Distopia Algoritmica - parte 3
Este começo de ano está sendo mais difícil do que imaginei, por isso começo pedindo desculpas porque esta edição era para ter sido publicada semana passada mas não consegui finaliza-la a tempo. Devo dizer que até para o conteúdo aqui presente isso foi realmente bom, com a cabeça mais fria e mais tempo, foi possível enxergar melhor detalhes que de outra forma passariam despercebidos, como é o caso de minha intenção inicial que era tentar deixar tudo com o mínimo de tecnicidades sobre a implementação de algoritmos justamente para que não se tornasse um texto técnico, mantendo a linha crítica/analítica como um ensaio, mas tem momentos que isso é impossível, então deixei aqui o mínimo possível que não prejudicasse o entendimento, sendo que a explicação mais técnica sobre como funciona o aprendizado de máquina, incluindo códigos e tudo o mais, estão aqui.
E para quem quiser contribuir com este projeto de discussão crítica sobre tecnologias, faz um pix :-)
O problema do aprendizado
Falar de aprendizado de máquina é completamente diferente de falar de aprendizado humano, para começar basta apenas dizer que nós não somos máquinas por mais que o nosso atual modelo de produção tente fazer parecer que somos. Apesar de ser algo tão lógico que parece ser uma piada, este fato é fundamental para acabar com as analogias comuns sobre assunto e que existem desde o nascimento do Perceptron, quando o NY Times alimentava a hype sobre essa coisa que teria a capacidade de ser autoconsciente, enxergar, escrever, aprender sozinha, andar, etc. Devo dizer que apesar da inerente comicidade de tudo isso ainda bate em mim uma sensação de desconforto, como se fosse uma realidade paralela e o que eu aprendi sobre inteligência artificial e aprendizado de máquina (sim, são coisas diferentes) fosse sobre algo completamente diferente do que falam nos sites especializados em notícias sobre tecnologia e isso tem seu lado preocupante, afinal se trata da formação de uma crença quase religiosa e um tanto quanto dogmática a partir de empresas e "gurus" do vale do silício que influenciam diretamente até políticas públicas, principalmente as voltadas para segurança nas ruas, e na forma como lidamos com a onipresente tecnologia da informação que embranquece as fotos feitas no celular e realça os comentários cheios de ódio no twitter, atraindo nossa atenção para o que menos nos interessa e mais interessa à plataforma.
diferenças iniciais
Acho que o melhor exemplo que já vi sobre a diferença entre o aprendizado de máquina e o humano é a forma como se ensina a uma criança o que é, um cavalo, por exemplo. O pai ou a mãe aponta um cavalo para a criança e diz "olha, tá vendo? é um cavalo!", a criança observa o cavalo, forma um conceito de cavalo e o associa a palavra. Mas com uma rede neural pegamos várias imagens e tentamos fazer com que o algoritmo aprenda um padrão nelas de modo que o permita identificar que há um cavalo na imagem. Daí já temos nossa primeira grande diferença substancial: é impossível lidar com conceitos em IA, pode-se até relacionar dados para que ofereçam algum contexto, como no caso de uma regressão usada para previsão do tempo, mas conceito é diferente, é algo mais filosófico e abstrato, que engloba todo um conjunto de conhecimentos acerca da coisa conceituada, algo impossível na simplista representação de apenas pontos num plano cartesiano.
Pausa para uma pequena explicação: para quem não conhece o termo, regressão é como uma função só que ao contrário: enquanto uma função é uma regra, como $f(x) = 3x+2$ que indica onde devemos marcar pontos num plano cartesiano para que, ao uni-los, teremos um gráfico. Numa regressão começamos justamente com estes pontos e tentamos traçar uma linha que representa o comportamento expresso pelos dados, de modo que se houver padrões que indicam ciclos, por exemplo, a regressão pode indicar a tendência de ocorrência de um evento.
