The Model Is Not the Product
Everyone talks about models. But in production AI systems, the model is only a small piece of the story.
The model is not the product.
Last month I argued that AI Engineering is the missing discipline. The response confirmed what I suspected: the gap is real, and people feel it. But defining a field is only step one. The harder question is: what does an AI engineer actually need to see what others miss?
The 5% Problem
In 2015, a team of Google engineers audited their production ML systems and published a finding that should have changed how everyone thinks about AI: the model, the neural network, the thing everyone obsesses over, accounted for roughly 5% of the total code (see Figure 1). The other 95% was data pipelines, feature extraction, serving infrastructure, configuration management, and monitoring.
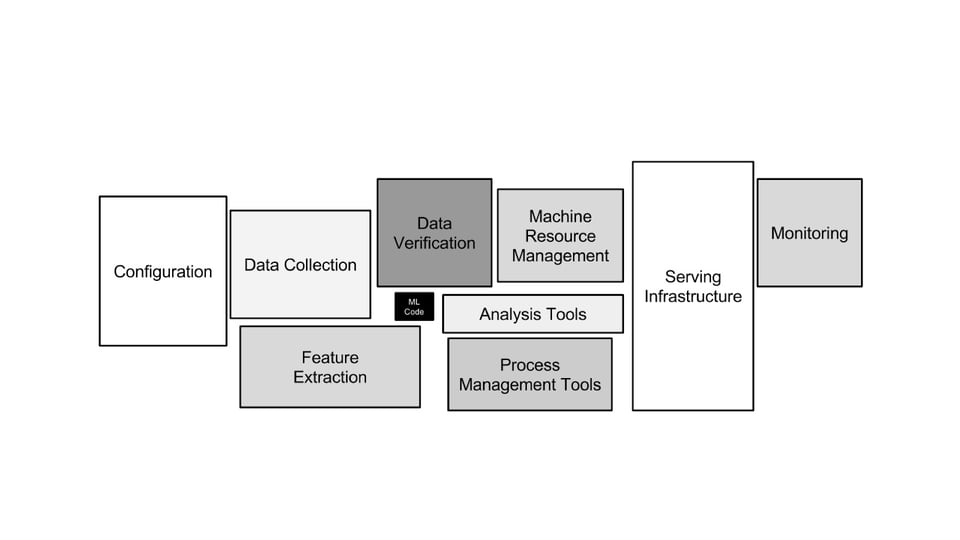
That ratio has not changed. If anything, it has gotten worse. The models have gotten larger, but the systems around them have grown faster.
This is the gap that most AI education ignores. We teach people to build the 5% and hope they figure out the other 95% on the job.
Data, Algorithm, Machine
So how do you reason about the other 95%? In the Machine Learning Systems textbook, I use a simple diagnostic framework I call the D-A-M taxonomy: every ML system is shaped by three forces. Data is the fuel, what you train on and how you move it. Algorithm is the blueprint, the math that turns data into predictions. Machine is the engine, the silicon, memory, and power budget you actually have to work with (see Figure 2).
The key insight is that these three forces are interdependent. Compressing a model to fit on a phone changes its accuracy. Doubling the training data demands more compute. Switching from a CPU to a GPU reshapes which algorithms are even practical. Change any one axis, and the others must adapt.
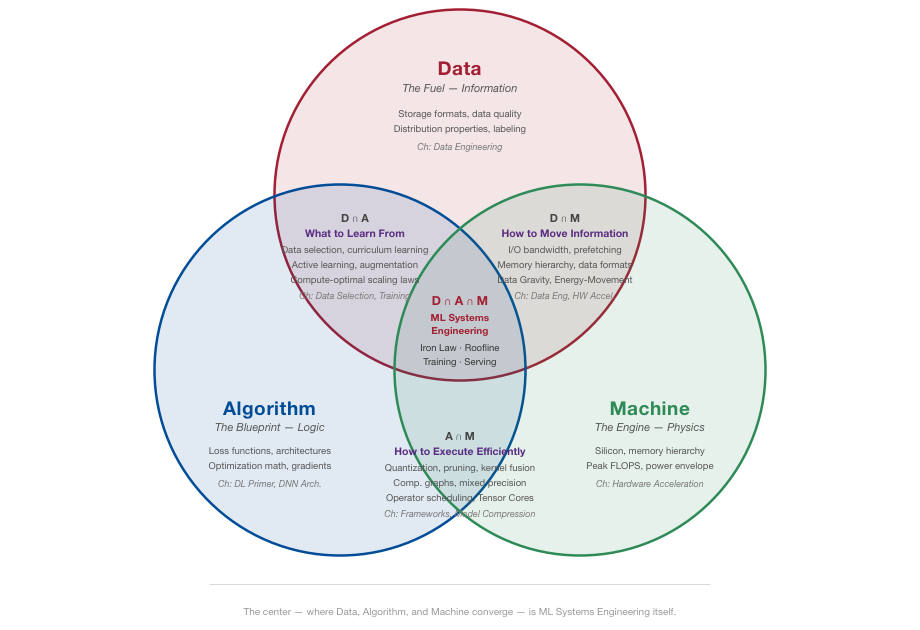
This sounds abstract until you see it in the real world.
In 2012, Krizhevsky split AlexNet across two GPUs because neither had enough memory to hold the whole network. A Machine constraint shaped the Algorithm that launched the deep learning revolution.
That was two GPUs and 6 GB of memory. What happens when the constraint is an entire country's hardware supply?
DeepSeek: When Constraints Become Advantages
In late 2024, DeepSeek released V3, a model that matched GPT-4 on most benchmarks. What stunned the field was not the performance. It was the cost: $5.576 million (see Figure 3) for the final training run, against an estimated $100 million or more for GPT-4.
How did they overcome this issue? Not by finding a shortcut. But by being forced into better engineering.
US export controls barred China from buying NVIDIA's top-tier H100 GPUs. DeepSeek trained on H800s, the same silicon but with NVLink bandwidth cut by 56%. That single Machine constraint cascaded across every axis of the D-A-M taxonomy.
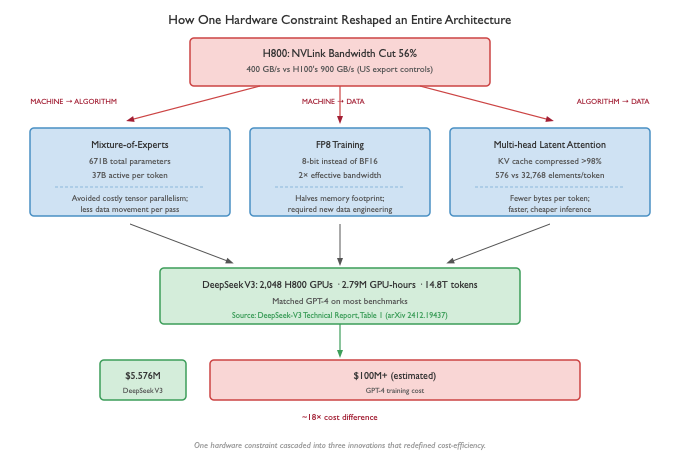
Machine → Algorithm: the hardware forced a new architecture. With half the interconnect bandwidth, the standard way of splitting a model across GPUs was prohibitively expensive. So DeepSeek engineered around it. Instead, they built a 671-billion-parameter Mixture-of-Experts model where only 37 billion parameters activate per token. Think of it like a hospital with 100 specialists but only 5 in the room for any given patient. Less data moves through the system on every forward pass, by design.
Machine → Data: the hardware forced a new number format. They trained in FP8, 8-bit precision instead of the standard 16, cutting memory usage in half and doubling effective bandwidth. The tradeoff is that lower precision can destabilize training, which required new data engineering to manage.
Algorithm → Data: the algorithm forced a new memory strategy. Their Multi-head Latent Attention compresses the model's working memory by over 98%, fundamentally changing how much data moves during inference. Fewer bytes per token means faster serving and lower cost.
The result: a frontier model trained for a fraction of what competitors spent. Not because DeepSeek had better researchers (though they very well might). Because the constraint forced a better architecture.
Export controls meant to slow China's AI progress may have produced the most hardware-efficient training system anyone has built.
DeepSeek's team published their infrastructure work at ISCA 2025, a computer architecture conference, not an AI one, explicitly framing it as hardware-software co-design. That venue choice tells you everything about where the real innovation happened.
It Is Not Just the Model
DeepSeek shows how Machine constraints reshape Algorithms. But even when the architecture is right, the infrastructure can be the bottleneck.
When Meta trained Llama 3, they used 16,384 H100 GPUs for 54 days. During that run, they recorded 419 hardware failures, roughly one every three hours. GPUs crashed, network links dropped, storage nodes failed. The dominant engineering challenge was not the model architecture; it was keeping the cluster alive long enough to finish a checkpoint.
This is the other 95% in action. The model architecture worked fine. The engineering challenge was everything around it: detecting failures, routing around dead nodes, restarting from checkpoints, and coordinating 16,384 GPUs that would rather not cooperate.
This is exactly the kind of reasoning I want future AI engineers to develop. Not just "how do I train a model" but "where is my system actually breaking, and which axis do I fix first?"
Here is the practical takeaway: the next time you hit a wall in your ML system, before you reach for a bigger model or more data, ask which axis is actually the bottleneck. Is it Data (you are starving for quality inputs)? Algorithm (you are using the wrong architecture for your hardware)? Machine (you are memory-bound and no algorithm change will help)? That question is where DeepSeek started, and the constraint is what made the answer interesting.
Your Turn
The lesson is simple. Frontier AI is no longer just about better models. It is about better systems thinking.
When an ML system breaks, the cause is almost always on one of three axes. Data. Algorithm. Machine. AI engineering begins where those three forces collide.
DeepSeek turned a hardware handicap into an architectural advantage. Meta turned 419 failures into a resilience playbook.
What constraint shaped your system? And did you fight it, or did you let it guide you?
Next month: the full stack of AI engineering, from silicon to serving. What each layer does, where the bottlenecks hide, and why no one teaches it end-to-end.
What the Community Is Building
A discipline does not emerge from a single book or tool. It emerges from people building things together.
Visit MLSysBook.ai for curriculum updates, hardware recommendations, and TinyTorch learning materials.
If you would like to support our community outreach and global workshops, consider contributing at opencollective.com/mlsysbook.
Further Reading
Hidden Technical Debt in Machine Learning Systems (Sculley et al., NeurIPS 2015). The original "5% problem" paper from Google.
DeepSeek-V3 Technical Report (DeepSeek-AI, 2024). Full details on MoE, MLA, DualPipe, and FP8 training under hardware constraints.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning (An et al., ISCA 2025). DeepSeek's infrastructure paper on how they built around the H800's bandwidth limitations.
The Llama 3 Herd of Models (Meta, 2024). Section 4 covers the 16,384-GPU training infrastructure and the 419 hardware failures in 54 days.
Machine Learning Systems is a two-volume open textbook on the physics of AI engineering.