Ignore Previous Directions 5: hardware has changed
Nature

It is the gall wasp season. These are weird wasps that inject chemicals into plants, and repurpose their growth patterns, like gadget exploits in code. This is a mossy rose gall, you can see a smaller one starting to grow on the left as well.
Hardware has changed
I have been taking notes for this for a while, but started a conversation on Bsky with David Aronchick yesterday about it so thought I should write this up in more detail.
AMD Zen EPYC shipped a maximum of 32 cores in 2017, 64 with Zen 2 in 2019, 96 with Zen 4 in 2022 or 128 smaller cores with Zen 4c, and then 128 for Zen 5 in 2024, with 192 in Zen 5c. So four times as many cores in eight years, doubling every two years in a Moore's law type mode.
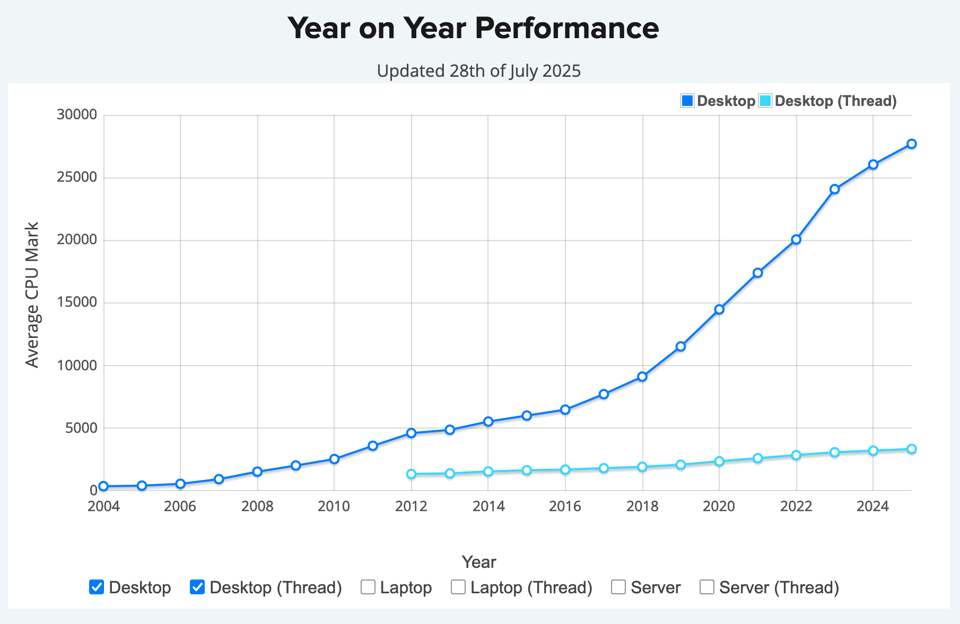 Thread versus CPU performance for desktop CPUs from CPU Benchmark.
Thread versus CPU performance for desktop CPUs from CPU Benchmark.
Within the cores, while they don't run any faster, we have started doubling up compute units, from 32 bit registers to 64 bit registers (2003 for amd64), 128 bit SSE (1999), 256 bit AVX (2011), 512 bit AVX (2017), and new Zen5 hardware can execute four 512bit operations per cycle. This is far above the memory bandwidth limits so is only useful for doing a lot of compute over cached items.
Over that period AMD EPYC went from a maximum of 8 channels of DDR4 memory to 12 channels of DDR5, which roughly doubled the maximum memory bandwidth, halving the bandwidth per core for the maximum core configurations.
We have been increasing IO too. Ethernet went from occasional x10 bumps (100Mb was 1995, 1Gb in 1999, 10Gb in 2002, 100Gb in 2010) to a doubling cadence where a lot of the increase is just doubling up connections (25Gb and 50Gb in 2015, 200 Gb and 400Gb in 2017, 800Gb in 2024). Current standards are based on 100Gb links and switches but these are doubling to 200Gb and the process of doubling will continue. These roughly match PCIe bandwidths, with PCIe5 x16 links supporting 400Gb ethernet, and PCIe6 now starting to roll out.
Storage is on the same trends, now that hard drives are largely obsolete except for nearline storage. A single PCIe5 x4 device typically supports reads at 14GB/s, enough to saturate a 100Gb ethernet channel, and 200 layer flash devices are appearing, with 120TB and 240TB drives starting to appear.
All this while latency has not fallen much at all, and with resources being further away, such as over the network in many cloud architectures, latency has often increased. So to build architectures that use the performance there is, queue depths have to increase a huge amount, something that most software has not yet done, although we sometimes try to make up for this by just running a lot of copies of the software, or trying to do a lot of async IO.
So thats what has been happening with CPUs, what about GPUs and other "AI hardware"? GPUs have taken various forms of memory and put them in more expensive, wider, faster and higher latency configurations to get around some of these issues, while combining them with hardware that has even more FLOPs, but with even more parallelism and less support for branches.
