
|
|
MODEL
MAJOR
2026-06-24
Gemini 3.5 Flash gets Computer Use — native browser, mobile, and desktop agents
Gemini 3.5 Flash can now see a screen and click, type, and scroll on its own through a single built-in tool.
What is it?
Computer Use is now a first-class tool on Gemini 3.5 Flash, so the same Flash model that handles chat and coding can now drive a browser, an Android phone, or a desktop without a separate model.
How does it work?
The tool takes screenshots from the target environment, returns a structured action (click, type, scroll, swipe) plus an intent field explaining each step, and loops until the task is complete via the Gemini API or Gemini Enterprise Agent Platform.
Why does it matter?
Enterprise teams no longer have to stitch a planning model and a separate computer-use model together — one API call now handles long-horizon work like software testing, form filling, and back-office automation. Google says this is its best performance yet on agentic computer-use tasks.
Who is it for?
Developers and enterprises building browser, mobile, or desktop agents.
|
|

|
|
ECOSYSTEM
MAJOR
2026-06-24
OpenAI Jalapeño — first custom inference chip, built with Broadcom
OpenAI's first piece of custom silicon — an inference ASIC co-designed with Broadcom for cheaper, lower-power model serving.
What is it?
OpenAI Jalapeño is a custom inference ASIC built for serving large language models rather than training them — co-designed by OpenAI and Broadcom, manufactured by Celestica, with engineering samples already running GPT-5.3-Codex-Spark at target frequency and power.
How does it work?
The chip cuts data movement and rebalances compute, memory, and networking around the LLM inference loop, paired with Broadcom Tomahawk silicon for large-scale fabric. OpenAI used its own models to accelerate the nine-month design cycle.
Why does it matter?
Broadcom CEO Hock Tan cites roughly 50% cost savings versus typical AI GPUs on inference. OpenAI frames Jalapeño as the first step in an "Apple of AI" strategy — owning the full stack from chip to product — targeting deployment by end of 2026.
Who is it for?
OpenAI infrastructure teams and any developer relying on OpenAI inference economics.
|
|

|
|
ECOSYSTEM
MAJOR
2026-06-24
Qualcomm to Acquire Modular — $3.9B all-stock deal for Mojo and MAX AI stack
Qualcomm buys Modular for $3.9B, picking up a hardware-agnostic AI compiler stack aimed at Nvidia's CUDA moat.
What is it?
Qualcomm will acquire Modular in an all-stock deal worth ~$3.9B, taking ownership of the Mojo language and the MAX AI platform — built by LLVM/Swift creator Chris Lattner to compile AI models across CPUs, GPUs, and NPUs.
How does it work?
Up to 19.2 million Qualcomm shares go to Modular shareholders; the deal closes in H2 2026 pending regulatory approval. MAX compiles AI workloads to Nvidia, AMD, Intel, or Qualcomm hardware without a rewrite — the same model targets any chip.
Why does it matter?
Modular's mission was to break CUDA lock-in; putting MAX under a major chipmaker gives a silicon vendor full ownership of a portable AI software layer — though it also raises questions about whether a Qualcomm-owned Modular can remain truly hardware-neutral.
Who is it for?
AI infrastructure engineers, Mojo and MAX users, Qualcomm hardware customers, and Nvidia-alternative watchers.
|
|

|
|
SECURITY
MAJOR
2026-06-24
Anthropic accuses Alibaba Qwen of largest-ever Claude distillation attack
Anthropic tells U.S. senators that nearly 25,000 fake accounts tied to Alibaba's Qwen lab harvested 28.8M Claude conversations between April 22 and June 5, 2026.
What is it?
Anthropic's June 10 letter to U.S. Senate Banking Committee leaders accuses operators affiliated with Alibaba's Qwen division of running the largest known adversarial distillation campaign against Claude, using tens of millions of fraudulent API calls targeting its Mythos Preview model.
How does it work?
Close to 25,000 fake accounts generated 28.8M+ Claude conversations, concentrated on Mythos Preview's software-engineering and agentic-reasoning capabilities. Adversarial distillation trains a weaker model on a stronger model's outputs to copy its behavior without paying full training costs.
Why does it matter?
The operation dwarfs the combined ~16M-exchange campaigns Anthropic previously attributed to DeepSeek, Moonshot AI, and MiniMax. With U.S. senators now weighing further sanctions on Chinese firms extracting U.S. AI outputs, this signals potential policy and compliance fallout for anyone working with Chinese frontier labs.
Who is it for?
AI policy watchers, Anthropic API customers, and teams evaluating Qwen for production use.
|
|

|
|
TOOL
MAJOR
2026-06-23
GitHub Copilot app gets BYOK — Anthropic, Ollama, and LM Studio supported
GitHub Copilot's desktop app now talks to Anthropic, Ollama, LM Studio, and any OpenAI-compatible endpoint with your own API key.
What is it?
The GitHub Copilot app's BYOK feature lets you connect Copilot to model providers you already pay for: cloud (OpenAI, Azure OpenAI, Anthropic), enterprise gateways (any OpenAI-compatible HTTP endpoint), and fully local runners (LM Studio, Ollama, Foundry Local).
How does it work?
Paste an API key into Copilot app settings; it stores the secret in the OS credential store and never displays it in the UI. From then on Copilot routes prompts to that provider's endpoint, letting you mix frontier and local models across tasks.
Why does it matter?
Copilot users blocked by compliance or cost from sending code to GitHub-hosted models now have an official supported path — including running a fully local model on the same laptop. Anthropic Claude becomes a first-class Copilot backend without any proxy.
Who is it for?
Enterprises with key/provider restrictions, devs running local LLMs, and Anthropic API customers.
|
|
|
|
TOOL
MAJOR
2026-06-23
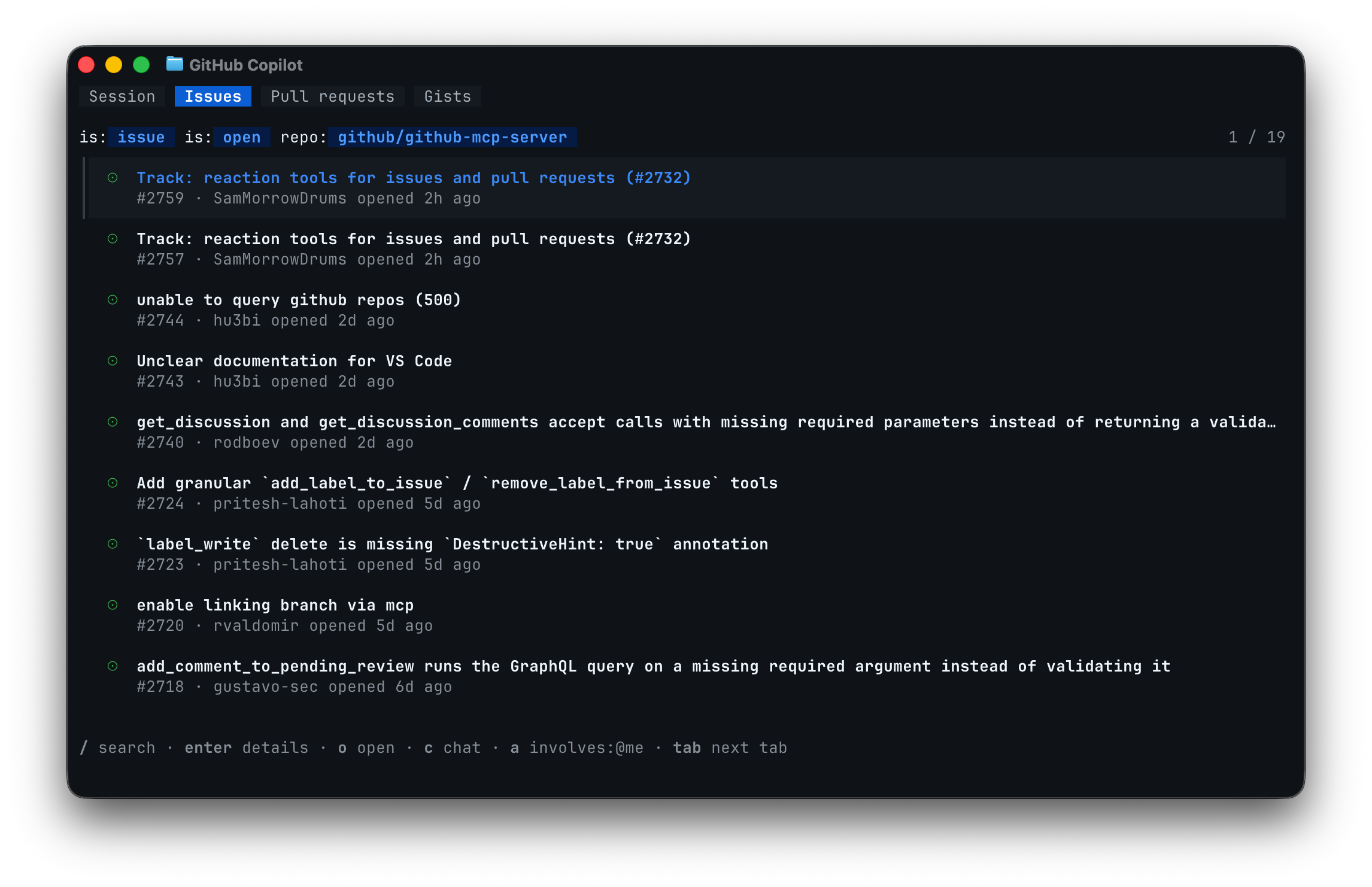
GitHub Copilot CLI GA — tabbed terminal with MCP, skills, and plugins
Copilot CLI's new tabbed terminal hits GA with Session, Issues, PRs, and Gists tabs plus in-session MCP, skills, and plugin commands.
What is it?
GitHub Copilot CLI's redesigned interactive terminal — previewed at Microsoft Build 2026 — is now generally available, opening inside any Git repository with four tabs: Session, Issues, Pull requests, and Gists.
How does it work?
Slash commands inside the live session handle everything: /mcp add wires up MCP servers, /skills and /plugin install tool packs, and the UI switches on screen-reader support automatically. Update with copilot update.
Why does it matter?
Copilot CLI users no longer drop out of the terminal to triage issues or edit a config file to add an MCP server — what used to be two or three context switches now stays in one place. Theme-aware colors and screen-reader support arrive without manual setup.
Who is it for?
GitHub Copilot CLI users who configure MCP servers, skills, or plugins from the terminal.
|
|
|
|
MODEL
MAJOR
2026-06-23
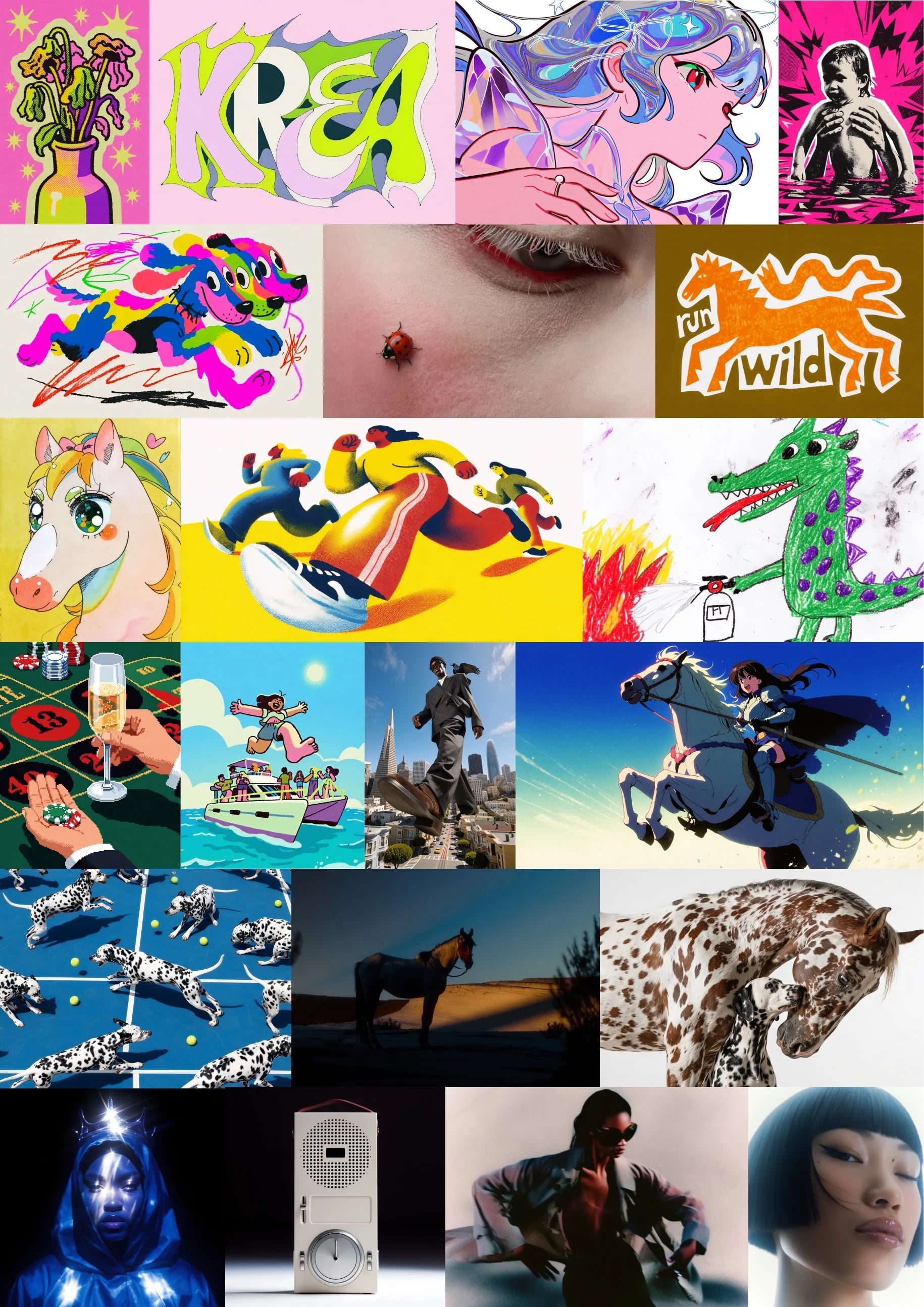
Krea 2 — open-weight 12B image model with 2-second Turbo variant
Krea AI open-sources a 12B Diffusion Transformer image model with a Turbo variant that draws 2K images in two seconds.
What is it?
Krea 2 is a 12B Diffusion Transformer trained from scratch for aesthetic-first text-to-image generation, published as two open-weight checkpoints: Krea 2 Raw (for LoRA fine-tuning) and Krea 2 Turbo, an 8-step distilled engine.
How does it work?
The 12B DiT backbone pairs with a Qwen3-VL text encoder using multi-layer feature aggregation. Krea 2 Turbo is distilled to 8 steps, reaching ~2 seconds per 2K image. Day-one support is live in ComfyUI, FAL, AWS, and GCP.
Why does it matter?
An independent lab shipping a 12B open-weight image model at 2 seconds per 2K image tightens the gap with proprietary APIs. Because Raw is published, studios can fine-tune Krea 2 for their own style without retraining from scratch.
Who is it for?
Image generation researchers, studios fine-tuning a base model, and ComfyUI workflow builders.
|
|
|
All releases at ai-tldr.dev
Simple explanations • No jargon • Updated daily
|
|