strickvl emphasized this need and hinted at using Hamel’s course repo for sanity checks.
- Modal Labs guide clarifies model loading: Andrewcka provided code insights from Modal Labs' inference script explaining how the script identifies the last trained model by date-time to handle inference effectively.
- Finetuning multi chat conversations with axolotl: Huikang inquired about adapting axolotl for multi chat conversations and shared resources like the code for CodeLlama and the axolotl dataset formats for conversation fine-tuning.
- Axolotl - Dataset Formats: no description found
- Axolotl - Config options: no description found
- llm-finetuning/src/inference.py at main · modal-labs/llm-finetuning: Guide for fine-tuning Llama/Mistral/CodeLlama models and more - modal-labs/llm-finetuning
- isafpr_finetune/notebooks/sanity_check.py at main · strickvl/isafpr_finetune: Finetuning an LLM for structured data extraction from press releases - strickvl/isafpr_finetune
- Optimizing your LLM in production: no description found
- ftcourse/06_sanity_check.ipynb at master · parlance-labs/ftcourse: Contribute to parlance-labs/ftcourse development by creating an account on GitHub.
- meta-llama/Meta-Llama-3-8B-Instruct · Hugging Face: no description found
- Chris Levy - Fine-Tuning LLMs with Axolotl on JarvisLabs: no description found
- llm-finetuning/config/codellama.yml at main · modal-labs/llm-finetuning: Guide for fine-tuning Llama/Mistral/CodeLlama models and more - modal-labs/llm-finetuning
LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (1 messages):
- Excitement over Code Llama's release: Code Llama is an evolution of Llama 2, tuned specifically for code tasks, and released in the Hugging Face ecosystem. The release includes models on the Hub, Transformers integration, and several productivity-boosting features for software engineers.
- Format difference spotted: Noting a format difference between the Hugging Face blog post about Code Llama and the GitHub configuration file for finetuning Code Llama models. This was highlighted to confirm if such differences are acceptable.
- Code Llama: Llama 2 learns to code: no description found
- llm-finetuning/config/codellama.yml at main · modal-labs/llm-finetuning: Guide for fine-tuning Llama/Mistral/CodeLlama models and more - modal-labs/llm-finetuning
LLM Finetuning (Hamel + Dan) ▷ #charles-modal (1 messages):
- Channel Lockdown Notice: The channel is being locked down, and members are directed to use another channel for any questions for Charles. A friendly emoji, <:hugging_angel:936261297182482452>, was included in the announcement.
LLM Finetuning (Hamel + Dan) ▷ #simon_cli_llms (5 messages):
- CORS Error blocks video fetch: A member reported encountering CORS errors when trying to fetch a video. The suggested workaround is to "open the raw .mp4".
- CloudFront misconfiguration suspected: The issue may stem from a CloudFront misconfiguration where the request's CORS headers aren't being cached properly. The member noted that "CloudFront will cache the whole response on the first time the URL is hit" and "their cache does not key on the fetch mode request headers".
- Video link provided: The video in question is accessible at this link. The member queried whether it was "recorded from outside zoom and shared via a bucket".
Link mentioned: no title found: no description found
LLM Finetuning (Hamel + Dan) ▷ #allaire_inspect_ai (3 messages):
- Using instructor with inspect_ai: A member asked if there was a way to use something like instructor in inspect_ai to ensure the output format is valid. Another member suggested either implementing and registering a custom model or using tool calls directly, as this is what instructor does under the hood.
- flexibility of inspect_ai: One user noted that inspect_ai allows for replacing existing infrastructure with custom solutions or enhancing current setups.
LLM Finetuning (Hamel + Dan) ▷ #credits-questions (3 messages):
- Credit Check Confusion on Braintrust Data: A user expressed frustration about not finding where to check credits on the Braintrust Data site: "I can not even find where to check credits on braintrustdata site. It does not show anything to billing at all?" Another user suggested seeking help in another channel, emphasizing they also couldn't find the credit status.
- Redirect to Proper Channel for Solutions: A member recommended moving the discussion to a different channel, tagging another user for a potential answer to the credits check issue. They acknowledged similar difficulties in locating the current credit status.
LLM Finetuning (Hamel + Dan) ▷ #fireworks (6 messages):
- Users Swamp Support for Credit Issues: Multiple users requested assistance with missing credits on their accounts. User account IDs mentioned include carljvh-7d2eb0, jalonso-e11d20, alex-kira-d15187, harrille-postia-723075, ayhanfuat-fa2dd5, and data-94d7ef.
LLM Finetuning (Hamel + Dan) ▷ #braintrust (3 messages):
- User seeks platform testing credits: @peaky8linders asked about logging in to test a platform and still seeing the Upgrade button, querying if they could still get credits. They provided their email and organization information for verification.
- Credits confirmed: @ankrgyl assured @peaky8linders that they should be all set with the credits.
LLM Finetuning (Hamel + Dan) ▷ #west-coast-usa (1 messages):
.peterj: Anyone from Seattle area?
