The Two Intertwinglers
New developments in my ever-expanding project to retrofit the Web.
Intertwingler began as “a bundle of ideas and opinions about how to make websites”, with roots I can trace back to the literal year 2000. I’d made bits and pieces of it over the years, in this language or that, but never managed to realize a complete, fully-circumscribed picture, until 2023. This current incarnation began life as a thing called RDF::SAK, short for “Resource Description Framework Swiss Army Knife”. That name reflected why I initially wanted it, which was to automatically turn RDF graphs into websites. I based this motivation on a hypothesis that doing so would be extraordinarily powerful—which, unsurprisingly, it is.
I wrote
RDF::SAK(now Intertwingler) in Ruby, which was a tactical decision, as my desired effect depended on an ostensibly rare category of software called a reasoner. My options were either to write one of these from scratch (extraordinarily hard) before I could get started, or try to fix an abandoned one written in Python (I tried and gave up), or write Intertwingler in Java (absolutely not, though I did try writing it in Clojure, but that would have taken months of front-loading effort and I got impatient), or, just write it in Ruby. I actually quite like working in Ruby, but as it ought to become clear, I don’t view Intertwingler as “yet another Ruby Web framework”. Rather, one of the big ideas underpinning Intertwingler is something I’m calling “intelligent heterogeneity”.In some sad news, furthermore, the architect of Ruby’s RDF framework, Gregg Kellogg—also a veteran of the W3C and author of the RDFa and JSON-LD specifications—passed away last September. What will happen with his codebase is unclear. I have commit access, so I can fix bugs upstream, but there’s no longer a very competent retired guy with lots of time to maintain that software.
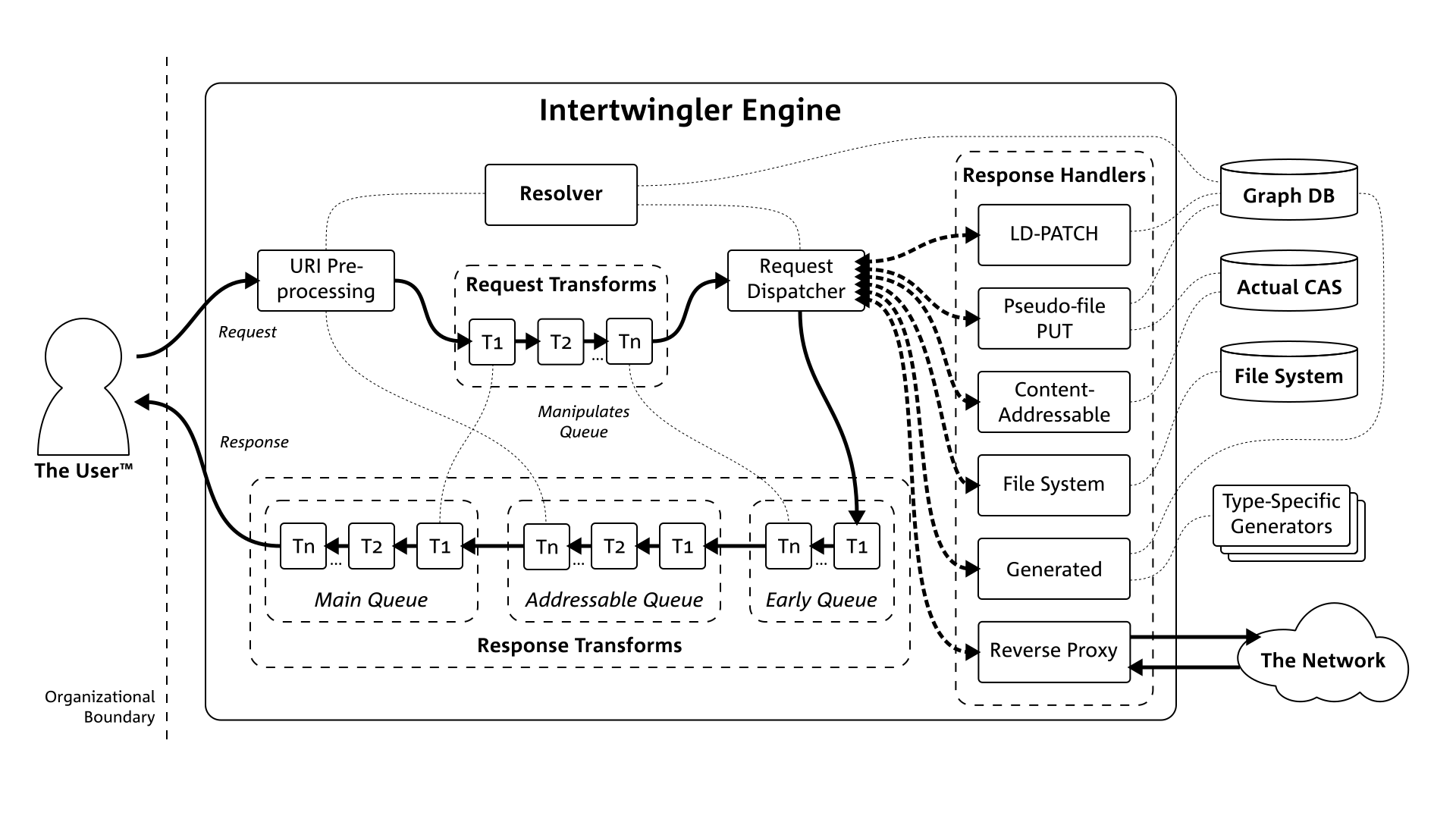
As work on Intertwingler progresses, a cleavage plane is beginning to emerge. I’ve always had trouble talking about Intertwingler because it has a dual role:
- Turn an RDF graph into a set of doubly-linked—and importantly, writable—(HTML and/or JSON) Web pages,
- and because it takes more than just pages to make a website, deal with everything else that isn’t clearly in that category.
A subsidiary problem I had to solve is that RDF puts a positively ridiculous amount of URLs into play, which magnifies—and, given that the whole strategy is to use open standards to compose highly-reusable pieces together at the network level, compounds—the already pervasive problem of link rot. So one essential component of Intertwingler is a resolver that relates durable canonical identifiers to the more human-friendly, yet mutable URL paths we’re accustomed to, and the concomitant database that preserves their naming history.
This basic design actually stretches back twenty years, from experience that goes back even farther. Back in 2006, I had an idea for a “Web substrate”. I was a big user of mod_perl back in the day, which can be thought of as just a wrapper around the Apache API, thus making it much easier to code—in Perl, in this case. This exposed me to something I don’t think most Web developers experience, which is access to the entire HTTP request loop. The majority of Web development has to do with writing code that emits content, and is thus concentrated in the content-serving phase of the request-handling cycle. There are, however, about a dozen phases, most of them occurring before the response, where you can subtly manipulate the request object—rewriting URLs, twiddling headers and such—and you can also create filters to transform the bytes of the request coming in, and response going out. What this amounts to, is an opportunity to bifurcate the code into that which has to take the particular content and/or application into account, and that which can remain ignorant. The overarching aim is much less code to maintain, due to an inventory of reusable parts in the latter category.
Now, of course, Apache is out of fashion—to say nothing of Perl. And a lot of this kind of functionality has been recapitulated anyway, with frameworks and middleware, within the content handling phase. A pattern has emerged across numerous programming languages (Rack, Plack, WSGI, JSGI, etc.) that serve as an adapter between $WHATEVER on one side, to a familiar CGI-like representation on the other, preprocessed into the given language’s native data structures. This is really smart, because it means developers don’t have to care how their application hooks up to the internet.
Indeed, products like AWS Lambda are designed such that you can just write code and forget that Web servers even exist.
Let’s examine for a moment how this progressed. In the very beginning, there were only Web servers, and if you were lucky, the server had an API. Then somebody invented the Common Gateway Interface, which mapped HTTP requests to the inputs of an ordinary command-line program. This made it possible to write trivial little scripts in interpreted languages and put them online quickly, instead of having to write C—which is hard—and for which you had to recompile and restart the server every time you changed something. The problem with CGI, though, is that the script starts, runs, and exits with each individual page hit, which is slow, and terrifically wasteful of (what would have been much scarcer) computing resources. Thus FastCGI—plus a handful of other similar protocols—was born. This would require minimal intervention on the script side (zero if you’re using one of those middlewares), which is kept running in a loop, and thus would no longer incur the setup and teardown costs with every request. Nowadays, the pattern is to run a toy Web server on your laptop while you’re writing these things. Well, these toy servers have gotten pretty good, so we can do away with FastCGI entirely, and deploy our applications using an ordinary reverse proxy.
I am eliding the parallel history that includes all the interpolation-paradigm platforms like PHP, ASP, JSP, ColdFusion, and the granddaddy of them all, server-side includes. These would nominally be implemented a server module or dedicated application server—although I know the
phpbinary can be run as a (Fast)CGI program—and then take care of the entire execution environment for the application.
This contemporary stance of “HTTP Is All You Need” is a momentous opportunity to revisit some of Roy Fielding’s most powerful ideas. Fielding is the guy who invented REST, which is about so much more than just a fun way to make Web APIs. (After all, he wrote an entire PhD dissertation on the subject.) The ideas I want to call attention to here are what he termed unified interface and layered system. What this reduces to, in practice, is something like a POSIX command pipeline, where the articulation points are HTTP. The key difference, aside from the obvious one of operating over a network, is that the data going through the pipe is typed, i.e., you know what kind of object the bytes are supposed to represent. What this means is that you can do all sorts of conditional processing and transformations, just like you could do with a filter in Apache, except you could implement it as a stand-alone microservice that interfaces over ordinary HTTP. This is what I’m trying to achieve with the “everything else” part of Intertwingler.
This is why I’m starting to think I may in fact be dealing with not one, but two cognizable entities. The outstanding question remains, roughly: how dependent—really—is this latter part I just described, on RDF? Now, I think RDF is the bee’s knees, but a lot of people don’t seem to agree with me. Intertwingler—the part other than the one that turns an RDF graph into a website—still uses it for its configuration, and I intend to use it even more for a thing I’m calling Handler Manifest Protocol, which is an organized way for microservices to advertise their contents to the engine. The engine behaves like a microservice bus, a reverse proxy that pools all downstream microservices into a single address space, and rewrites the URLs going in and out. All it needs to pull that off is its own configuration data, plus that URL mapping I was just talking about.
This, as I said, is how I eliminate
404errors: start off with immutable canonical identifiers and overlay human-friendly ones, then be sure to record any changes to the latter. Redirect any stray requests to the old addresses to the new ones. Because we have a transformation filter infrastructure, furthermore, we can rewrite the URLs in outgoing messages.
What I’ve just described here has sort of always been the plan, but I’ve been thinking about it more recently due to the rise of BlueSky and the AT Protocol. Intertwingler (the ensemble) overlaps considerably with what ATProto calls a PDS—a “personal data server”. It should be possible to create a set of adapters that make Intertwingler speak ATProto. This would lay the groundwork for a general-purpose PDS that could store your data and interact with the network, whether it was ATProto, ActivityPub, Solid, or some future protocol that hasn’t been invented yet.
This brings me back to the RDF question. ATProto uses its own schema format called Lexicon. Now, I am fairly confident—though I have yet to prove this—that anything that can said in Lexicon, can be said in RDF. It should therefore be possible to create a pair of transformation functions that ferry instance data undisturbed between the two representations. This is something I will have to work out if I were to connect Intertwingler to the ATmosphere. Which got me thinking: why not do something similar with the microservice-bus component?
The reason why I stubbornly insist on RDF is because I believe it is by far the most robust way to organize data. If data expressivity were a hill, RDF would be at the top. You can roll RDF data downhill into other formats and representations, but you have to push non-RDF data uphill. Other people aren’t convinced; that’s fine. They can keep pushing while I roll.
The advantage of decoupling this microservice-bus thingy (Intermingler? Interwrangler?? Hopefully something better…) from the RDF-graph-to-website thingy is that it could be a tight little server module—written in Rust or Go or something—that plugs into nginx or whatever. Again, this was kind of the plan, but the new bit is that with no perceptible RDF presence, it won’t spook the workaday Web developer.
At any rate, there is a crapload of work to do to get to this point, which I am currently doing off the corner of my desk. I fund this development by helping clients with all sorts of things to do with making—or even just heavily depending on—digital information infrastructure, including those in the ballbark of what I just described. I’m also putting together a set of technical seminars. The first one I’m showcasing, which is based on the technique I used to make this entire stack, I’m calling Semantic REST. Because there’s so much to cover, I also have a seven-part lecture series in the works that anybody will be able to purchase access to. The first of such lectures is done, and I’ve decided to self-host them, so I’m just wrapping up the order processing microservice. I should have time for that in the next few weeks. I’ll be announcing that on all channels, so stay tuned.