Na parte anterior dessa tetralogia falei que toda classificação feita por algoritmos se baseia em alguma noção espacial sobre os dados, quase sempre considerando um espaço plano (espaço euclidiano). Sei que isso é começar pelo fim, mas antes de entrar mais fortemente na teoria, acho interessante explorar um pouco a extenção do que isso significa de fato. Além da ausência de conceitos, também temos a ausência de incerteza: uma resposta sempre será dada, nunca haverá a resposta como um "eu não sei" e no máximo será acompanhada de uma estatística que indica algo como 65% de chances de ser X, 62% de chances de ser Y, etc. Obviamente lidar com dados dessa forma exige alguma interpretação e por isso achei tão precisa a comparação feita aqui com "falar com espíritos" que transmitem suas mensagens só para iniciados. Na prática o que se faz é definir uma margem de "certeza" mínima, mas na imensa maioria das vezes a distância entre o valor dado como "certeza" sobre uma coisa e outra são tão mínimos que muito frequentemente termina em algo como num chute, como um aluno fazendo uma prova em que ele tem alguma noção da resposta certa mas mais de uma proposição estão alinhadas com o que ele acha que é certo, então ele chuta em algum mais ou menos aleatório mas tendendo para o mais provável, respira fundo e entrega assim mesmo.
É fácil presumir então que muitas das aplicações são feitas mais com base na sensibilidade dos responsáveis pelos algoritmos do que por alguma razão mais objetiva, também não podemos desprezar a ilusão que dá a "certeza" expressa pela estatística que falei agora a pouco, mas este é um assunto para a próxima parte dessa tetralogia, quando encerrarei esta sequência de discussões sobre IA falando justamente de como definir seu lugar de aplicação e entre outras coisas, como seriam testes para validar a qualidade de um algoritmo se houvesse alguma regulação que definisse procedimentos a respeito, mas já adianto o que a esta altura é óbvio: sou a favor da regulação, também sou a favor do ensino de computação a sério e de forma crítica nos colégios, afinal, nisso estão inseridas questões inescapáveis a todos e já faz certo tempo que não há como fugir de assuntos que tem sua origem no desenvolvimento das tecnologias da informação, só de ver quantos escândalos existem por volta das big techs com todo esse oligopólio, as farsas futuristas dos discursos neoliberais e tudo o mais, os pés no chão do básico do conhecimento técnico me parece fundamental para que se observe criticamente tantas coisas tecnológicas que têm definido nossas relações uns com os outros e com instituições e até mesmo nossas existências. Mas como eu já disse, esse é um assunto futuro, por enquanto, vamos avançar na teoria sobre o aprendizado de máquina.
entrando na teoria
Primeiro um rápido esclarecimento, aqui estou falando especificamente de aprendizado de máquina, não de inteligência artificial, ambos são coisas bem distintas que podem ser usadas ou não em conjunto ao preparar um algoritmo para que tenha maior qualidade nas respostas.
Inteligência artificial se trata de simular comportamentos tanto de animais quanto de humanos, também dá para extender a outros processo que ocorrem na natureza, mas tudo com o objetivo de reproduzir alguma resposta/comportamento diante de um conjunto de dados, o que também pode significar fazer alguma escolha (no caso de classificação) ou previsão (no caso da regressão).
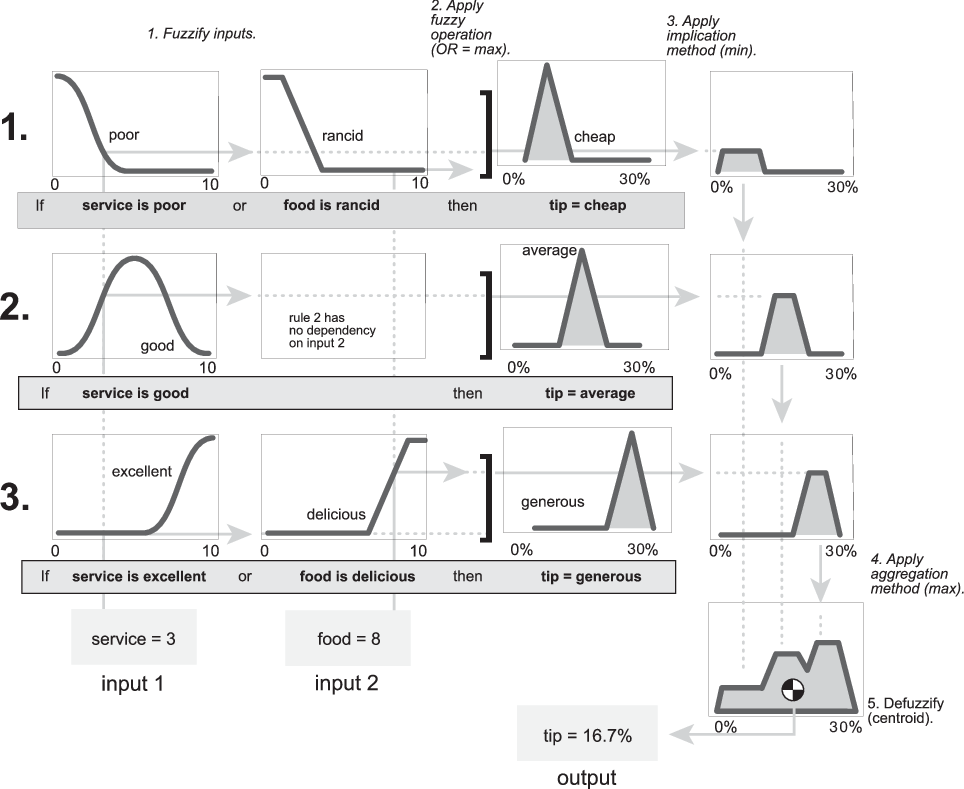
Acho que um bom exemplo de IA sem aprendizado de máquina está em alguns tipos de sistemas especialistas que funcionam com árvores de decisão ou lógica fuzzy, embora, dependendo de como um sistema assim seja desenvolvido, pode combinar diferentes algoritmos inteligentes, mas a nível de exemplo, vamos nos concentrar no mais simples possível. Como o nome indica, estes sistemas buscam reproduzir o trabalho de um especialista humano, ou melhor, a parte mais repetitiva possível do trabalho de um especialista humano, e ressaltar isso é importante, afinal o que fez com que se tornassem tão populares na indústria foi justamente isso (além de batear consideravelmente os custos). Vamos imaginar o caso de gerar diagnósticos preliminares com base em exames de sangue, podemos imaginar na nossa mente um grande encadeamento de if-else sobre os níveis de glicose, hemoglobina glicada, etc. Mas também é possível pensar de forma mais... matemática, ao pensar a partir dos diagnósticos possíveis, podemos modelar as expressões de modo que num plano cartesiano existam regiões que representem os diagnósticos com base nos dados obtidos pelos exames, algo mais ou menos assim:
Bem diferente disso são os algoritmos que dependem de aprendizado de máquina para que se tornem utilizáveis, como é o caso das redes neurais, elas podem ter milhões de parâmetros para ser ajustados aos dados, e por essas semanas devo publicar um texto falando dessa tendência à insustentabilidade com base no alto custo computacional mas antecipo brevemente este assunto porque cabe aqui: o treinamento nada mais é do que a aplicação de um algoritmo de otimização, isto é, uma forma de busca pelos parâmetros ideais para que o algoritmo se ajuste o melhor possível ao conjunto de dados que por sua vez, representam elementos reais na imensa maioria dos casos. O aprendizado de máquina pode ser resumido muito bem nisso de ser um ramo de estudos voltado para otimização, e que obviamente não se limita a otimizar outros algoritmos, como os usados em previsão no tempo, e pode ajudar a modelar desde circuitos eletrônicos a componentes de veículos (a F1 é um ótimo exemplo de aplicação intensiva de algoritmos de otimização para modelar objetos reais).
É curioso que quando estudamos sobre funções do 1º ou 2º grau no colégio também estamos tratando de otimização, isso de buscar o ponto mínimo ou máximo, onde a parábola da função do 2º grau faz a curva, os zeros da função, tudo isso pode ser sobre otimização, é um dos contextos de uso, mas como no mundo real existem muitas situações com bem mais complexidade e outras que nem tem como estimar a totalidade de fatores envolvidos, representar tudo numa função matemática apenas para ir descobrindo soluções possíveis chega a ser um caminho inviável que é simplificado pelo uso de algoritmos de otimização, que mesmo não chegando numa resposta definitiva, podem chegar a uma solução boa o suficiente para ser considerada aceitável.