LLM Finetuning (Hamel + Dan) ▷ #east-coast-usa (1 messages):
ssilby: <@415846459016216576> I'm in! Let's set up a DMV meetup :3
LLM Finetuning (Hamel + Dan) ▷ #predibase (7 messages):
- Predibase Misinterprets Dataset Fields: A user faced issues with their Alpaca/ShareGPT-formatted dataset on Predibase due to a missing
textfield. They were curious how to work with template-free datasets and convert their data accordingly. - Getting Data Format Right for Predibase: The user resolved their issue by selecting the 'instruction tuning' format and adjusting the data as per Predibase's documentation. They shared their dataset for reference here.
- Test Data Evaluation on Predibase: The user noted a limitation of Predibase regarding the use of test data for evaluation and mentioned they would perform the evaluation after the model is trained.
- Extracting Adapters from Predibase: The user inquired if it is possible to download or extract the adapters trained on Predibase for local testing, preferring to avoid deploying a custom instance.
Link mentioned: isafpr_finetune/data at main · strickvl/isafpr_finetune: Finetuning an LLM for structured data extraction from press releases - strickvl/isafpr_finetune
LLM Finetuning (Hamel + Dan) ▷ #openpipe (3 messages):
- Dataset Format Struggles Resolved: A member asked for examples of datasets formatted correctly for Openpipe, mentioning unsuccessful attempts with axolotl and template-free datasets. Later, they solved their own problem by formatting the data according to the OpenAI chat format used for OpenAI finetuning, sharing their dataset on GitHub.
Link mentioned: isafpr_finetune/data at main · strickvl/isafpr_finetune: Finetuning an LLM for structured data extraction from press releases - strickvl/isafpr_finetune
LLM Finetuning (Hamel + Dan) ▷ #openai (1 messages):
kramakurious: <@1010989949572612166> is this something you can help with?
Interconnects (Nathan Lambert) ▷ #news (69 messages🔥🔥):
- Sakana AI hits $1B valuation: Sakana AI, a Japanese startup developing alternatives to transformer models, raised funds from NEA, Lux, and Khosla at a $1B valuation. For more details, check out the link.
- Runway's Gen-3 Alpha debuts: Runway introduced Gen-3 Alpha, a new base model for video generation. Claimed to create highly detailed videos with complex scene changes and a wide range of cinematic choices.
- DeepSeek-Coder-V2 impresses: DeepSeek-Coder-V2 was released, reportedly beating GPT-4 on both HumanEval and MATH benchmarks.
- Google DeepMind’s new video-to-audio tech: Google DeepMind showcased progress on their video-to-audio (V2A) technology, capable of generating an "unlimited number" of tracks for any video. See examples here.
- Wayve's new view synthesis model: Wayve released a new view synthesis model, impressively creating views from input images using 4D Gaussians, according to Jon Barron's update.
- Tweet from Rowan Cheung (@rowancheung): Google DeepMind just shared progress on their new video-to-audio (V2A) tech Until now, AI video generations have been silent, this solves that. V2A can generate an "unlimited number" of track...
- Tweet from Jon Barron (@jon_barron): Wayve dropped a new view synthesis model earlier today. I'm guessing it's a radiance field made of 4D Gaussians. Nothing generative, just view synthesis from input images. Very impressive.
- Tweet from Runway (@runwayml): Introducing Gen-3 Alpha: Runway’s new base model for video generation. Gen-3 Alpha can create highly detailed videos with complex scene changes, a wide range of cinematic choices, and detailed art di...
- Tweet from Dwarkesh Patel (@dwarkesh_sp): I asked Buck about his thoughts on ARC-AGI to prepare for interviewing @fchollet. He tells his coworker Ryan, and within 6 days they've beat SOTA on ARC and are on the heels of average human perf...
- Tweet from Stephanie Palazzolo (@steph_palazzolo): NEW w/ @nmasc_ @KateClarkTweets: Sakana AI, a Japanese startup developing alternatives to transformer models, has raised from NEA, Lux and Khosla at a $1B valuation. More here: https://www.theinform...
- Tweet from Nathan Lambert (@natolambert): What unlocked all these text-to-video models being good within the same 6month window? Was it just that people weren't trying? Wild that it seems like just coincidence for them to all emerge. L...
- AI Text to Sound Effects Generator: Use our AI Sound Effects Generator to generate any sound imaginable from a text prompt for free. Perfect for videos, podcasts, or any other audio production.
Interconnects (Nathan Lambert) ▷ #ml-drama (4 messages):
- Sam Altman hints at OpenAI governance changes: A tweet by Jacques Thibault referenced a private statement by Sam Altman, suggesting OpenAI might convert to a for-profit business. This move could potentially enable a public offering, allowing Altman to gain a stake in OpenAI. Read the full tweet.
- The Information reports on OpenAI’s potential shift: The Information detailed that Altman has privately mentioned OpenAI’s possible shift to a benefit corporation, similar to Anthropic and xAI. This transformation could lead to OpenAI going public. Read the article here.
- Community reacts skeptically: One member expressed skepticism over these developments, summarizing their sentiment with "This is so sketch lmao".
Link mentioned: Tweet from Jacques (@JacquesThibs): "Sam Altman recently told some shareholders that OAI is considering changing its governance structure to a for-profit business that OAI's nonprofit board doesn't control. [...] could open ...
Interconnects (Nathan Lambert) ▷ #random (63 messages🔥🔥):
- Compliments on Interconnects Merch: Members discussed the quality of the merchandise, noting that while stickers were not well-received, the T-shirts were appreciated. One member mentioned, "stickers were bad need to try another vendor."
- Dissecting ARC-AGI Performance: A link to a Redwood Research article discussing methods to improve ARC-AGI performance sparked debate. Members criticized the approach of using a large number of samples, arguing it's more about hitting by chance rather than scaling.
- Exploring Neurosymbolic AI: Members dove into neurosymbolic AI, questioning if leveraging LLMs for discrete program search truly fits the traditional definition. A discussion evolved around a tweet from François Chollet, parsing out whether current AI techniques suffice or if fundamental breakthroughs are necessary.
- MidJourney's New Ventures: MidJourney is expanding into hardware and anticipates launching training on its video models in January. CEO David Holz confirmed this during a Discord "Office Hour" session.
- Conundrums at Academic Conferences: A member pondered the value of attending ACL in Thailand despite the travel inconvenience from California, questioning its relevance compared to major conferences like NeurIPS. "I don't think it's do or die," another member responded, suggesting optional attendance.
- Apparate AI: no description found
- Tweet from François Chollet (@fchollet): @dwarkesh_sp This has been the most promising branch of approaches so far -- leveraging a LLM to help with discrete program search, by using the LLM as a way to sample programs or branching decisions....
- Getting 50% (SoTA) on ARC-AGI with GPT-4o: You can just draw more samples
- arc_draw_more_samples_pub/arc_solve/edit_distance.py at 0b36f4584aebae9ec876d3510842b3651e719d67 · rgreenblatt/arc_draw_more_samples_pub: Draw more samples. Contribute to rgreenblatt/arc_draw_more_samples_pub development by creating an account on GitHub.
LlamaIndex ▷ #blog (9 messages🔥):
- RAG and Agents Guide Excites with Excalidraw Diagrams: @nerdai shared a comprehensive slide deck on building RAG and Agents. The guide includes full Excalidraw diagrams breaking down simple-to-advanced concepts.
- Arize Integration Adds End-to-End Observability: The new instrumentation module integrates with Arize, demonstrated in this guide. It shows how to instrument custom event/span handlers in LLM apps.
- AI World's Fair Wrap-up Featuring Top Speakers: Join talks from @jerryjliu0, @freddie_v4, @atitaarora, and more at the AI Sizzle and Waves event by AI Engineer World's Fair. Hosted by Angela Tse, Atita Arora, and Julia Neagu.
- Beginner’s Guide for Full-Stack Agents Released: @MervinPraison's tutorial offers a step-by-step guide on building core components of an agent using local models and @chainlit_io. The tutorial is designed to create simple applications.
- Multimodal RAG Pipeline with Claude 3 and SingleStoreDB: @Pavan_Belagatti discusses future roles of multimodal RAG in his article, which utilizes Claude 3 by @AnthropicAI and @SingleStoreDB. This pipeline addresses the prevalence of images within documents.
- AI Engineer World's Fair Closer: AI Sizzle and Waves @ GitHub HQ · Luma: Wrap up the Fair with an AI summer Friday. Enjoy refreshing treats and ride the waves of fresh takes from fellow developers and innovators. Hear from our…
- openinference/python/instrumentation/openinference-instrumentation-llama-index at main · Arize-ai/openinference: Auto-Instrumentation for AI Observability. Contribute to Arize-ai/openinference development by creating an account on GitHub.
- Instrumentation: Basic Usage - LlamaIndex: no description found
LlamaIndex ▷ #general (95 messages🔥🔥):
- Chunking customer service emails for RAG: One member asked how to create chunks for a customer service RAG model based on email conversations. Another suggested capturing the first email from each chain to ensure each email is included.
- Generating specific outputs from markdown documents: A user is having issues with LlamaIndex truncating relevant language from markdown documents. They need precise outputs without summarization and are looking for any advice to improve this.
- Using Neo4j with LlamaIndex: Multiple queries were raised about converting Neo4j knowledge graphs into LlamaIndex property graphs. Detailed instructions and a link to the LlamaIndex documentation were shared (LlamaIndex Property Graph Example).
- Overlapping sentence retrieval: A user inquired about expanded sentences overlapping when using sentence-level retrievals. It was clarified that overlapping sentences do not get merged, and custom post-processing would be needed.
- Saving ChatMemoryBuffer: There was a discussion on saving
ChatMemoryBufferobjects to a file format to manage token limits in long conversations. A method to save chat memory as a dict and store it in a JSON file was suggested.
- LlamaIndex Webinar: Advanced RAG with Knowledge Graphs (with Tomaz from Neo4j) · Zoom · Luma: We’re hosting a special workshop on advanced knowledge graph RAG this Thursday 9am PT, with the one and only Tomaz Bratanic from Neo4j. In this webinar, you’ll…
- llama_index/llama-index-integrations/storage at 02984efc5004126ccaffa15ec599d0dacce55dd3 · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Neo4j Property Graph Index - LlamaIndex: no description found
- llama_index/llama-index-core/llama_index/core/query_engine/knowledge_graph_query_engine.py at 01e5173f8a272e8b7e5ccb2ae3ff215eb6c4ca6a · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- llama_index/llama-index-core/llama_index/core/query_engine/knowledge_graph_query_engine.py at 01e5173f8a272e8b7e5ccb2ae3ff215eb6c4ca6a · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- no title found: no description found
- Relative Score Fusion and Distribution-Based Score Fusion - LlamaIndex: no description found
- A framework for creating knowledge graphs of scientific software metadata: Abstract. An increasing number of researchers rely on computational methods to generate or manipulate the results described in their scientific publications. Software created to this end—scientific so...
