Increasing success using verified LLM prompt iteration
Here I look back at the last 14 months building my RebelAI leadership community and I'll talk on a technique I used in last year's ARC-AGI-1 (AKA ARC AGI 2024) LLM competition that uses iteration and feedback to boost success rates on a hard problem.
PyDataLondon 2025 will run this June, the call for proposals closes in a few weeks. All going well the 3rd edition of our High Performance Python book will be ready for signing at the conference and Micha will be along with me for some sort of discussion session.
New job Co-founder - Experienced Full-Stack developer, agentic architecture lead is listed at the end of this post, an exciting opportunity for one of you?
RebelAI a year in review
I founded my RebelAI private leadership group in November 2023. I've been strategically helping build great teams as an interim head of DS for years with some brilliant outcomes, but then I move on and leave behind a great group.
I wanted to gather excellent leaders together to help us collectively do better with our data science teams. We started as a group of 10, in a few weeks we'll be 30.
Looking back at the last year we've run:
- 20 "crits" where a member presents a problem on Zoom and we pull it apart and build a set of next-steps based on collective experience
- reviews on "what happened next" to learn on the outcomes of our advice
- each week we have a Slack discussion digging into a wide variety of questions
- 7 pub meets building IRL bonds between members (the most recent being last week)
- a great side-of-conference dinner at PyDataLondon 2024, we'll do that again alongside PyDataLondon 2025
Looking at some of our sessions members have been able to:
- redefine their DS strategy with their CxO suite
- approach hiring and restructuring with better and smoother plans
- tackle overload, in part by recognising success and making it visible
- figure out "which of these metrics are actually useful" and communicate this to the right people in their org
- debug and redefine failing DS projects
"Ian’s leadership of RebelAI has been a great support for me as I transitioned from a technical role to leadership. The community he’s built provides a space for AI and data science leaders to share challenges and ideas. It’s been reassuring to see that many of the issues I’ve faced are common, and learning from others’ experiences has been really helpful. Ian’s work in creating this space has definitely contributed to my growth as a leader." - Paola
Currently we stretch across insurance, financial services (investment banking, private equity, public banking), education, automotive, construction, marketing, retail and healthcare from startup through to some of the largest players in their domains. A mix like this perhaps "shouldn't work" - but it quite clearly does. I'm dead proud of what we've built in 2024 and where we're taking it in 2025.
This year I want to double the group's size, and perhaps spread from solely data science leadership to include data engineering leaders and just maybe a few ICs who will be or have been leaders. Maybe this sounds like you?
It is for excellent data scientists turned leaders who'd like a safe private space to ask questions from a trusted peer group. If that's you, reach out and I'll tell you more.
ARC AGI additional result
Building on the notes I posted back in August (so far back!) I had a second result to share which drives the LLM to learn from its output via automated feedback in a loop.
The tl;dr is that by prompting in an iterative loop, evaluating the results on each loop and providing feedback - the machine is more likely to keep improving the quality of its answer. You get "success" faster than if you blindly keep sampling from a single prompt.
Back in August this felt like a fab idea (and indeed it was). Having seen the release of GPT o3 with inference-time search and now DeepSeek r1 with similar, my thinking from August feels like the past. How quickly things are changing!
The underlying idea is still valid, indeed I'm using variations of this thinking on client work to improve the outcomes we get from LLMs, so I'll give a short recap.
You can check the slides (below) for more details. This is for the ARC-AGI-1 challenge (AKA ARC AGI 2024 or "ARC AGI"). You need to get a system (Llama 3.0 8/70b for me) to solve never-seen-before logic puzzles. I did this by getting it to write Python code.
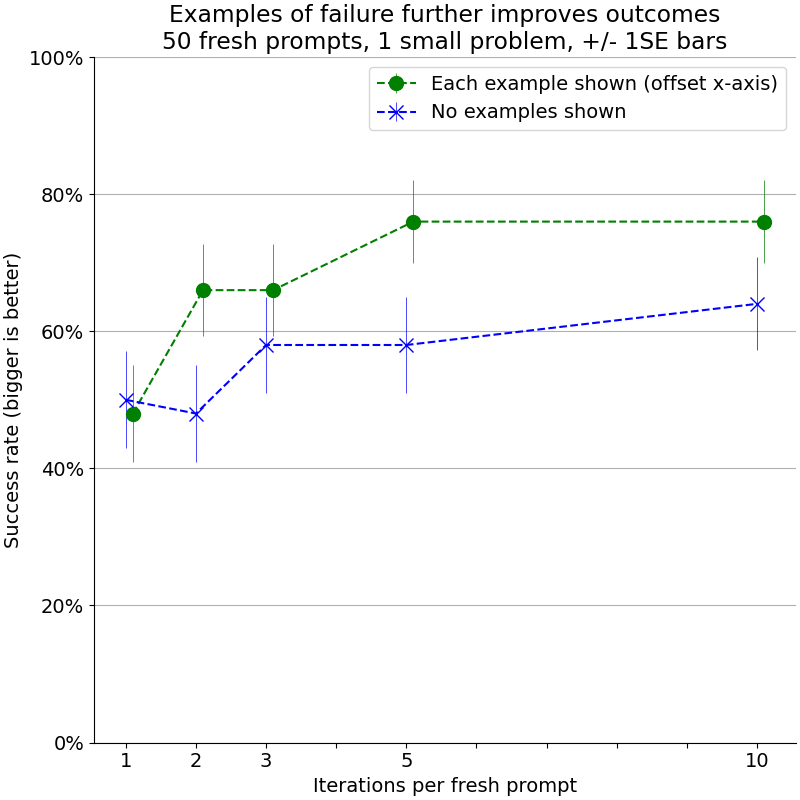
My observation (also shown on this slide, building from this slide) for the above two results was that:
- a single run of a prompt (no history i.e. "1 iteration") generated a solution that ran correctly "some of the time" (about 54% of the time in the graph above for blue)
- if I took a failed solution and told it (blue line) "here's your previous solution, it doesn't work, do better" and then iterated up to 10 times (x-axis), the success rate rose (for blue to about 65% of the time) - if I'd sampled 10* as many single-iteration prompts, I'd still be at a 54% good solution rate
- if I took the same failed solution and told it (green line) "here's your solution, specifically this example failed like this, but this next example succeeded like this - now do better" and iterated up to 10 times - it did even better!
For the green variant where I give it more detailed feedback on a case by case basis, after 5 iterations the success rate was closer to 75%. I'd come across papers suggesting that feedback could be useful but this was the first time I'd really drilled into the payoff that could be generated.
This technique is likely to be just as valid with current LLMs if you've got a verifier that can check your results.
In the above image the error bar is 1 standard error around 50 iterations of the slower/better Llama 3.0 70b Q4 model I was running.
The results are in these slides which I gave at PyDataLondon's meetup in November and then at the PyDataGlobal conference in December.
Relevant papers include Inference Scaling fLaws: The Limits of LLM Resampling with Imperfect Verifiers (Dec 2024) which notes "10 or fewer samples with a verifier is optimal" which mirrors my earlier discovery and Self-Refine: Iterative Refinement with Self-Feedback (2023) which talks on using a set of LLMs to propose, critique and refine solutions (but without an external verifier as I've used) - but again focusing on inference-time iteration.
The ARC-AGI-1 Technical Report (published a few weeks back) details the 2 main strategies people used - either a code-writing LLM or a transductively taught model (which solves the challenge without producing code). The idea of inference-time iteration and search is discussed as it was used by others. Links for papers are on the competition results page.
Sidenote - I'm highly motivated to take part in the upcoming ARC-AGI-2 (2025) challenge - if you are too, please drop me a line by replying to this.
Now some jobs…
Jobs are provided by readers, if you’re growing your team then reply to this and we can add a relevant job here. This list has 1,700+ subscribers. Your first job listing is free and it'll go to all 1,700 subscribers 3 times over 6 weeks, subsequent posts are charged.
Co-founder - Experienced Full-Stack developer, agentic architecture lead
At Trajex, we are building a first in class pocket CFO (Chief Financial Officer) for small business owners who are priced out of accessible, 24/7 financial scenario analysis and strategic guidance. We're a team of passionate and innovative engineers, researchers, and industry experts dedicated to pushing the boundaries of AI technology to financially empower small business owners and entrepreneurs. We're looking for an exceptional Full-Stack Developer to join our team as technical co-founder and help design, develop, and deploy an agentic architecture that meets the highest standards of quality, reliability, and performance. The ideal candidate will have prior experience in product and team leadership, the ability to produce high-quality, clean, scalable code, and an interest in joining an early-stage start-up to work on cutting-edge AI projects and technologies. Trajex is Oxford based, and the position is remote with regular meetings in Oxford and Central London.
- Rate: Equity + up to £120k
- Location: Remote. Regular meetings in Oxford and Central London.
- Contact: sev@trajex.ai (please mention this list when you get in touch)
- Side reading: