Why AI Companies School Like Fish, and More
Hi all,
I haven’t had much time for writing over the last month, which is a gift and a curse. I’m greatly enjoying the work occupying my time (stay tuned for details…) but enjoy these retrospectives.
Let’s just dive in.
A Recent Podcast Appearance: “Generative AI in the Real World”
Ben Lorica was kind enough to invite me on his O’Reilly podcast, to talk about context engineering. I really enjoyed this chat spanning context engineering as a term, context fails & fixes, the importance of domain knowledge, what DeepSeek revealed about our hopes & dreams, and how the line between post-training & applied AI is going to blur.
That last bit is something I’ve been thinking about a lot lately:
There’s pre-training, where you train on unstructured data and establish the model’s knowledge base and language capabilities. Then there’s post-training, which has lots of functions but I’ve started thinking about it as interface design… You’re teaching it how to chat with your. This is when it learns to converse. You’re teaching it how to use tools, specific sets of tools. And you’re teaching it alignment, what’s safe, what’s not safe, all these things.
But after the model ships, you can still RL that model. You can still fine-tune that model. You can also prompt engineer and context engineer that model. And this brings us back to systems engineering: I think we’re going to see that post-training all the way through to a final, applied AI product… that’s going to be a subtle, shades-of-gray gradient.
The only thing that’s keeping us from doing this now is a lack of tools, the operating system to manage the model from post-training to applied AI products. Once these tools exist, the difference between post-training and applied AI is going to get really, really blurry.
I really enjoyed this conversation. Check it out.
Recent Writing
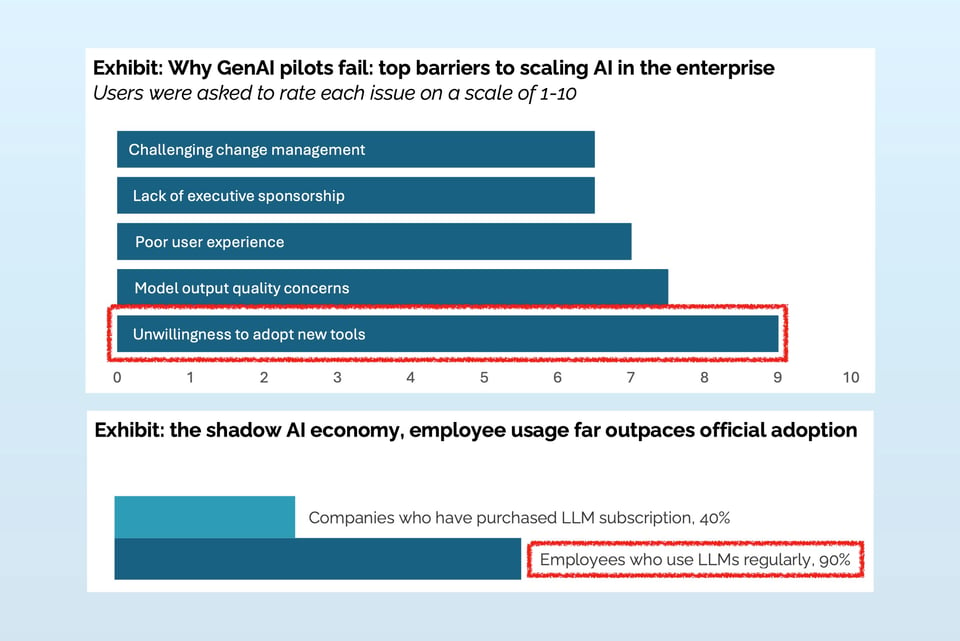
Enterprise AI Looks Bleak, But Employee AI Use Looks Bright
These two charts above come from the same report, the notorious MIT NANDA report that claimed, “95% of generate AI pilots at companies are failing.”
There’s plenty to discuss about the MIT report (and plenty to criticize), but the two charts above are the crux of it for me: business leaders believe the biggest reason their AI pilots are failing is because their employees are unwilling to adopt new tools… While 90% of employees surveyed eagerly use AI tools they procure themselves.

When an AI-powered product archetype emerges and catches the eye of the ecosystem, we enter a familiar pattern. Open source demos and tools pop up, followed quickly by a few fast-moving startups offering the product as a service. Finally, an incumbent clones the model and brings it to their existing user base and platform.
This cycle has happened at least 8 times, by my count. In this post we looked at past examples and identified a few lessons.