LlamaIndex ▷ #ai-discussion (6 messages):
- Power-Up LLMs with Web Scraping and RAG!: How to Power-Up LLMs with Web Scraping and RAG explores enhancing LLM performance through web scraping and retrieval-augmented generation (RAG). The article highlights tools like Firecrawl for clean Markdown extraction and Scrapfly for various output formats.
- Firecrawl vs. Scrapfly in LLM Applications: "Firecrawl shines for Markdown", making it ideal for preparing data for LLMs. Scrapfly offers flexibility with various output formats but may need additional processing for LLM optimization.
tinygrad (George Hotz) ▷ #general (39 messages🔥):
- Script indentation breaks in autogen_stubs.sh: A member faced issues with the
autogen_stubs.shscript whereclang2pybreaks indentation, causing syntax errors. Discussions revealed it was not needed for the intended task of running tinygrad with GPU. - OpenCL installation issues cause errors: Problems with OpenCL installation led to errors when running tinygrad on GPU. George Hotz suggested fixing the OpenCL setup and checking
clinfoto troubleshoot. - Improving OpenCL error messages: The community discussed enhancing OpenCL error messages by autogenerating them from OpenCL headers. A pull request was opened to implement better error messages.
- Process replay documentation needed: George Hotz requested adding documentation on process replay to assist new contributors. This was in response to simplifying the process of rewriting operations using new styles.
- Monday meeting agenda topics: Important topics include the tinybox launch, the 0.9.1 release, the CI benchmark duration, removing numpy, and various technical discussions. Highlights also include performance milestones like achieving 200 tok/s for llama 7B on multi-GPU setups.
- Tweet from the tiny corp (@__tinygrad__): @PennJenks It's three kernels. We need to fuse it into 1. GRAPH=1 python3 -c "from tinygrad import Tensor; Tensor.rand(100,100).softmax().realize()"
- Tweet from the tiny corp (@__tinygrad__): tinybox has a 1TB NVMe boot drive on USB 3, and 4 1TB NVMes each on 4 lanes of PCI-E 4.0; 4TB for holding weights and datasets. No theory, that's a real benchmark. It's faster than the RAM on...
- nv better error messages for ioctls by nimlgen · Pull Request #4899 · tinygrad/tinygrad: no description found
- Fix/opencl Better error Messages by GabrielZCode · Pull Request #5004 · tinygrad/tinygrad: Better openCL error messages!! Using the same strategy as generate_nv() function in generate_stubs.sh , I've extracted the error messages from https://github.com/KhronosGroup/OpenCL-Headers/tree/m...
- OpenCL error codes (1.x and 2.x) - StreamHPC: Knowing all errors by heart is good for quick programming, but not always the best option. Therefore I started to create ...
- OpenCL-Headers/CL/cl.h at main · KhronosGroup/OpenCL-Headers: Khronos OpenCL-Headers. Contribute to KhronosGroup/OpenCL-Headers development by creating an account on GitHub.
- OpenCL-Headers/CL/cl_ext.h at main · KhronosGroup/OpenCL-Headers: Khronos OpenCL-Headers. Contribute to KhronosGroup/OpenCL-Headers development by creating an account on GitHub.
- OpenCL-Headers/CL/cl_egl.h at main · KhronosGroup/OpenCL-Headers: Khronos OpenCL-Headers. Contribute to KhronosGroup/OpenCL-Headers development by creating an account on GitHub.
- OpenCL-Headers/CL/cl_dx9_media_sharing.h at main · KhronosGroup/OpenCL-Headers: Khronos OpenCL-Headers. Contribute to KhronosGroup/OpenCL-Headers development by creating an account on GitHub.
- OpenCL-Headers/CL/cl_d3d11.h at main · KhronosGroup/OpenCL-Headers: Khronos OpenCL-Headers. Contribute to KhronosGroup/OpenCL-Headers development by creating an account on GitHub.
- OpenCL-Headers/CL/cl_d3d10.h at main · KhronosGroup/OpenCL-Headers: Khronos OpenCL-Headers. Contribute to KhronosGroup/OpenCL-Headers development by creating an account on GitHub.
tinygrad (George Hotz) ▷ #learn-tinygrad (69 messages🔥🔥):
- George Hotz addresses recursive rewrite assert: A member asked about an assert in
uops graph_rewritewhich counts recursive rewrites. This assert ensures that recursive rewrites loop below a threshold to prevent infinite recursion.
- Gradient sync in
beautiful_mnist_multigpu.pysimplified: George Hotz confirmed that gradient synchronization is inherent in Tinygrad's optimizer. He emphasized the simplicity over Torch's Distributed Data Parallel.
- Tinygrad's goals to surpass PyTorch: George Hotz discussed Tinygrad's aim to outperform PyTorch in speed, API simplicity, and bug reduction. While currently slower, especially in LLM training, Tinygrad's purity and potential were highlighted by enthusiastic users.
- Mixed precision implementation discussion: A user sought advice from George Hotz on implementing mixed precision for a model, discussing various approaches including using
DEFAULT_FLOATandnnclass modifications. George suggestedcast_methods and late casting techniques for better efficiency.
- Kernel issues resolved: A user resolved kernel issues related to
remaindertensors not appearing in UOp graphs, learning that separaterealizecalls split operations into different kernels. Discussions highlighted the significance of realizing tensors appropriately to meet custom accelerator requirements.
Link mentioned: Creation - tinygrad docs: no description found
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
- Introducing GPT Notes app: A member showcased a hybrid application combining an LLM client and notes app, allowing users to dynamically include/exclude notes into the LLM's context. The project, built without using any JS libraries, offers features like import/export, basic markdown, and responses management.
- No mobile support, pure vanilla JS: Despite lacking mobile support, the app boasts of no reliance on libraries, purely built with vanilla JavaScript. It includes functionalities like storing API keys, history, and notes locally in the browser.
- Explore the app on Codepen: The member provided a Codepen link for the project and a deployed fullscreen app. The application serves as an example for anyone looking for a similar tool.
Link mentioned: GPNotes: no description found
OpenRouter (Alex Atallah) ▷ #general (68 messages🔥🔥):
- OpenRouter Errors without User Messages Sparking Debate: Users discussed the issue of OpenRouter returning errors if no user message is found, noting that some models require at least a user message as an opener, and even starting with an assistant is not supported by every model due to their instruct-tuned format. A suggested workaround was using the
promptparameter instead ofmessages(OpenRouter Docs).
- Document Formatting and Uploading Puzzles Users: A user inquired about services for formatting text into structured "papers," leading to a broader discussion on document formatting and uploading. The conversation highlighted the complexity of making PDFs LLM-friendly, with suggestions to preprocess PDFs using tools like PDF.js and Jina AI Reader.
- Qwen2's Censorship Criticized: Users shared their experiences with the Qwen2 model, labeling it as overly censored despite jailbreak attempts, evidenced by implausibly positive narrative outcomes. Alternative, less-censored models like Dolphin Qwen 2 were recommended.
- Gemini Flash's Context Limit Debate: A discrepancy in Gemini Flash's token generation limits prompted questions, with OR listing 22k tokens while Gemini Docs claimed 8k. It was clarified that OR counts characters to match Vertex AI's pricing model (OpenRouter Status).
- Rate Limits and Model Configuration Questions Arise: Users inquired about rate limits for models like GPT-4o and Opus, leading to guidance on checking rate limits via API keys (OpenRouter Rate Limits). Also, discussions about maximizing model performance and configuration settings like "Sonnet from OR vs Sonnet with Claude key" and "LiteLLM vs OR Routing" unfolded, emphasizing custom retry options and API call efficiency.
- Google: Gemini Flash 1.5 (preview) – Provider Status and Load Balancing: See provider status and make a load-balanced request to Google: Gemini Flash 1.5 (preview) - Gemini 1.5 Flash is a foundation model that performs well at a variety of multimodal tasks such as visual u...
- Limits | OpenRouter: Set limits on model usage
- Reader API: Read URLs or search the web, get better grounding for LLMs.
- Transforms | OpenRouter: Transform data for model consumption
OpenRouter (Alex Atallah) ▷ #일반 (1 messages):
is.maywell: <:a6adc388ea504e89751ecbbd50919d3a:1240669253699637339>
LangChain AI ▷ #general (48 messages🔥):
- TextGen Integration in LangChain Broken: A member reported that textgen integration into LangChain is broken due to an API update.
- Best Splitter for Chunking Textbook PDFs: A member asked for advice on the best splitter to use for chunking PDF text according to headers and chapters, aiming to structure the text better.
- LangChain Postgres Installation Trouble: Users exchanged advice about installing langchain_postgres, with a solution involving correcting the targeted directory for
pip install. - Module Error with New Tenacity Version: A user encountered a ModuleNotFoundError for 'tenacity.asyncio' following an update to version 8.4.0, but found reverting to version 8.3.0 resolved the issue.
- Help for New LangChain Users: Multiple users sought guidance on implementing specific models or error handling in LangChain, including transitioning from Python code to LangChain JS, managing HuggingFace models, and recommended LLMs like Llama 3 or Google Gemini for local use. A relevant discussion was linked here.
- no title found: no description found
- no title found: no description found
- How to build a chatGPT chatbot on Slack: Welcome to this tutorial video on creating a Slack chatbot using the OpenAI language model, LangChain, and the Slack Bolt library. This video will showcase t...
- Vaios Laschos on Instagram: "This is the promotional video for the app that I create for Generative AI Agents Developer Contest by NVIDIA and LangChain. #NVIDIADevContest #LangChain @nvidiadeveloper For demo video, see: https://www.youtube.com/watch?v=9mMbQpofiJY The app makes the life of academics easier by automating some tedious jobs like retrieving files from arxiv, making summaries and performing context based translation. Future goal is to make a paper survey out of a single paper. If you feel like in need for some punishment. Check my git repo https://github.com/artnoage/Langgraph_Manuscript_Workflows": 72 likes, 1 comments - vaioslaschos on June 16, 2024: "This is the promotional video for the app that I create for Generative AI Agents Developer Contest by NVIDIA and LangChain....".
- Blowing Kisses Gratitude GIF - Blowing kisses Kisses Kiss - Discover & Share GIFs: Click to view the GIF
- How to properly provide the input schema to the model · langchain-ai/langchain · Discussion #22899: Checked other resources I added a very descriptive title to this question. I searched the LangChain documentation with the integrated search. I used the GitHub search to find a similar question and...
LangChain AI ▷ #share-your-work (14 messages🔥):
- R2R adds automatic knowledge graph construction: R2R v2 now includes automatic knowledge graph construction along with a comprehensive cookbook that walks through basic and advanced features. "This should make a great (and up to date) starting point If you are interested in KGs."
- Collision event interactive map launched: Eloquentsyntax announced an interactive map for Collision parties and events. The map includes filters, door fees, addresses, RSVP links, and an AI chat to find events easily.
- CryptGPT: Privacy-Preserving LLMs using Vigenere cipher: Diwank introduced CryptGPT, a project that pretrains a GPT-2 model on Vigenere ciphertexts, ensuring privacy from the model provider. The unique feature is that usage requires knowledge of the encryption key.
- Scrape Web + Create diagrams with GPT: Ashes47 shared a project from user Anuj4799, who created a custom GPT for generating technical diagrams. The demo can be checked out here.
- Rubik's AI beta tester and promo: Paulm24 invited users to beta test an advanced research assistant and search engine, offering a 2-month free premium with models like GPT-4 Turbo and Claude 3 Opus using the promo code
RUBIX. Interested users are encouraged to sign up at Rubik's AI.
- no title found: no description found
- Tweet from Anuj Verma (@Anuj4799): So I was having a tough time with generating technical diagrams, and I ended up creating a custom GPT to handle it for me. Now, I'm loving the ease and efficiency! Check it out: https://chat.opena...
- Tweet from Diwank Singh (@diwanksingh): http://x.com/i/article/1802116084507848704
- R2R Documentation: The official documentation for the RAG to Riches (R2R) framework.
- Appstorm.ai: Generative AI for Effortless App Development: no description found
- Rubik's AI - AI research assistant & Search Engine: no description found
LangChain AI ▷ #tutorials (1 messages):
emarco: https://www.youtube.com/watch?v=0gJLFTlGFVU
Latent Space ▷ #ai-general-chat (21 messages🔥):
- OtterTune is no more: OtterTuneAI officially shut down after a failed acquisition deal. The announcement was shared on Twitter.
- Check out Apple's models on Hugging Face: Apple has published several models optimized for on-device performance on Hugging Face, including DETR Resnet50 Core ML for semantic segmentation and Stable Diffusion Core ML.
- OpenAI under fire for appointing former NSA head: Edward Snowden criticized OpenAI’s decision to appoint former NSA Director Paul M. Nakasone to its board, calling it a betrayal of public trust.
- Runway releases Gen-3 Alpha video model: Runway introduces Gen-3 Alpha, a new model for video generation with advanced features. Details were shared on Twitter.
- Anthropic research on reward tampering: Anthropic publishes a new paper on AI models learning to hack their reward systems. The research and its findings are summarized in their blog post.
- Flo Crivello on Building Lindy.AI: no description found
- Tweet from Anthropic (@AnthropicAI): New Anthropic research: Investigating Reward Tampering. Could AI models learn to hack their own reward system? In a new paper, we show they can, by generalization from training in simpler settings. ...
- apple (Apple): no description found
- Tweet from Buck Shlegeris (@bshlgrs): ARC-AGI’s been hyped over the last week as a benchmark that LLMs can’t solve. This claim triggered my dear coworker Ryan Greenblatt so he spent the last week trying to solve it with LLMs. Ryan gets 71...
- Tweet from Air Katakana (@airkatakana): i’m calling the top, this company didn’t even do anything yet
- Tweet from Tom Goldstein (@tomgoldsteincs): LLMs can memorize training data, causing copyright/privacy risks. Goldfish loss is a nifty trick for training an LLM without memorizing training data. I can train a 7B model on the opening of Harry P...
- Tweet from Greg Brockman (@gdb): GPT-4o as an assistant for helping doctors screen and treat cancer patients: Quoting Othman Laraki (@othman) I'm thrilled to announce the @Color Copilot, which we developed in partnership with ...
- Tweet from Runway (@runwayml): Introducing Gen-3 Alpha: Runway’s new base model for video generation. Gen-3 Alpha can create highly detailed videos with complex scene changes, a wide range of cinematic choices, and detailed art di...
- Tweet from Andy Pavlo (@andy_pavlo@discuss.systems) (@andy_pavlo): I'm to sad to announce that @OtterTuneAI is officially dead. Our service is shutdown and we let everyone go today (1mo notice). I can't got into details of what happened but we got screwed ove...
- Tweet from François Chollet (@fchollet): Re: the path forward to solve ARC-AGI... If you are generating lots of programs, checking each one with a symbolic checker (e.g. running the actual code of the program and verifying the output), and ...
- Tweet from Buck Shlegeris (@bshlgrs): ARC-AGI’s been hyped over the last week as a benchmark that LLMs can’t solve. This claim triggered my dear coworker Ryan Greenblatt so he spent the last week trying to solve it with LLMs. Ryan gets 71...
- Tweet from Edward Snowden (@Snowden): They've gone full mask-off: 𝐝𝐨 𝐧𝐨𝐭 𝐞𝐯𝐞𝐫 trust @OpenAI or its products (ChatGPT etc). There is only one reason for appointing an @NSAGov Director to your board. This is a willful, calculat...
- Flo Crivello on Building Lindy.AI | annotated by Daniel: AI Agents are a new category of software, built on top of large language models (LLMs).
Latent Space ▷ #ai-in-action-club (20 messages🔥):
- Prime Intellect set to open source DiLoco and DiPaco: Users discussed how Prime Intellect plans to release state-of-the-art models DiLoco and DiPaco soon, enhancing open collaboration. One member shared a Prime Intellect link detailing how the platform democratizes AI through distributed training across global compute resources.
- Bittensor utilizes The Horde: Users mentioned that The Horde, known for distributing computational tasks, is being utilized on the Bittensor network for decentralized AI model training.
- DeepMind did not participate: Contrary to some expectations, it was clarified that DeepMind did not contribute to specific ongoing projects in the community discussion.
- YouTube video on Optimizers: Members shared a YouTube video about optimizers, explaining various types from Gradient Descent to Adam. It offered an easy way to remember different optimizers for effective model training.
- ChatGPT's multi-step responses: A discussion centered around how ChatGPT formulates multi-step responses, clarifying that different transformer blocks can be processed separately. This sparked interest and questions about specific parallelizations within transformer layers.
- Prime Intellect - Commoditizing Compute & Intelligence: Prime Intellect democratizes AI development at scale. Our platform makes it easy to find global compute resources and train state-of-the-art models through distributed training across clusters. Collec...
- Optimizers - EXPLAINED!: From Gradient Descent to Adam. Here are some optimizers you should know. And an easy way to remember them. SUBSCRIBE to my channel for more good stuff! REFER...
Cohere ▷ #general (20 messages🔥):
- Debate on AGI Hype: A user shared a YouTube video titled "Is AGI Just a Fantasy?" featuring Nick Frosst, spurring discussions about the hype, real tech advancements, and evaluation of LLMs. Members expressed fatigue over "hype bros" but acknowledged the importance of ongoing investment, likening it to the dot-com bubble that led to significant innovations.
- Call for Next.js App Router Collaboration: A member announced the creation of a GitHub issue inviting collaboration on migrating the Cohere toolkit UI to Next.js App Router to improve code transferability and attract more contributors. The GitHub issue #219 contains more details about the feature request.
- C4AI Talk Link Shared: Nick Frosst provided a Google Meet link for the C4AI talk and directed members with questions to the relevant Discord channel.
- Interest in Contributing Data for Training: A user inquired about submitting 8,000 PDFs for embedding model training with Cohere. Nick Frosst sought clarification if the user intended to fine-tune an embedding model, opening a discussion on potential data contributions.
- Is AGI Just a Fantasy?: Nick Frosst, the co-founder of Cohere, on the future of LLMs, and AGI. Learn how Cohere is solving real problems for business with their new AI models.Nick t...
- any plans to migrate to nextjs app router? · Issue #219 · cohere-ai/cohere-toolkit: What feature(s) would you like to see? hi, fantastic toolkit and project to get started quickly. i was wondering if there is any plan to migrate it to the app router. most (if not all) of new nextj...
- Join the Cohere For AI Discord Server!: Cohere For AI's Open Science Community is a space to come together to work on machine learning research collaborations. | 3016 members
Cohere ▷ #project-sharing (11 messages🔥):
- Cohere models integrate into Chrome for free: A member announced a free Chrome Extension that integrates LLMs directly into the browser, eliminating repetitive tasks and enhancing productivity. Users are encouraged to provide feedback and can configure it with detailed instructions provided.
- Interactive Collision map launched: Another member created an interactive map of all Collision events, allowing users to filter by event details and access AI chat for easier navigation. It utilizes Sveltekit, Supabase, and Vercel for its build.
- Command R+ configuration issue resolved: A user experienced issues configuring Command R+ with the Cohere-powered extension but received help to rectify it by using a Blank Template first. The developer acknowledged the bug and plans to fix it.
- Inquiry about Cohere data submission: A user inquired if Cohere accepts data submissions for training, specifically mentioning they have nearly 8,000 PDFs for embedding model training.
- no title found: no description found
- Ask Steve - Unlock the Power of ChatGPT and Gemini in any web page!: Ask Steve adds AI superpowers from ChatGPT & Gemini to any web page, so you can get your everyday tasks done better and faster. FREE!
- Configuring Ask Steve to use Cohere Command R+: Configuring Ask Steve to use Cohere Command R+ You will need to login to Ask Steve in order to add a new model: chrome-extension://gldebcpkoojijledacjeboaehblhfbjg/options.html After logging in, go to...
Cohere ▷ #announcements (1 messages):
- David Stewart to host Cohere Developer Office Hours: A relaxed session is scheduled for tomorrow, hosted by David Stewart, a seasoned Solution Architect at Cohere. Members are encouraged to post their questions and issues on this thread to get prioritized during the event.
- Event details released: The Office Hours event will take place on June 18, at 1:00 PM ET. Join the event here for live interaction and guidance on Cohere API and model-related queries.
Link mentioned: Join the Cohere Community Discord Server!: Cohere community server. Come chat about Cohere API, LLMs, Generative AI, and everything in between. | 17098 members
OpenInterpreter ▷ #general (14 messages🔥):
- Model freezes mid-code: One member inquired if others were experiencing their model freezing while in the middle of coding. Another member replied that it usually completes the task even when it looks frozen.
