The data round-up #1 - April 2023
👋 Hello and a special welcome to those of you who subscribed recently! You can recover past issues on the site, they’re always available. Feel free to comment with any feedback, you can also respond directly to the email.
This one is a special issue, it’s the first data round-up of Doodling Data, a new monthly space where I’ll share some of my favourite things in the field of data: articles, blog posts, long reads, research papers, shows, documentaries, websites, … Also, news from the trenches. It will not be just new stuff though, some old-but-gold material will sneak in too.
I will put these in their own section in the publication, you will be automatically subscribed to them but you can control this in your account. I’m planning some other expansions - stay tuned!
AI - it’s all the rage now
Calling for a pause on the training of LLMs, and begging to differ
It’s been a long process lasting decades, but finally everyone is talking about AI, and I mean everyone, not just those that develop it or somehow revolve around it. That’s the measure of how a technology has actually made it to a spot in the sun.
LLM (Large Language Models) are what’s behind tools like ChatGPT, Google Bard, or Github Copilot, to name the most famous ones. These are models trained on big text corpora and capable of generating human-like responses to queries or help with writing code - they’re pretty amazing, though it’s debatable how much they really resemble human intelligence.
Anyway, they can perform some tasks pretty well and with the updated releases of the last couple of months they’re now helping people with drafting emails or sales pitches, getting ideas for a dinner recipe or finding simple information - because they can efficiently speed up some activities they’re getting embedded in more and more products. This is relevant, because the new generation of AI bots is finally turning out to be useful, after years of varied and fragmented disappointment with tools like Alexa, Siri, the Google Assistant & Co, boasted like wonderful but actually somewhat disappointing in delivery: ever had the tragicomical experience of spending more time and energy in making any of these understand what you were after than you would have searching for the answer yourself?
These new AI models don’t come without issues though. One of the biggest ones is a general concern that they risk contributing to spreading misinformation (of which we really don’t need more). This is because they’re not always right and may even hallucinate - for some examples, see here and here. It is funny, except when you think about potential applications for students, children or any of us who aren’t in the privileged position to be able to discern. OpenAI, the creators of ChatGPT, are of course improving their models in iterations, the latest one is claimed to be more factual than its predecessors, so there’s some silver lining, but the problem remains.
Setting aside the Terminator-inspired fear that these bots will soon overpower and enslave humans (we’re still too far for this to be a grounded fear), there’s other problems too. For instance, not everyone is exactly ecstatic about the fact that a few tech giants monopolise the AI market, and it may seem that we’ve not learned much about this from, say, what happened with social media.
You might have seen that in late March many notable people from the field of AI and tech have signed a letter to ask for a moratorium in the training of such models, arguing that we have not fully assessed risks vs. benefits and we should spend some time implementing regulations and protocols to make sure these new technologies are applied safely. The letter had many prestigious signatories.
However, there’s a few voices that disagree with this idea, most notably those of Andrew Ng and Yann LeCun, two people who have been involved in AI research and applications for a long time. In early April they had a conversation that you can watch here.
Essentially, they argue that calling for a pause on research is calling for a new age of obscurantism and it’d also be useless because it would require deep government stepping-in. They fully acknowledge that these tools have issues but, they say, we should regulate products and applications, not research. The tools have already done major steps towards becoming less toxic (remember Microsoft’s Tay, the racist and bigot chatbot immediately retired?) and, LeCun insists, it’s lack of imagination to think that new ideas won’t arise to make them controllable.
I’d tend to agree, I don’t think anything good can come from putting a barrier to the human longing to know and discover more. But we should regulate the use, to make outcomes fairer to all and to limit dramatic consequences.
As for the fear that we’re being complacent to the risk that we’re going to soon live in a world of robot overlords, they stress that the understanding of the world tools like ChatGPT have is very superficial and this is a fear we can postpone by at least a few decades. And about the fact that a few companies own these things and profit from them, they say it is a concern but we ought not to overthink it as the space is becoming more and more competitive hence the situation will improve. Personally, this is the point that doesn’t convince me, it seems quite an American Neoliberalism way of thinking, that I don’t believe has exactly proven to promote social equality.
Leaving aside this discussion, some other folks are worried that limiting AI right now will have a detrimental effect on the balance of global power, especially in light of the fact that China won’t stop, resulting in America being left behind. This one is really a sign of the times and we’ll surely see more of it.
Regulatory machines vs. the machines
Government intervention, which has been often short-sighted and slow in the approach to digital, is trying to step up in the AI game. We need good regulation that doesn’t hinder research but makes it so that society as a whole can benefit from technology and to get there we need regulatory officers to be knowledgeable on tech.
Some news:
About a month ago Italy’s data protection institution had banned ChatGPT outright out of concerns that users’ privacy was not respected and terms were not clear. It looked (to many) like a conservative move, despite concerns were fair. A month later, concerns have been addressed and ChatGPT is allowed again in the country
The EU has a proposed law, called the AI Act, which it is currently improving to address the specifics of generative models like those fuelling ChatGPT. I’ve discovered there’s a Substack about this (!), you can subscribe here.
The US is also exploring avenues for regulating these systems, so in short we can expect some movement within the year
A creative use of the new bots
We said that tools like ChatGPT, when used well, can be valuable. One interesting use is ChartGPT, a web-based tool that can draw you little charts under a prompt. It was developed by Kate Reznykova, see announcement here. It’s brilliant!
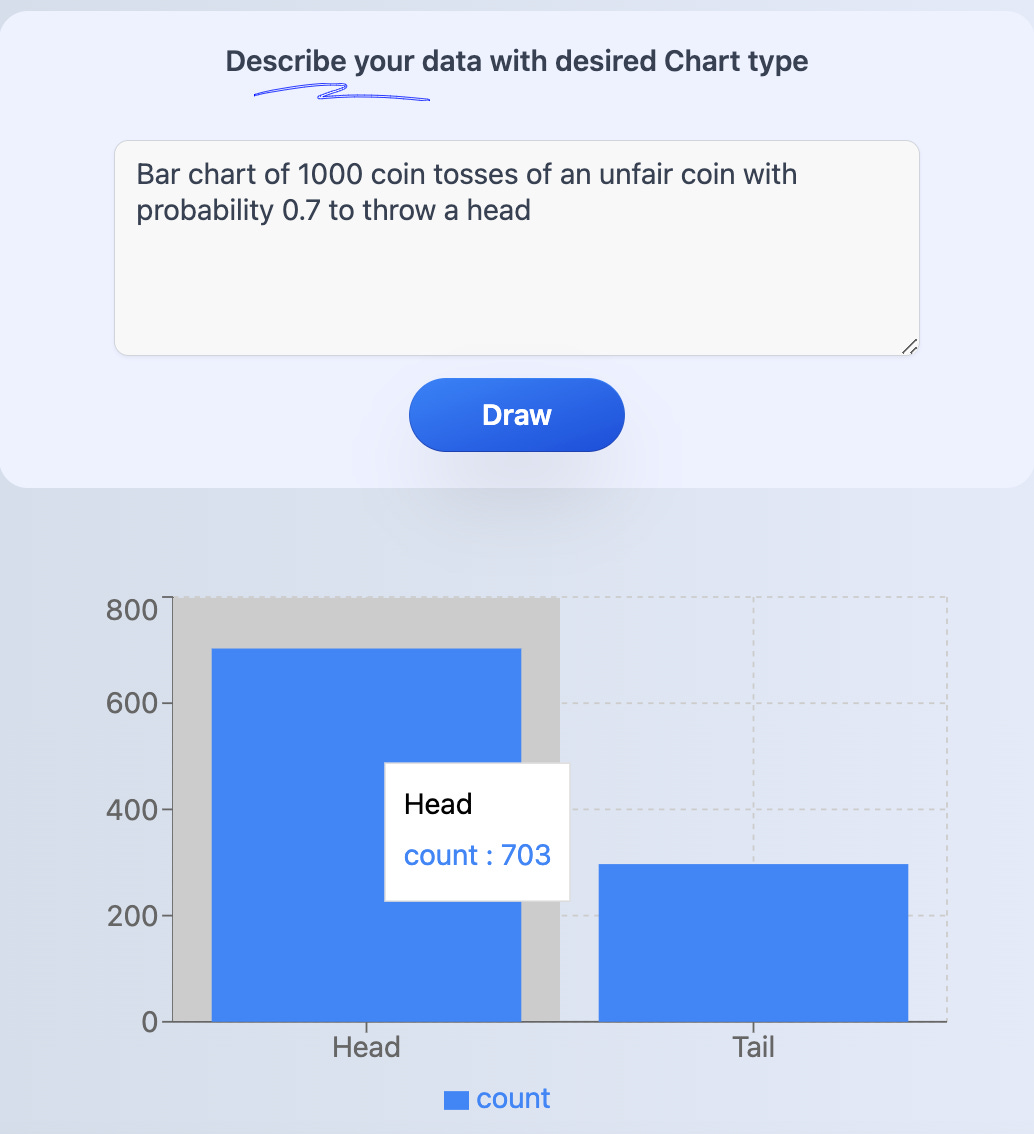
🎨 To conclude all this, I’m going to definitely make use of ChatGPT when researching datasets to use for my data cards from now on. 📊
Good ol’ Statistics
Statistics may be less sexy but I promise, it’s the base. And it’s clever and fun.
An interactive compendium on foundations
Seeing theory is an interactive little book, created by then students at Brown University and in active development between 2016 and 2019. It is not maintained anymore, but it remains a wonderful resource for anyone wanting to explore concepts of probability and statistics as it offers an interactive interface that makes you “see“ what happens. The site is built with D3.js.
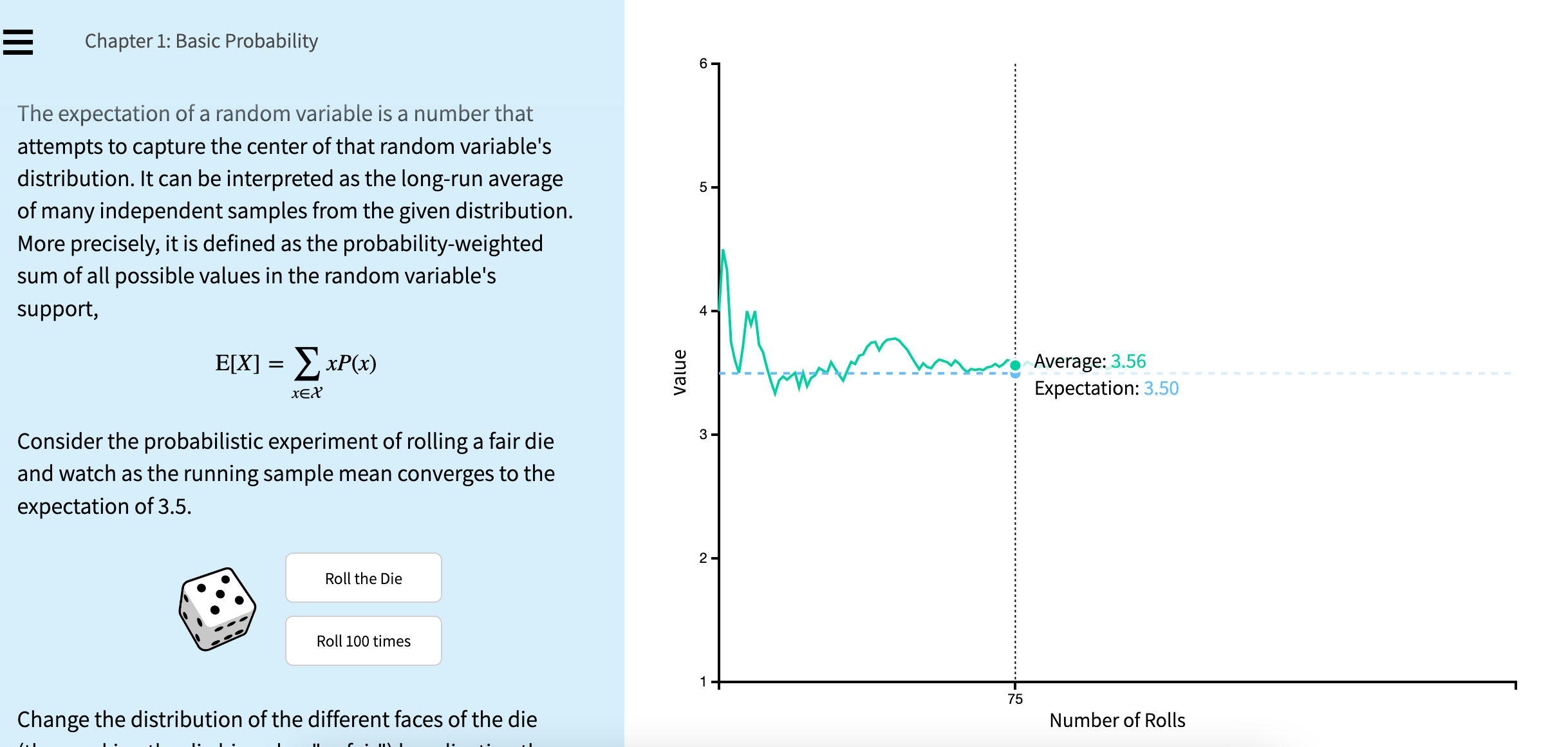
It is a great resource to use in the classroom but also for anyone wanting to brush up on basics or just learn them.
Read some more
Some more good links
ChatGPT: Everything you need to know about OpenAI's GPT-4 tool, BBC Science Focus, 3 April 2023
The problem with artificial intelligence? It’s neither artificial nor intelligent, the Guardian, 30 March 2023
Add a comment: