Reviewing Pull Requests
My colleague on the machine learning team recently asked me for advice on better reviewing pull requests. It was a productive conversation with things worth sharing, so here they are.
Theory
First, let’s quickly discuss theory. In my experience, you should optimize for two consistent things in software engineering: reducing complexity and tightening the feedback loop.
All of the coding tricks you hear, like DRY or KISS, fundamentally attempt to reduce complexity. Complexity is the ever-looming specter in software engineering. It corrodes your systems, making them slow and hard to change. Stagnant software is destined to fail.
Complexity must be actively fought at every stage.
The other side is tightening the feedback loop. You want to get feedback on all your changes as soon as possible. Feedback is how you align your assumptions and systems with reality.
Think about feedback loops when writing a buggy line of code. Consider some stages where the bug could be caught:
External users of the system in a production environment
Internal users in a lower environment
Pull request
Linting and testing
Within your IDE
These are ordered from the slowest to the tightest feedback loop. If your IDE immediately flags the issue when you write the line of code, it’s likely a simple fix. You have the most context you’ll ever have. Ideally, linting and testing happen frequently as you work on the code. Issues caught by these are relatively low cost.
Once you submit a pull request, the context around the change drops drastically. There’s some time between when the change is made and when it is reviewed. The reviewer will also have less context about the implementation. Still, catching an issue in a pull request is much better than after it’s deployed, which is still much better than an external user experiencing the problem.
So, why are reducing complexity and tightening feedback loops important for pull requests?
Reviewing and order
Taking these together, we want our PRs to be as small as possible. I’ve heard that a PR review should take around twice as long as it does to create the PR. Hard to do with large PRs!
Small PRs minimize their complexity and shorten the feedback loop. They’re reviewed faster, deployed faster, and get feedback faster.
There’s also a general order in reviewing pull requests:
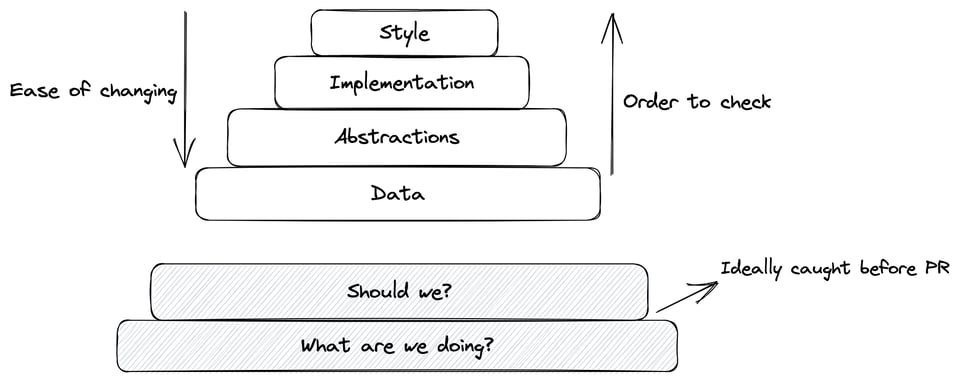
First, we need the context on what we’re trying to do—or if we should even do it. If we’ve established that code is the optimal solution, we should start our review with the things that are hardest to change. Typos in method documentation don’t matter if the method shouldn’t exist.
This generally means starting with fundamentals like the data model, including database migrations, data formats, and the system’s data flow. Software, at its core, takes input data in some form and produces output data in some form. Good data schemas and abstractions are among the most important things for managing complexity.
After the data, we can review the abstractions, particularly any core abstractions of the system. Type signatures, class definitions, and structures are more challenging to change than their respective implementations. Every new abstraction is a commitment, requiring support over the system’s lifetime.
Assuming the abstractions look good, we can review the implementation. Are there any obvious bugs? Is the time and space complexity of the implementation acceptable for our requirements?
Finally, we can take a look at stylistic concerns. The code should match the team’s conventions. It should be idiomatic if possible. Comments should discuss the “why” when helpful. And, of course, try to catch any typos.
You’ll get better at this as you practice.
Takeaways
Tighten your feedback loops.
Add only the essential complexity.
Make your pull requests minimal.
Confirm the code change or addition is required.
Review things in descending order of how hard they are to change.
Thanks for reading! I’d love to hear any thoughts, suggestions, or questions you have.
Stay safe,
Justin