Too many thoughts about AI in the classroom
My last newsletter dealt a lot with why the imperative to implement AI in classrooms felt so desperate and possibly delusional about the value of college degrees. But it didn’t actually deal with what I think college professors should do with AI.
I don’t know the answer to that. At some base level, chatbots are here, students are going to use them. If you set a blanket ban on Chatbot use for your classes, you are committing yourself to spending a great deal of time and effort trying to police student honesty to catch a few acts of dishonesty using flawed tools rather than attending to learning and teaching. I could describe in detail why the actual process of discovering illegitimate AI use is so difficult, and why, even once discovered, proving it such that you could penalize a student’s grade is so fraught and time consuming, but I’m just going to ask you to trust me here. Teachers should be spending their precious grading and prep time on advancing student learning, not fighting them about grades.
Another reason why an AI ban seems like a bad idea to me is that AI deployment has severely reduced the usefulness of other uncontroversially legitimate tools students had been using to write papers. While I’d love to imagine most students are doing research through library search tools, the reality is most have used Google Search for years, no matter how much we try to direct them to something more scholarly. There was always a slop problem on Google: search “Scarlet Letter” and you would get more SparkNotes-esque empty content produced for cheap than scholarly writing, literary criticism, or journalism. But, as almost everyone has experienced, since 2023 when AI started churning out content, Google Search has almost entirely lost its value: it produces pages of adverts and slop for any search with very little of value to a researcher.
Compounding this is that university disinvestments in libraries (at least at a university like mine) means that even with those better scholarly searches of journal databases and Lexus Nexus available through the library webpage, students often have access to very little beyond abstracts. Us scholars have networks to get around that (just ask a friend at an Ivy to send you a .pdf of the article you need), but students do not. Moving from Google to the library doesn’t really help.
And much to my big-tech hating chagrin, ChatGPT and Claude are usually pretty great at finding sources. They work really well as search engines! Researchers, never mind students, absolutely can benefit from using it to generate bibliographies and work through secondary literature on a topic. It automates a part of research that I think honest people will admit was laborious, tedious, and not instrumental to our critical thinking: the literature review. There’s more to say here, but while my sense is these tools are very poor at generating anything new (at least the ones consumers have access to), they are great at wading through and summarizing things that have already been said. It’s not a deep engagement, you still have to read and think about the human writing it brings to you, but it streamlines a labor-intensive step in research that is adjunct to the main work with primary materials and analysis that humans still very much need to do.
Chatbots have basically entirely replaced the search engine for now (even coming in at the top of search results), and, in my opinion, have significantly improved upon it. I don’t know how long this will last. It seems like in the case of ChatGPT, its massive speculative investments and inability to successful monetize thus far is leading the company down the road to desperate enshittification of its own product by incorporating paid advertisements into its chat responses. This was the first step that killed Google Search’s use value, and I can’t imagine it will go any better for ChatGPT. Still, for now, this is genuinely useful, and I could easily see student papers improving because they are getting access to better quality research faster.
My rough rule of thumb distinction is between process and product. The large, much talked about negatives of AI—cognitive deficits, labor disempowerment, and the slop factory—seem largely a result of people use AI to make final products. AI does not write good papers. AI generated emails from coworkers or corporate entities are annoying and counterproductive. Consumer chatbots use too many words to say way too little and the feeling that you are wading through slop to find the actually relevant point of information is deeply alienating. Students, of course, have always written fluffy papers to meet assignment page length guidelines and cover up their lack of ideas, but there is a true emptiness to the language of AI papers that goes beyond even that. I got an awful HBOMAX email ad about the new GOT show. Its junk mail anyway, but the content was not categorically different from reading “lorem ipsum” a thousand times.
My understanding is that the industry would identify these outcomes as an alignment problem. Just like students, AIs prioritize filling out the patterns of form and length they’ve been shown examples of and just churn material to fill it in excess of anything they are actually trying to express. Calling it an alignment problem (the AI doing something counterproductive to your actual goal as a user) lets us imagine it will one day be fixed. But why fix it at all? Asking an AI to write something entirely for you is a bad use of the technology. It is “cognitive offloading,” and if a person is sending me material to read, they haven’t even bothered to write, why should I read it? The purpose of communication and thinking is getting lost. At work it shows a disrespect to your colleagues, for students it’s avoiding work, anywhere else it’s contempt for your audience.
But lest I sound too romantic here, let me hold up. Writing is cognitive offloading (memory), calculators are cognitive offloading. This is what tech does; it outsources things we used to have to do so that we can do more complex things. In the SAT tutoring I do, one thing I have noticed is that SAT math is significantly more difficult than I remember. I was never good at math, but I still got a decently strong SAT score back when because, for the most part, SAT math was just knowing some concepts and formulas. My memory could be flawed here, and maybe it was more complex than I remember. But when I was training to tutor not only was I learning Math (particularly around Trig and Quadratic formulas) I simply don’t recall ever having learned, but the questions being also asked were more complex implementations of the concepts that involved significantly more lateral and creative thinking. Comparatively, the actual number values are often simpler and rounder; it’s about figuring out what you have to do with a ton of variables to solve, not doing long division or irregular fractions.
What explains these changes? SAT always allowed graphing calculators, but now an extremely complex and powerful one (DESMOS)is built right into the testing platform. If every student has access to a powerful and easy to use graphing calculator, then simply having complex multiple decimal point numbers to calculate doesn’t matter much. Linear and quadratic equation systems are a breeze to solve, even when they have multiple variables beyond x and y. But the College Board still needs to produce a test that maintains a curve of score distributions, otherwise its useless as an assessment instrument. Every test taker clustering in the 1400 and 1500s doesn’t tell college admissions anything. So, the questions had to be less about the concepts themselves and more about creative thinking: figuring out what alterations are need to fit formulas into matching patterns and finding ratio equivalences between them, complex factoring, function transformations, understanding and working with unit circles, using trig to find solve circle problems, and irrational numbers. The wide adoption of a technology that allowed for the cognitive offloading of foundational math didn’t make the test any easier, contra the perennial conservative “they dumbed everything down” talking points. Now, much more is expected of students in terms of creative problem solving. Trust me when I say, the average high school junior is probably much better at math than people of my generation are/were unless they continued to use it professionally. Half of my friends can’t even figure out tips, never mind compound interest (and this was me before I started this job, too).
So, I do find it specious to assume that any use of ChatGPT or other chatbots to automate part of the research or writing process in the college classroom is merely a loss of student capacity. The overall quality of student research has been on the decline since I started working in higher education. The larger enshittification of the web and loss of library resources are probably large drivers of this. But if students can use chatbots to put together better bibliographies faster, that may open the door for more complex expectations of what they should be able to DO with those sources. If we can get students to use AI as a process assistant rather than a writing producer, we may have a powerful new tool in advancing core research and thinking skills.
However, beyond the question of finding good uses of chatbots for learning, there are bigger social, moral, and political questions that inform how students approach them. In my experience, students have become very hesitant about Chatbots. There is no consistency in policy between their classes, and I think many of them more or less see any chatbot use as cheating. This does not at all stop its use, but it makes students very hesitant to talk openly about it both with each other and with instructors. In addition, I have a general sense that students, like many of us, are swinging hard against big tech. It would take a whole essay to talk about this, but there is certainly a growing sense among the students I teach that tech platforms and companies are bad for us, damaging to the environment, home to nazis, alienating, making us miserable and lonely. They aren’t wrong. But like with many things we know are bad for us, they are still roped into them for a variety of reasons. Nonetheless facing a pressure to adopt a new tool, they have understandable and justified resistance. Even if they still use it sometimes, there can be a discomfort to admitting it in public places dedicated to professional and social virtues, like admitting you smoke. There is a growing social and personal guilt around chatbot use.
Some clarity is useful here, because I believe this guilt is misplaced. Big-tech platforms, are, in my well-documented opinion, extractive, alienating, likely neo-feudal technologies. However, the most commonly repeated reason for not using chatbots remains environmental impact. It seems to many like a good line to draw, something we can control. And, this will probably make people mad and I’m sorry ahead of time, the environmental concerns about the AI build out are probably overblown or, at the very least, confused about what power we have as consumers.
The data here is actually pretty clear (this is all drawn from the linked research). First of all, spending time prompting Chatbots represents such a miniscule portion of your daily carbon footprint and water use, its barely even worth measuring. The article compares it to taking a walk. If you go for a walk, the amount of wear and tear on your shoes probably represents greater emissions and water use than spending the same time prompting ChatGPT.
Data Centers (as a whole) account for 2% of global C02 emissions. Training and running AI models is only a percentage of overall data center energy use (15%). So, we are in the tenths of a percent of overall emissions. To try to give scale of this compared to everything else we do, the article uses a pie chart of global emissions from 2016.
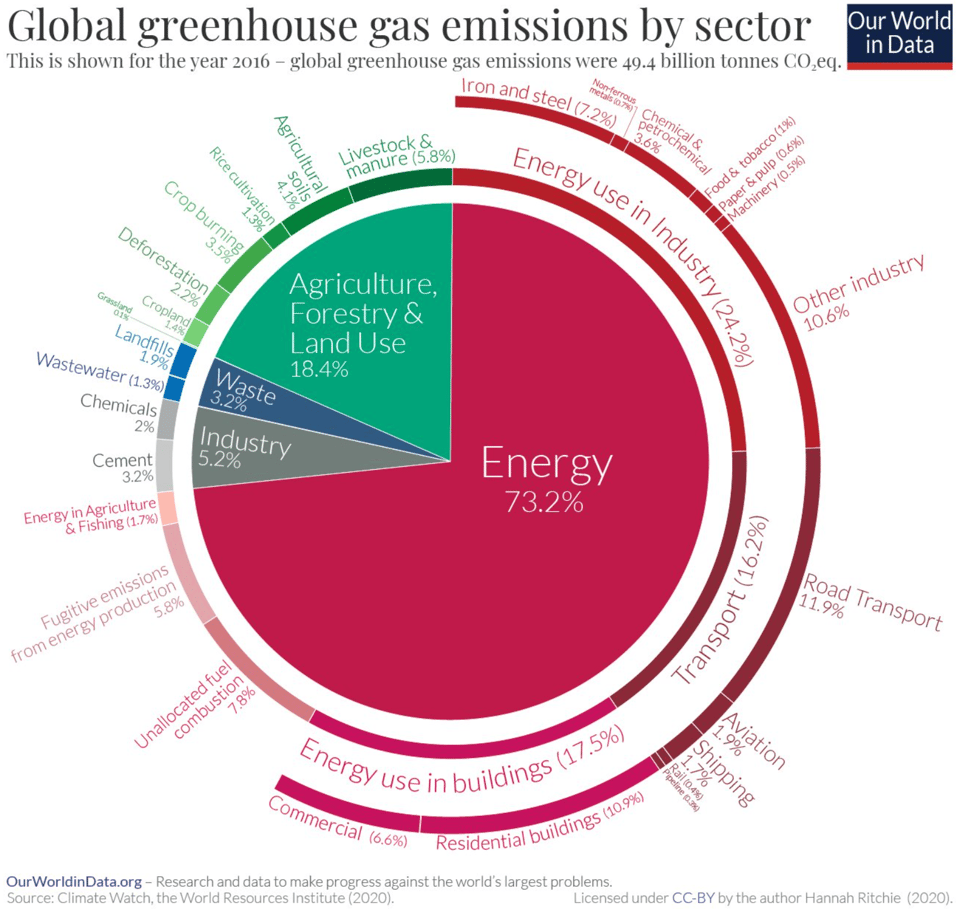
I don’t want to get into the question of whether or not AI will successfully make electrical grids more efficient (I don’t have the chops to assess that claim of AI proponents) or what growth might look like in the coming years and whether that will create a significant effect. But I do think there’s some relevant points we can make about where AI fits in overall environmental questions.
AI is only one part of the Data Center infrastructure build out. It has been driving a lot of recent growth, and it’s not hard to find a story about individual data centers-built for AI specific functions that have been environmentally destructive. xAI’s Memphis center is the big villian here, and I think we all can agree: fuck Elon Musk. We can and should be looking at instances like this and be fighting for environmental justice, good land use, green energy, lower pollution. But, and here’s where I’m being difficult, if you are just paying attention to data centers and not say, Cancer Alley, you are missing part of the larger picture. This is not whataboutism, both what has happened in Memphis and Cancer Alley are examples of devasting environmental injustice that must be redressed. But there are about 5,427 data centers in operation in the U.S. If we are assessing data center’s environmental impact in general rather than certain data center’s environmental impact, we have to talk about the big picture not a few examples.
The data center big picture is not at all straightforward, but if you are reading this, you are in fact “using” computing power housed at a data center somewhere. That is because over the last decade the world has moved from a distributed computing power model to a consolidated cloud computing model. Think of it this way, if you are my age you probably remember your first computer and perhaps you still have a “gaming” computer. You will remember big stacks with cooling fans, running things through DOS, overwhelming your computer capacity on a regular basis. You may also remember that workplaces used to have server rooms. My mom spent her working career as an administrative assistant at the Harvard Smithsonian Astrophysical Observatory in Cambridge. I remember visiting her office on bring your children to work days and, nerdy computer boy I was (I used to go to programming camp at MIT in the summers, how my life changed), she and her coworkers would describe the Linux systems and servers they used for communication and running programs. All of that is gone, because now nearly all computing runs through cloud applications. I’m writing this on a cheap dinky laptop because I don’t need my laptop to run any programs, everything goes through the cloud. My university doesn’t have any servers, just wi-fi routers. While my mom’s old workplace may remain an exception (an astrophysical observatory is running deep space telescopes), most workplaces are not themselves computing on site, but either using Office 365 or Google work suites run through cloud computing or renting space from AWS or someone.
From the point of view of power, consolidated computing is a consolidation of power—now everyone is paying rents to a few big tech companies that own all our data to do all our work, make all our purchases, talk to our friends, make and sell art, and everything else. From the point of view of energy use, this is a massive efficiency upgrade. Data Centers are way more efficient than everyone having their own servers and computing towers. They run state-of-the-art chips that are more efficient than the hodgepodge of updated and dated hardware of the past, economies of scale decrease water and energy use, and consolidated computing power at least hypothetically is much easier to convert to green energy sources. This is not to deny that building a data center can have significant local costs. Much more widespread than the extreme pollution examples like Memphis are instances in which local energy costs have spiked because of the large increased demand on a particular grid that comes with a new Data Center. Local political entities should be demanding green energy build outs as a condition of data center permitting. But those spikes are because suddenly a bunch of computing that was happening all over is now happening in that one place.
So, when we look at the 2% of global emissions that are data centers overall, we are 1) talking about a net reduction from a world running all the same processes without data centers and 2) quite an amazing feat that the entirety of everything the whole world does on computers and the internet is so low. I find it hard to see this as a major emissions villain compared to the really big problems with runaway C02 emissions we face in the energy sector as a whole.
Now there are many complications here I want to admit without spending too much more time on details, since this post needs to get back to classrooms. Are we doing much more computing now because of data centers than we would do without them and is that incentivizing runaway growth? What is the future growth demand of AI for energy? Even if there are net energy use reductions with data centers, aren’t we entering into moral hazard because the risk of their environmental impact on water and pollution are being localized, potentially near communities, that face structural, environmental justice, disadvantages (i.e as in Memphis)? These are all valid questions, but they are larger that require more complex answers across multiple domains of regulation, political activism, selective economic withdrawal/resistance to cloud capital, and energy and economic transformations. I don’t think “don’t use AI because it’s bad for the environment” works as a catch all solution, however, for a much clearer reason than the thorny answers to these questions.
The AI industry build-out/bubble has almost nothing to do with consumer use (or the use we might put it to in our classrooms).
We are used to thinking about capitalist enterprise as producing “products” that are sold for profits and if we, consumers, refuse to purchase a product we can have some effect on the system. Even if the efficacy of boycotts as political strategy were clear (it is not) this coherent and simple cause and effect model just does not apply to AI. I don’t want to get too into the business weeds here, but here’s a metaphor. When the U.S. massively invested in the transcontinental railroad (a labor and environmentally devastating speculative investment project if there ever was one), the adoption of the railroad by passengers excited to see the Pacific Ocean with their own eyes was completely adjunct to the value proposition of the railroad. As remains true today, American railroads just aren’t for passengers—even in the famed Acela corridor, Amtrak rents passage on shipping lines. The speculative bet was about business-to-business sales and economic growth fueled by industrial expansion (of resource access, of markets). If every American consumer had said “I’ll never ride the railroads!” (and Thoreau scholar that I am, I know there were in fact protests against railroads) it would not have mattered one bit to the builders of the railroad. The bet wasn’t on consumer use.
Someone may object that nevertheless, the railroads enabled massive westward migration of settlement with devastating effects on native Americans and local environments. That’s true! But look, this explanatory metaphor is not meant to be a one-to-one comparison with AI. I am trying to explain one thing only: that the builders of the railroads were not building them for consumer use.
That is basically the same with AI. All the major use cases for AI that promise real efficiency gains and thus would pay off the speculative investments are business to business or business to government: Coding, biomedical research, power grid efficiency projects, just for instance. This chart shows it very clearly. While initially the novelty of ChatGPT in 2023 resulted in a large percentage of AI being used for text generation (what you and I and students are doing with chatbots), that has quickly been overwhelmed by every other use to the point that its completely negligible.
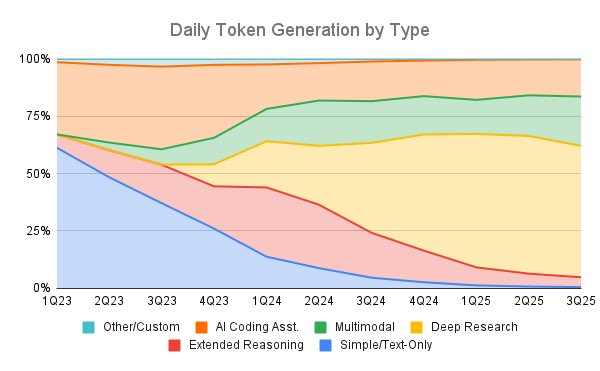
This is not because of any drops in use. Chatbot adoption rates are astronomical. It is because the other functions have so massively expanded. And that was always the plan. The models we access through ChatGPT or Claude are adjunct to the project. If we all stopped using ChatGPT tomorrow, you might see some hiccups in stock prices, but I doubt it would have any major impact on the overall investment trajectory. We just don’t matter as consumers here very much. As consumers at home or students in a class we are the smallest piece of the overall use cases. In fact, ChatGPT costs much more money to run than it makes on memberships. Why would OpenAI be spending so much money on something that is not profitable? It only makes sense if 1) consumer use is not the main target, and 2) you follow the technofeudalism thesis that cloud capital firms are not profit-seeking but rent-seeking (like the railroads!) They want to have the platform everyone needs to pay rent to use, not sell a product. To do that you need power, control, access to business funds, speculative investment, and frontier models, not paying customers. Thus, whatever strategy we have to contest tech company power, we have to let go of the capitalist myth of consumer buying power that informs boycott strategies. It’s a waste of time and energy.
I think the other part people don’t always recognize is how much “AI” is already everywhere in everything we do on computers. I don’t just mean how search engines are now providing chatbot text before any links or how AI assistance has been integrated into word processing, e-mail clients and every other productivity application. It is the backbone of the web. Machine learning algorithms come in different forms. LLM chatbots are one. But the algorithms that generate every social media feed are another. When you scroll through Instagram, TikTok, recommendations on e-commerce sites, Netflix, or any website with advertisements, you are prompting algorithms to select and generate content for you based on the inputs of your user data. Any “costs” of AI data center use are being incurred here just a surely as when you prompt a chatbot. These are not categorically different technology; they are early rough deployments of the same architectures that formed the basis of LLMs, and they all use Data Centers and contribute to the ballooning demand for computing power and efficiency.
I want to be clear: my purpose is not to dismiss discomfort with this technology or the way it’s being pursued and directed by a few ridiculously powerful corporations. My last email hopefully makes that clear. My point is that people have a particular sense that chatbots are bad that leads them to avoid, or at least be shy about, using them for anything at all, but do not apply the same standards to tech as a whole. This is ineffective because it proposes a strategy “don’t use chatbots” that doesn’t achieve anything, is likely unscalable, and I fear it will become another useless upper middle class liberal college grad shibboleth (like most all consumer choice environmentalism becomes).
So to finish being annoying and trying to correct misconceptions, the “real” problems with AI are, roughly: AI is an extractive technology, based on the foundational data extraction mechanisms of surveillance capitalism and growing technofeudalism that appropriates and encloses the creative labor and attention of all of humanity into highly managed, rent-seeking, fiefdom platforms, and is an engine of massive inequality and de-professionalization of workers. If we are going to attempt to fight the power of big tech by way of withdrawal from platforms we would need to withdraw across the board: social media, e-commerce, fintech, Gmail, Microsoft 365, etc…. Unless that is what you are doing (and I, for one am not, I would lose my job) there’s a basic level at which its unfair and hypocritical to try to force some moral norm around no chatbot use. I think a withdrawal strategy is immensely unfeasible. I can’t even get friends to quit Meta platforms no matter how much I talk about how much it improved my mental health. Morally absolutist (or wellness!) demands about consumer choice that do not have a coherent organizing and political strategy always get captured by elite status seekers. It’s a way to perform a virtue to the already converted, not build solidarities across difference
So, I don’t want my students to feel guilt and shyness about chatbot use for class, either because they imagine it only as a tool for cheating, or because they are getting messages that they should feel guilty about it for environmental reasons. I can’t control the social and information environment my students are in that communicates this message to them, but I do think we have to be able to discuss chatbots between the extremes of “must use” and “can’t use.”
I have no answer: it is a hard conversation. I am thinking about structuring my freshman writing class next semester as something like a “critical algorithm studies” course, transitioning a bit from pure writing questions to questions about the production, distribution, and assessment of information under cloud capitalism. What can probably never be automated is the human necessity to assess information, to understand what evidence supports what claims, and whether we should believe what we have read. If the processes of research and writing is being transformed, the need for humans to develop skills for assessing information and taking responsibility over what they communicate has not.
Universities used to be the primary producers and brokers of information. The liberal institutional structures of free speech and inquiry, rigor, faculty governance, and academic freedom existed to ensure the quality of that information. All of those have significantly decayed and tech has appropriated information production and brokerage to itself. But they don’t have any incentive to care about the quality of information in terms of rigor, truthfulness, logic, or free inquiry. Those of us teaching and researching can and should still be doing that and it’s what we should be teaching our students. But we need to reclaim the value of teaching the core part of this “what is a claim? what evidence do you need to make it? how do you assess someone else’s claim?”
The urgency of this is quite large. Deepfakes are already here; our information environment may be no worse than any information environment in the past (newspapers have always made up shit for profit, and, yes liberals, traditional media does in fact herd around elite consensus without meaningfully challenging it—just ask Iraqis) but the sheer volume of information inundating us certainly has not brought anyone out of Plato’s cave. I doubt we can fix the problem at a society wide level in our classrooms, but we still have a responsibility to our students to advance their capabilities, to be a good guide out of the cave by teaching them how knowledge and communication works. To do that we have to sit with the problem of knowledge production and information brokerage in our historical moment. It involves critical encounters with algorithms, chatbots, and machine learning, as well as building an understanding of the political economy of communication and information. We can’t say “yes!” to AI, but we also shouldn’t be saying “no!” either.
So, the question I have is definitively not: “do I incorporate AI in my classroom to help students train for the jobs of future or do I try to recover some possibility of learning writing and research without it?” These options are inadequate. My question about AI in the classroom is more along the lines of: “how do we teach writing classes to ensure they are preparing students for navigating existing and emerging knowledge and information economies?”