🔥 Ha salido scikit-learn 1.2 con un montón de novedades, y entre ellas una muy deseada desde hace años: ¡todos los transformers aceptan y devuelven dataframes de pandas! Esto significa que si tienes un Pipeline complejo con muchos pasos, ColumnTransformer, etc será capaz de, por ejemplo, retener el nombre de las columnas. Esto es un salto cualitativo en la forma en la que veníamos usando scikit-learn hasta la fecha y estoy deseando probarlo.
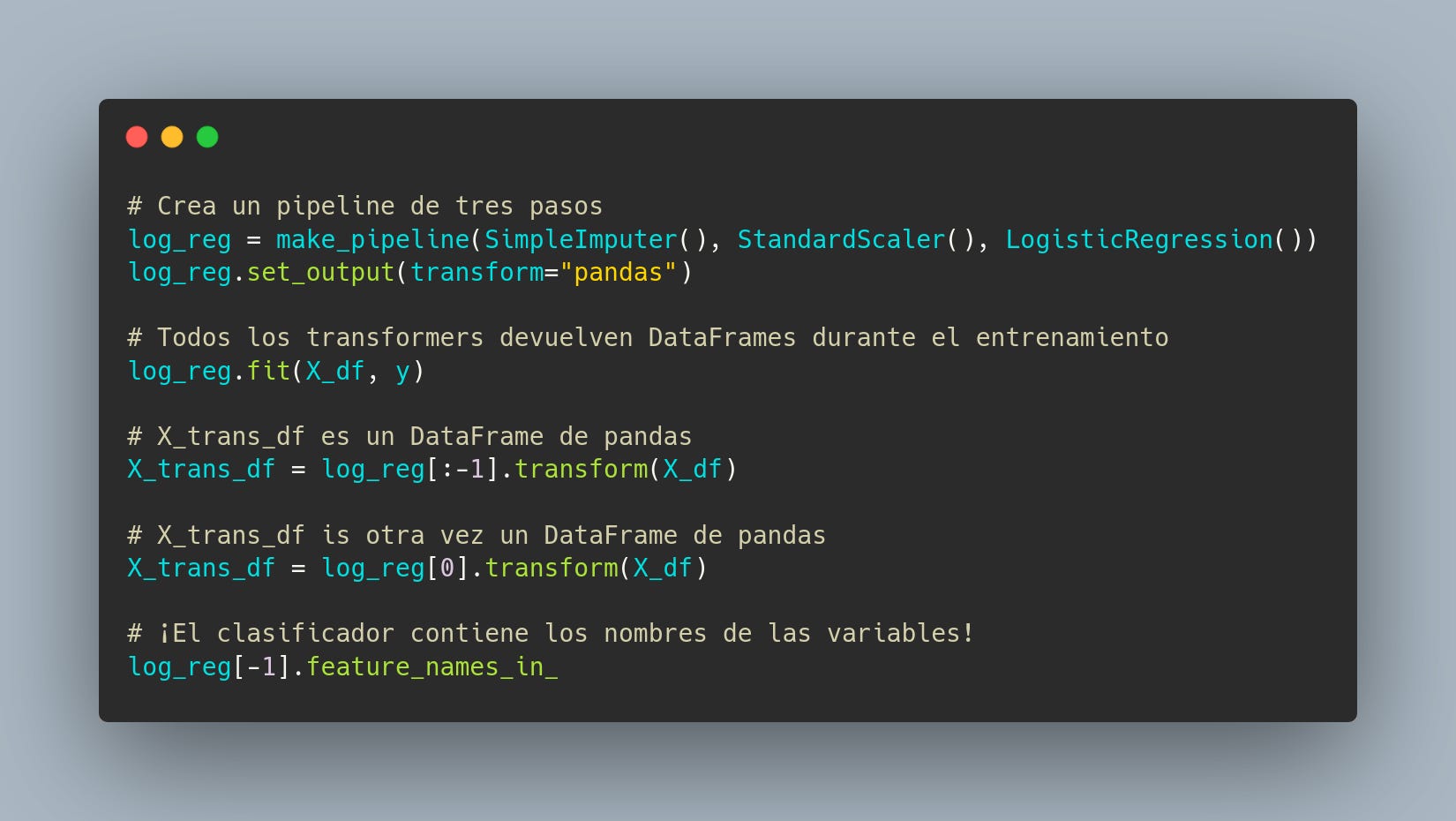
Tienes más información en la SLEP 18 (siglas de scikit-learn enhancement proposal). Nótese que la petición original data de 2015 y que ya había experimentos como sklearn-pandas, pero para integrar esos cambios en el proyecto han hecho falta muchas iteraciones. ¡A veces los tiempos en el código abierto son así!
🚀 Tenemos versión nueva de Jupyter Server, 2.0 - aunque es una pieza interna de Jupyter con la que los usuarios no interactúan directamente, es muy importante porque allana el camino para cambios grandes en el ecosistema: identidad (importante para cuando lleguen los notebooks colaborativos), autorización más granular, un sistema de eventos para comentarios y notificaciones, y mucho más.


Por otro lado, he descubierto que los proyectos de RAPIDS como cuDF, cuGraph y demás vuelven a ser instalables con pip. En un momento dado dejaron de dar soporte para centrarse en conda, pero parece que ya han encontrado una forma de producir wheels también.

💡 Como cuenta Merve Noyan en su LinkedIn, Hugging Face ha creado su propio formato para serializar modelos de aprendizaje profundo llamado safetensors. Permite inspeccionar el archivo sin cargarlo completamente y otras funcionalidades interesantes.

También he descubierto Lightly, una biblioteca Python para aprendizaje autosupervisado con imágenes.

📚 ¡MicroPython ya se puede utilizar en Arduino! Se pueden consultar las placas disponibles en la documentación oficial.
Y para terminar, me ha encantado como siempre esta visualización de Dialid Santiago hecha con matplotlib:

The CIR process is used to model #interestrates
dX_t = a(b - X_t) dt + c X_t^{1/2}dW_t
✅ Mean reversion ✅ Marginal distribution X_t~non-central Chi-square ✅ Envelope made of confidence intervals
#Python

🤔 Se suele comentar que los científicos tienen malas prácticas de programación, y el impacto que tiene esto. Este artículo que comparte Ethan Mollick arroja un poco de luz sobre el tipo de errores que ocurren, y qué campos tienen una tasa de error más alta. Parece que en Física están en apuros.

74% of R files included with papers & replication datasets failed to execute, but about a third of those could be fixed with simple code changes. Physicists were the worst offenders. nature.com/articles/s4159…


¿Estás buscando una alternativa a Heroku? Yo he migrado a Railway (enlace afiliado) y me encanta que las aplicaciones no “duermen” así que el tiempo de respuesta es siempre rápido ⚡
Acabas de leer la edición #49 de El noticiero de Juanlu. También puedes explorar archivo completo de este boletín.