🔥 Estos días varios paquetes importantes del ecosistema PyData han sacado versiones nuevas:
pandas 1.5 trae numerosas mejoras, como por ejemplo una función from_dummies simétrica a get_dummies (¡por fin!), soporte para tipado gradual, implementación del protocolo estándar de intercambio de dataframes, y mucho más.

In version 1.5.0 we’ve added from_dummies, which allows you to do decode one-hot-encoded DataFrames
It’s the reverse of get_dummies
Check the docs for more info pandas.pydata.org/pandas-docs/st…

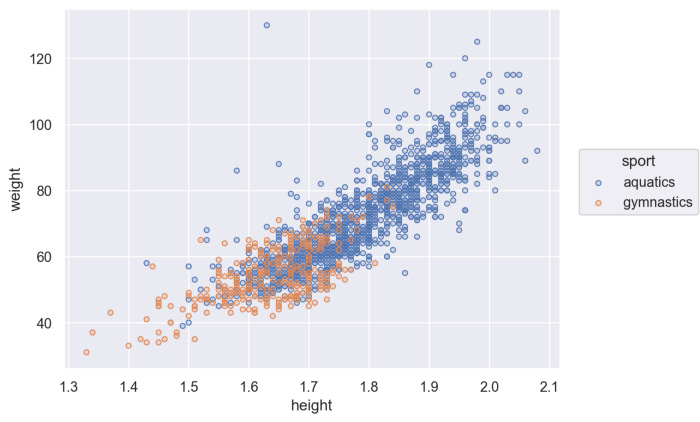
Por otro lado, seaborn 0.12 trae una API totalmente nueva, inspirada en el concepto de la “gramática de los gráficos” presente en ggplot2 de R.

🚀 Y más versiones nuevas: nbgrader 0.8.0 por fin funciona en JupyterLab, duckdb 0.5 trae notables mejoras de rendimiento, y la gente de Tryolabs ha publicado Norfair 2.0, una biblioteca para detección y seguimiento de objetos en tiempo real.

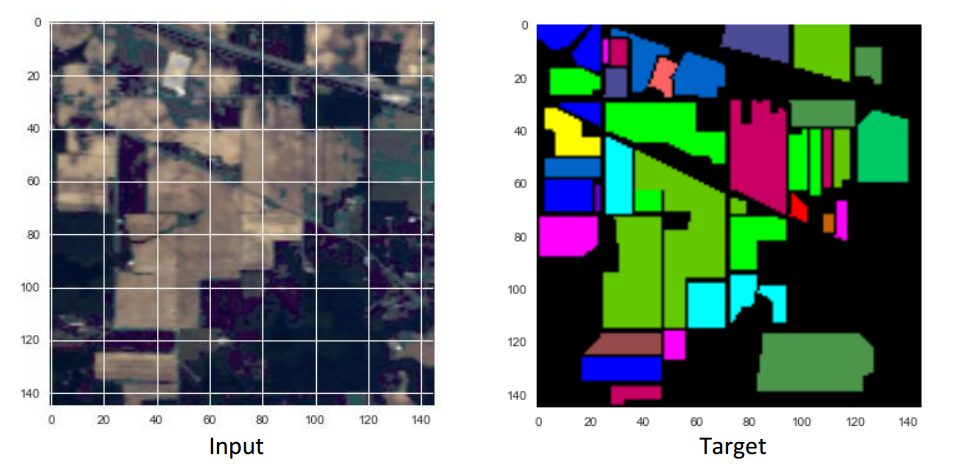
💡 Esta semana he descubierto este repositorio lleno de recursos para aplicar aprendizaje profundo sobre imagen satelital. ¡La cantidad de enlaces que hay es alucinante!
También he descubierto esta web que compara varias herramientas de visualización de Python, muy útil para elegir en función del caso de uso.

You can see that Streamlit has 10 times as many github ⭐️but only has 1.6 times as many downloads.
@Panel_org has no resources for marketing and strategic partnerships. It shows.

Y hablando de visualización con Python, hace semanas que te quiero compartir este hilo de Twitter sobre plotnine (ggplot2 en Python) y seaborn:

💭and I have some thoughts.
Here’s the notebook with plotnine (commented out) and seaborn plots:
geom_bar(aes(fill = “books”), stat = “identity”) +
theme_minimal() +
labs(title = “Book Ratings”,
x = “Book Titles”,
y = “Average GoodRead Ratings”) +
theme(axis_text_x = element_text(angle = 45),
legend_position = “none”))
bp3 = sns.barplot(data = book_df, x = "books", y = "ratings", hue = "books", dodge = False) bp3.set(title = "Book Ratings", xlabel = "Book Titles", ylabel = "Average GoodRead Ratings") plt.xticks(rotation=45) plt.legend([],[], frameon = False)
(plus resulting barplot showing the average goodreads ratings for various books with bars filled with different colors)” loading=”lazy”>
📚 Me ha gustado mucho este informe sobre el proyecto nbproject, contiene varias referencias a estudios empíricos sobre el trabajo con notebooks. Por ejemplo, he aprendido que la “fealdad” del código está correlada con una mayor cantidad de defectos.
Por otro lado, la empresa Zalando ha publicado un dataset parecido al MNIST (el de los números) pero con ropa. El MNIST ya estaba demasiado trillado, así que son buenas noticias.

Y por último, este artículo sobre cómo una bandera de compilación está afectando a los resultados numéricos de miles de paquetes Python no tiene desperdicio.
🦙 La semana que viene es la SciPy Latin America 2022 en la Universidad Nacional de Salta. El evento se desarrollará entre el 26 y el 28 de septiembre y la entrada es gratuita. Lamentablemente no podré asistir en persona, pero desde aquí mando un abrazo a mis amigas y amigos de Argentina, a quienes echo mucho de menos. ¡Muchos éxitos!

¿Estás buscando una alternativa a Heroku? Yo he migrado a Railway (enlace afiliado) y me encanta que las aplicaciones no “duermen” así que el tiempo de respuesta es siempre rápido ⚡
Acabas de leer la edición #38 de El noticiero de Juanlu. También puedes explorar archivo completo de este boletín.