One take-away comes up often enough I’ll quote it here:
Considering both the rapid cloning problem and the speed of model advancements, I think every non-niche, applied AI start up needs to ask themselves two questions:
If a better model arrives tomorrow, does your product get better or does your backend get simpler? If your product doesn’t get better, you need to rethink. A better model simplifying your backend (by reducing the complexity of your prompts, your error handling, your infra, etc.) makes your product easier to clone.
If you are early to market with this use case, what are you going to do in a handful of months that will fend off Google/OpenAI/whomever’s entry into your market? Cursor and Perplexity are the rare examples that have managed to grow fast enough to be able to fend off larger entrants. What are you going to do, if you can’t go niche, to prepare your defenses?
Can Chatbots Accommodate Advertising?
Ads are coming to our chatbots. Someone’s gotta pay for the 700+ free ChatGPT users. But adding ads to AI assistants is a tricky task, because they’re, “so deeply accountable to your goals.”
In this piece we discuss the challenges and explore the options. The principles and tensions remain relevant, but hats off to OpenAI who’ve greatly increased their options since then:


Glimpses of the Future: Speed & Swarms
Every few months, I allow myself to tweak my development set up. I peruse new models, check out new apps, and see if any recent options are worth learning.
During my last exploration session, I had my mind blown a bit by incredibly fast models (30x faster than Claude Sonnet) and application-specific swarms (in this case, Rails). Both provided a glimpse of the patterns that await us as our AI-assisted coding tools mature.
Art Break
Four years after gold was found in California, here a map of the “THE BEST CENTRAL OVERLAND ROUTE” to Sacramento:
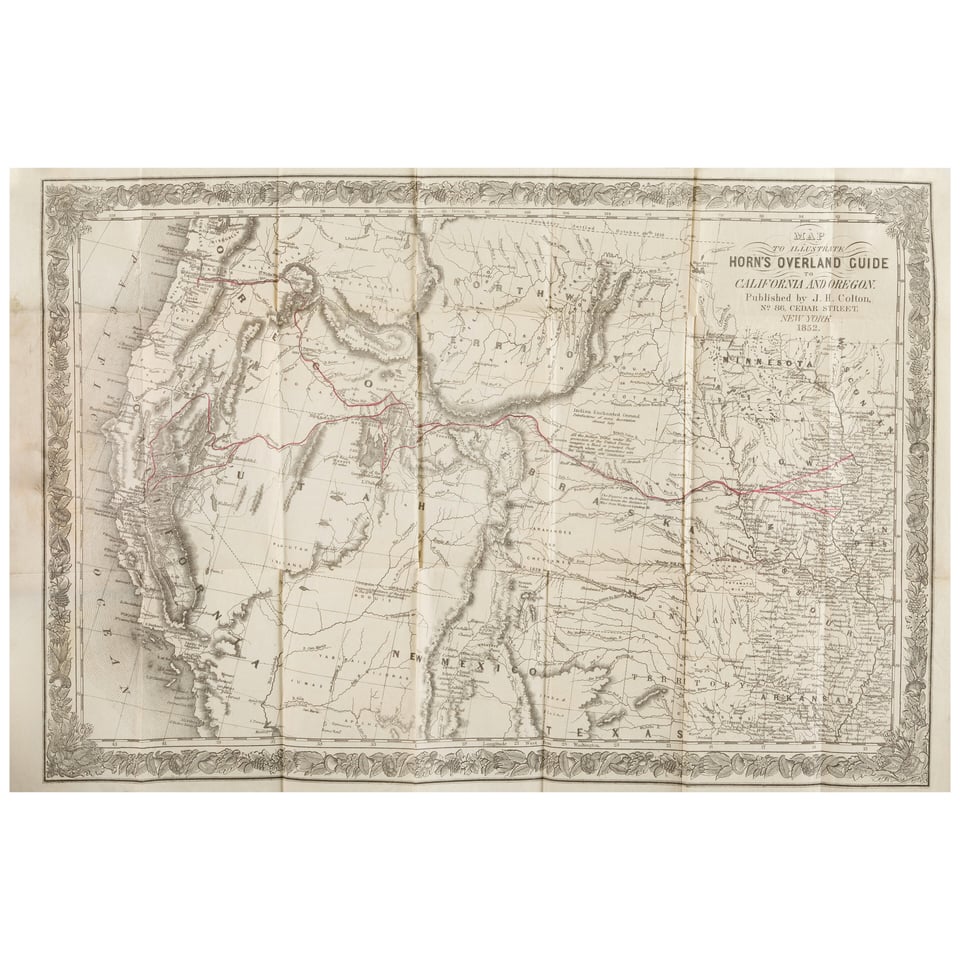
Starting bid: $3,200.
Until next month,