- Windows installation issues: A user reported issues with installing and running the model on Windows. They were advised to search for help and post their query in a designated channel.
- Memory functionality improves: A member expressed satisfaction with getting memory to work in a "very primitive way." They enthusiastically shared their progress with the community.
- Llama 3 Performance Review: A detailed model comparison and performance test for Llama 3 was shared, promising a comprehensive assessment of Llama 3 Instruct's capabilities across various formats and quantization levels.
- Profiles functionality feature: A new 'profiles' feature on Open Interpreter was highlighted. A member shared a video to explain its capabilities and applications.
- Tweet from Thomas Smith (@tx_smitht): If you don't know about Open Interpreter's new "profiles" functionality, you need to check it out! It lets you extend OI's capabilities. It's like uploading a specific set of...
- Reddit - Dive into anything: no description found
OpenInterpreter ▷ #O1 (4 messages):
- Check your unit arrival in pinned messages: A user asked how to check when their unit is arriving, mentioning they placed an order very early. Another member redirected them to a pinned message in the channel for manufacturing updates and timelines.
- Discuss combo of vector DB, semantic search, and LLM: A question was raised about the potential of combining a vector database of audio with voice-based semantic search and indexing, alongside an LLM capable of accessing this data and performing actions. The proposed combination hints at a powerful tool for actions based on verbal inputs.
OpenInterpreter ▷ #ai-content (6 messages):
- DIY AI Cyber Hat turns heads: A member shared their project on making an open-source AI-enabled wearable hat, likening it to smart glasses. They provided a video preview and expressed openness for collaboration, view the video here.
- Terminator humor on hat design: One member humorously remarked that the hat design made the creator look like a terminator sent to eliminate the founder of Hobby Lobby.
- Interest in sci-fi wearables sparks engagement: People showed enthusiasm for the AI hat project, requesting access to the source code once it's cleaned up. The creator suggested possible future integration of more sensors for scientific experiments.
- Pi Zero heads to Big Mouth Billy Bass: The same creator teased their next project involving integrating a Pi Zero in a Big Mouth Billy Bass.
- Dream Machine generates buzz: A member shared Dream Machine, an AI model that creates high-quality, realistic videos from text and images. The model aims to build a universal imagination engine and is now available to the public.
- Luma Dream Machine: Dream Machine is an AI model that makes high quality, realistic videos fast from text and images from Luma AI
- I Made My Own Custom AI Cyber Hat: This is a video about the start of a project of mine that I've called "heddy" (the hat portion at least). I created my own smart AI enabled hat largely thro...
Torchtune ▷ #general (7 messages):
- Single node focus for now in Torchtune: When asked if Torchtune plans to release multi-node training, a member clarified that the focus is currently on single node training. However, they noted that "our ‘tune run’ command is a wrapper around torch run" and with minor changes, multi-node setups could work, although it's untested.
- Distributed config adjustments for multi-node training: Members exchanged tips on setting up multi-node training in Torchtune. One suggested setting
tune run —nnodes 2, while another mentioned the need forTorchXorslurmto handle script launches and node communications over specific ports, pointing to resources like TorchX and hybrid shard strategy documentation.
Link mentioned: FullyShardedDataParallel — PyTorch 2.3 documentation: no description found
DiscoResearch ▷ #discolm_german (5 messages):
- Llama3 tokenizer remains unchanged: Members discussed whether the Llama3 tokenizer was extended for the German model. One member confirmed that "tokenizer is the same as the base Llama3".
- Concerns about German token handling: A member questioned the rationale behind not extending the tokenizer, noting that not including German tokens probably decreases the context window quite a bit. They were curious if they were missing any reasoning, especially considering the potential increases in embeddings.
- Size comparison with Llama2: Another member pointed out that Llama3's tokenizer is 4 times larger than Llama2's. They inquired whether it was already more effective on German or if there were still issues.
Datasette - LLM (@SimonW) ▷ #ai (3 messages):
- Alternative Positions in AI Discussions Praised: One member appreciated another's writing for "addressing the alternative position in good faith". They humorously noted that ChatGPT's rise is "a full employment act for data engineers in perpetuity".
- Thoughtbot's LLM Guide Shoutout: A member highlighted a useful thoughtbot resource for beginners in LLMs. They recommended reading Jose Blanco's post on using open-source LLMs locally and remotely.
- Clarity in Naming Conventions for LLMs Appreciated: Another member found the categorization of LLMs into Base, Instruct, and Chat models particularly clear and detailed.
Link mentioned: Understanding open source LLMs: Do you think you can run any Large Language Model (LLM) on your machine?
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
- Turso adds native vector search support: Turso has introduced native vector search capabilities to their platform, supplementing SQLite’s existing features. This new addition aims to simplify vector search for users building AI products, addressing previous challenges with managing extensions like sqlite-vss.
Link mentioned: Turso brings Native Vector Search to SQLite: Vector Similarity Search is now available!
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (1 messages):
gomiez: anyone know of the hospital ai town project name?
Mozilla AI ▷ #llamafile (1 messages):
cryovolcano.: can we use llamafile with tinyllama as a search engine in firefox ?