Can You Trust AI Scores?
Hey everybody,
There's a new technique available in Open Creativity Scoring: confidence-aware scoring. It provides two things - a better performing originality scores, and a measure of how confident the machine is in that score.
If we move toward automated scoring of open-ended responses, we need safeguards to be able to know how trustworthy those scores are compared to what we could have achieved with a trained expert. Now when Ocsai scores a response, it tells you how much it trusts that score — a number from 0 to 1. You can use this today with Ocsai 1 models at openscoring.du.edu, and it'll ship with Ocsai 2 when that goes live soon.
The technique is described in a pre-print with Selcuk Acar, "Know When to Trust: Making AI Scoring More Reliable for Educational Assessment".
What it does
When a language model predicts a token, it assigns probabilities to many possible scores. We've been throwing away all that information when we pick just one token.
Confidence-aware scoring does two things with that internal log probability:
-
Weighted scoring — instead of taking the single top prediction, it computes a weighted average across all likely scores. This is more accurate, especially in ambiguous cases.
-
Self-confidence — the probability the model assigns to its best guess becomes a trust measure. Higher confidence = closer to human judges, lower confidence = worth a second look.
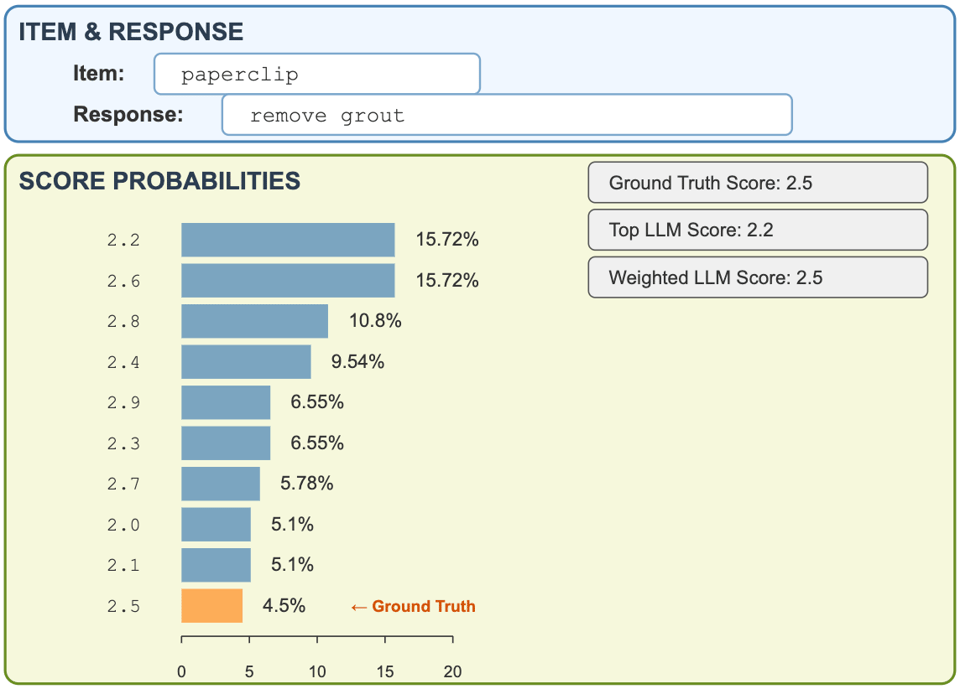
In the example above, human experts scored "use a paperclip to remove grout" as 2.5 out of 5. The model's top guess was 2.2, but its second guess (2.6) was equally likely. The weighted average across all possibilities? Exactly 2.5.
How much does it help?
Excluding low-confidence responses by confidence improves accuracy across all models we tested. The effect is consistent: if the model says it's unsure, it really is unsure.
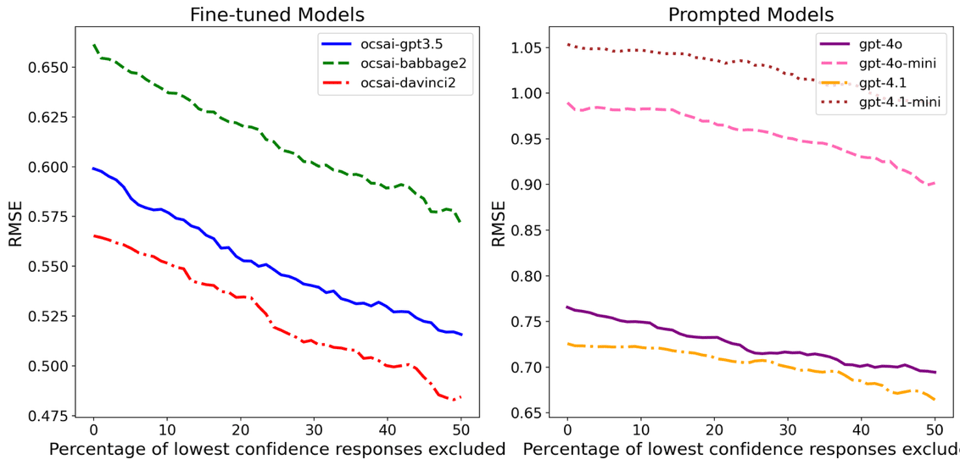
Meanwhile, with weighted scoring, the overall correlation with human judges goes from r=0.781 to r=0.812 with current trained models.
Using it in OCS
On the web interface, just score as usual — the confidence column now shows up in your results alongside originality scores (for Ocsai 1 and the 2, not in 1.5/1.6). Select Weighted Probabilistic Scoring for the better scoring method.
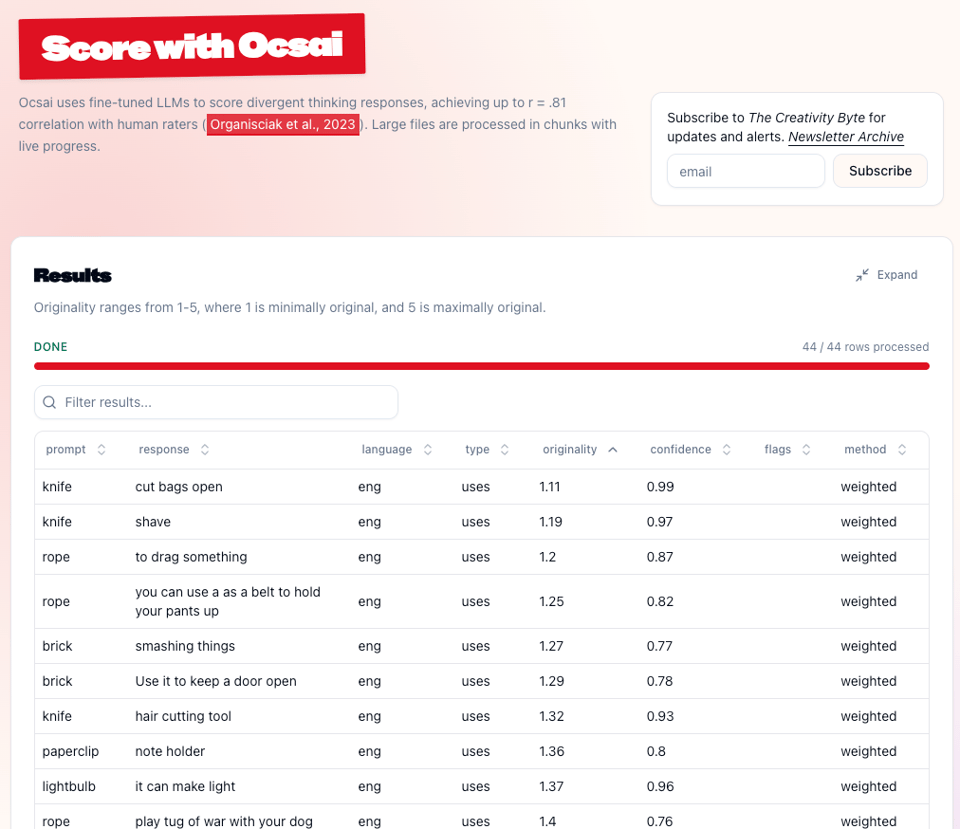
The API works similarly. Through the Python library, set top_probs=5 to get log probabilities back:
scores = scorer.score(
target="brick",
response="makeshift anchor",
task_type="uses",
model="ocsai1-4o",
top_probs=5
)
# Returns score, confidence (0-1), and method
The confidence library
Beyond Ocsai, we released a standalone Python library called confidence that provides drop-in confidence-aware scoring for OpenAI, Gemini, and HuggingFace Transformers. If you're building your own scoring system — or any system that derives a number from an LLM — you can use it to extract weighted scores and confidence measures. I'll share more details on using the library in a future post, but it's ready now and runs with a single command. Early version, so here be dragons.
Ensemble Scoring
Our paper evaluates one more thing: ensemble models. If you combine the outputs of two models, your score is likely to be better. That's true most of the time in most computing settings, and is here too. We didn't implement automated ensembles, but if are using Ocsai for a setting where you need to eke out the best possible performance, you can score with two models and combine the score.
A note on the old confidence score
I've been interested for some time in this notion of signals that can help determine trustworthiness of an AI response. The improvements in automated scoring caused me some concern, because it went from research curiosity to something that you can see being used in applied settings. Getting better meant it suddenly wasn't good enough!
Some of you may have noticed it that using Ocsai 1.5/1.6 already returned a confidence value, from 1-3. That was a different measure — the model had learned to generate its own confidence number as part of the output, an artifact of training. It worked to a degree, but our focus with Ocsai 1.5/1.6 was on multilingual training and a more generalized training that allows custom tasks, and we never fully explorer that measure.
The new log probability-based measure described here is more robust and interpretable. The new measure is on a 0–1 scale derived from the model's internal probability distribution, not a learned output.
Links
Paper: Pre-print
Code + data: https://osf.io/xujt5/
Confidence library: https://github.com/massivetexts/confidence
— Peter