Fundraising Emails as Data and WBB Games
I recently passed the 11-year mark of collecting political fundraising emails, which seems either noteworthy or problematic. Who wants more email, and from politicians seeking to raise money, to boot?
Me, as it turns out. Also, maybe you?
Aside from providing fodder for ridiculous social media posts, these emails are data, and worthy of treatment as such. As it turns out, there are plenty of good Python tools for parsing email inboxes, either directly or from exported MBOX files.
The trouble I had was in developing a good process for handling the literally thousands of emails that arrived every week from campaigns, political committees and adjacent grifters. Exporting an ever-increasing email inbox on a weekly basis takes a bit - my current export file is more than 5GB - and sharing that much data also has its issues.
For awhile I’ve been using Datasette to store this in a SQLite database, thanks to the kindness of Simon Willison and Alex Garcia, who created a Datasette Cloud instance for this data. I’m still interested in doing that, but haven’t yet developed an update routine that isn’t time-consuming or too complicated (that’s not a criticism of Datasette - I’ve got weirdly large data).
So while I figure that out, I figured I could take a page from my work on congressional statements and publish the email data as JSON files on GitHub. Here’s the repository for that work. And, like Congress Press, there’s a public-facing site with some basic stats and downloads.
The wrinkle is that I have - currently - more than 600,000 emails, and while many of them are fairly brief, there are some that have a decent chunk of text. These emails also have lots of HTML, so the JSON files I am providing include both the full text and a cleaned-up version:

That should make doing text analysis at least somewhat easier. I’ve already started extracting committee names from this data and will incorporate those results (or publish them separately now that these have unique IDs). There's still work to be done with this data, including assigning party identification to many emails, and analyzing the fundraising URLs present in them.
If you’d like to use collaborate on any of those (or something else), drop me a line at dwillis AT gmail.com.
Women’s College Basketball Game Data
Plenty of sites and services can offer you basic data on women’s college basketball games: Sports Reference, ESPN, the excellent wehoop package among them. But if you want play-by-play data, or structured information that matches what official college sites like, say umterps.com publish, you have to get that from individual team sites.
Fortunately for me (and maybe you), most collegiate official sites - here’s Maryland - use the same vendor: Sidearm Sports. And Sidearm sites have a lot in common, so much so that if you know the domain, you can usually fetch game data, including play-by-play details. As JSON.
Here’s an example: a Feb. 7 game between my beloved Terps and the Nebraska Cornhuskers (apologies to Matt Waite). In addition to play-by-play details, the data has everything from the attendance, names of the officials and even calculated summary and advanced stats. In other words, lots of things you can use to build dashboard or conduct analyses. I used it to build a small site that shows off Maryland stats for the previous 12 seasons.
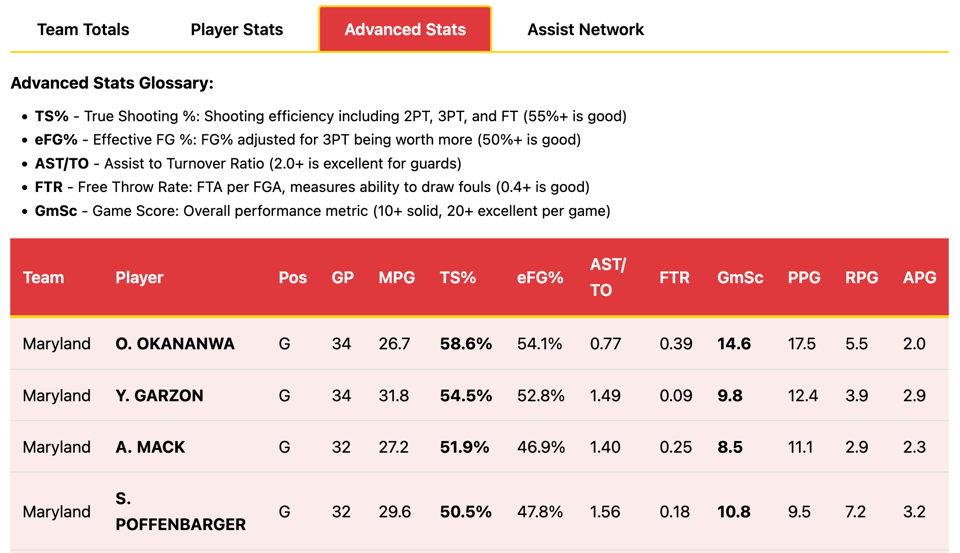
You can find all of the 200k+ game files I’ve collected in this GitHub repository, which admittedly is a bit unwieldy since it has folders for more than 1,000 NCAA teams across all three division. Some of the teams have data that does back 20 years; others only have a handful of seasons. Not everyone uses Sidearm or does so in a predictable manner; unfortunately that list includes some consequential teams such as South Carolina, Virginia Tech, LSU and Iowa, which have their own format that is similar but not identical, and often larger in size.
This week I took a spin through the repository to try and backfill as many teams as possible. The Python code that pulls in most of the JSON files can be found here. The possibilities for this data are pretty wide: substitution patterns, free throw shooting trends (how many players miss the first and make the second?) and more. If you do something with this data, I’d love to know.
Oh, and if you’re wondering if this could be done with other college sports, it absolutely could.