Seguindo o método
Acho que a este ponto é melhor detalhar o procedimento de um algoritmo e como estamos falando aqui de aprendizado de máquina, então nada melhor que um algoritmo de otimização. Vamos de PSO (particle swarm optimization, a otimização por enxame de partículas), criado por um biólogo junto a um engenheiro elétrico, inspirado pelo movimento de bandos de pássaros.
PSO:
- Criação de uma "população", que na verdade é apenas uma lista de coordenadas aleatórias a princípio (pontos aleatórios num plano cartesiano)
- Faz um ranking com base na qualidade da posição de cada partícula para identificar a melhor posicionada e registrar a melhor posição de cada partícula nessa rodada do treinamento
- atualização do vetor velocidade, isto é: calcular uma direção e a largura do "salto" a ser dado quando for atualizar a posição
- atualizar a posição: nova posição = posição anterior + vetor velocidade
- repetir os passos de 2 a 4 até chegar ou não num resultado aceitável. Sim, tem vezes que não chega a um resultado, pode estagnar em alguma região.
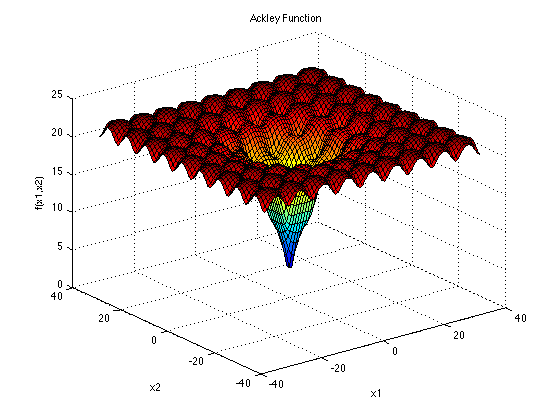
Imagino que a primeira dúvida que se tenha ao observar este passo a passo é: se "faz um ranking com base na qualidade da posição", como saber se uma posição é melhor que a outra? Simples, se cada coordenada no plano é composto por parâmetros são o alvo da busca, digamos se estamos buscando a calibragem ideal para os pneus de uma bicicleta para uma competição de ciclosmo cross country, cada "ponto" no gráfico representa, em libras, a calibragem de cada pneu, e para saber qual é a melhor, teríamos de fazer uma simulação tão próxima ao real quanto possível para só depois disso fazer o ranking. Então temos aqui um processo exaustivo, pois se temos 30 partículas, em cada rodada do treinamento, teremos 30 simulações, e a partir do tempo estimado de cada volta com a bicicleta no circuito simulado podemos encontrar qual está mais próxima do ponto mínimo (menor tempo). Só que também poderíamos representar espacialmente tanto uma forma como um "terreno" como as partículas explorando este terreno em busca do ponto mínimo, por isso faz sentido que para testar algoritmos do tipo quando serão propostos em artigos acadêmicos, os testes envolvam ver se e como o algoritmo proposto lida com "terrenos" como os expressos nessas funções:
Como é possível imaginar até aqui, IA lida basicamente com dados, simulação de comportamentos e estatística, que é fundamental para o treinamento já que é através de conhecimentos dessa área que de ponta a ponta se avalia e se decide o que fazer, desde a preparação do dataset até a qualidade do treinamento do algoritmo, por hora ressalto o sentido de erro, que nada mais é do que uma métrica para quantificar a distância do "ideal"(acertar tudo numa classificação é ideal?), ou seja, à primeira vista podemos compreender como algo que funciona quase como uma métrica de assertibilidade, sendo portanto um dos elementos que definem a forma desse "terreno"/horizonte de busca numa aplicação real. É realmente interessante discutir o sentido de erro numa IA, pois em situações simples de uso, é de fato apenas a busca por se adequar ao dataset mas no mundo real há uma dissonância entre o dataset e a realidade, tornando o que o erro indica até certo ponto subjetivo, e quanto mais se percepbe a discrepância promovida muitas vezes pelo próprio tempo, mais subjetivo é pois termina sempre por depender dos responsáveis interpretar o que aquilo significa e a simples adequação a um dataset diz muito pouco se o dataset não representar os dados reais com alguma fidedignidade. Para ficar bem claro: não adianta pegar um monte de foto de homens brancos ricos em sites de fofoca de Hollywood junto com um ou outro artista negro perdido alí no meio e depois usar um algoritmo, por mais moderno que seja, por mais preciso que seja em relação ao dataset escolhido, e depois usar em câmeras de vigilância numa comunidade do RJ onde a maior parte da população é negra, a distância diminui muito a qualidade da resolução das fotos tiradas de rostos e ainda tem a variação da luz ao longo do dia além de obviamente ter condições climáticas inteiramente distintas do dataset de origem. Não digo que é esse o caso, mas pensemos nas possibilidades, quais as chances reais de existir datasets de fotos de rostos com identificações corretas em volume suficiente, representando razoavelmente o escopo de possibilidades das condições das imagens com a luz, chuva, luz dos postes e de faróis de veículos para que no treinamento de um algoritmo do tipo possa-se dizer que pelo menos se ajustou em algo extraído da realidade de onde será aplicado. Acho que existir um dataset assim também seria uma barreira legal já que é claramente uma grande violação de privacidade, mas não duvido da ética política.

O que eu queria mais chamar a atenção aqui é no fato de todo treinamento ser exaustivo, envolver um volume enorme de testes só para ajustar parâmetros, e o que se fala sobre um grande volume de dados em IAs atualmente é especificamente para se ter uma representatividade de casos de tal modo que cubra a maior quantidade de possibilidades que for possível, delineado de forma mais consistente, regiões no hiperplano para que o treinamento chegue a um resultado que tenha o mínimo de falhas em situações reais (pelo menos hipoteticamente, o que já vimos que essa é uma noção bem ilusória). Mas não podemos deixar de compreender todo este processo como uma "tentativa e erro"/chute sofisticada, ou melhor como um jogo da forca ou ainda um batalha naval, onde os resultados de uma rodada, por piores que sejam, ajudam a direcionar o algoritmo para a resposta mais adequada, e isso define bem o conceito de heurística aplicado aqui, que é usar dados sobre o problema para se chegar na solução, neste caso, é usar a própria "geografia" desse espaço de busca para se chegar no ponto mínimo ou máximo.
Para resumir e agora podendo falar tecnicamente pois agora é compreensível depois dessa explicação toda, o aprendizado de máquina em grande parte se resume a aplicação de um algoritmo de otimização, que nada mais é do que uma busca heurística, e aqui dei um exemplo de um algoritmo bio-inspirado, mas no caso de redes neurais densas que por si só já tem um custo computacional alto para qualquer execução, o método usado é mais "matemático", usando a própria inclinação da região que se está no "terreno" para direcionar o passo a ser dado. A este ponto, imagino que para quem nunca teve contato antes com esses assuntos, o aprendizado de máquina começa a partecer bem mais... material, palpável, mais próximo e menos abstrato. Em grande parte é como num jogo de adivinhação em que cada tentativa recebemos alguma dica sobre como estar mais perto da resposta, sem precisar percorrer todas as possibilidades, mas ao mesmo tempo imagino que o contraste entre o mito da IA perfeita que faz tudo como que por mágina, as mesmas que frequentemente aparecem em notícias sobre tecnologia sendo propagandeadas como absolutamente confiáveis e melhores que humanos. O fato é que essa redução a nível numérico é uma abstração que impede ir além disso da representação gráfica, por isso IAs são impossibilitadas de lidar com conceitos, tudo é muito bruto em apenas dados sem teorias ou sentidos por trás, mas ainda assim há um esforço em relacionar o aprendizado de máquinas com aprendizado de humanos e outros animais como se todos aprendessem assim, só que não é desse jeito que a banda toca.
Conexionismo
Eu costumava dizer que o que há de teoricamente mais moderno em IA hoje (redes neurais densas como essas da tal IA que sonha e a GPT) nada mais é do que implementações de teorias dos primórdios da psicologia, quando ainda tentava se separar da psiquiatria e tinha fundamentos quase exclusivamente biológicos. Justamente dessa época que nascem teorias sobre a cognição que nos importam aqui, como é o caso do behaviorismo em seus primeiros momentos, que é o que fundamenta o aprendizado de máquina da forma como utilizamos hoje. Para quem não ligou o nome à coisa, falo daquilo que tornou famosos os experimentos de Pavlov com cachorros. Apesar de que em meio a área de educação se fale mais de Skinner quando se toca nesse assunto, aquele mesmo imortalizado na homenagem feita pelos Simpsons (Diretor Skinner é uma referência a ele 😆). Ele, pelo menos tinha uma noção de cultura e civilização nos seus pensamentos tecnicistas sobre o ensino, afinal se trata acima de tudo de uma reprodução de um modelo de sociedade idealizada a partir de determinado viés, que ao menos aqui no Brasil se tornou bastante popular na administração pública durante a ditadura militar.
Talvez seja mais correto começar com Thorndike, afinal o termo conexionismo vem dele e atualmente quando se fala de aprendizado de redes neurais no campo teórico, se fala de conexionismo apesar de algumas diferenças do que foi definido por Thorndike. Foi ele que dizia que a repetição era fundamental para gravar nas sinapses o que foi aprendido além de ser pela repetição que também se pode apreender as coisas, criando uma compreensão do assunto, enfim, ele é que ajudou a popularizar lá pelos anos 30/40 do século XX essa prática adorada por vários professores de exatas em passar listas intermináveis de exercícios como se a simples repetição garantisse o aprendizado em profundidade e não apenas a reprodução de procedimentos. Além disso de haver avaliações frequentes sobre os educandos, o que significava ter de fazer várias provas, e aí outra subversão do sentido de aprender, se resumindo a realizar treinamentos, e nada mais justo do que essas listas intermináveis de exercícios. Acho que já deu para entender a relação entre as coisas e onde quero chegar, a alguns parágrafos atrás escrevi exatamente sobre isso no contexto do aprendizado de máquina.
A idéia básica do conexionismo, que é o termo mais adequado aqui por juntar elementos de diversas áreas como psicologia, biologia, estatística, etc. É justamente essa, usar estímulos ao estilo Pavlov para direcionar o comportamento do algoritmo: quando falamos em reforço positivo e negativo no behaviorismo, falamos em reforçar ações no sentido da continuidade do que já está sendo feito ou no sentido contrário, essa é uma perspectiva tão cartesiana que não há como não associar a um ambiente controlado como um laboratório ou um computador. E para decidir sobre os estímulos, se faz testes, avaliações e outras formas de extrair métricas à exaustão a cada passo, quantificar e medir está ao centro da prática. Admito que tudo isso faz completo sentido e é conveniente para uma máquina cujo objetivo é executar uma tarefa repetitiva, mas depois de tanto tempo, de se ter outras dimensões sobre o aprendizado, os estudos sobre cognição terem avançado tanto além do simples estímulo-resposta-memorização, a compreensão sobre a mente ter deixado de ser apenas como resultado da ação das sinapses e ter ganhado contornos que beiram a filosofia com a psicanálise ao lidar com a mente através de estruturas e relações lógicas ao dizer que estamos num contínuo exercício de interpretação e reinterpretação da realidade em nossa volta, onde o ego, superego e id vivem como num conflito que representa ao nível mais abstrato possível o cerne de nossas ações ao conceituar com princípios (prazer e responsabilidade) e pulsões (simbolizadas por Eros e Tanatos)... Enfim, há praticamente 1 século de estagnação na teoria ligada diretamente ao aprendizado, em grande parte porque não há como fugir da redução ao numérica/quantitativa além do enorme acervo de recursos e direcionamento do desenvolvimento de hardwares para dar suporte a tantas aplicações.
Mas de que serviria dar esses passos? Eu realmente não sei, mas é fácil perceber os limites do que se tem atualmente e como só manter a reprodução dessa forma de pensar sobre a estrutura dos algoritmos e as formas de lidar com o aprendizado tendem a uma inevitável estagnação, a qual já estamos. É curioso notar a reação geral a isso tudo: os algoritmos estão inflando, com a quantidade de parâmetros a serem otimizados no treinamento ultrapassando a casa dos milhões. Com o custo computacional cada vez mais alto, há de fato o estímulo a melhorias em processadores voltadas para o processamento numérico (cuja velocidade também tem crescido lentamente, diferente do que era no passado), o SIMD é um ótimo exemplo disso, mas isso não resolve o problema fundamental... Que problema fundamental? Todo algoritmo inteligente está inserido numa lógica de produção/atendimento de demandas, faz inteiro sentido seu uso como no auxílio a decisões sobre como tornar veículos mais seguros ou fazer motores elétricos mais eficientes, mas o uso que mais tem ganhado evidência ultimamente, exatamentes estes que envolvem algum nível de consciência e responsabilidade, conceitos sobre valores éticos e que justamente por serem tão insuficientemente quantificáveis, é impossível testar adequadamente. Falo desses sensíveis usos ligados ao sistema judiciário, ao recrutamento de pessoas, na segurança pública, nos veículos autônomos, etc. Continuando nessa direção, eu até diria que o problema real aqui, lá no cerne da coisa toda, é filosófico. E isso chega a ser até cômico: no artigo de 1959 escrito por Turing que é tido como um marco na pesquisa em IA, fala-se logo no início, forma ilustrativa apenas, como seria uma máquina que se comportam como humanos e como testar empiricamente isso, também em 1959 aquele artigo do NY Times sobre o Perceptron de Rosenblat, fala que a "coisa" poderia se tornar auconsciente, sendo que até uma definição clara sobre consciência ligada a esse ou outros contextos, assim como "inteligência", são tratados de forma tão fantásticas por tecnocratas e tão... incerta, superficial, muitas vezes como algo vago que mais sugere uma intenção do que realmente a coisa em si, que muitas e muitas vezes chega a parecer cômico de tão absurdo. É por isso que eu implico tanto com a "IA que sonha" 😂.
Espero que ao longo deste longo texto tenha sido possível entender como a simples redução numérica e representação espacial dos dados são absolutamente insuficientes para equiparar a capacidade de máquinas com capacidades humanas no que se refere a cognição e em especial ao aprendizado. Concordo com François Chollet ao dizer que coisas como jogos são insuficientes para medir a "qualidade" da inteligência de uma máquina em comparação com a inteligência humana, nós nos desenvolvemos como espécie para lidar com mundo complexo e um tanto quanto caótico, onde nossa capacidade de abstração/imaginação sempre foi fundamental para nossa sobrevivência, ao contrário de máquinas que são criadas em fundamentos estatísticos/matemáticos, tendo o algoritmo em si uma natureza repetitiva, e portanto, usar um algoritmo como o PSO ou algoritmos genéticos (que se baseiam no neo-darwinismo e na genética, garanto que é mais simples que o PSO), que vai executar a mesma fase de um jogo milhares de vezes, aprendendo/decorando os movimentos que deram certo e no final escolher só o que funcionou ignorando todas as milhares de tentativas que deran errado, nada tem a ver com o esforço humano de percepção e coordenação que envolve um humano jogando o mesmo jogo, passando dias para superar o nível mas com certeza sem as milhares de tentativas sistematicamente utilizadas. Falar assim tem 2 efeitos distintos: retira a dimensão fantástica do algoritmo como algo inexplicável/místico e em alguma medida aproxima da perspectiva humana de tentativa e erro mas com uma escala e sistematização obviamente não-humana, afinal nós nos desenvolvemos como espécie não para executar ações repetitivas em jogos, reproduzindo cegamente ações pré-determinadas com base em métricas, mas nos desenvolvemos para lidar com ambientes complexos como era a vida quando nossa espécie era caçadora-coletora, enfrentando os muitos perigos da vida na natureza.