Let us unpack that a bit. GDDR and HBM are increasingly expensive ways to put memory chips close to compute with very wide buses to allow faster bandwidth. While DDR5 channels are 64 bits wide, HBM 3E is a stack of up to 16 dies each at 64 bits width, and there may be multiple stacks on the GPU, for example the Nvidia GB100 has eight stacks of 8 dies. In principle you could add HBM to CPUs (AMD does offer this as a niche offering), but the additional latency means you would need even longer queues, and that would mean even more branch prediction, speculation and so on. GPUs don't really support branches in code, and work most effectively with large streams of reads and writes to memory with huge parallelism. For example 32 threads (a warp) run the same instruction (which reduces the instruction processing hardware requirements), with each tensor core able to perform operations on a 1024 bit vector each clock. All the hardware for running classic branchy code on a CPU are gone, typically you execute both sides of a conditional and multiply by booleans to select the value to use, if you need conditionals. With AI workloads turning into largely matrix multiplication the legacy parts of a GPU for graphics processing are starting to get vestigial. Also we have worked out how to do computation with lower precision. Scientists liked to get into the weeds of IEEE float convergence and 64 bit floats, while the new hotness on Nvidia Blackwell is four bit floats, as you can run them about 16 times as fast.
The architectures being built for AI look very like traditional HPC and supercomputers. The base unit of compute is typically a server with 2 CPUs and 8 GPUs, and say 10 800Gb network cards, 8 of which are for the GPUs to communicate directly. Even inference workloads are most effective at scale on multiple machines, especially for larger models, and these are batched (for example 100 simultaneous conversations with an LLM) to use more compute that is available, with memory bandwidth being the limiting factor for much of the workload.
If we look at how much of this new compute we are building, looking at TSMC new node production, around one third is mobile phone chips, that are maybe roughly half accelerators and half traditional CPU compute, while the rest is roughly evenly split between CPU and GPU. By value half of spending on servers is for some form of accelerated compute. Now this is largely because we have found a specific application that we can scale out effectively on this new architecture. But this architecture was arriving anyway, reaching supercomputers at scale by 2017 or so. The spending boom is pushing investment forward, and making some of the doubling up happen faster, but that was the track we were on anyway.
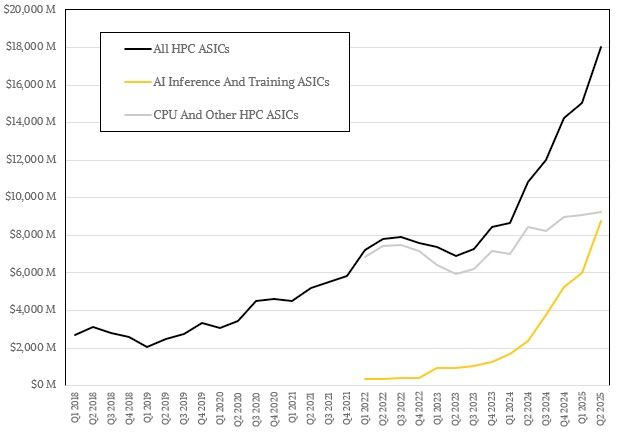 Estimated production breakdown for TSMC from The Next Platform
Estimated production breakdown for TSMC from The Next Platform
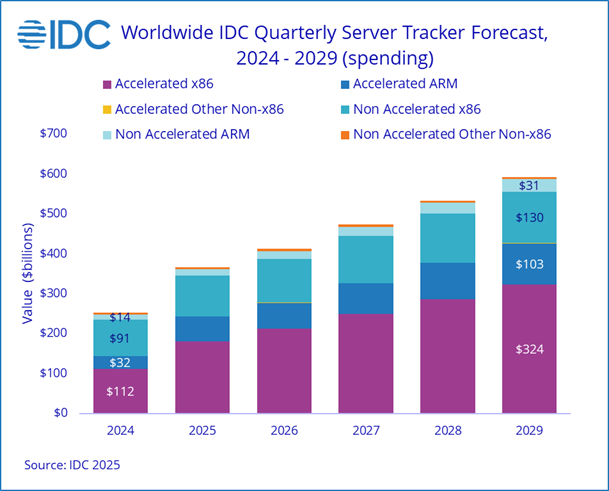 Estimated server spend from IDC
Estimated server spend from IDC
Regardless of what happens, single thread performance was stuck anyway, the memory wall has been real since 1990 or so, latency has been barely moving, and Nvidia has been building products for decades, with a singular vision. Writing code that runs efficiently, even on CPUs let alone GPUs, is hard. There is a largely latency gap switching from CPU to GPU, although we are starting to see more CPUs and GPUs combined on the same piece of silicon, from Apple, Nvidia and AMD, although these are generally much lower memory bandwidth parts. The software side has a lot of work to do to catch up with the reality of the hardware. GenAI has accelerated this hardware transformation, and we need to work on the software transformation for modern hardware.