
|
|
ECOSYSTEM
MAJOR
2026-06-18
MCP Enterprise-Managed Authorization — zero-touch OAuth for Claude, VS Code, Linear
MCP's new Enterprise-Managed Authorization extension stabilizes — admins authorize MCP connectors once through Okta, users skip per-app OAuth.
What is it?
Enterprise-Managed Authorization (EMA) is an extension to the Model Context Protocol that just moved from draft to stable. EMA lets a company's identity provider — Okta at launch — grant access to MCP servers in bulk, scoped to user groups and roles. End users open Claude or VS Code, sign in once, and inherit every MCP connector their admin already approved without seeing an OAuth screen.
How does it work?
EMA leans on the Identity Assertion JWT Authorization Grant (ID-JAG) standard. During single sign-on, the MCP client receives an ID-JAG from the IdP and exchanges it for an access token at the MCP server, replacing the per-server consent screen. Admins enable specific MCP servers in the IdP, set group scopes, and audit usage through the same IdP logs they use for SaaS.
Why does it matter?
Per-user OAuth on every MCP server is the main reason MCP has not landed in regulated enterprises — security teams want a single audit log and a single revoke button. With EMA stable, an admin can plug an MCP server into Okta the same way they plug in any SaaS, and rollouts the size of Ramp's 2,000-employee deployment become routine.
Who is it for?
Enterprise IT, security teams, and MCP server maintainers who need centralized provisioning and auditing for AI tool access.
|
|

|
|
TOOL
MAJOR
2026-06-18
OpenAI Codex Record & Replay — demonstrate a macOS workflow, get a reusable skill
OpenAI Codex 26.616 lets you record a Mac workflow once, then replay it as a reusable agent skill.
What is it?
Record & Replay is a new feature in the OpenAI Codex desktop app, shipped in version 26.616. The user demonstrates a workflow on their Mac — clicks, typing, window switches — and Codex captures the actions and visible window content, then turns the recording into an inspectable, editable skill the agent can replay later.
How does it work?
After starting a recording, Codex watches both the actions taken and the surrounding window state, then synthesizes a skill the agent can run on its own. Each skill is editable after capture: prompts, branches, and action steps can be refined without re-recording. Record & Replay rides on top of Codex's existing Computer Use capability.
Why does it matter?
Codex pitches Record & Replay for tasks that are "easier to show than to describe" — filing an expense report, submitting a time-off request, running a recurring data export. Spelling those out in a prompt was the friction point that pushed many repetitive workflows out of Computer Use.
Who is it for?
macOS users of the Codex desktop app running Computer Use workflows. Note: not available in the EEA, UK, or Switzerland at launch.
|
|

|
|
SHOWCASE
MAJOR
2026-06-17
Midjourney Medical — full-body ultrasonic CT scanner, 60-second scan, SF spa in 2027
Midjourney spins up a hardware division and unveils a full-body ultrasound scanner inside a planned San Francisco spa.
What is it?
Midjourney Medical is a new division of Midjourney that builds Ultrasonic CT, a full-body ultrasound scanner. The first scanner takes about a minute to capture a 3D body image using sound waves in water — no radiation, no magnets — and will live inside the Midjourney Spa opening in San Francisco at the end of 2027.
How does it work?
The scanner uses 8,960 ultrasound transducers wrapped around 40 Butterfly Network ultrasound-on-chip modules. The patient descends into a shallow pool of water and passes through a ring of underwater sensors that fire sound waves through the body from every angle, producing a 3D full-body image in ~60 seconds.
Why does it matter?
Midjourney is the first major generative-AI company to ship a real hardware product. The spa-and-scan delivery model is unusual — Midjourney is selling scans direct to consumers rather than to hospitals, targeting 50,000 scanners and 1 billion scans per month by 2031.
Who is it for?
AI watchers tracking hardware bets from software companies, medical-imaging engineers, and consumer-health investors.
|
|

|
|
BENCHMARK
MAJOR
2026-06-17
LifeSciBench — OpenAI's 750-task benchmark for life-science research
OpenAI's new biology benchmark grades models with expert rubrics, and even GPT-Rosalind passes only one task in three.
What is it?
LifeSciBench is OpenAI's new evaluation suite for AI in life-science research. It contains 750 free-response tasks across seven biology workflows and seven domains, written by 173 PhD-level scientists from biotech and pharma — graded by rubric rather than multiple choice.
How does it work?
LifeSciBench grades model output with 19,020 expert-written criteria — about 25 per task — tracking a normalized rubric score and a task pass rate at the 70% threshold. About 53% of tasks include attached artifacts (figures, PDFs, sequence files, chemical structures) that models must read and interpret.
Why does it matter?
LifeSciBench gives biotech teams a hard, realistic yardstick for picking models to run scientific workflows. Even the strongest model, GPT-Rosalind, passes only 36.1% of tasks — and that drops to 28.1% when files are attached, revealing that artifact-handling is the field's main bottleneck.
Who is it for?
AI evaluation researchers, biotech and pharma teams deploying LLMs for scientific workflows, and anyone tracking the state of AI in biology.
|
|

|
|
TOOL
MAJOR
2026-06-16
Superpowers v6.0 — Jesse Vincent's agentic-skills framework, ~2x faster reviews
v6.0 makes Superpowers' subagent-driven review loop run twice as fast and burn half the tokens.
What is it?
Superpowers is a software-development methodology and skills framework for AI coding agents — 232k GitHub stars, MIT licensed. It ships composable skills plus an instruction layer that steers the agent through brainstorm, plan, TDD implementation, and review.
How does it work?
Version 6.0 dispatches one reviewer per task instead of two, with that reviewer returning both spec-compliance and quality verdicts at once. Diffs and task text now move as files rather than inline text, cutting context cost. The controller must explicitly pick a model for every dispatch, blocking silent upgrades to a more expensive tier.
Why does it matter?
Superpowers users running Claude Code or Codex through the framework now get the same review quality at roughly twice the speed and ~50% lower token spend. The release also lands first-class harness support for Kimi Code, Pi, and Antigravity.
Who is it for?
Developers using Claude Code, Codex, Cursor, or any of the 11+ supported coding agents who want structured, subagent-driven code review.
|
|

|
|
ARTICLE
NOTABLE
2026-06-17
Simon Willison: GLM-5.2 is probably the most powerful text-only open weights LLM
Simon Willison ranks GLM-5.2 as today's top open-weights text LLM — frontier-class scores at roughly a quarter of GPT-5.5's price.
What is it?
Simon Willison argues that Z.ai's GLM-5.2 — a 753B-parameter Mixture-of-Experts model, MIT licensed, 1M-token context — is currently the strongest text-only open-weights LLM. It tops Artificial Analysis Intelligence Index v4.1 at score 51 and sits second on Code Arena's WebDev leaderboard behind only Claude Fable 5.
How does it work?
Willison runs GLM-5.2 through OpenRouter at ~$1.40/$4.40 per million input/output tokens — well below GPT-5.5's $5/$30. He notes one catch: GLM-5.2 uses ~43k output tokens per task vs 26k for GLM-5.1, which dents cost savings on long agent runs.
Why does it matter?
GLM-5.2 closes most of the gap to the closed frontier on coding and general intelligence at a quarter to a sixth of the price. Willison's framing sets the open-weights conversation: GLM-5.2 is now the default candidate for "self-host or cheap API."
Who is it for?
AI engineers comparing open-weights models, OpenRouter and self-host users, and cost-sensitive teams evaluating alternatives to closed frontier models.
|
|
|
|
TOOL
NOTABLE
2026-06-17
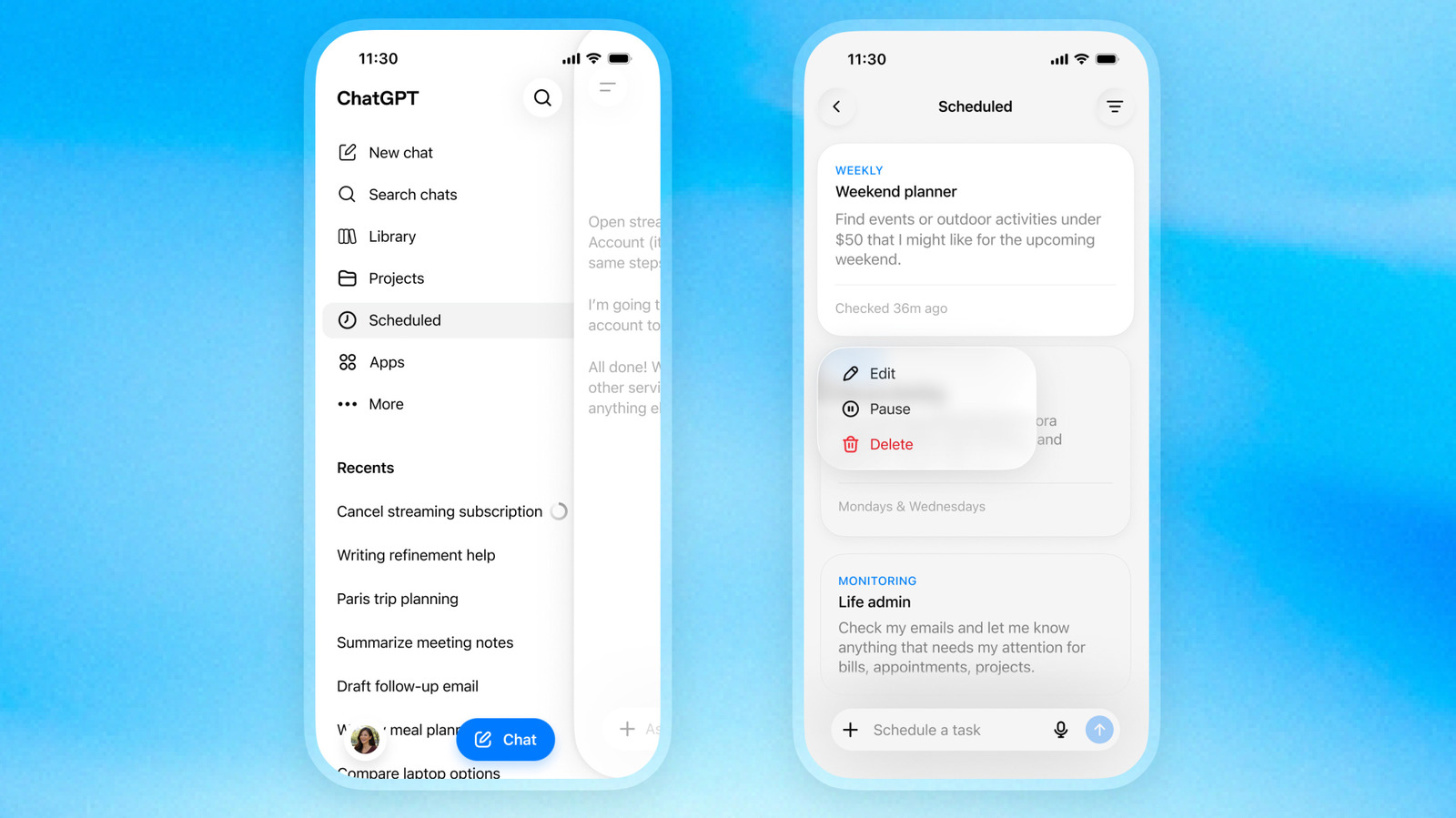
ChatGPT Scheduled Tasks Hub — sidebar page replaces Pulse
ChatGPT moves scheduled prompts into a single sidebar Scheduled page and retires Pulse in 14 days.
What is it?
ChatGPT Scheduled Tasks is OpenAI's redesigned home for recurring prompts inside ChatGPT. A new Scheduled page in the sidebar lists every active task with its next run time and lets users pause, resume, edit, or delete it without scrolling through chat threads.
How does it work?
Scheduled Tasks runs each saved prompt on its own cadence — a specific time or a window like morning, afternoon, or evening — capped at once per hour. Monitoring tasks can search the web and check connected apps, notifying users only when something material changes.
Why does it matter?
Scheduled Tasks pulls automated ChatGPT work out of buried chat threads and into a managed surface. The launch also retires Pulse, OpenAI's earlier proactive-summary feature, which sunsets in 14 days.
Who is it for?
ChatGPT Go, Plus, Pro, Business, and Enterprise subscribers running daily or weekly automations and monitoring tasks.
|
|
|
All releases at ai-tldr.dev
Simple explanations • No jargon • Updated daily
|
|