Not so fast.
Everyone says Anthropic won the coding race. The new benchmark says otherwise.
The benchmark everyone's arguing about
For the last six months to year, the assumption was that Anthropic had won the coding fight because they were the first on AWS Bedrock. Claude Code became the default and people built their whole setup around it. Then Datacurve dropped a benchmark last week called DeepSWE, and the verdict came back

DeepSWE scores long-horizon software engineering, the multi-step work that runs for an hour, rather than the leetcode-style puzzles older benchmarks reward. The numbers: GPT-5.5 landed around 70%, Claude Opus 4.7 around 54%. That's 16pp spread, and it's why my feed has been arguing about it all week.
Note: Don't sleep on gpt-5.4xhigh when usage based billing drops.
 DeepSWE leaderboard, Datacurve (May 2026). GPT-5.5 at 70% ±4%, Claude Opus 4.7 at 54% ±5%.
DeepSWE leaderboard, Datacurve (May 2026). GPT-5.5 at 70% ±4%, Claude Opus 4.7 at 54% ±5%.
One benchmark doesn't settle it, though, even if it's the one that most closely mirrors my experience. ChatGPT (browser) still owns general use by a wide margin, and Codex went from about 600K weekly users in January to 4 million by late April (since reported around 5 million), so OpenAI's momentum is real. But Claude earned its agentic ground for a reason, and part of it is reach: it's the only frontier model you can run on all three big clouds, AWS, Google, and Azure. OpenAI was effectively Azure-only until its models landed on AWS Bedrock a few days ago. The lead keeps moving, and that's the real argument against locking yourself to one of them.
The argument keeps missing one step: a benchmark scores a model, not your setup. And a setup tuned for one model doesn't carry to another. When LangChain's team ran a harness built for Codex on Claude instead, the same harness dropped to 59.6%. So when GPT-5.5 beats Opus on DeepSWE, part of what you're seeing is whose harness the test was built around.
I stopped defaulting to a single model
I build one harness and swap the model underneath it by task. The harness is the part that compounds: your CLAUDE.md, your skills, your MCP setup, your verification gates. The model is a component you route to based on who's winning that kind of work this month. Right now, for long-horizon engineering, that's GPT-5.5, and it's the runtime I reach for first. That'll change, but the harness won't.
The thing that makes swapping cheap is a one-file bridge between the two. Codex reads AGENTS.md, Claude Code reads CLAUDE.md, and a single pointer keeps them in sync so you're never maintaining two sources of truth. Setup's below, and it takes about five minutes. The payoff: switching from Claude Code to Codex on the same repo costs nothing, and when the leaderboard flips next quarter you only have to change the model.
Setting up Codex next to Claude Code
If you've never run Codex, here's the whole setup. It is included with ChatGPT Plus at $20/month, so if you already pay for ChatGPT you have it.
1. Open your existing repo in Codex. Install the Codex app (or the VS Code extension) and point it at the same project folder Claude Code already uses. On first run it offers to import your Claude settings, skills, and plugins.
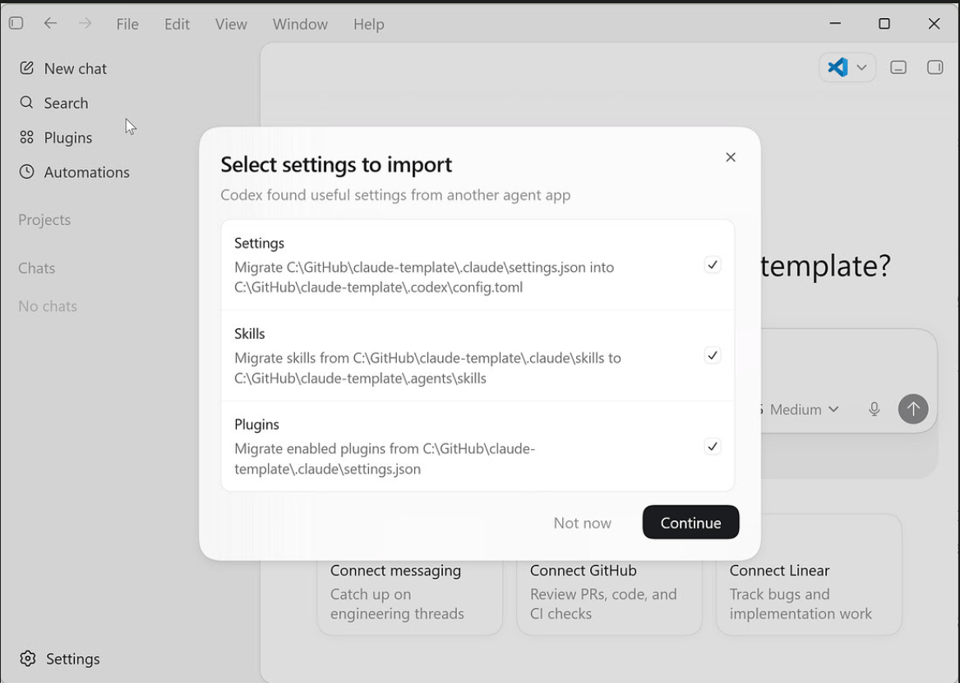
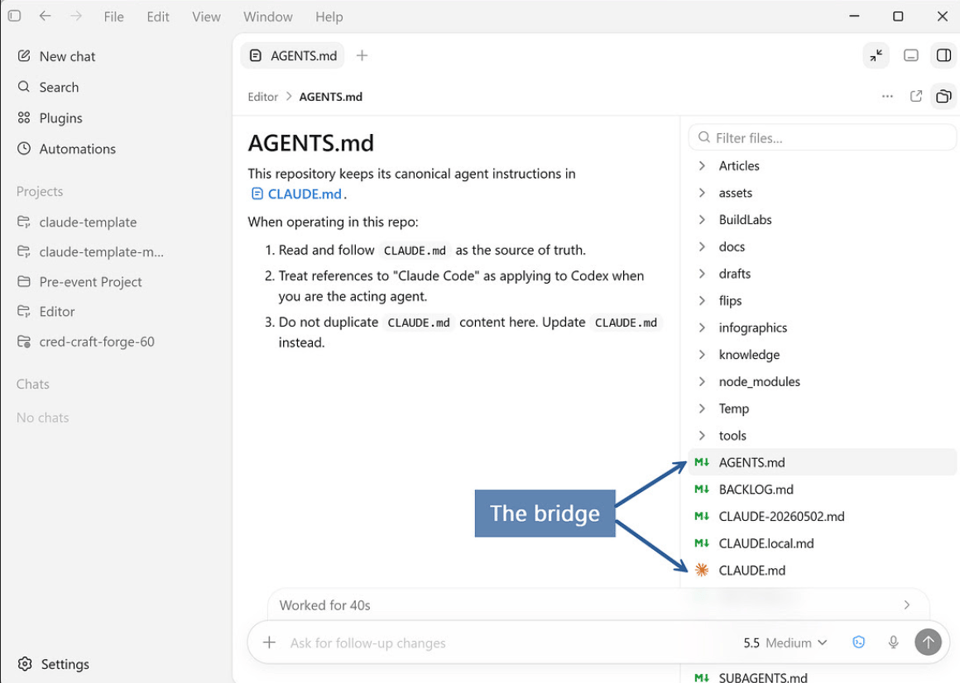
2. Drop in the bridge. Add an AGENTS.md at the repo root that points Codex back at your CLAUDE.md:
# AGENTS.md
This repository keeps its canonical agent instructions in CLAUDE.md.
When operating in this repo:
1. Read and follow CLAUDE.md as the source of truth.
2. Treat references to "Claude Code" as applying to you when you are the acting agent.
3. Do not duplicate CLAUDE.md content here. Update CLAUDE.md instead.
Now both runtimes read the same instructions. CLAUDE.md stays the long, canonical file. AGENTS.md is just the pointer.
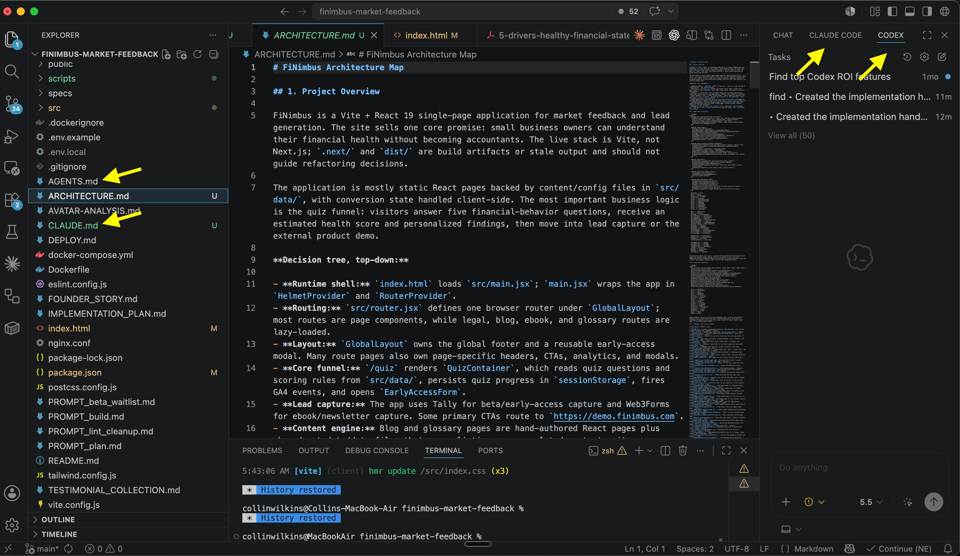
3. Run them in one window. The Codex and Claude Code extensions both live in the VS Code sidebar. Switch by tab on the same repo, same files. Hand each task to whichever runtime you want, and use the other for a second pass when you want fresh eyes.
What this actually is →
If "build one harness, swap the model" still sounds abstract, this is the mental model under it: what a harness is, what goes in it, and why it's the layer worth investing in while the models trade places.
CTA
If you're running one AI tool and wondering whether the other is worth the switching cost, reply and tell me what you build in. I'll tell you where I'd start and whether a bridge like this is worth it for your setup.
Quote of the Week
"A ship in harbor is safe, but that is not what ships are built for." — John A. Shedd
You can argue benchmarks and tune a harness until it gleams but none of that is the work. Pick the model that's winning today, point AGENTS.md at CLAUDE.md, find what works for you, and ship the thing you've been planning.
— Collin