🚀 Esta semana ha salido dbt 1.3.0, una versión muy esperada porque ¡incluye la funcionalidad de modelar datos con Python! Hay todavía muchos cabos sueltos, así que si usas dbt y te interesa, puedes participar en la discusión.
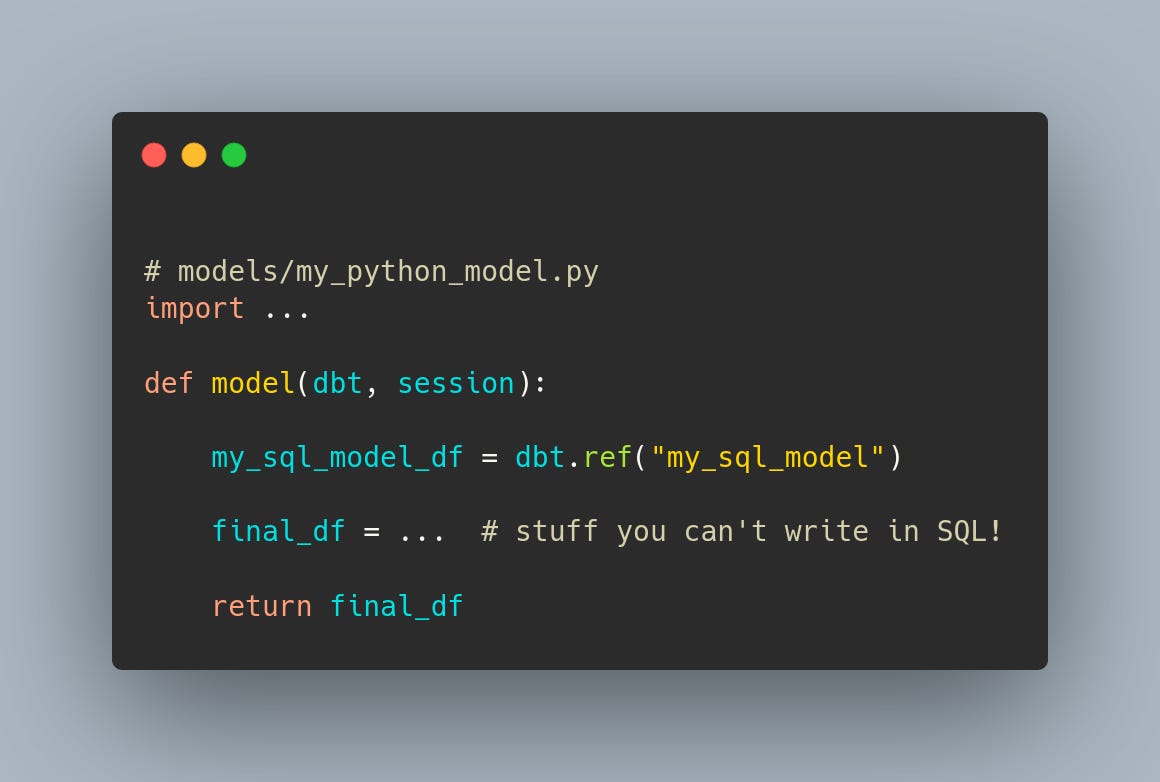
También ha salido Panel 0.14, con varias novedades muy jugosas: compatibilidad con Pyodide y PyScript (es decir: ¡corre en el navegador sin backend!), mejoras sustanciales de rendimiento, y una extensión de Sphinx para crear documentación interactiva.

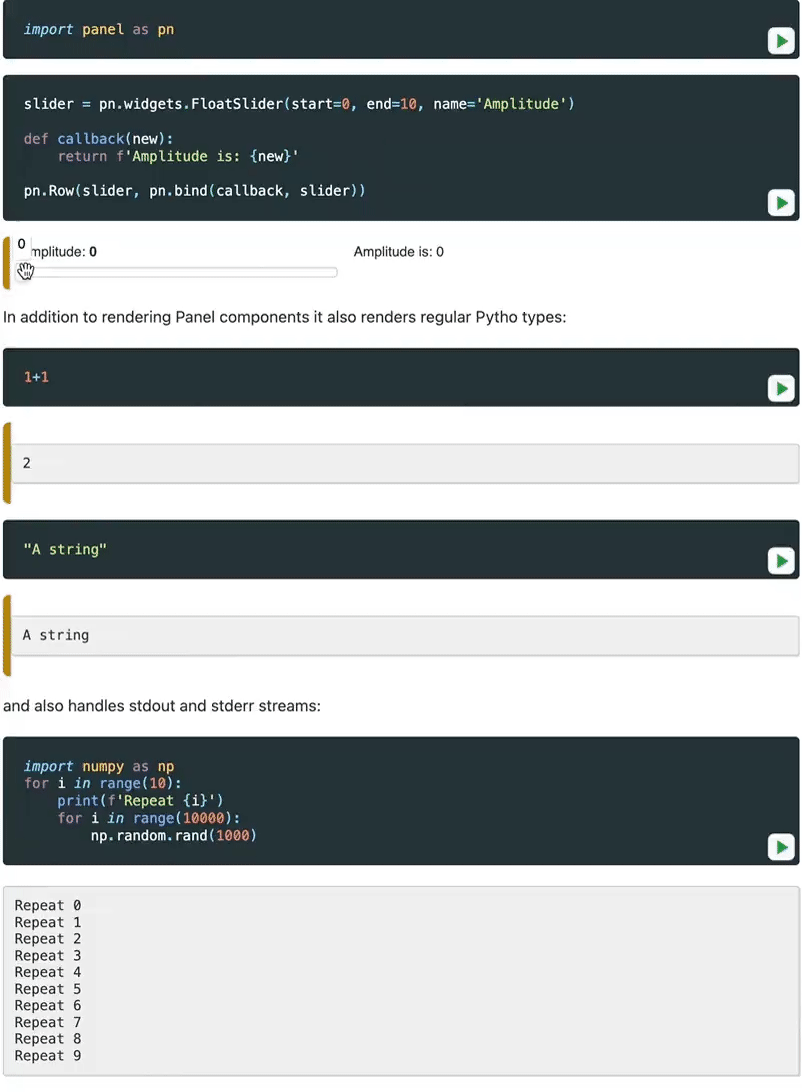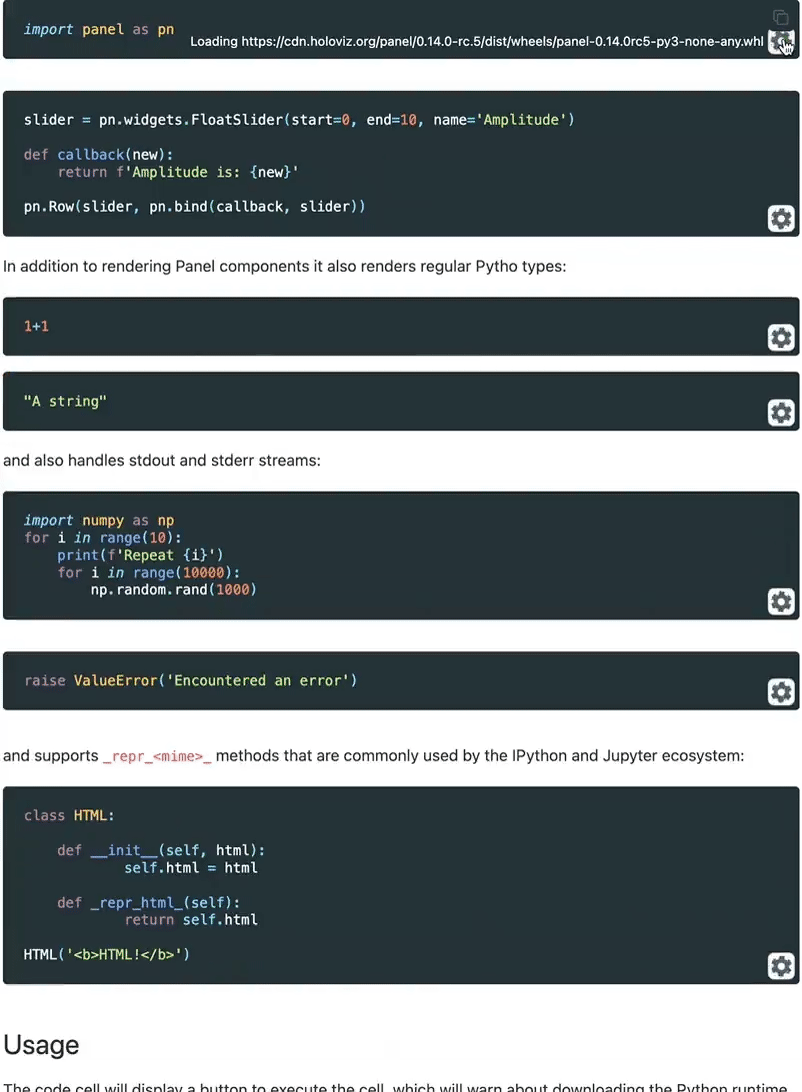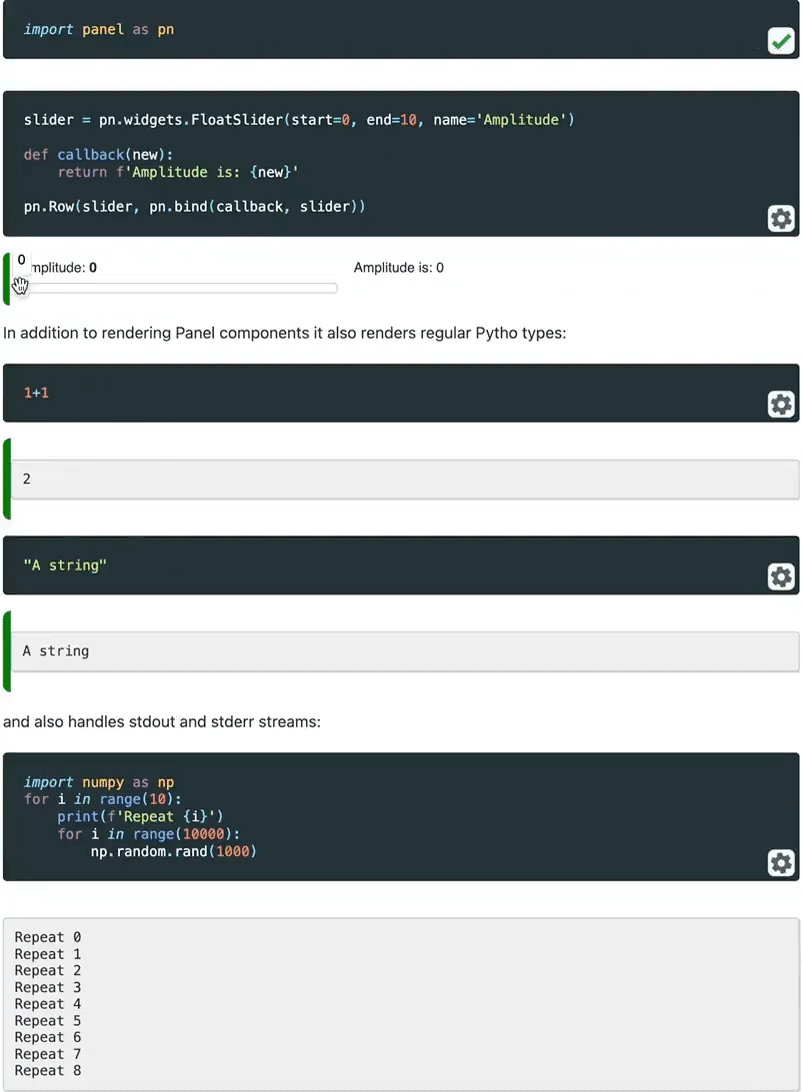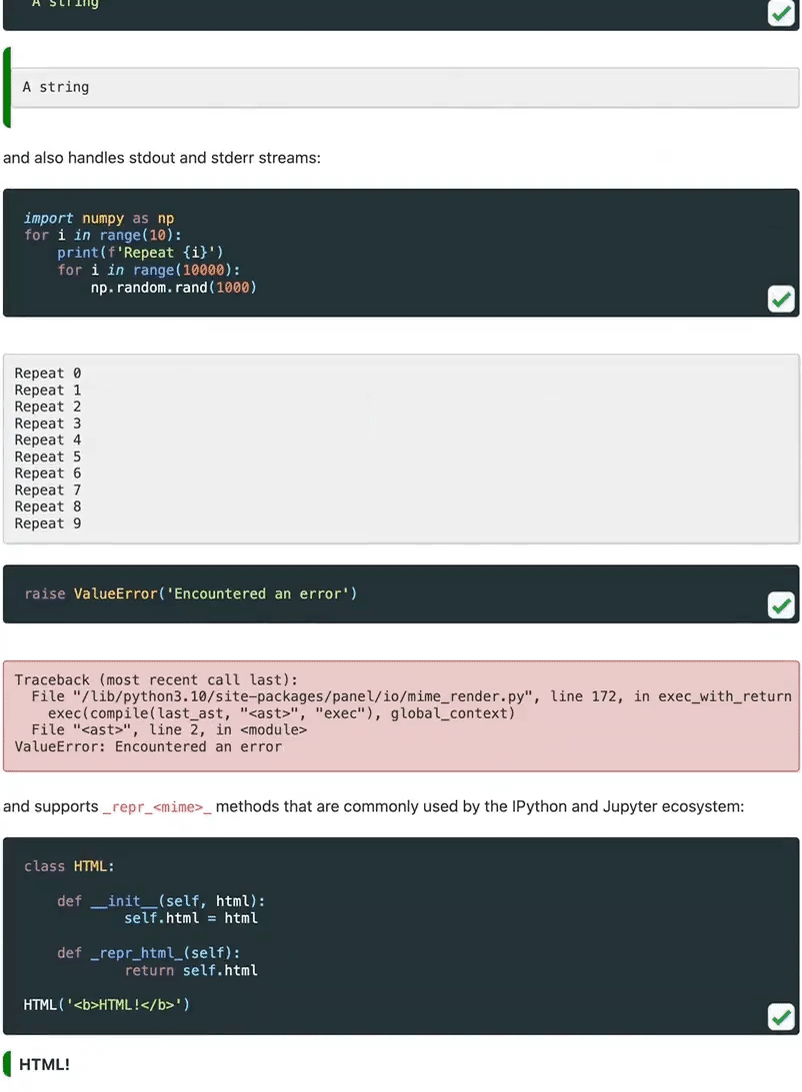
💡 Hace unos días he descubierto MLEM, una herramienta para simplificar despliegues de modelos de machine learning (¡gracias Dani!)
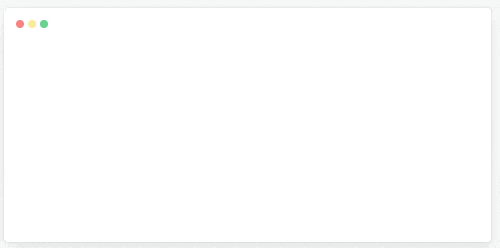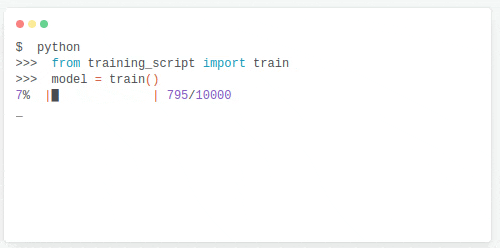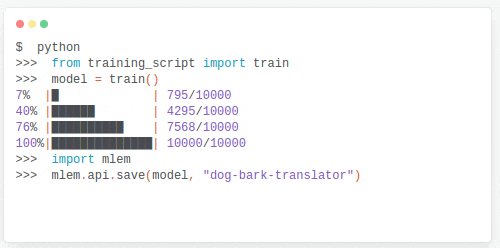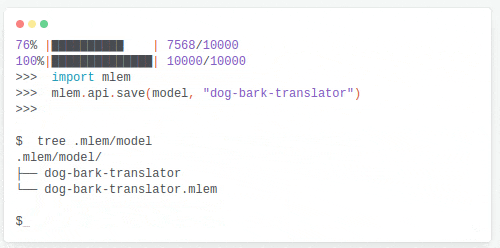
También he descubierto Kedro, un framework para estructurar proyectos de ciencia de datos (como un cookiecutter evolucionado) y visualizar el flujo de información.

📚 Me ha encantado este resumen de las diferentes maneras en las que se está mejorando el rendimiento de JupyterLab. La versión 4 se está haciendo un poco de rogar pero tiene pinta de que será clave para el futuro del proyecto.

He encontrado un libro sobre Research Software Engineering (¿Ingeniería de Software para Investigación? ¿Cómo traducimos esto?) con Python que tiene buenísima pinta.
Y finalmente, hace solo unas horas la fundación CZI (que está financiando varios proyectos del ecosistema de software científico, especialmente para ciencias de la salud pero no solo) ha publicado este espectacular análisis sobre citas académicas a código abierto. Cada cita está enlazada al software, e incluye el contexto en el que se escribió. Todos los datos y el código están en abierto. ¡Así sí!
💼 La gente de Shapelets busca Senior Backend Engineer con experiencia en sistemas distribuidos, C++, y Python. Modalidad remota, salario 45-55 k€/año. Si te interesa, ponte en contacto directamente con Adrián Carrio.
¿Estás buscando una alternativa a Heroku? Yo he migrado a Railway (enlace afiliado) y me encanta que las aplicaciones no “duermen” así que el tiempo de respuesta es siempre rápido ⚡
Acabas de leer la edición #41 de El noticiero de Juanlu. También puedes explorar archivo completo de este boletín.