30 Days of Vibe Coding - Day 16 - Tic-Tac-Toe: Evolved
A tic-tac-toe game where the AI opponent learns from every match using Q-learning, getting smarter in real-time.
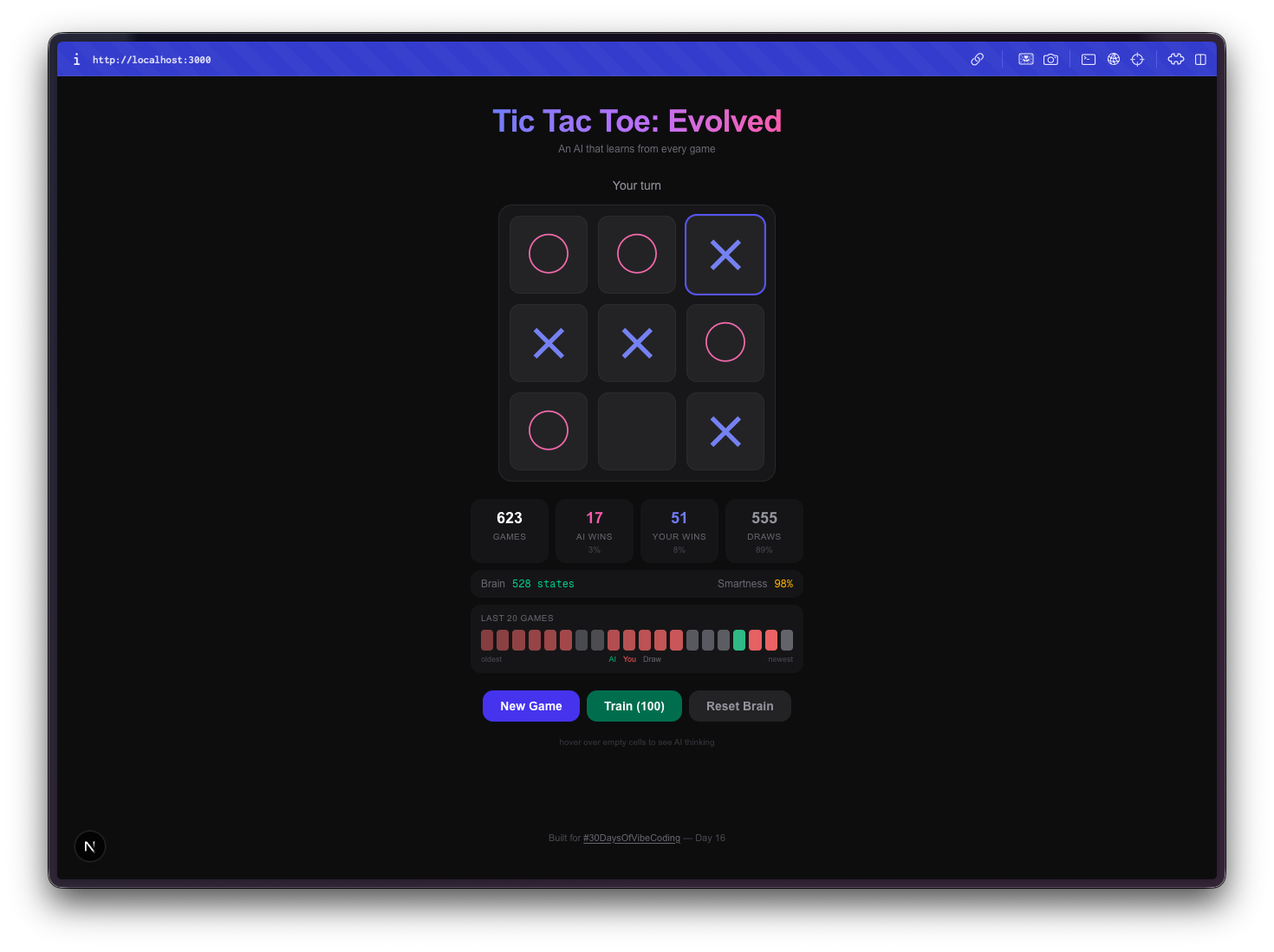
A tic-tac-toe game where the AI opponent learns from every match using Q-learning, getting smarter in real-time.
Day 16. What if the AI opponent actually learned from losing to you?
Not a minimax algorithm that plays perfectly from the start. Not a random mover. Something that starts dumb, watches what works, and gradually figures out how to beat you. That's Q-learning. And that's what I wanted to build into the simplest game possible.
The Prompt
> "Build a tic-tac-toe game with a Q-learning AI that learns from every game, persists its brain to localStorage, and shows real-time stats"
Try out the game yourself here
How It Was Built
Watchfire broke this one into 4 tasks:
1. Scaffold the Next.js project with the basic game board and layout
2. Q-learning AI with an epsilon-greedy strategy and localStorage persistence for the Q-table
3. Stats dashboard, AI brain visualization, and a training mode for bulk self-play
4. Difficulty modes, winning move highlights, sound effects, and final polish
The first task gave me a playable tic-tac-toe game. Nothing special. The second task is where things got interesting, because now the AI was actually updating state-action values after every game. Win a game against it, and it adjusts. Beat it the same way twice, and it starts blocking that move. The Q-table grows with every match.
Tasks 3 and 4 turned it from a learning experiment into something you can actually watch evolve. The brain visualization shows Q-values for each cell, the stats dashboard tracks win/loss/draw rates over time, and the training mode lets you run thousands of self-play games to fast-forward the AI's education.
What I Got
The AI starts terrible. Your first few games, it plays almost randomly. It picks squares with no strategy, falls for the same traps, loses in obvious ways. This is the whole point. It's exploring the game space, trying moves it hasn't tried before, building up its Q-table from scratch.
Then it stops being terrible. Somewhere around 50-100 games, you notice it blocking your winning moves. By a few hundred games, it's drawing consistently. Train it with a few thousand self-play games and good luck winning at all. The progression from clueless to competent is genuinely fun to watch.
...
---
Read the full article →
Add a comment: