Managing Django’s Queue
With the Django 5.2 prerelease cycle now in play, eyes can turn to what might come in for Django 6.0. Top of that list is the interface part of django-tasks, the proposal to bring background task handling into Django.
If you’ve run any queuing system for any length of time, you’ll know that they don’t like being run at anywhere near capacity. You think it’s your queue — Oh it’s Celery’s fault again — but it’s not: it’s just math. I’ll quote Dan Slimmon’s classic article on the topic, The Most Important Thing to Understand About Queues:
As you approach maximum throughput, average queue size – and therefore average wait time – approaches infinity.
If you run your queue hot, it backs up fatally. (I’m not going to explain that. Go read the article. But it’s true.)
The point is that we run Django kind of like that. Back in November, I talked about this in my Thoughts on Django’s Core:
There are currently 954 open accept tickets on Django. There are currently 260 open pull requests on the Django repo. We have two Fellows, one of whom is part-time, so 1.5 full-time Fellows to work on all of those, as well as doing releases, security report handling, and community work.
It survives. Just. It’s more or less stable. Just. But there is approximately zero additional capacity to expand.
There’s only so much throughput. New tasks come in at more or less that rate — sometimes a bit slower, sometimes a bit quicker — but certainly with nowhere near the headroom we’d want if architecting a low-latency task handling system. If you’ve ever wondered why your PR takes as long as it does to make progress, that’s why.
… and therefore average wait time – approaches infinity.
§
It’s with that background in mind that I saw Christopher Neugebauer’s recent talk, An Obvious Statement About Open Source:
It’s great. Do give it a watch.
Neugebauer’s main point is that we folks involved in open source need to be the ones who write the narratives about it. That hasn’t really happened so far and, to fill the gap, outsiders have told the stories that then set the terms of the debate. To our detriment, as it happens.
Neugebauer uses two key examples from the literature. Eric S. Raymond’s (shall we say) classic, The Cathedral and the Bazaar and the much more recent Working in Public: The Making and Maintenance of Open Source Software (WiP), by Nadia Eghbal.
I found Neugebauer’s argument compelling. It’s a great talk — do go watch it, really. But I had a bit of cognitive dissonance regarding his criticisms of Working in Public. I’d read it back in 2020 and thought of it fondly. I had memories of it describing exactly many of the challenges that we face in Django. As I’d read it back then, I’d felt seen. Given the talk, I had to dig back into that.
Over the Christmas holidays, I decided to reread Working in Public. There’s still a lot in it that does capture the problems we face, but several years later, the impression I took from it was much different.
I began a longish thread of thoughts as I was reading it on Fosstodon:
Rereading “Working in Public”. I remember being enthused by it first time round. Several years later it just reads like a dystopian hellscape.
Some folks picked up on that, and there are some interesting comments. Will and I also chatted about it on the podcast for our first episode back after the break. Do check those out.
I want to talk about Working in Public’s analysis here — as I say, I think there’s still much it does capture — but if I’m looking for the underlying difference in perception, it’s that the book’s tone celebrates the aggregating platform effect of GitHub-driven development. That feels dated.
As we stand here now, with Enshittification the term du jour, and seemingly ubiquitous, it’s difficult to recapture any joy around platform effects:
While some like to grumble at GitHub’s homogenizing effects, what happened in open source isn’t much different from what happened to the rest of the internet. Before platforms, our online world was a scattered collection of forums, blogs, personal websites. — WiP Ch3.
I just want to say, exactly.
§
Working in Public introduces a way of categorising projects based on their contributor and user growth.
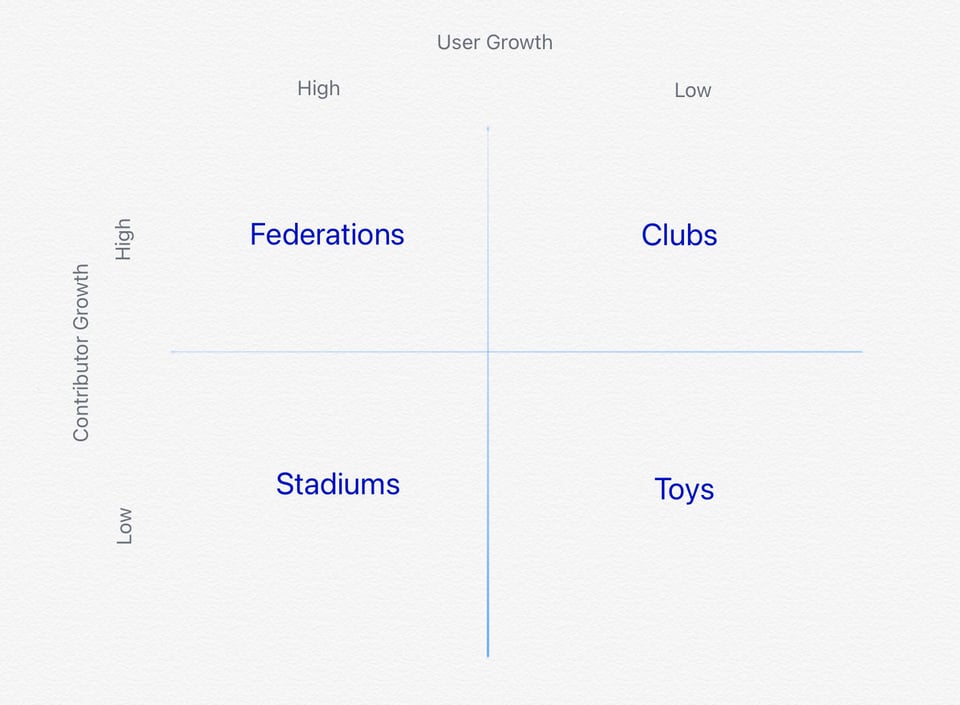
At the bottom right, with both low user and contributor growth, we have Toys. This might be your personal project, that maybe only you use, that likely only you contribute to.
On the top right we have Clubs. Here there’s still not masses of users, but a good number of those people who do use it are also helping to keep it updated. Many of the long-standing packages in the Django ecosystem fit this pattern.
On the left column we have high user projects. This is where Django itself sits.
The choice then is between two models: Federations, which have high contributor numbers and growth, and Stadiums, which have low contributor numbers.
Numbers are relative here. Every large project has only a few contributors compared to its total user base. The question is whether, within that, there’s a broad base of contributors, with new ones being welcomed, or if rather there are a few stars, whom everyone else just watches.
Django clearly wants to inhabit the Federation space. We actively aim to encourage a wide contributor base.
Working in Public’s core argument is that the platform nature of GitHub-driven development elevates extractive contributions. These then undermine the environment needed to enable new contributors. It raises the volume of traffic so much that projects are forced into the Stadium type model instead. In so doing, projects need to further embrace platform-based development, as the only way to manage (essentially one-way) communications between the small number of contributors and the wider user base.
From Django’s perspective, it’s a vicious circle. This is what I meant by dystopian hellscape.
I don’t want to here just quote Working in Public at length. You can go read it; I pulled out a few choice ones on the Fosstodon thread.
What’s interesting is that the book’s examples — of needing to maintain a code-of-conduct, of the difficulty of getting a contribution merged, of long and tiring discussion threads, and many more — all describe the situation in Django to a tee. But almost all of them are about projects apart from Django. These are general problems in open source. They’re not something that we’re doing particularly wrong (not per se).
The challenge we face is how to limit the extractive requests so that we can maintain the community we aspire to. Django is well-used. We can fund-raise to support a Stadium-like approach to keep it running if we need to. But that would be defeat in my book.
Current Django Fellow, Sarah Boyce commented on the Fosstodon thread:
Perhaps having a culture change where folks give attention to others before they can request attention themselves would also be interesting.
A lot of contributors work on only their own stuff. It makes sense also - giving attention is hard and doesn't get a lot of credit. I would say 90% of contributors ask more than they give. A handful of people give more than they ask
I don't think it's a problem unique to Django but attention is a finite resource
§
Dan Slimmon finishes his article about queues with a discussion of What can be done about it?:
To reiterate:
As you approach maximum throughput, average queue size – and therefore average wait time – approaches infinity.
What’s the solution, then? We only have so many variables to work with in a queueing system. Any solution for the exploding-queue-size problem is going to involve some combination of these three approaches:
Increase capacity
Decrease demand
Set an upper bound for the queue size
I like number 3. It forces you to acknowledge the fact that queue size is always finite, and to think through the failure modes that a full queue will engender.
On increasing capacity, there’s always mention of Another Fellow. If your queue is overwhelmed, then you can add another worker. This would absolutely help, at least in the short term. I do worry that it’s like adding another lane to a road, though. Soon enough, the traffic is as bad as it was before, but there’s just more of it.
Getting community members doing a significant amount of triage and pull request review (to the point where PRs are fully ready to merge) might help too. If I’m honest, though, I’m doubtful this would change much on its own.
On decreasing demand, there’s talk currently about how we can better handle new feature requests and ideas. These are among the most extractive of demands on a maintainers time. Most ideas lack context of why things are the way they are, and communicating that can be difficult at best. The person making the request is often left feeling like they’ve not been listened to.
Related, and on setting an upper bound, having a formal Roadmap might help to scope individual releases, so the pressure to try to include every single feature we can, in every release, would be eased.
§
These are all tactics worth trying. In particular, removing the expectation that the Fellows need to respond directly to every request made of them will ease their load.
At a fundamental level, though, I think our problem in Django is that we have only a single pipeline, a single queue — a single bottleneck that everything has to go through.
Again, I talked in my Thoughts on Django’s Core about how third-party apps in the Django ecosystem are undervalued — or at least perceived that way. There’s this constant desire to merge more and more into Django itself.
With a constant throughput — our fixed Fellow capacity — all that does is to slow everything down, for everyone. By having everything in the django/django repo, and everything going through the Fellows, we’re forced ever more into a Stadium-like model where the development of Django happens just by the few.
You don’t have to be Fred Brookes to see that in order get anything done, coordination costs need to be kept down. That means group size needs to be constrained. In an open platform environment, like GitHub, that means (of necessity) that potential contributors need to be turned away (or discouraged).
That’s not what we aspire to with Django. But short of breaking the cycle somewhere, it’s unavoidable.
§
The question then is: What could a functioning Federation look like?
Working in Public focuses almost entirely on the left-hand side of its grid. On Federations and Stadiums. Due to its argument, it is focused much more on Stadiums. It doesn’t really look at Federations too closely. (This is part of Christopher Neugebauer’s complaint in the talk, linked above.)
The right-hand side of the grid, the Clubs and Toys aren’t genuinely considered. The very name Toys implies what’s thought of it — these aren’t proper projects, is the claim. But of course — in many cases — they are. You build a project out for your work. Maybe no-one else uses it, perhaps only very few, but it’s an essential lynchpin for the businesses built upon it. I can think of probably 100 packages in the Django ecosystem that fit that description. Easily. (We need a better name than Toys.)
If you talk about a Federation, you need to ask a Federation of what? (A Federation of Planets?)
I suggest a successful open-source Federation would precisely be made up of the very Clubs and Toys that Working in Public ignores.
Our challenge in Django — if we’re serious about wanting to maintain the community that we aspire to — is to really think about federation. We’ve got an outstanding ecosystem. What do we need to do to enable and nurture it? How do we protect it from The GitHub Effect?
§
In terms of queues, federation serves to increase capacity. Instead of just one pipeline, one bottleneck, there are many. Each with a lower demand, and a less burdened worker, or set of such.
In the short run, whilst the high-level interface for django-tasks needs to be part of Django itself, it would be nice to keep the DB worker separate. Why tie that to Django’s release cycle? Why add to the queue there?
How we package that is an interesting question. We still want it to be easy. Pip extras are one possibility:
$ pip install django[tasks-db]
… Or something.
Could we push that further? FastAPI has you install fastapi[standard] by default.
What if it becomes unmaintained? — not django-tasks, but in general, of any package we point to, or extract.
Well, one complaint is that we keep adding to Django but never take anything out. If something becomes unmaintained, maybe that’s a sign it’s not essential. Perhaps it should be retired.
Django is so stable, it’s rarely difficult to update an old package so that it works again if you need it to. If a company is depending on a package, they’ll do that work. That’s totally fine.
Then there’s a social thing. Folks will make comments on social media, Oh so-and-so package hasn’t been updated. But they’ll neither contribute themselves, nor fund the development it needs.
Who are these people complaining?
Precisely the kind of extractive drive-by users that GitHub encourages. Precisely the kind of users that undermine the common good.
Precisely the kind of users that — if our community is flourish — we need to ignore.
Oh, a package you want to use is under-maintained? What are you going to do about that? Are you going to join the club?